
CleanArchitecture
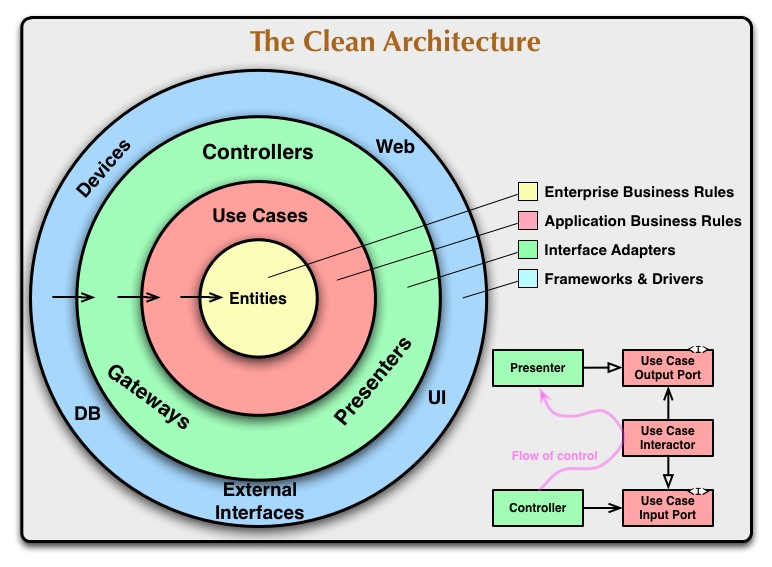
CleanArchitecture 架构特点:
- 独立于框架。该架构不依赖于某些功能丰富的软件库的存在。这使您可以将此类框架用作工具,而不必将系统塞入其有限的约束中。
- 可测试。可以在没有 UI、数据库、Web 服务器或任何其他外部元素的情况下测试业务规则。
- 独立于用户界面。UI 可以轻松更改,而无需更改系统的其余部分。例如,可以用控制台 UI 替换 Web UI,而无需更改业务规则。
- 独立于数据库。您可以将 Oracle 或 SQL Server 换成 Mongo、BigTable、CouchDB 或其他东西。您的业务规则未绑定到数据库。
- 独立于任何外部机构。事实上,您的业务规则根本不了解外部世界。
尽管这些架构在细节上都有所不同,但它们非常相似。它们都有相同的目标,即关注点分离。他们都通过将软件分层来实现这种分离。每个都至少有一层用于业务规则,另一层用于接口。
这些架构中的每一个都产生以下系统:
- 独立于框架。该架构不依赖于某些功能丰富的软件库的存在。这使您可以将此类框架用作工具,而不必将系统塞入其有限的约束中。
- 可测试。可以在没有 UI、数据库、Web 服务器或任何其他外部元素的情况下测试业务规则。
- 独立于用户界面。UI 可以轻松更改,而无需更改系统的其余部分。例如,可以用控制台 UI 替换 Web UI,而无需更改业务规则。
- 独立于数据库。您可以将 Oracle 或 SQL Server 换成 Mongo、BigTable、CouchDB 或其他东西。您的业务规则未绑定到数据库。
- 独立于任何外部机构。事实上,您的业务规则根本不了解外部世界。
本文顶部的图表试图将所有这些架构集成到一个可操作的想法中。
依赖规则
同心圆代表软件的不同领域。一般来说,你走得越远,软件的层次就越高。外圈是机制。内圈是政策。
使这个架构工作的最重要的规则是依赖规则。这条规则说源代码依赖只能指向内部。内圈中的任何人都无法对外圈中的事物一无所知。特别是,在外圈中声明的事物的名称不能被内圈中的代码提及。这包括函数、类。变量或任何其他命名的软件实体。
同样,在外圈中使用的数据格式不应该被内圈使用,特别是如果这些格式是由外圈中的框架生成的。我们不希望外圈的任何东西影响内圈。
实体
实体封装了企业范围的业务规则。实体可以是具有方法的对象,也可以是一组数据结构和函数。只要实体可以被企业中的许多不同应用程序使用,这并不重要。
如果您没有企业,并且只是编写单个应用程序,那么这些实体就是应用程序的业务对象。它们封装了最通用和最高级的规则。当外部事物发生变化时,它们最不可能发生变化。例如,您不会期望这些对象会受到页面导航或安全性更改的影响。对任何特定应用程序的操作更改都不应影响实体层。
用例
该层中的软件包含特定于应用程序的业务规则。它封装并实现了系统的所有用例。这些用例协调进出实体的数据流,并指导这些实体使用其企业范围的业务规则来实现用例的目标。
我们预计这一层的变化不会影响实体。我们也不希望这一层受到外部变化的影响,例如数据库、UI 或任何常见框架。该层与此类问题隔离。
但是,我们确实希望对应用程序操作的更改会影响用例,从而影响这一层中的软件。如果用例的细节发生变化,那么这一层的一些代码肯定会受到影响。
接口适配器
该层中的软件是一组适配器,可将数据从最适合用例和实体的格式转换为最适合某些外部机构(如数据库或 Web)的格式。例如,正是这一层将完全包含 GUI 的 MVC 架构。Presenters、Views 和 Controllers 都属于这里。模型可能只是从控制器传递到用例,然后从用例返回到演示者和视图的数据结构。
类似地,在这一层中,数据从对实体和用例最方便的形式转换为对正在使用的任何持久性框架最方便的形式。即数据库。这个圈子内的任何代码都不应该对数据库有任何了解。如果数据库是 SQL 数据库,那么所有的 SQL 都应该限制在这一层,特别是限制在这一层与数据库有关的部分。
在这一层中还有任何其他适配器,用于将数据从某种外部形式(例如外部服务)转换为用例和实体使用的内部形式。
框架和驱动程序。
最外层一般由框架和工具组成,如数据库、Web 框架等。通常在这一层你不会写太多代码,除了与下一个循环往内通信的胶水代码。
这一层是所有细节的所在。网络是一个细节。数据库是一个细节。我们把这些东西放在外面,它们不会造成什么伤害。
只有四个圈?
不,圆圈是示意性的。您可能会发现您需要的不仅仅是这四个。没有规则说你必须总是只有这四个。但是,依赖规则始终适用。源代码依赖项总是指向内部。随着您向内移动,抽象级别会增加。最外圈是低层次的具体细节。随着您向内移动,软件变得更加抽象,并封装了更高级别的策略。最内圈是最一般的。
跨越界限。
图的右下角是我们如何跨越圆圈边界的示例。它显示了控制器和演示者与下一层的用例进行通信。注意控制流程。它从控制器开始,遍历用例,然后在演示者中执行。还要注意源代码依赖项。它们中的每一个都指向用例。
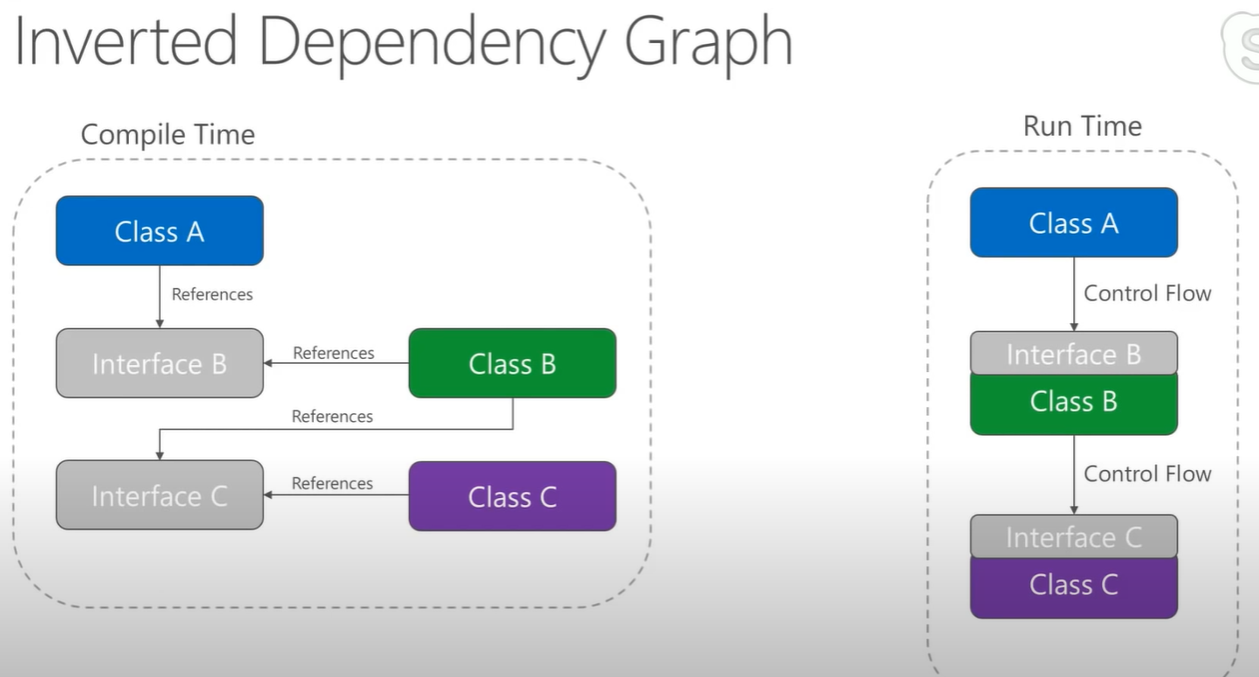
我们通常通过使用依赖倒置原则来解决这个明显的矛盾。例如,在像 Java 这样的语言中,我们会安排接口和继承关系,以便源代码依赖关系在跨越边界的正确点反对控制流。
例如,考虑用例需要调用演示者。但是,这个调用不能是直接的,因为这会违反依赖规则:内圈不能提及外圈中的名称。所以我们在内圈中让用例调用一个接口(这里显示为用例输出端口),并让外圈中的演示者实现它。
相同的技术用于跨越架构中的所有边界。我们利用动态多态性来创建与控制流相反的源代码依赖关系,这样无论控制流向哪个方向,我们都可以遵守依赖规则。
哪些数据跨越边界。
通常,跨越边界的数据是简单的数据结构。如果您愿意,可以使用基本结构或简单的数据传输对象。或者数据可以只是函数调用中的参数。或者你可以将它打包成一个 hashmap,或者将它构造成一个对象。重要的是,隔离的、简单的数据结构可以跨越边界传递。我们不想欺骗和传递实体或数据库行。我们不希望数据结构有任何违反依赖规则的依赖。
例如,许多数据库框架返回方便的数据格式以响应查询。我们可以称其为 RowStructure。我们不想跨边界向内传递该行结构。这将违反依赖规则,因为它会迫使内圈了解外圈。
所以当我们越界传递数据时,总是采用最方便内圈的形式。
结论
遵守这些简单的规则并不难,并且会为您省去很多麻烦。通过将软件分层并遵守依赖规则,您将创建一个本质上可测试的系统,并具有所有暗示的好处。当系统的任何外部部件(如数据库或 Web 框架)过时时,您可以轻松替换那些过时的元素。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号