KP模型迭代
- 大规模稀疏模型的训练和serving
- 自研PS架构:支持稀疏特征
- 实时数据流:支持实时行为特征
- 丰富特性:feasign实时统计特征;特征淘汰、特征准入;在离线一致性校验;
- 本地预估:优化后的图直接在本地计算,增加embedding数据缓存层,大大提升预估侧性能
- 特征评估:离线特征重要度
- 最终模型结构
![]()
数据流项目
![]()
- 背景:上报有错、漏、重复,模型是FTRL,样本没有落盘,特征实时性和准确性不佳
- 先后应用在萌推、实惠喵、趣键盘等业务上,取得明显线上收益
- 优化方向:是否可以直接用reqid作为拼接依据(需要考虑正反馈长度),对于加购合并付款的处理
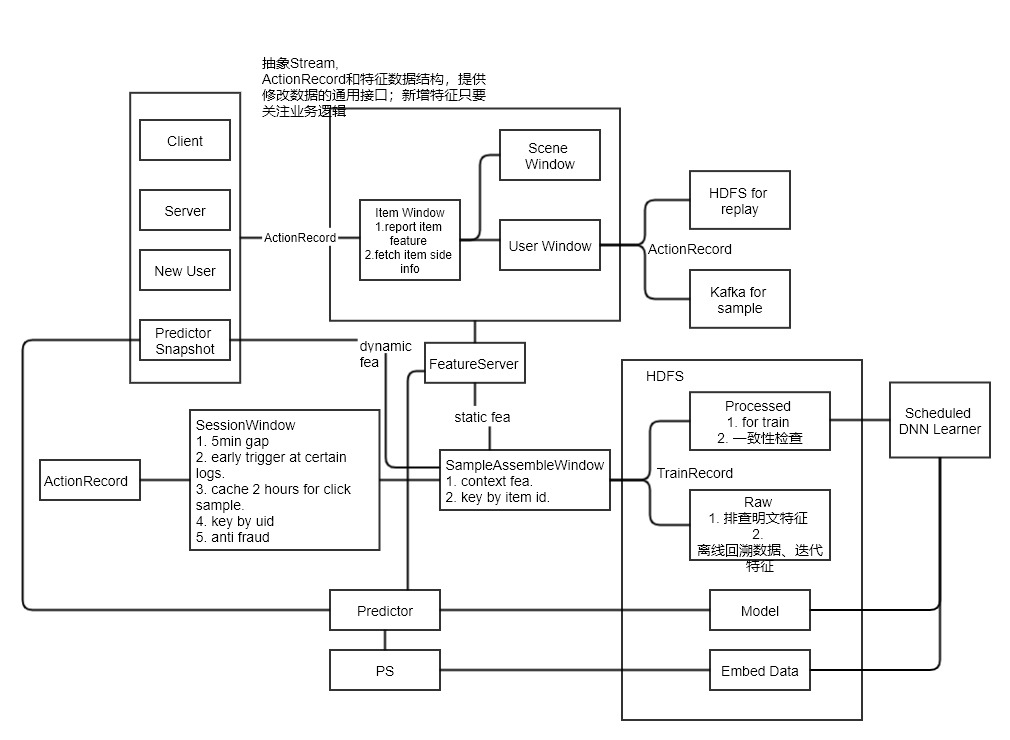
- 主导了算法中台的关键项目,基于flink开发了能够快速应用于多个业务的一整套特征上报、样本拼接与落盘的解决方案,支持线上模型从ftrl升级到dnn并持续迭代。项目亮点主要有以下方面:对数据源和特征数据进行了抽象化和可配置化,大幅降低新增特征开发效率,且易于业务线之间的迁移;实现明文和hash双dump,提升特征调研效率;实时特征上报稳定、准确、高效,用户行为产生到特征更新在200ms左右;采用用户维度的session窗口和水位线机制,样本拼接准确性得到大幅提升,且易于排查case;新引入用户维度天级和小时级的反刷单机制;新引入行为日志的重放机制,保证线上特征被污染时可快速回滚。
粗排项目
- 先后在萌推和米读上线
- 基于双塔实现,item向量离线生成文件加载
- 迭代路径:多目标、SENet、PAL、模型蒸馏、粗排WDL,整体负责米读和萌推业务的粗排,在模型方向先后迭代上线了基于shared embedding的多目标模型、为了解决双塔交互太迟问题的SENet模型、位置特征作为模块的位置消偏模型、学习精排模型表达能力和优势特征的模型蒸馏机制等多个版本,同时为了在粗排中引入交叉特征,尝试了双塔版本的WDL模型;支持趣头条进行数据流改造,尝试粗排全链路一致性建模;主导推进了引擎、预估服务、KNN服务和实验平台对于召回和粗排的支持,积累了在粗排和模型召回方向丰富的模型和业务经验。
- 优化方向:直接学习精排topk(是否选择策略重排后的结果),负样本采用精排靠后位置(进入精排未曝光),pointwise / pairwise,与精排的相似度评测
- 粗排直接学习精排结果,例如topk作为正样本,未展示作为负样本;或者学习pairwise loss
- 粗排模型增加自注意力结构
- 比较重要的特征(人工筛选或者SENet学出来的结果),不经过或者只经过浅层DNN,直接连接到最后的塔的输出(add or concat)
- 模型蒸馏 (直接学习 or 引入辅助塔+辅助loss)(mse or temperature softmax) https://blog.csdn.net/qq_38343151/article/details/103795833
- 特征:负反馈、hit类特征、文本特征(关键是简介和头几章)、书籍在其他平台的搜索/阅读热度、KV类统计特征
召回项目
- 双塔u2i实时召回
- 迭代路径:负采样、难负例挖掘、自注意力
- item向量导入faiss
- 基于图网络(GraphSAGE)的u2i2i和i2i
- 构图方法:同session下的相邻点击作为item同构图
- 负采样在萌推效果明显,但是米读负向,不符合预期:米读物料太少,不需要样本来解决样本选择偏差问题
- 优化方向:尝试采样方式 纯曝光池、曝光去点击item池、纯点击item池(类似难负例思路)
- graphsage学习效果差,学到趋同,改进:减小采样周期,约束边的个数,补充同类目边,屏蔽高热节点
- 双塔u2i 因为点击样本太稀疏,学习效果差,改进:增加同一次曝光下,同类目、关键词正样本
- 考虑到召回中比较明显的样本选择偏差问题,双塔召回上线时采用基于热度的全库负采样;为了提升召回模型的能力,尝试了batch内的难负例挖掘,开发了基于图神经网络的item和类目的向量表示用于相关召回和兴趣探索,通过case分析,先后采取减小采样周期,约束边的个数,补充同类目边,屏蔽高热节点等构图策略,优化了图和节点向量表示的质量;
精排
- 迭代路径: MLP、hit-session特征版本、MMOE
- 持续迭代萌推签到页和优惠券场景精排模型,在MLP基础上、尝试通过deepFM、DCN等模型层面的特征交叉替代笛卡尔交叉特征;尝试通过DIN挖掘目标item和用户历史行为的关系,由于工程方面存在障碍,最后通过引入hit交叉和session特征取得了uv价值2%+的收益;多目标模型方面尝试了MMOE,业务指标微正向,且节约了线上服务的机器成本。其他工作还包括多目标公式调优、用以提升模型迭代速度的离线实验和预估服务搭建辅助工具。
- 为什么不直接上多目标版本? 1. 需要先做一个base 2. 预估和引擎端不支持
- session特征不明显,不符合预期:优惠券场景的用户更看重优惠券、券后价格、是否能凑单等因素
- 优化方向:超长序列建模
小加复盘图像识别
- 不定长数字识别: 先切割后单独识别 -> CRNN+CTC
posted @
2021-10-13 11:43
排骨zzz
阅读(
197)
评论()
收藏
举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号