SQL Server 2005 中删除重复记录
我们在数据库开发和维护时由于各种原因,经常会产生重复数据,如果数据量比较大的话,会是一个很费事的工作,那么怎么能够迅速的删除这些无用的重复记录呢.
USE [master]
GO
if exists (select * from dbo.sysobjects where id = object_id(N'[dbo].[TestTD]'))
DROP TABLE TestTD
CREATE TABLE TestTD(ProductID INT, ProductName NVARCHAR(50),Unit NVARCHAR(50),Price MONEY)
INSERT INTO TestTD(ProductID,ProductName,Unit,Price) VALUES (1,'A','UnitA',1)
INSERT INTO TestTD(ProductID,ProductName,Unit,Price) VALUES (2,'B','UnitA',2)
INSERT INTO TestTD(ProductID,ProductName,Unit,Price) VALUES (3,'C','UnitA',3)
INSERT INTO TestTD(ProductID,ProductName,Unit,Price) VALUES (3,'C','UnitC',3)
INSERT INTO TestTD(ProductID,ProductName,Unit,Price) VALUES (4,'D','UnitD',4)
SELECT * FROM TestTD
--Remove Redundancy Records
DECLARE @AllCount INT
--检查是否有重复记录
SELECT RedundancyCount = COUNT(ProductID),
ProductID
INTO #CostItem
FROM TestTD
GROUP BY ProductID
HAVING COUNT(ProductID) > 1
SELECT @AllCount = COUNT(ProductID) FROM #CostItem
-- There are some Redundancy Records. Remove them.
IF @AllCount > 0
BEGIN
DECLARE @CurrentPosition INT,
@DuplicateCount INT,
@ProductID INT
SET @CurrentPosition = @AllCount
SELECT SortOrder = ROW_NUMBER() OVER (ORDER BY ProductID),
*
INTO #T
FROM #CostItem
--循环删除
WHILE @CurrentPosition > 0
BEGIN
--取出有重复数据的ProductID和重复的个数
SELECT @DuplicateCount = RedundancyCount,
@ProductID = ProductID
FROM #T WHERE SortOrder = @CurrentPosition
--利用rownumber来删除,使重复的数据只保留一条.
;WITH [CostItem_RowID] AS
(SELECT ROW_NUMBER() OVER (ORDER BY @ProductID) AS ROWID, *
FROM TestTD gwci WHERE gwci.ProductID = @ProductID)
DELETE FROM [CostItem_RowID] WHERE ROWID < @DuplicateCount
SET @CurrentPosition = @CurrentPosition - 1
END
DROP TABLE #T
END
DROP TABLE #CostItem
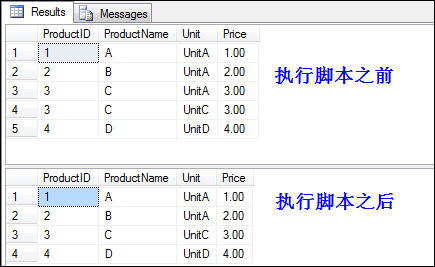
SELECT * FROM TestTD
效果图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号