
k近邻法笔记及Python实现
k近邻法,简要说就是 近朱者是赤的,近墨者是黑的
如何定义近邻?
距离度量
- 欧式距离
- 曼哈顿距离
- 切比雪夫距离
- 闵可夫斯基距离
- 标准化欧氏距离
- 马氏距离
- 夹角余弦
- 汉明距离
- 杰卡德距离、杰卡德相似系数
- 相关系数、相关距离
- 信息熵
k如何选取?
交叉验证,取效果最佳的k。
k值小时,模型复杂,近似误差小,估计误差大,噪声敏感,容易发生过拟合;
k值大时,模型简单,近似误差大,估计误差小。
怎么确定类别?
常用的分类决策规则是多数表决,对应于经验风险最小化。
优缺点总结:
优点:精度高、对异常值不敏感、无数据输入假定
缺点:计算复杂度高、空间复杂度高
适用数据范围:数值型和标称型
一些细节
-
因为一般不同特征数据的量纲不同,所以需要归一化。
-
默认的KNN,是对每个相邻节点赋予一样的权重。可以根据距离分配不同的权重。
-
可以指定k或者指定r(距离)。
-
k近邻回归,取k个近邻值的均值。 Nearest Neighbors Regression
如何快速进行k近邻搜索?
可以使用线性扫描法,但耗时太大。构造kd树,kd树是二叉树。也可以构造ball tree
有关kd树
kd树的建立:
递归建立,是前序遍历。
kd树的查找:
先找到包含结点的超平面,然后回溯查找距离结点最小的点。是左、右子树访问顺序不定的中序遍历。
kd树的插入:
kd树的删除:
基于KNN的工作
聚类方法:DBSCAN、SpectralClustering
流形方法:TSNE、Isomap
NCA(Neighborhood Components Analysis)
代码:
#!/usr/bin/python3
# -*- coding: utf-8 -*-
from collections import Counter
import heapq
import numpy as np
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
class TreeNode:
def __init__(self, x, depth, left=None, right=None):
self.val = x
self.depth = depth
self.left = left
self.right = right
def __repr__(self):
return '[{}, {}, {}]'.format(self.val, str(self.left), str(self.right))
class KNN:
def __init__(self):
# self.d: feature dimension
self.d = 0
self.depth = 0
self.root = None
def build_tree(self, x):
if not x: return None
self.d = len(x[0]) - 1
left, root, right = self.split(x)
root = TreeNode(root, self.depth)
self.depth += 1
root.left = self.build_tree(left)
root.right = self.build_tree(right)
self.depth -= 1
self.root = root
return root
def split(self, x):
if len(x) == 1: return None, x, None
axis = self.depth % self.d
x.sort(key=lambda a: a[axis])
mid = x[len(x)//2][axis]
left, root, right = [], [], []
for d in x:
if d[axis] < mid:
left.append(d)
elif d[axis] == mid:
root.append(d)
else:
right.append(d)
return left, root, right
def search_tree(self, x, dist, k=5):
res = []
self._search(self.root, x, res, dist, k)
res = sorted([(n, -h) for n, h in res], key=lambda x: x[1])
cls = [n[-1] for n, h in res]
counter = Counter(cls)
y = max(counter, key=lambda x: counter[x])
return res, y
def _search(self, node, x, res, dist, k=5):
axis = node.depth % self.d
if x[axis] > node.val[0][axis]:
if node.right:
self._search(node.right, x, res, dist, k)
else:
if node.left:
self._search(node.left, x, res, dist, k)
for val in node.val:
distance = dist(x, val[:-1])
if len(res) < k:
heapq.heappush(res, (val, -distance))
else:
if distance < -res[0][1]:
heapq.heappushpop(res, (val, -distance))
if x[axis] > node.val[0][axis]:
if x[axis] - node.val[0][axis] < -res[0][1] and node.left:
self._search(node.left, x, res, dist, k)
else:
if node.val[0][axis] - x[axis] < -res[0][1] and node.right:
self._search(node.right, x, res, dist, k)
iris = load_iris()
X = iris.data[:, :2]
y = iris.target
data = np.zeros((X.shape[0], X.shape[1] + 1))
data[:, :-1] = X
data[:, -1] = y
var = X.var(axis=0)
h = .02
cmap_light = ListedColormap(['orange', 'cyan', 'cornflowerblue'])
cmap_bold = ListedColormap(['darkorange', 'c', 'darkblue'])
kdt = KNN()
kdt.build_tree([list(x) for x in data])
def dist(p):
def distance(a, b):
return (sum(((p1 - p2) / var[i]) ** p for i, (p1, p2) in enumerate(zip(a, b))) ** (1/p))
return distance
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
for k in range(5, 25, 5):
Z = []
for x in np.c_[xx.ravel(), yy.ravel()]:
Z.append(kdt.search_tree(x, dist(2), k)[1])
Z = np.array(Z).reshape(xx.shape)
plt.figure()
plt.pcolormesh(xx, yy, Z, cmap=cmap_light)
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=cmap_bold, edgecolor='k', s=20)
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.title("3-Class classification (k = %i)" % (k))
plt.show()
实现中构建kdtree的输入数据格式是使用python原始list,改成numpy可以更高效。
量纲未归一化:
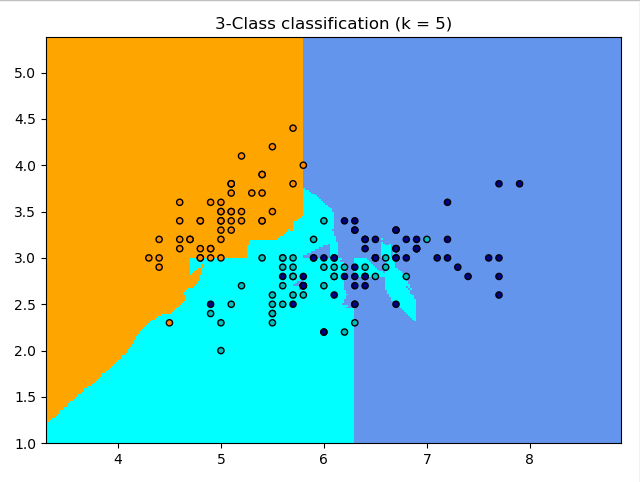
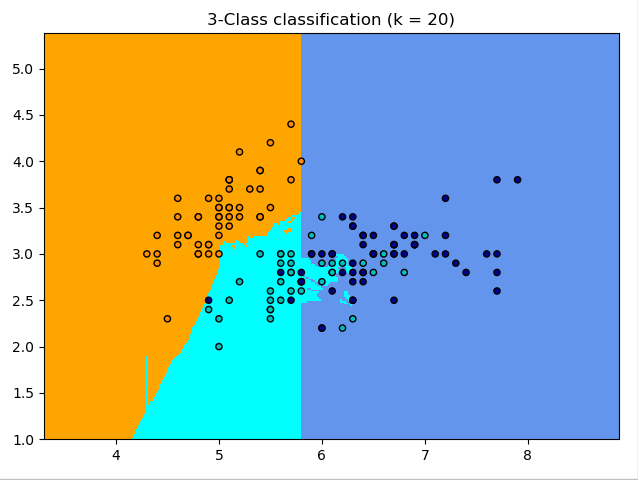
量纲归一化:
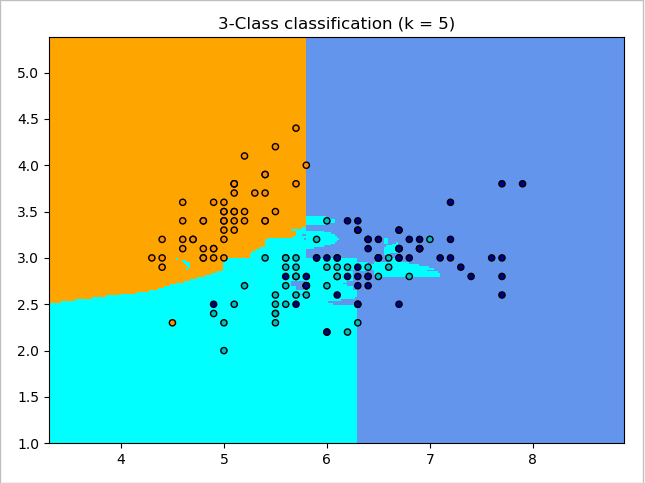
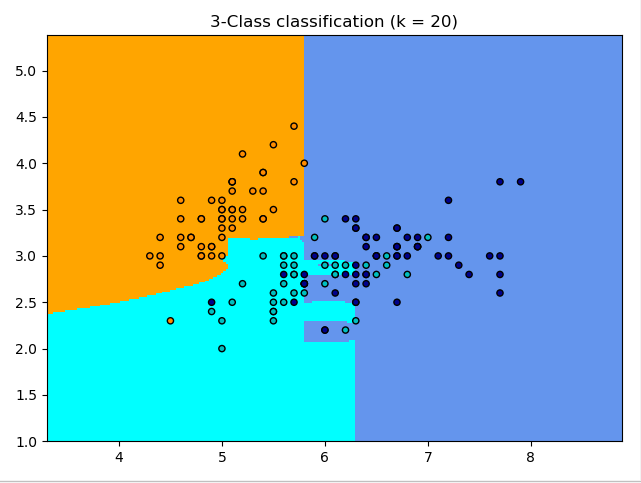
参考:
李航. (2012). 统计学习方法. 清华大学出版社. 北京
sklearn的官方介绍
机器学习中的相似性度量
kdtree实现
【统计学习方法】k近邻 kd树的python实现

 浙公网安备 33010602011771号
浙公网安备 33010602011771号