
计算机科学速成课
课程链接:
https://www.bilibili.com/video/av2 1 376839?p=3
课程目标:从高层次总览一系列计算机话题,快速入门计算机科学。
待整理
物理(晶体管)-> 数字电路(门 -> Register / Arithmetic Logic Unit / Accumulator / SRAM...)-> 微体系结构(CPU)-> ISA(x86-64)-> Machine Code(01000001)-> Assembler -> Compiler -> BIOS/UEFI(设备驱动程序) -> kernel(linux kernel) -> 应用程序(操作系统,程序)
注:操作系统属于程序
电子计算机系统的 抽象层次:
物理(电子)——>器件(晶体管、二极管)——>模拟电路(放大器、滤波器)——>数字电路(与门或门)——>逻辑(加法器、储存器)——>微体系结构(数据路径控制器)———>体系结构(指令寄存器)——>操作系统(设备驱动程序)——>应用软件(程序)
第一课:计算机早期历史
1、计算机技术的影响——进入信息时代
-
出现自动化农业设备与医疗设备
-
全球通信和全球教育机会变得普遍
-
出现意想不到的虚拟现实/无人驾驶/人工智能等新领域
2、计算机的实质:
极其简单的组件,通过一层层的抽象,来做出复杂的操作。
计算机中的很多东西,底层其实都很简单,让人难以理解的,是一层层精妙的抽象。像一个越来越小的俄罗斯套娃。
3、关于计算的历史:
-
公元前 2500 年,算盘出现,为十进制,功能类似一个计数器。
-
公元前 2500 年-公元 1500 年:星盘、计算尺等依靠机械运动的计算设备出现
-
公元 1613 年:computer 的概念出现,当时指的是专门做计算的职业,
-
1694 年:步进计算器出现,是世界上第一台能自动完成加减乘除的计算器。
-
1694-1900 年:计算表兴起,类似于字典,可用于查找各种庞大的计算值。
-
1823 年:差分机的设想出现,可以做函数计算,但计划最后失败。
-
19 世纪中期:分析机的设想出现,设想存在可计算一切的通用计算机。
-
1890 年:打孔卡片制表机。原理:在纸上打孔→孔穿过针→针泡入汞→电路连通→齿轮使计数+1。
第二课:电子计算机的发展史
1、电子计算机元器件变化:
继电器→真空管→晶体管
2、计算机的出现背景:
20 世纪人口暴增,科学与工程进步迅速,航天计划成形。以上导致数据的复杂度急剧上升、计算量暴增,对于计算的自动化、高速有迫切的需求。
3、电子计算机的发展:
1945 年 哈佛马克 1:使用继电器,用电磁效应,控制机械开关,缺点为有磨损和延迟。
最早还因为有虫子飞进去导致故障,引申出 bug=故障的意思。
1943 年 巨人 1 号:使用真空管(三极管),制造出世界上第一个可编程的计算机。
1946 年 ENIAC:第一个电子通用数值积分计算机。
1947 年 晶体管出现,使用的是固态的半导体材料,相对真空管更可靠。
1950s 空军 ANFSQ-7: 真空管到达计算极限。
1957 年 IBM 608: 第一个消费者可购买的晶体管计算机出现。
第三课:布尔逻辑与逻辑门
1、计算机为什么使用二进制:
-
计算机的元器件晶体管只有 2 种状态,通电(1)&断电(0),用二进制可直接根据元器件的状态来设计计算机。
-
而且,数学中的“布尔代数”分支,可以用 True 和 False(可用 1 代表 True,0 代表 False)进行逻辑运算,代替实数进行计算。
-
计算的状态越多,信号越容易混淆,影响计算。对于当时每秒运算百万次以上的晶体管,信号混淆是特别让人头疼的的。
2、布尔代数&布尔代数在计算机中的实现
-
变量:没有常数,仅 True 和 False 这两个变量。
-
三个基本操作:NOT/AND/OR。
-
为什么称之为“门”:控制电流流过的路径
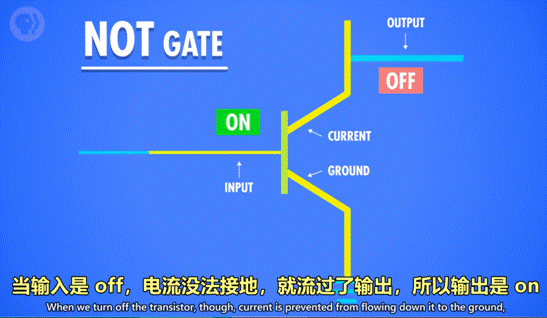
1)NOT 操作:
1 命名:称为 NOT 门/非门。
2 作用:将输入布尔值反转。输入的 True 或 False,输出为 False 或 True。
3 晶体管的实现方式:
-
半导体通电 True,则线路接地,无输出电流,为 False。
-
半导体不通电 False,则输出电流从右边输出,为 True。
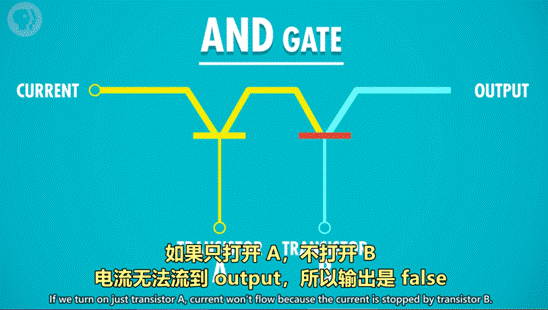
2)AND 操作
1 命名:AND 门/与门
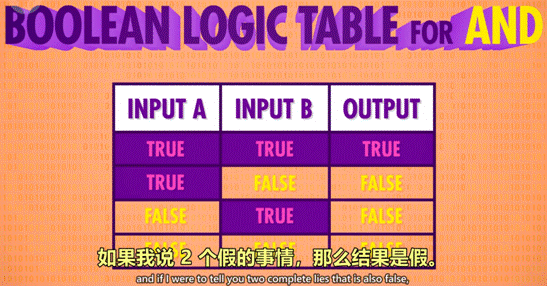
2 作用:由 2 个输入控制输出,仅当 2 个输入 input1 和 input2 都为 True 时,输出才为 True,2 个输入的其余情况,输出均为 False。*可以理解为,2 句话(输入)完全没有假的,整件事(输出)才是真的。
3 用晶体管实现的方式:
串联两个晶体管,仅当 2 个晶体管都通电,输出才有电流(True)
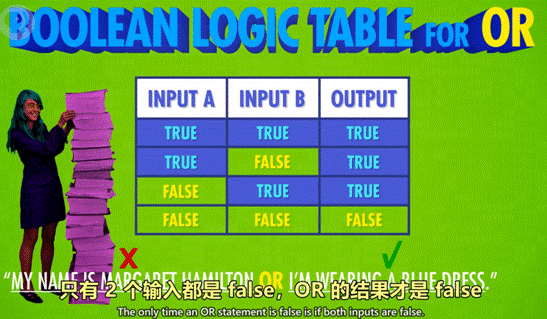
3)OR 操作
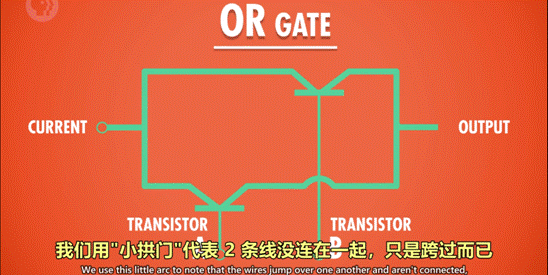
1 命名:OR 门/或门
2 作用:由 2 个输入控制输出,只要其中一个输入为 True,则输出 True。
3 用晶体管实现的方式:
使用 2 个晶体管,将它们并联到电路中,只要有一个晶体管通电,则输出有电流(True)。
3、特殊的逻辑运算——异或
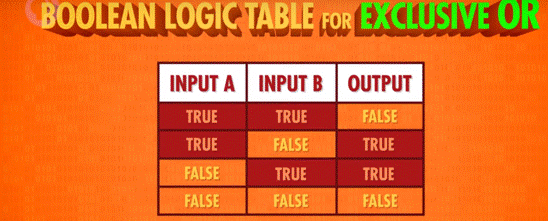
1 命名:XOR 门/异或门
2 作用:2 个输入控制一个输出。当 2 个输入均为 True 时,输出 False,其余情况与 OR 门相同。
3 图示:
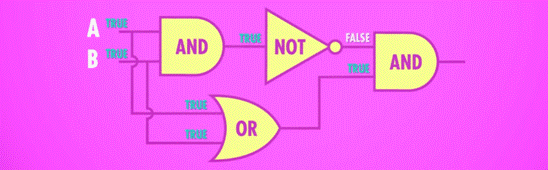
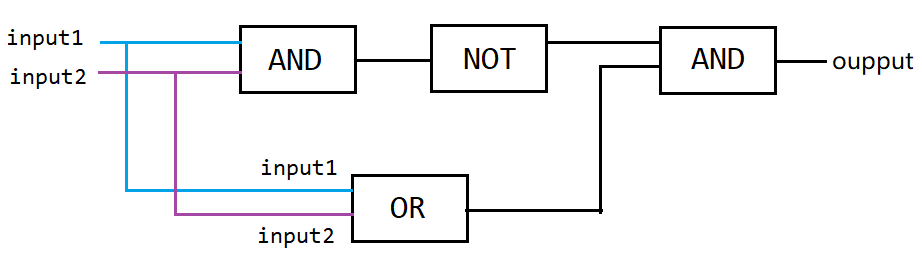
先用一个 OR 门,将其与 AND 门并联,AND 门与 NOT 门串联,最后让 NOT 与 AND 门并联,获得输出。
① true + true = (!( true && true )) && ( true || true ) = false && true = false
② false+ false = (!( false && false)) && ( false || false ) = true && false = false
③ true + false = (!( true && false )) && ( true || false ) = true && true = true
4、逻辑门的符号表示
1 作用:将逻辑门简化,将逻辑门用于构建更大的组件,而不至于太复杂。
2 图示:
l 非门:用三角形+圆圈表示
l 与门:用 D 型图案表示
l 或门:用类似 D 向右弯曲的图案表示
l 异或门:用或门+一个圆弧表示




5、抽象的好处
使得分工明确,不同职业的工程师各司其职,而不用担心其他细节。
第四课:二进制
1、二进制的原理,存储单元 MB/GB/TB 解释
0 计算机中的二进制表示:
单个数字 1 或 0,1 位二进制数字命名为位(bit),也称 1 比特。
1 字节(byte)的概念:
1byte=8bit,即 1byte 代表 8 位数字。最早期的电脑为八位的,即以八位为单位处理数据。为了方便,将八位数字命名为 1 字节(1byte).
2 十进制与二进制的区别:
l 十进制有 10 个数字,0-9,逢 10 进 1(不存在 10 这个数字),则每向左进一位,数字大 10 倍。
l 二进制有 2 个数字,0-1,逢 2 进 1,(不存在 2 这个数字),则每向左进一位,数字大 2 倍。
2 如何进行二进制与十进制联系起来:
l 将十进制与二进制的位数提取出来,编上单位:
eg.二进制的 1011=12^0 + 12^1 + 02^2 + 12^3= 11(从右往左数)
eg.十进制的 1045= 110^3 + 010^2 + 410^1 + 510^0
3 十进制与二进制的图示:
十进制的 263
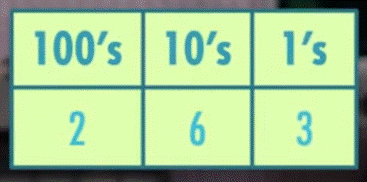
二进制的 10110111
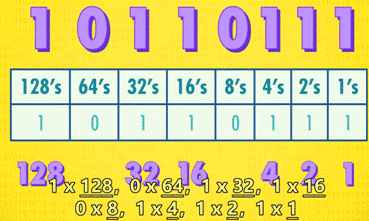
4 二进制的运算:
相同的位数相加,逢 2 进 1

5 byte 在电脑中的单位换算:
1kb=2^10bit = 1024byte =1000b
1TB=1000GB
1GB=十亿字节=1000MB=10^6KB
6 32 位与 64 位电脑的区别
32 位的最大数为 43 亿左右 32 位能表示的数字:0——2的32次方-1,一共2的32次方个数
64 位的最大数为 9.2*10^18
2、正数、负数、正数、浮点数的表示
1)计算机中表示数字的方法
1 整数:
表示方法:
l 第 1 位:表示正负 1 是负,0 是正(补码)
l 其余 31 位/63 位: 表示实数
2 浮点数(Floating Point Numbers):
定义:小数点可在数字间浮动的数(非整数)
表示方法:IEEE 754 标准下
用类似科学计数法的方式,存储十进制数值
l 浮点数=有效位数*指数
l 32 位数字中:第 1 位表示正负,第 2-9 位存指数。剩下 23 位存有效位数
eg.625.9=0.6259(有效位数)*10^3(指数)
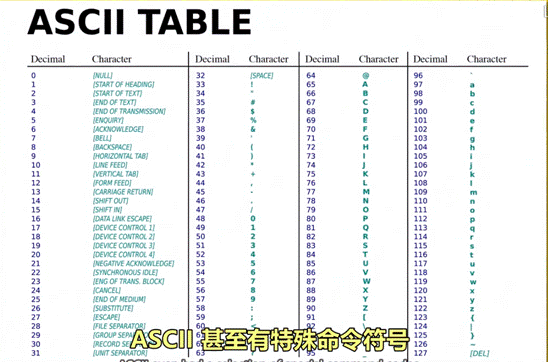
3、美国信息交换标准代码-ASCⅡ,用来表示字符
1 全称:美国信息交换标准代码
2 作用:用数字给英文字母及符号编号
3 内容:7 位代码,可存放 128 个不同的值。
4 图示:
4、UNICODE,统一所有字符编码的标准
1 诞生背景:1992 诞生,随着计算机在亚洲兴起,需要解决 ASCⅡ不够表达所有语言的问题。
为提高代码的互用性,而诞生的编码标准。
2 内容:UNICODE 为 17 组的 16 位数字,有超过 100 万个位置,可满足所有语言的字符需求。
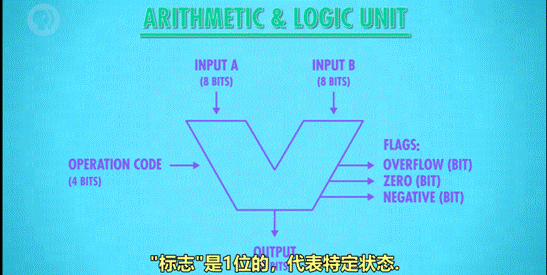
第五课:算术逻辑单元
1、什么是算术逻辑单元
1 命名:简称 ALU,Arithmetic&Logic Unit
2 组成:ALU 有 2 个单元,1 个算术单元和 1 个逻辑单元(Arithmetic Unit 和 Logic Unit)
3 作用:计算机中负责运算的组件,处理数字/逻辑运算的最基本单元。
2、算术单元
1)基本组件:
l 由半加器、全加器组成
¡ 半加器、全加器由 AND、OR、NOT、XOR 门组成
2)加法运算
1 组件:AND、OR、NOT、XOR 门
2 元素:输入 A,输入 B,输出(均为 1 个 bit,即 0 或 1)
3 半加器:
l 作用:用于计算个位的数字加减。
¡ 输入:A,B
¡ 输出:总和,进位(此进位并未参与计算,仅仅是记录了下来)
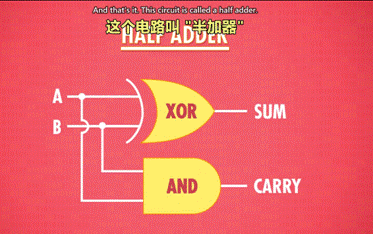
l 抽象:
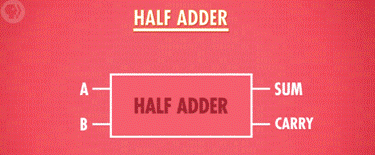
sum:总和 carry:进位
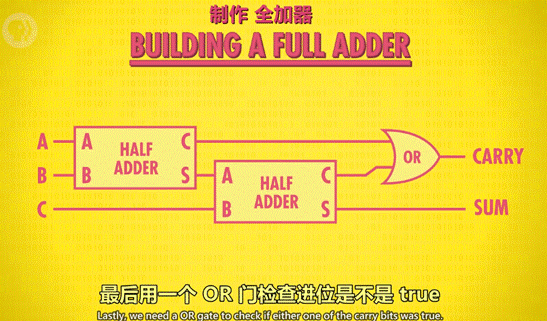
4 全加器:
作用:用于计算超过 1 位的加法(ex:1+1+1),由于涉及进位,因此有 3 个输入(C 充当进位)。
eq:以十进制的11 + 9 为例
sum:1 + 9 = 0 (进一位)
carry:10(此10位11的10) + 10(此10为进的一位) = 20
a :1 b:9 c:10(即进的一位)
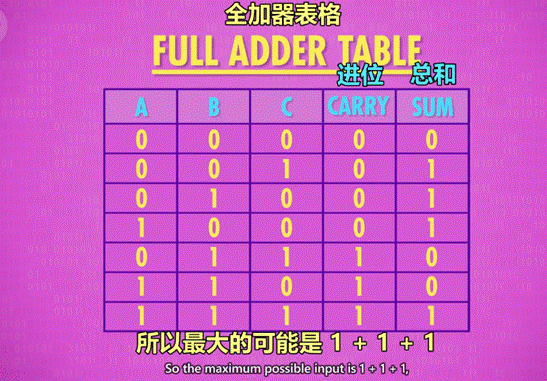
原理图示:
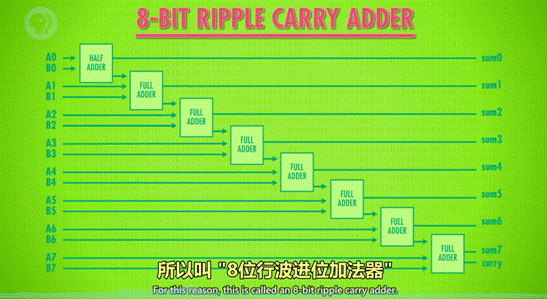
3)如何用半加器与全加器做 8 位数的加法
1 说明:以 8 位行波加法器为例
-
用半加器处理第 1 位数(个位)的加法,得到的和为结果的第 1 位。
-
将输出的进位,输入到第 2 位用的全加器的输入 C 中。
-
将第 2 位的 2 个数用全加器计算,得到的和为结果的第 2 位(sum)。
-
将第 2 位计算的进位连接到百位的全加器输入 C 中。
-
在第 3-8 位上,循环第 3-4 步的操作。
*现在电脑使用的加法器叫“超前进位加法器”
4)算术单元支持的其他运算

3、溢出的概念
内容:在有限的空间内,无法存储位数过大的数,则称为溢出。
说明:第 8 位的进位如果为 1,则无法存储,此时容易引发错误,所以应该尽量避免溢出。
现在计算机使用的是超前进位加法器
4、逻辑单元
作用:执行逻辑操作,如 NOT、AND、OR 等操作,以及做简单的数值测试。
5、ALU 的抽象
ALU即Arithmetic&Logic Unit
1)作用:ALU 的抽象让工程师不再考虑逻辑门层面的组成,简化工作。
2)图示:
像一个大“V”。

3)说明:
图示内容包括:
l 输入 A,B
l 输出
l 标志:溢出、零、负数
第六课 寄存器与内存
0、课程导入
当玩游戏、写文档时如果断电,进度会丢失,这是为什么?
-
原因是这是电脑使用的是 RAM(随机存取存储器),俗称内存,内存只能在通电情况下存储数据。
-
本节课程将讲述内存的工作原理。
1、概念梳理
锁存器:锁存器是利用 AND、OR、NOT 逻辑门,实现存储 1 位数字的器件。
寄存器:1 组并排的锁存器
矩阵:以矩阵的方式来存放锁存器的组合件,n*n 门锁矩阵可存放 n^2 个锁存器,但同一时间只能写入/读取 1 个数字。(早期为 16*16 矩阵)
位址:锁存器在矩阵中的行数与列数。eg.12 行 8 列
多路复用器:一组电线,输入 2 进制的行址&列址,可启用矩阵中某个锁存器
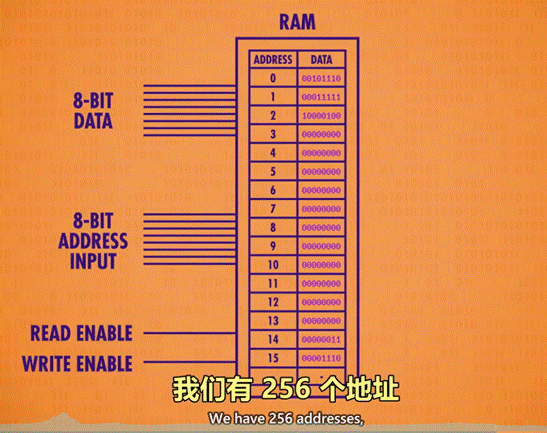
内存(RAM):随机存取存储器,由一系列矩阵以及电路组成的器件,可根据地址来写入、读取数据。类似于人类的短期记忆,记录当前在做什么事情。
2、锁存器
作用:存储 1 位数字。
图示:
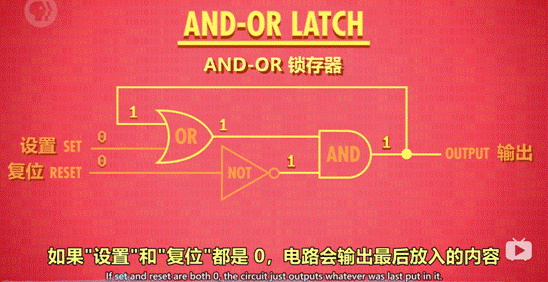
2.5 门锁
锁存器需要同时输入 2 个数字,不太方便。
为了使用更方便,只用 1 根电线控制数据输入,发展了门锁这个器件。另外,用另一根电线来控制整个结构的开关。(和复位作用不同)
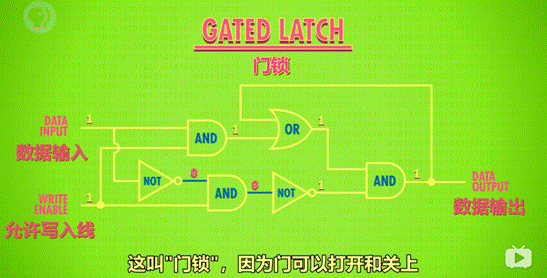
3、寄存器
作用:并排使用门锁,存储多位数字
图示:
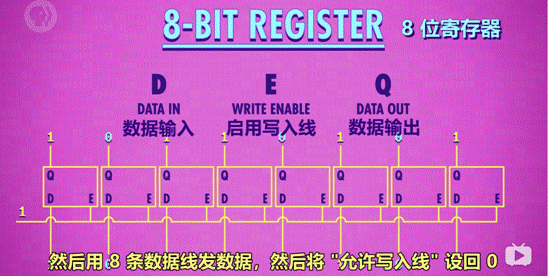
4、门锁矩阵
作用:
n*n 的矩阵有 n^2 个位址,则可以存储 n^2 个数。但 1 个矩阵只可记录 1 位数字,n 个矩阵组合在一起,才可记录 n 位数。如 1 个 8 位数,会按位数分成 8 个数,分别存储在 8 个矩阵的同一个位址中。
8 个矩阵,则可以记录 256 个 8 位数字。
通俗理解:
16*16 的门锁矩阵,可理解为 1 个公寓,1 个公寓 256 个房间。
8 个门锁矩阵并排放,则有了 8 个公寓。
规定每一个公寓同一个编号的房间,都有一样的标记(地址),共同组成 8 位数字。
那么 8 个公寓就能存 (8*256 / 8)个数字。
原因:
16*16 的门锁矩阵虽然有 256 个位置,但每次只能存/取其中 1 个位置的数字。因此,要表示 8 位数字,就需要同时调用 8 个门锁矩阵。
图示:

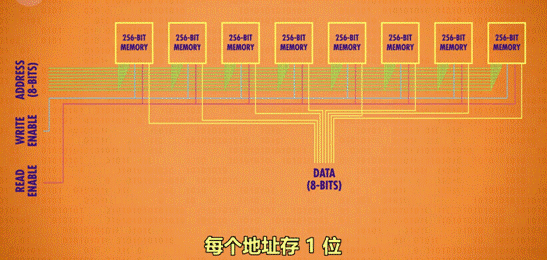
1个256位(寄存器)只能存1bit(8位二进制数的一个位数,其他位数都只能取到0),需要8个寄存器来表示1byte(8bit)
使用方法:在多路复用器中输入位址,x 行 x 列(2 进制),即可点亮 x 行 x 列的锁存器。
举例:
| 行列数 | 矩阵 1 | 矩阵 2 | 矩阵 3 | 矩阵 4 | 矩阵 5 | 矩阵 6 | 矩阵 7 | 矩阵 8 |
|---|---|---|---|---|---|---|---|---|
| 1 行 5 列 | 1 | 0 | 1 | 1 | 0 | 0 | 1 | 0 |
| 2 行 3 列 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 1 |
5、内存
粗略定义:将一堆独立的存储模块和电路看做 1 个单元,组成内存方块,n 个内存方块组成内存模块。在一个电路板上所有的内存方块统称为内存(RAM)。
图示:
第七课 中央处理器(CPU)
1、概念梳理
-
CPU(Central Processing Unit):中央处理单元,负责执行程序。通常由寄存器/控制单元/ALU/时钟组成。与 RAM 配合,执行计算机程序。CPU 和 RAM 之间用“地址线”、“数据线”和“允许读/写线”进行通信。
- 指令:指示计算机要做什么,多条指令共同组成程序。如数学指令,内存指令。
-
时钟:负责管理 CPU 运行的节奏,以精确地间隔,触发电信号,控制单元用这个信号,推动 CPU 的内部操作。
-
时钟速度:CPU 执行“取指令→解码→执行”中每一步的速度叫做“时钟速度”,单位赫兹Hz,表示频率。
-
超频/降频:
-
超频,修改时钟速度,加快 CPU 的速度,超频过多会让 CPU 过热或产生乱码。
-
降频,降低时钟速度,达到省电的效果,对笔记本/手机很重要。
-
-
-
微体系框架:以高层次视角看计算机,如当我们用一条线链接 2 个组件时,这条线只是所有必须线路的抽象。
2、CPU 工作原理
1)必要组件:
-
指令表:给 CPU 支持的所有指令分配 ID
-
控制单元:像指挥部,有序的控制指令的读取、运行与写入。
-
指令地址寄存器:类似于银行取号。该器件只按顺序通报地址,让 RAM 按顺序将指令交给指令寄存器。
-
指令寄存器:存储具体的指令代码。
-
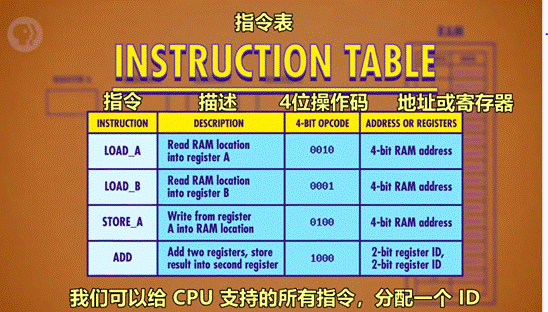
2)过程
l 取指令:指令地址寄存器发地址给 RAM→RAM发该地址内的数据给指令寄存器→指令寄存器接受数据
l 解码:指令寄存器根据数据发送指令给控制单元 →控制单元解码(逻辑门确认操作码)
l 执行阶段:控制单元执行指令(→涉及计算时→调用所需寄存器→传输入&操作码给ALU执行)→调用RAM特定地址的数据→RAM将结果传入寄存器→指令地址寄存器+1
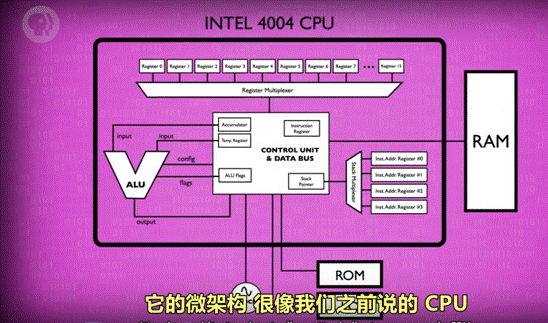
3)图示:
第一个 CPU
第八课 指令和程序
1、概念梳理
-
指令:指示计算机要做什么的代码(机器码),多条指令共同组成程序。如数学指令,内存指令。
- 注:指令和数据都是存在同一个内存里的。
-
指令集:记录指令名称、用法、操作码以及所需 RAM 地址位数的表格。
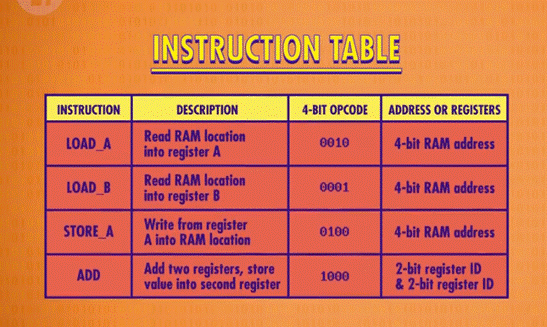

程序
2、指令的执行
- 原则:
- RAM 每一个地址中,都存放 0 或 1 个数据。
- 特定的数字组合,就表示为一个指令,否则表示一个值。
- LOAD 指令:
- 计算机会按地址的顺序,读取 RAM 中所记录的指令/数据。
- 计算机接受到指令后,如 LOAD_A,则通过数据线将数据传至寄存器 A。
- STORE
- 读取对应寄存器中的值,并存储到RAM对应位置中
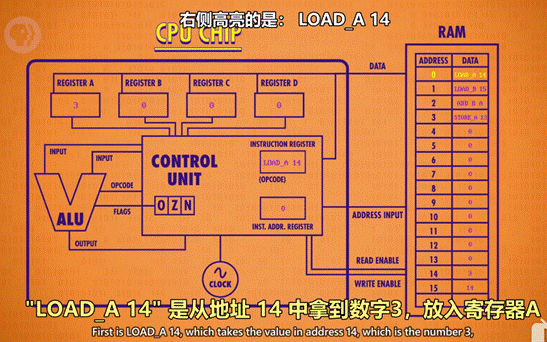
- ADD 指令:
- ADD B A 指令告诉 ALU,把寄存器 B 和寄存器中的数字加起来,存到寄存器 A 中。
- SUB指令:
- SUB B A 指令告诉 ALU,把寄存器 B 和寄存器中的数字相减,存到寄存器 A 中。
- JUMP 指令:
- 遇到 JUMP 指令,程序会跳转至对应的 RAM 地址读取数据。
- JUMP 指令可以有条件跳转(如 JUMP-negative),也可以无条件跳转。
3、计算机指令长度
由于早期计算机每个字只有 8 位,指令只占 4 位,意味着只能有 16 个指令,这远远不够。
现代计算机有两种方式解决指令不够用的问题:
-
最直接的是用更多位来表示指令,如 32 位或 64 位。
-
采用“可变指令长度”,不同的指令的长度不同,尽量节约位数。
假设 某个CUP 使用8 个长度的操作码,如果看到HALF指令,HALF指令不需要额外长度,那么会马上执行。
如果看到JUMP,它得知道位置值才能进行跳转,这个值在JUMP后面 ,称为立即值。
这样设计,指令可以是任意长度,会让读取阶段稍微复杂一点
第九课 高级 CPU 设计
0、概念梳理
多核处理器:一个 CPU 芯片中,有多个独立处理单元
1、现代 CPU 如何提升性能:
早期通过加快晶体管速度,来提升 CPU 速度。但很快该方法到达了极限。
后来给 CPU 设计了专门除法电路+其他电路来做复杂操作:如游戏,视频解码
2、缓存:
缓存:在 CPU 中的小块 RAM,用于存储批量指令或数据
缓存命中:想要的数据已经在缓存里(就不用再去RAM取)
缓存未命中:想要的数据不在缓存里
为了不让 CPU 空等数据,在 CPU 内部设置了一小块内存,称为缓存,让 RAM 可以一次传输一批数据到 CPU 中。(不加缓存,CPU 没位置放大量数据)
缓存也可以当临时空间,存一些中间值,适合长/复杂的运算。
脏位:缓存里每块空间,有个特殊标记,叫脏位,用于检测缓存内的数据是否与 RAM 一致
当缓存已满,而CPU再次向缓存存储数据时,需要清除原来的缓存,此时会先检查脏位,
若脏位标记了此处空间,则表示缓存中此处空间与 RAM 对应原位置的数据 不一致(缓存的数据已被修改),需把修改后的数据写入RAM
空等原因:从 RAM 到 CPU 的数据传输有延迟(要通过总线,RAM 还要时间找地址、取数据、配置、输出数据)。
3、缓存同步:
缓存同步一般发生在 CPU 缓存已满,但 CPU 仍需往缓存内输入数据。此时,被标记为脏位的数据会优先传输回 RAM,腾出位置以防被覆盖,导致计算结果有误。
4、指令流水线:
作用:让取址→解码→执行三个步骤同时进行。并行执行指令,提升CPU性能。
原本需要 3 个时钟周期执行 1 个指令,现在只需要 1 个时钟周期。
设计难点:数据具有依赖性 跳转程序
数据依赖性解决方法:
乱序运行、预测分支(高端 CPU)
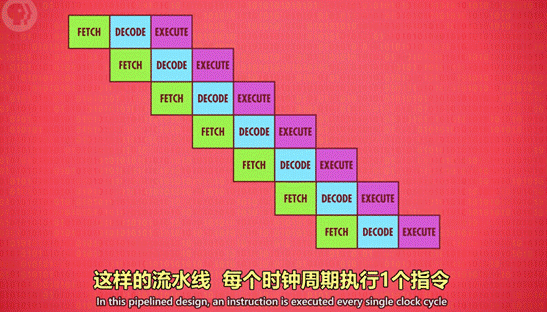
5、一次性处理多条指令
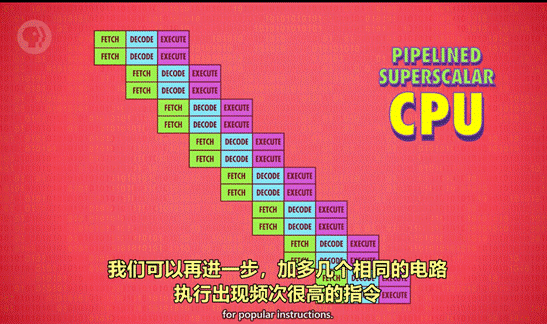
6、同时运行多个指令流(多核 CPU)
多核处理器:一个 CPU 芯片中,有多个独立处理单元。但因为它们整合紧密,可以共享一些资源。
7、超级计算机(多个 CPU)
在一台计算机中,用无数个 CPU,做怪兽级的复杂运算,如模拟宇宙形成。
第十课 早期的编程方式
1、早期,程序如何进入计算机
程序必须人为地输入计算机。早期,电脑无内存的概念,人们通过打孔纸卡等物理手段,输入数据(数字),进入计算机。
2、早期计算机的编程
打孔纸卡/纸带:在纸卡上打孔,用读卡器读取连通电路,进行编程。原因,穿孔纸卡便宜、可靠也易懂。62500 张纸卡=5MB 数据
插线板:通过插拔线路的方式,改变器件之间的连接方式,进行编程。
面板开关(1980s 前):通过拨动面板上的开关,进行编程。输入二进制操作码,按存储按钮,推进至下一个内存位,直至操作完内存,按运行键执行程序。(内存式电脑)
3、现代计算机基础结构——冯诺依曼计算机
冯诺依曼计算机的标志是,一个 处理器(有算术逻辑单元) + 数据寄存器 + 指令寄存器 + 指令地址寄存器 + 内存
第十一课 编程语言发展史
0、概念梳理
伪代码:用自然语言(中文、英语等)对程序的高层次描述,称为“伪代码”
汇编器:用于将汇编语言装换成机器语言。一条汇编语句对应一条机器指令。
助记符(汇编器):
软件
1、早期二进制写代码
先前都是硬件层面的编程,硬件编程非常麻烦,所以程序员想要一种更通用的编程方法,就是软件。
早期,人们先在纸上写伪代码,用"操作码表"把伪代码转成二进制机器码,翻译完成后,程序可以喂入计算机并运行。
2、汇编器&助记符
背景:1940~1950s,程序员开发出一种新语言, 更可读 更高层次(汇编码)。每个操作码分配一个简单名字,叫"助记符"。但计算机不能读懂“助记符”,因此人们写了二进制程序“汇编器"来帮忙 eg:LOAD_A xxxx
作用:汇编器读取用"汇编语言"写的程序,然后转成"机器码"。
3、最早高级编程语言“A-0”
汇编只是修饰了一下机器码,一般来说,一条汇编指令对应一条机器指令,所以汇编码和底层硬件的连接很紧密,汇编器仍然强迫程序员思考底层逻辑。
1950s,为释放超算潜力,葛丽丝·霍普博士,设计了一个高级编程语言,叫 "Arithmetic Language Version 0",一行高级编程语言 可以转成几十条二进制指令。但由于当时人们认为,计算机只能做计算,而不能做程序,A-0 未被广泛使用。
过程:高级编程语言→编译器→汇编码/机器码
4、开始广泛应用的高级编程语言 FORTRAN
1957 年由 IBM1957 年发布,平均来说,FORTRAN 写的程序,比等同的手写汇编代码短 20 倍,FORTRAN 编译器会把代码转成机器码。
但它只能运行于一种电脑中。
5、通用编程语言——COBOL
1959 年,研发可以在不同机器上通用编程语言。
最后研发出一门高级语言:"普通面向商业语言",简称 COBOL
每个计算架构需要一个 COBOL 编译器,不管是什么电脑都可以运行相同的代码,得到相同结果。
6、现代编程语言:1960s-2000
1960s 起,编程语言设计进入黄金时代。
1960:LGOL, LISP 和 BASIC 等语言
70 年代有:Pascal,C 和 Smalltalk
80 年代有:C++,Objective-C 和 Perl
90 年代有:Python,Ruby 和 Java
7、安全漏洞&补丁由来:
在 1940 年代,是用打孔纸带进行的。
但程序出现了问题(也就是漏洞),为了节约时间,只能贴上胶带也就是打补丁来填补空隙,漏洞和补丁因此得名。
第十二课 编程基础-语句和函数
1、变量、赋值语句
如a=5 ,其中a为可赋值的量,叫做变量。把数字 5 放a里面.这叫"赋值语句",即把一个值赋给一个变量
2、if判断
可以想成是 "如果 X 为真,那么执行 Y,反之,则不执行Y",if语句就像岔路口,走哪条路取决于条件的真假。
3、while循环
当满足条件时进入循环,进入循环后,当条件不满足时,跳出循环。
4、for循环
for循环不判断条件,判断次数,会循环特定次数,不判断条件。for 的特点是,每次结束, i 会 +1
5、函数
当一个代码很常用的时候,我们把它包装成一个函数(也叫方法或者子程序),其他地方想用这个代码,只需要写函数名即可。
第13课 算法入门
0、基本慨念
算法:解决问题的基本步骤
1、选择排序
数组:一组数据
选择排序的复杂度为O(n²)
2、大O表示法
大O表示法(算法)的复杂度:算法的输入大小和运行步骤之间的关系,来表示运行速度的量级
3、归并排序
归并排序的算法复杂度为O(n*log n),n是需要比较+合并的次数,和数组大小成正比,log n是合并步骤所需要的的次数,归并排序比选择排序更有效率
4、Dijkstra算法
一开始复杂度为O(n²),后来复杂度为O(nlog n +I),在下图中,n表示节点数,I表示有多少条线。
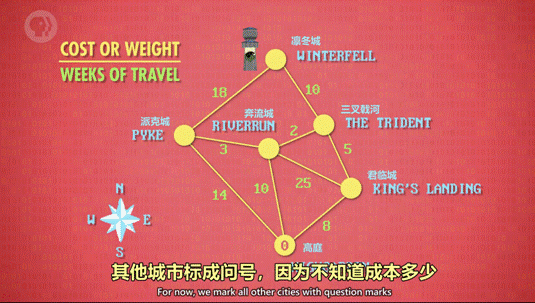
第十四集 数据结构
1、数组 下标
数组(Array),也叫列表(list)或向量(Vector),是一种数据结构。为了拿出数组中某个值,我们要指定一个下标(index),大多数编程语言里,数组下标都从 0 开始,用方括号 [ ] 代表访问数组。注意:很容易混淆 "数组中第 5 个数" 和 "数组下标为 5 的数",数组下标为5的数是数组里面的第6个数
2、字符串
即字母 数字 标点等组成的数组,字符串在内存里以0结尾。
3、矩阵
可以把矩阵看成数组的数组
4、结构体
把几个有关系的变量存在一起叫做结构体
5、指针
指针是一种特殊变量,指向一个内存地址,因此得名。
6、节点
以指针为变量的结构体叫节点
7、链表
用节点可以做链表,链表是一种灵活数据结构,能存很多个 节点 (node),灵活性是通过每个节点 指向 下一个节点实现的。链表可以是循环的也可以是非循环的,非循环的最后一个指针是0
8、队列
"队列" 就像邮局排队,谁先来就排前面,这叫 先进先出(FIFO——first in first out),可以把"栈"想成一堆松饼,做好一个新松饼,就堆在之前上面,吃的时候,是从最上面开始
9、栈
栈是后进先出(LIFO)
10、树
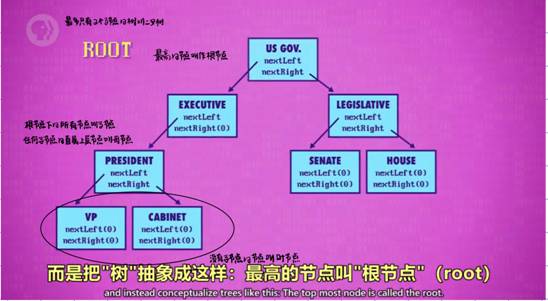
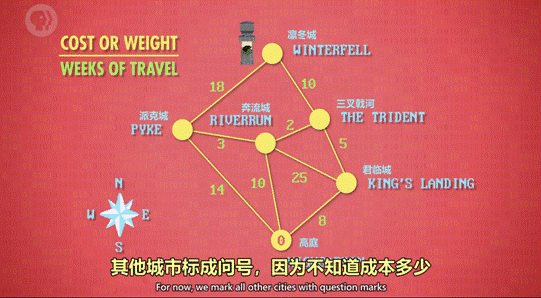
11、图
如果数据随意连接,有循环,我们称之为图,如下图
第15课 阿兰图灵
0.可判定性问题
是否存在一种算法,输入正式逻辑语句 输出准确的"是"或"否"答案?eg:是否存在比其他所有数都小的数
1.阿隆佐邱奇,Lambda算子
美国数学家 阿隆佐·丘奇,开发了一个叫"Lambda 算子"的数学表达系统,证明其不存在。
2.图灵机
只要有足够的规则,状态和纸带,图灵机可以解决一切计算问题。和图灵机一样完备,叫做图灵完备。
3.停机问题
证明图灵机不能解决所有问题。
4.图灵测试
向人和机器同时发信息,收到的回答无法判断哪个是人,哪个是计算机,则计算机达到了智能程度。
第16课 软件工程
1、对象
当任务庞大,函数太多,我们需要把函数打包成层级,把相关代码都放一起,打包成对象。对象可以包括其他对象,函数和变量。把函数打包成对象的思想叫做“面向对象编程”,面向对象的核心是隐藏复杂度,选择性的公布功能。
3、API
当团队接收到子团队编写的对象时,需要文档和程序编程接口(API)来帮助合作。API控制哪些函数和数据让外部访问,哪些仅供内部。
4、集成开发环境(IDE)
程序员用来专门写代码的工具 integrated development environment
6、调试(debug)
IDE帮你检查错误,并提供信息,帮你解决问题,这个过程叫调试
7、文档与注释
文档一般放在一个叫做README的文件里,文档也可以直接写成“注释”,放在源代码里,注释是标记过的一段文字,编译代码时,注释会被忽略。注释的唯一作用是帮助开发者理解代码。
8、版本控制
版本控制,又称源代码管理。大型软件公司会把会把代码放到一个中心服务器上,叫"代码仓库",程序员可以把想修改的代码借出,修改后再提交回代码仓库。版本控制可以跟踪所有变化,如果发现bug,全部或部分代码,可以"回滚"到之前的稳定版。
9、质量控制
测试可以统称“质量保证测试”(QA),作用是找bug
10、beta alpha
beta版软件,即是软件接近完成,但没有完全被测试过,公司有时会向公众发布beta版,以帮助发现问题。alpha是beta前的版本,一般很粗糙,只在内部测试
第17课 集成电路与摩尔定律(硬件的发展)
1.分立元件与数字暴政
一开始,计算机都有独立组件构成,叫"分立元件" , 然后不同组件再用线连在一起,这会导致计算机的构成很复杂,这个问题叫做数字暴政。
2.集成电路与仙童半导体
封装复杂性:与其把多个独立部件用电线连起来,拼装出计算机,不如把多个组件包在一起,变成一个新的独立组件。这种新的独立组件就叫集成电路(IC),仙童半导体(用硅做成)让集成电路变成了现实。为了不用焊接或用一大堆线,发明了印刷电路板(PCB),他通过蚀刻金属线的方式把零件连接到一起
3.光刻0421
即用光把复杂图案印到材料上。我们把一片薄片状的硅叫做晶圆,通过一系列生产步骤,将晶圆表面薄膜的特定部分除去的工艺叫做光刻。
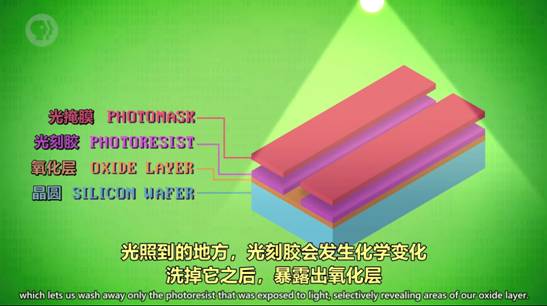
光刻组件示意图

光刻成品示意图
4.摩尔定律
每两年左右,得益于材料和制造技术的发展 ,同样大小的空间,能塞进两倍数量的晶体管。
IT定律之计算机行业发展三大规律
1.摩尔定律(Moore’s Law)
微处理器的速度每18个月翻一番每18个月计算机等IT产品的性能会翻一番;或者说相同的性能的计算机等IT产品,每18个月价钱会降一半。
2.安迪-比尔定律(Andy and Bill’s Law)
比尔要拿走安迪所给的(What Andy gives,Bill takes away. )计算机工业是由软件更新带动硬件更新的。
软件的开发和发展,令使用软件的设备需要更高的性能和速度,从而推动了硬件技术的不断更新和升级。
3.反摩尔定律(Reverse Moore’s Law)
一个IT公司如果今天和18个月前卖掉同样多的、同样的产品,它的营业额就要降低一半。
反摩尔定律的作用下要求所有的硬件设备公司必须赶上摩尔定律规定的更新速度,否则将面临着亏损或者被淘汰的危险
5.进一步小型化会碰到的问题
1、由于光的波长限制,精度已到极限。 --所以科学家在研制波长更短的光源,投射更小的形状。
2、量子隧穿效应:当晶体管非常小,电极之间可能只距离几个原子,电子会跳过间隙,会产生漏电问题
第18课 操作系统
1.操作系统(OS)
操作系统也是一种程序,不过它有操作硬件的特殊权限,可以运行和管理其他程序。
2. 批处理
一个程序运行后会自动运行下一个程序。
3.外部设备
和计算机连着的其他设备,如打印机。
4.设备驱动程序
为了使所写程序和不同类型的电脑兼容,我们需要操作系统充当软件和硬件之间的媒介,更具体地说,操作系统提供程序编程接口(API)来抽象硬件,叫“设备驱动程序”。程序员可以用标准化机制,和输入输出硬件(I/O)交互,
5.多任务处理
操作系统能使多个程序在单个CPU上同时进行的能力,叫做“多任务处理”
6.虚拟内存
多程序处理带来了一个程序所占用内存可能不连续的问题,导致程序员难以追踪一个程序,为了解决这个问题操作系统会把内存地址“虚拟化”,这叫“虚拟内存”。
程序可以假定内存总是从地址0开始,简单又一致,而实际物理地址,被操作系统隐藏和抽象了。
对程序而言,只能看到从0开始的虚拟地址,而操作系统会自动处理虚拟内存与实际内存的映射。
7.动态内存分配
虚拟内存的机制使程序的内存大小可以灵活增减,叫做“动态内存分配”,对程序来说,内存看上去是连续的(程序只能看到“虚拟内存”)。
8.内存保护
给每个程序分配单独的内存,那当这个程序出现混乱时,它不会影响到其他程序的内存,同时也能有效地防止恶意程序篡改其他程序,这叫做内存保护。
9.多用户分时操作系统(Multics)
用来处理多用户同时使用一台计算机的情况,即每个用户只能用一小部分处理器,内存等,
10.Unix
把操作系统分成两个部分,一个是操作系统的核心部分,如内存管理,多任务和输入/输出处理,这叫做“内核”,第二部分是一堆有用的工具,比如程序和运行库。
第19课 内存和储存介质(存储技术的发展)
1.纸卡 纸带
问题:读取慢 难修改 难存临时值
2.延迟线存储器
利用线的延迟在线里存储数据,又叫顺序存储器或者循环存储器。
存在问题:1 不能随意调出数据
2 难以增加内存密度
3.磁芯
利用电磁感应原理
问题 成本高
4.磁带
问题 访问速度慢
5.磁鼓
与磁带相似
6.硬盘
与磁带相似
7.内存层次结构
在计算机中,高速昂贵和低速便宜的内存混合使用以取得一个平衡
8.软盘
除了磁盘是软的,其他都和硬盘一样,好处是便携,但已被淘汰
9.光盘
原理:光盘表面有很多小坑,造成光的不同反射,光学传感器会捕获到,并解码为 1 和 0
10.固定硬盘(SSD)
里面是集成电路
第 20 课 文件系统
0.为什么要采用文件格式:
可以随便存文件数据,但按格式存会更方便
1. TXT 文本文件
用ASCII解码
2.WAV 音频文件
记录的是振幅

元数据存在文件开头,在实际数据前面,因此也叫文件头(Header)
上图为 音频文件: WAV 文件具体数据示意图
前44位为Header表明文件格式,转码方式等信息,后面DATA部分才是真正的文件数据(二进制形式)
3. BMP 图片文件:
记录每个像素的红绿蓝 RGB 值
4.目录文件:
用来解决多文件问题,存其他文件的信息,比如开头,结尾,创建时间等
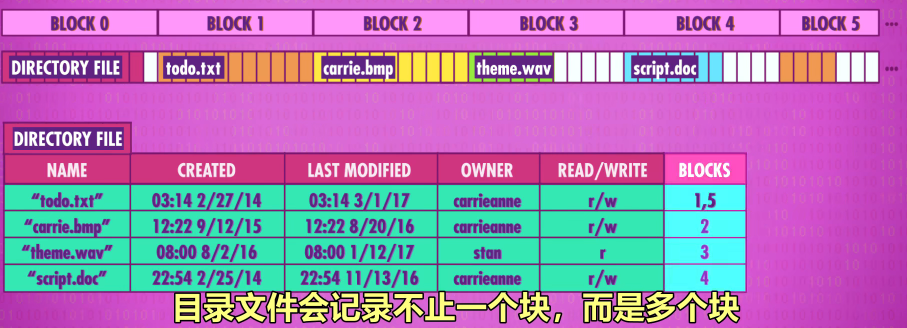
5.平面文件系统 - Flat File System
文件都在同一个层次,早期空间小,只有十几个文件,平面系统够用
删除数据时,只删除了directory中的引用,实际内存中对应的块中并未删除(还存在,可被恢复),下次再次向那一个块中写入数据时进行的是覆盖操作
6.解决文件紧密的排序造成的问题
-
把空间划分成一块块
-
文件拆分存在多个块里
7.碎片整理
文件的增删改查会不可避免的造成文件散落在各个块里,如果是磁带这样的存储介质就会造成 问题,所以需要碎片整理——计算机把文件内容调换位置
8.分层文件系统 - Hierarchical File System:
有不同文件夹,文件夹可以层层嵌套

第21课 压缩
0.压缩的好处
能存更多文件,传输也更快
1. 游程编码 Run-Length Encoding
适合经常出现相同值的文件,以吃豆人游戏为例:



2. 无损压缩 Lossless compression
没有损失任何数据的压缩。
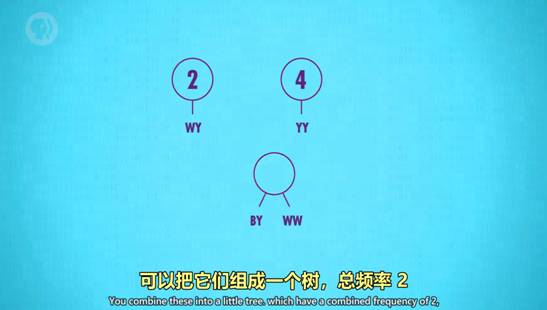
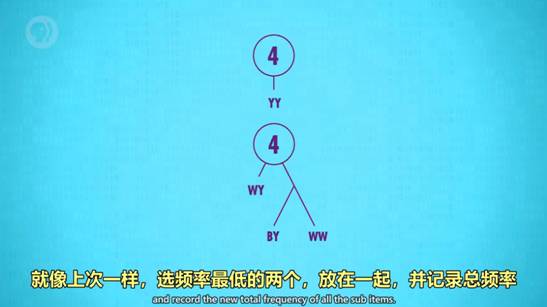
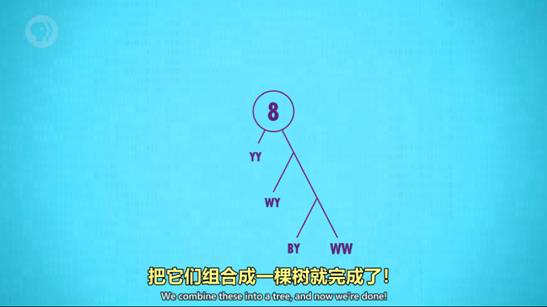
3. 霍夫曼树 Huffman Tree和字典编码 Dictionary coders
一种高效的编码模式,以压缩图片为例



4. 感知编码 Perceptual coding和有损压缩 jpeg 格式
删掉人类无法感知的数据的有损压缩方法,叫做“感知编码”,如音频文件,人类听不到超声波,所以可以舍去,MP3就是音频的一种压缩形式。
有损压缩的一个例子就是jpeg模式,如图:



5. 时间冗余 Temporal redundancy
一个视频由很多图片构成,其中很多图片的背景一样,这就构成了时间冗余,很多视频编码格式,只存变化的部分。进阶的视频压缩模式会找到帧与帧的相似性,然后打补丁,MPEG-4 是视频压缩的常见标准。
第 22 课 命令行界面
1. 人机交互 (Human-Computer Interaction)发展史
计算机早期同时输入程序和数据(用纸卡/纸带)
运行开始直到结束,中间没有人类进行操作,
原因是计算机很贵,不能等人类慢慢输入,执行完结果打印到纸上 (02:34)
到1950年代,计算机足够便宜+快,人类和计算机交互式操作变得可行
为了让人类输入到计算机,改造之前就有的打字机,变成电传打字机 (02:44~05:38)
到1970年代末,屏幕成本足够低,屏幕代替电传打字机,屏幕成为标配 (07:24)
2. 人机交互工具的变化
1 早期输出数据是打印到纸上,而输入是用纸卡/纸带一次性把程序和数据都给进去
2 QWERTY 打字机的发展
3 电传打字机 Teletype machine
作用:用于发电报,使两人可以远距离沟通
3. 命令行界面 Command line interface
输入命令,计算机会给予回应
第 23课 屏幕与 2D 图形显示
1.PDP-1 计算机、键盘和显示器分开,屏幕显示临时值
2. 阴极射线管 Cathode Ray Tube (CRT)
CRT 有两种绘图方式:
矢量扫描 Vector Scanning

光栅扫描 Raster Scanning

3.02:14 液晶显示器 Liquid Crystal Displays (LCD),像素 (Pixel)
随着显示技术的发展,出现了LCD,LCD 也用光栅扫描。在屏幕上显示的清晰的点,叫"像素"
4.03:32 字符生成器 Character generator,
相比于像素,为了减少内存,人们更喜欢使用字符,计算机需要额外硬件,来从内存读取字符,转换成光栅图形 \N 这样才能显示到屏幕上个硬件叫 "字符生成器",基本算是第一代显卡。它内部有一小块只读存储器,简称 ROM,存着每个字符的图形,叫"点阵图案",
5. 屏幕缓冲区 Screen buffer
为了显示,"字符生成器" 会访问内存中一块特殊区域 这块区域专为图形保留,叫 屏幕缓冲区,程序想显示文字时,修改这块区域里的值就行。
6.05:09 矢量命令画图
概念非常简单:所有东西都由线组成,矢量指令可以画出线,把许多矢量指令存在硬盘上,就能画出很多由线组成的复杂图形。
7.06:34 Sketchpad, 光笔 (Light pen),位图显示和画矩形
Sketchpad ,一个交互式图形界面,用途是计算机辅助设计 (CAD)。
光笔,就是一个有线连着电脑的触控笔,有了它们,用户可以画出很完美的线条并进行缩放等操作。
位图显示,内存中的位对应着屏幕上显示的像素。
想画更复杂的图形,如画矩形,我们需要四个值,起点的x y坐标,高度和宽度。
第 24 课 冷战和消费主义
本课概括:政府和消费者推动了计算机的发展
早期靠政府资金,让技术发展到足够商用,然后消费者购买商用产品继续推动产品发展
冷战导致美国往计算机领域投入大量资源 (00:00~01:43)
范内瓦·布什 预见了计算机的潜力,提出假想机器 Memex
帮助建立 国家科学基金会,给科学研究提供资金 (01:43~03:43)
1950 年代消费者开始买晶体管设备,收音机大卖
日本取得晶体管授权后,索尼做了晶体管收音机,为日本半导体行业崛起埋下种子 (03:43~04:29)
苏联 1961 年把宇航员加加林送上太空,导致美国提出登月
NASA 预算大大增加,用集成电路来制作登月计算机 (04:29~06:27)
集成电路的发展实际上是由军事应用大大推进的,阿波罗登月毕竟只有 17 次
美国造超级计算机进一步推进集成电路 (04:29~07:11)
美国半导体行业一开始靠政府高利润合同活着,忽略消费者市场,1970年代冷战渐消,行业开始衰败
很多公司倒闭,英特尔转型处理器 (07:11~08:23)
第 25 课 个人计算机革命
本集概括:继续讲计算机发展史
00:18 1970年代初成本下降,个人计算机变得可行
RAM:random-access memory 随机访问存储器
ROM:read-only memory 只读存储器
01:51 Altair 8800 第一台取得商业成功的个人计算机
02:32 比尔·盖茨 和 保罗·艾伦写 BASIC 解释器,解释器和编译器类似,区别是解释器运行时转换,而编译器提前转换
03:45 乔布斯提议卖组装好的计算机,Apple-I 诞生
04:40 1977年出现3款开箱即用计算机:
"Apple-II","TRS-80 Model I","Commodore PET 2001"
06:26 IBM 意识到个人计算机市场
IBM PC 发布,采用开放架构,兼容的机器都叫 IBM Compatible (IBM 兼容)
生态系统产生雪球效应:
因为用户多,软硬件开发人员更愿意花精力在这个平台
因为软硬件多,用户也更乐意买 "IBM 兼容" 的计算机
08:44 苹果选封闭架构,一切都自己来,只有苹果在非 "IBM 兼容" 下保持了足够市场份额
第 26 集:图形用户界面 (GUI)
——GUI(graphical user interface)是“事件驱动编程”,代码可以在任意时间执行以响应事件,而不像传统代码一样自上而下。
01:10 图形界面先驱:道格拉斯·恩格尔巴特(Douglas Engelbart)——设想计算机成为未来知识性员工应对问题的工具,并发明了鼠标。
03:20 1970年成立 帕洛阿尔托研究中心(Palo Alto Research Center)
03:29 1973年完成 Xerox Alto(施乐奥托) 计算机——创立了桌面,窗口等计算机概念
06:38 1981年的 Xerox Star system(施乐之星系统)
创建了文档概念
07:45 所见即所得 WYSIWYG(what you see is what you get)——
施乐打印出来的东西和计算机上一样,并发明了剪切cut 复制copy 黏贴paste等计算机概念
08:18 史蒂夫·乔布斯去施乐参观
09:15 1983年推出 Apple Lisa
09:31 1984年推出 Macintosh 成功
10:12 1985年推出 Windows 1.0,之后出到 3.1
10:43 1995年推出 Windows 95 提供新的图形界面,并有Mac没有的新功能,如多任务和受保护内存
11:08 1995年微软做失败的 Microsoft Bob——类似于房子的设计
第 27 集:3D 图形
1.线框渲染 Wireframe Rendering
有图形算法 负责把3D坐标"拍平"显示到2D屏幕上,这叫3D投影(包括正交投影和透视投影),所有的点都从3D转成2D后,就可以用画2D线段的函数来连接这些点,这叫线框渲染,
2.网格 Mesh
如果我们需要画比立方体复杂的图形,三角形比线段更好,在3D图形学中我们叫三角形"多边形"(Polygons),一堆多边形的集合叫 网格,网格越密,表面越光滑,细节越多,
3.三角形更常用因为能定义唯一的平面
4.扫描线渲染 Scanline Rendering——填充图形的经典算法
填充的速度叫做填充速率
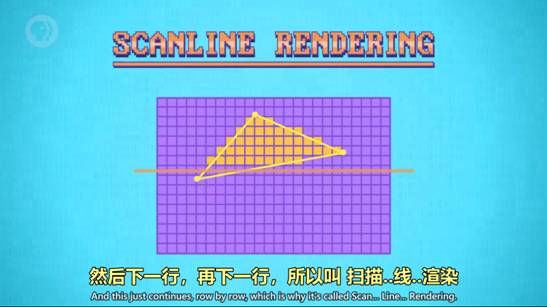
抗锯齿——边缘羽化,如果像素在多边形内部,就直接涂颜色,如果多边形划过像素,颜色就浅一些

5.遮挡 Occlusion
用排序算法,从远到近排列,然后从远到近渲染,这叫画家算法
6.深度缓冲 Z Buffering
另一种画遮挡的方法,简而言之,Z-buffering 算法会记录场景中每个像素和摄像机的距离,在内存里存一个数字矩阵,首先,每个像素的距离被初始化为"无限大",然后 Z-buffering 从列表里第一个多边形开始处理,也就是A,它和扫描线算法逻辑相同,但不是给像素填充颜色,而是把多边形的距离和 Z-Buffer 里的距离进行对比,它总是记录更低的值,因为没对多边形排序,所以后处理的多边形并不总会覆盖前面的。
07:45 Z Fighting 错误
采用深度缓冲算法,哪个图形在前将会变化
07:51 背面剔除 Back Face Culling
由于游戏角色的头部或地面,只能看到朝外的一面,所以为了节省处理时间,会忽略多边形背面,这很好,但有个bug是 如果进入模型内部往外看,头部和地面会消失
08:53 表面法线 Surface Normal
在3D图形上任取一小个区域,它面对的方向叫“表面法线”
09:33 平面着色 Flat Shading
基本的照明算法,缺点是使多边形边界明显,看上去不光滑
09:43 高洛德着色 Gouraud shading, 冯氏着色 Phong Shading
不只用一种颜色上色
10:06 纹理映射 Texture Mapping
纹理在图形学中指外观,纹理有多种算法来达到花哨效果,最经典的是纹理映射。

纹理映射示意图
11:24 图形处理单元 GPU, Graphics Processing Unit
方便并行处理多个图形,并把图形分成一个个小块来处理。
(28-30:介绍网络的发展和支撑他们的基础原理和技术)
第 28 集:计算机网络
1.局域网 Local Area Networks - LAN
计算机近距离构成的小型网络,叫局域网(LAN),以太网是经典的局域网
2.媒体访问控制地址 Media Access Control address - MAC
用于确认局域网和WiFi传输的对象
3.载波侦听多路访问 Carrier Sense Multiple Access - CSMA
多台电脑共享一个传输媒介,叫做载波侦听多路访问,共享媒介又称载体,如WiFi的载体是空气,以太网的载体是电线。载体传输数据的速度叫带宽,
4.指数退避 Exponential Backoff
当多台计算机同时想要传输数据时,就会发生冲突,当计算机检测到冲突 就会在重传之前等待一小段时间,,这一段时间包括固定时间+随机时间,再次堵塞时固定时间将会指数级增加(2s 4s 8s 16s ...),这叫做指数退避。
5.冲突域 Collision Domain
载体和其中的设备总称为“冲突域”,为了避免冲突,可以用交换器
交换机会记录一个列表(写着那个mac地址在那个网络)

07:08 电路交换 Circuit Switching
缺点:不灵活且数量昂贵
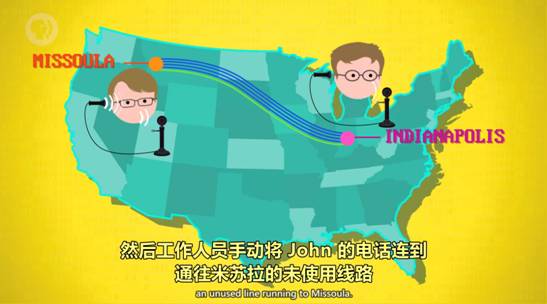
6. 报文交换 Message Switching
报文的具体格式简称IP,每一个电脑都会有一个IP地址
好处,可以用不同路由,通信更可靠也更能容错。
坏处,当报文比较大的时候,会堵塞线路。解决方法是 将大报文分成很多小块,叫"数据包",来进行运输,这叫“分组交换”。路由器会平衡与其他路由器之间的负载 以确保传输可以快速可靠,这叫"阻塞控制"
消息沿着路由跳转的次数 叫"跳数"(hop count),看到哪条线路的跳数很高,说明出了故障,这叫跳数限制(hop limit)。
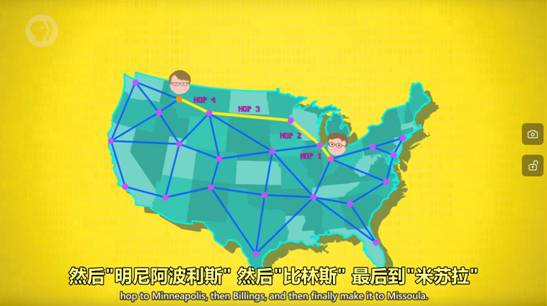
通过协议解决数据包的乱序问题(详见29)
数百万台计算机在网络上不断交换数据 瓶颈的出现和消失是毫秒级的
路由器会平衡与其他路由器之间的负载 ,以确保传输可以快速可靠,这叫"阻塞控制"
有时,同一个报文的多个数据包会经过不同线路,到达顺序可能会不一样,这对一些软件是个问题
幸运的是,在 IP 之上还有其他协议,比如 TCP/IP, 可以解决乱序问题
将数据拆分成多个小数据包,然后通过灵活的路由传递 非常高效且可容错,如今互联网就是这么运行的 这叫"分组交换"
好处是 它是去中心化的。如今,全球的路由器协同工作,找出最高效的线路
用各种标准协议运输数据比如 "因特网控制消息协议"(ICMP --Internet Control Message Protocol ) 和 "边界网关协议"(BGP-- Border Gateway Protocol)
第 29 集:互联网
1.电脑连接互联网的过程
你所用的电脑首先要连接到局域网,家里WiFi路由器连着的所有设备,组成了局域网,局域网再连到广域网(WAN),广域网的路由器一般属于你的互联网服务提供商(ISP),再连更大的WAN,往复几次,最后连到互联网主干。
2.IP - 互联网协议 - Internet Protocol
IP负责把数据包送到正确的计算机
3. UDP - 用户数据报协议 - User Datagram Protocol
UDP负责把数据包传送到正确的程序,有端口号(哪个程序),校验和(数据是否损坏)
4.校验和 - Checksum
UDP校验和只有16位,超过这个数,弃高位。
假设 UDP 数据包里原始数据是 89 111 33 32 58 41。在发送数据包前,电脑会把所有数据加在一起,算出"校验和" 89+111+33+... 以此类推
UDP 中,"校验和"以 16 如果算出来的和,超过了 16 位能表示的最大值 , 高位数会被扔掉,保留低位位形式存储 (就是16个0或1)
当接收方电脑收到这个数据包 它会重复这个步骤:把所有数据加在一起,89+111+33... 以此类推
如果结果和头部中的校验和一致, 代表一切正常;如果不一致,数据肯定坏掉了 也许传输时碰到了功率波动,或电缆出故障了
不幸的是,UDP 不提供数据修复或数据重发的机制,接收方知道数据损坏后,一般只是扔掉
而且,UDP 无法得知数据包是否到达. 因为UDP 又简单又快 用 UDP 可以做视频播放等功能
5.TCP - 传输控制协议 - Transmission Control Protocol
如果要控制所有数据必须到达,就用传输控制协议
TCP的特点
1.TCP 数据包有序号:序号使接收方可以把数据包排成正确顺序,即使到达时间不同
2 要求接收方收到数据包并且"校验和"检查无误后(数据没有损坏)后发送确认码(ACK),代表收到了
确认码的成功率和来回时间可以用来推测网络的拥堵程度,TCP可以根据这个调整传输率。
由于这个特点,TCP对时间要求高的程序不适用
发送方:假设这次发出去之后,没收到确认码 那么肯定哪里错了,如果过了一定时间还没收到确认码 \N 发送方会再发一次
注意:数据包可能的确到了,只是确认码延误了很久,或传输中丢失了
但这没有关系,因为收件方有序列号,如果收到重复的数据包就删掉
还有,TCP 不是只能一个包一个包发:可以同时发多个数据包,收多个确认码。这大大增加了效率,不用浪费时间等确认码
确认码的成功率和来回时间,可以推测网络的拥堵程度:TCP 用这个信息,调整同时发包数量,解决拥堵问题由上可得:1.TCP 可以处理乱序 2.处理丢失数据包的问题,丢了就重发 3.可以根据拥挤情况自动调整传输率(发送多少文件)
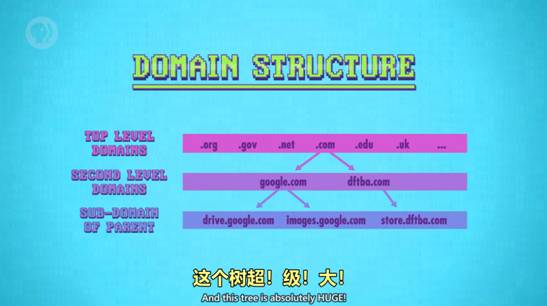
6 DNS - 域名系统 - Domain Name System
计算机访问网站时需要两样,IP地址和端口号,但记数字很难,所以互联网通过域名系统把域名和IP地址一一对应。域名系统是树状结构
10:47 OSI - 开放式系统互联通信参考模型 - Open System Interconnection

"物理层":线路里的电信号,以及无线网络里的无线信号
"数据链路层":媒体访问控制地址(MAC),碰撞检测,指数退避,以及其他一些底层协议(负责操控"物理层",)
"网络层":负责各种报文交换和路由
"传输层": UDP 和 TCP 。。。
"会话层":使用 TCP 和 UDP 来创建连接,传递信息,然后关掉连接
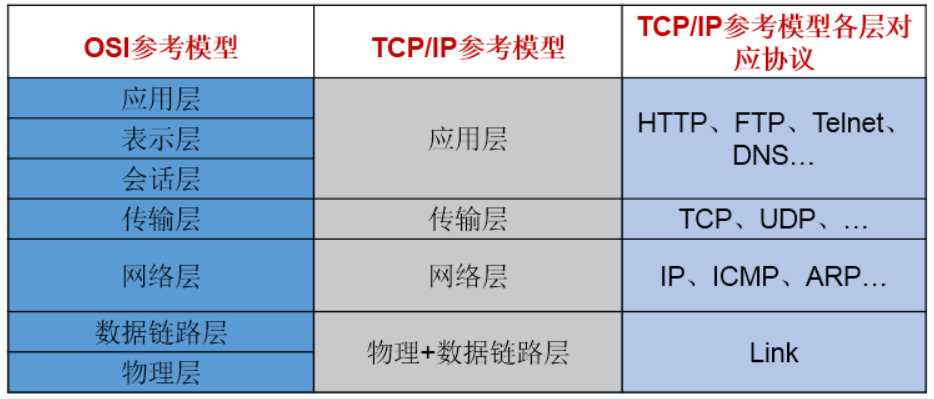
上图中,TCP/IP协议中的四层分别是应用层、传输层、网络层和链路层,每层分别负责不同的通信功能。
-
链路层:链路层是用于定义物理传输通道,通常是对某些网络连接设备的驱动协议,例如针对光纤、网线提供的驱动。
-
网络层:涉及寻址和路由器选择(定义了基于IP协议的逻辑地址;连接不同的媒介类型;选择数据通过网络的最佳路径)
网络层的主要协议有IP(Internet protocol:IPv4,IPv6)、CMP协议(Internet Control Message Protocol,互联网控制报文协议)、
IGMP(Internet Group Management Protocol,互联网组管理协议)、ARP(Address Resolution Protocol,地址解析协议)和
RARP(Reverse Address Resolution Protocol,反地址解析协议)等
-
运输层:传输层的基本功能是为两台主机间的应用程序提供端到端的通信。
传输层从应用层接受数据,并且在必要的时候把它分成较小的单元,传递给网络层,并确保到达对方的各段信息正确无误
主要使网络程序进行通信,在进行网络通信时,可以采用TCP协议,也可以采用UDP协议。
-
应用层:提供应用程序的网络接口;主要负责应用程序的协议,例如HTTP协议、FTP协议等。
第 30 集:万维网(WWW)
1.基本单位
万维网在互联网上运行,它的基本单位是页面
2.超链接 Hyperlinks
点超链接可以去到另一个页面,文字超链接又叫超文本
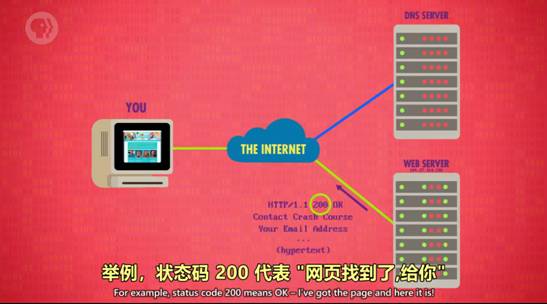
超链接工作过程中示意
3.状态码
状态码代表所访问网页的状态
4.URL - 统一资源定位器 - Uniform Resource Locator
网页的唯一网址
5.HTTP - 超文本传输协议 - HyperText Transfer Protocol
6.HTML - 超文本标记语言 - HyperText Markup Language
7.万维网发展史
1 第一个浏览器和服务器是 Tim Berners-Lee 花了 2 个月在 CERN 写的
2 1991年万维网就此诞生
3 Jerry 和 David 的万维网指南 后来改名成 Yahoo
4 搜索引擎 JumpStation
(包括爬虫 索引 用法)
5 搜索引擎 Google
改进排序方法,按照链接指向的多少来排序
8.网络中立性
平等地对待每个数据包
第 31 集:计算机安全
1. 保密性, 完整性, 可用性 Secrecy, Integrity, Availability
计算机为了安全,要实现三性
保密性:只有有权限的人,才能读取计算机系统和数据
完整性:只有有权限的人,才能使用和修改系统和数据
可用性:有权限的人,可以随时访问计算机系统和数据
2.Threat Model 威胁模型
为了实现这三个目标,安全专家会从 \N 抽象层面想象"敌人"可能是谁,这叫"威胁模型分析",模型会对攻击者有个大致描述:\N 能力如何,目标可能是什么,可能用什么手段,攻击手段又叫"攻击矢量","威胁模型分析"让你能为特定情境做准备,不被可能的攻击手段数量所淹没。
很多安全问题可以总结成两个:你是谁?你能访问什么?
3.身份验证 (Authentication) 的三种方式:
What you know, 你知道什么 ex、用户名和密码
What you have, 你有什么
What you are, 你是什么
4.访问控制 Access Control
Bell LaPadula model 不能向上读取,不能向下写入
5.安全内核
安全内核应该有一组尽可能少的操作系统软件,和尽量少的代码。
6.独立安全检查和质量验证
最有效的验证手段
7.隔离 Isolation, 沙盒 Sandbox
优秀的开发人员,应该计划当程序被攻破后,\N如何限制损害,控制损害的最大程度,并且不让它危害到计算机上其他东西,这叫"隔离"。要实现隔离,我们可以"沙盒"程序,这好比把生气的小孩放在沙箱里,他们只能摧毁自己的沙堡,不会影响到其他孩子,方法是给每个程序独有的内存块,其他程序不能动。一台计算机可以运行多个虚拟机,如果一个程序出错,最糟糕的情况是它自己崩溃,或者搞坏它处于的虚拟机。
第 32 集:黑客与攻击
1.社会工程学 Social Engineering
欺骗别人获得信息,或让人安装易于攻击的系统
2.钓鱼 Phishing
3.假托 Pretexting
4.木马 Trojan Horses
5.NAND镜像 NAND Mirroring
——来避免输错密码后等待
暴力尝试:尝试所有可能的密码,直到进入系统
大多数现代系统会加长等待时间,来抵御这种攻击
如果能物理接触到电脑,可以往内存上接几根线,复制整个内存。
复制之后,暴力尝试密码,直到设备让你等待,这时只要把复制的内容覆盖掉内存。
本质上重置了内存,就不用等待,可以继续尝试密码了。这项方法在 iPhone 5C 上管用
6.漏洞利用 Exploit
7. 缓冲区溢出 Buffer Overflow
——一种常见的漏洞利用
9.边界检查 Bounds Checking和金丝雀
——防止缓冲区溢出的手段,金丝雀,留出一些不用的空间,当空间变少时,说明有攻击者乱来。
10. 代码注入 Code Injection
把代码注入到程序中,造成混乱
11.零日漏洞 Zero Day Vulnerability
当软件制造者不知道软件有新漏洞被发现了,这个漏洞被称为“零日漏洞”
12.计算机蠕虫 Worms
如果有足够多的电脑有漏洞,让恶意程序可以在电脑间互相传播,这种恶意程序叫做蠕虫
13.僵尸网络 Botnet
如果黑客掌握足够多电脑,那他们可以组成“僵尸网络”
可以进行DDoS攻击:Distributed Denial of service 分布式拒绝服务攻击
第 33 集:加密
1.加密 - Encryption,解密 - Decryption
01:11 凯撒加密 Caesar cipher——一种替换加密 Substitution cipher,把字母替换成其他字母
01:59 移位加密 Permutation cipher

列移位加密 Columnar transposition cipher
02:37 德国 Enigma 加密机 一种进阶的替换加密,每一次的映射都不同。
04:54 1977年"数据加密标准" - Data Encryption Standard (DES)
05:24 2001年"高级加密标准" - Advanced Encryption Standard (AES)
2. 密钥交换 - Key exchange




用颜色来举例"单向函数"和"密钥加密"的原理
实例:迪菲-赫尔曼密钥交换 - Diffie-Hellman Key Exchange
用模幂计算来得到秘钥
3. 非对称加密 - Asymmetric encryption
对称加密(Symmetric encryption):以上的例子,双方用一样的秘钥加密和解密信息,叫对称解密。
也可以人们用公钥加密信息,只有有私钥的人能解密,或者反过来,这叫非对称解密。最有名的非对称加密算法是RSA
详见:https://www.cnblogs.com/jfzhu/p/4020928.html
第 34 集:机器学习与人工智能
以区分飞蛾为例
1. 分类 Classification
2.做分类的算法 分类器 Classifier
3.用于分类的值是特征 Feature
4. 特征值+种类叫做标记数据 Labeled data

标记数据
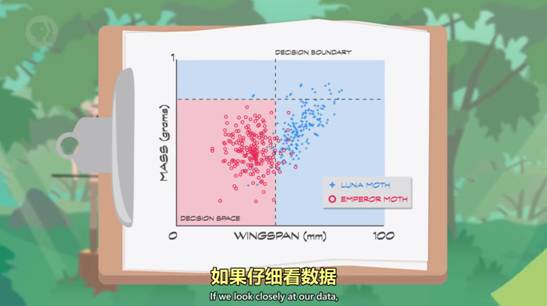
5. 决策边界 Decision boundaries
虚线为决策边界
6.混淆矩阵 Confusion matrix

右下角表为混淆矩阵
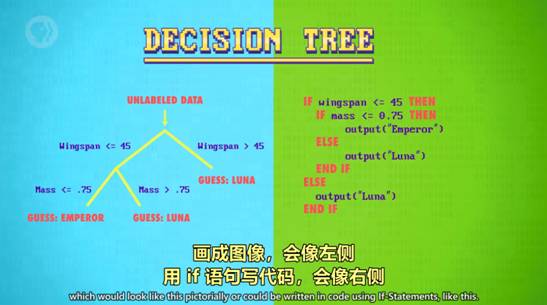
7.03:49 决策树 Decision tree
8.支持向量机 Support Vector Machines
本质上是用任意线段来切分决策空间,不一定是直线。
9.人工神经网络 Artificial Neural Network
不用统计学的算法。模拟人类学习的过程,将数据进行加权求和修正等一系列处理。
10.深度学习 Deep learning
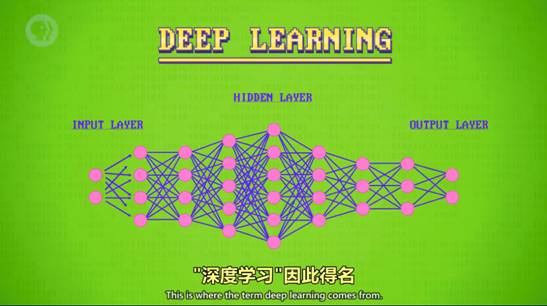
得名原因:有很多的隐藏层
11.弱AI, 窄AI Weak AI, Narrow AI
只能做指定内容的内容
12.强AI Strong AI
通用的,和人一样智能的AI叫做强AI,目前没有人能做到。
14.强化学习 Reinforcement Learning
学习什么管用,什么不管用,自己发现成功的策略,这叫强化学习。
第 35 集:计算机视觉
1.颜色跟踪算法——跟踪一个像素
2. 检测垂直边缘的算法
物体的边缘有多个色素,不适合颜色跟踪算法。要识别边缘,可以判断其两边像素的颜色差异程度
3. 核/过滤器 kernel or filter
——用来检测垂直边缘的算法的数学符号,如下绿色的图。

核或过滤器图示

算法示例
4. 卷积 convolution
把核应用于像素块
5.Prewitt 算子 Prewitt Operators
水平和垂直边缘增强的核叫Prewitt 算子
6. 维奥拉·琼斯 人脸检测 Viola-Jones Face Detection
7.卷积神经网络 Convolutional Neural Networks
用一层层不同的核来识别复杂场景,用脸来举例,先识别边缘,然后形状,器官...直至某一层把所有特征堆积在一起,识别出脸之后,可以进一步用其他算法定位面部标志,如眼睛和眉毛具体位置,从而判断心情等信息
第 36 集:自然语言处理 NLP
1.过程
通过词性 Parts of speech和短语结构规则 Phrase structure rules构建分析树 Parse tree,并结合语言模型 Language Model来实现语音识别 Speech recognition
2.实现原理:
快速傅立叶变换 Fast Fourier Transform,把波形转换成频率
3.音素 Phonemes
构成单词的声音片段
4.语音合成 Speech Synthesis
第 37 集:机器人
1.机器人发展中的例子
02:08 法国吃饭鸭 - Digesting Duck, Canard Digerateur
02:23 土耳其行棋傀儡, 下国际象棋(假的,有人控制)
02:43 第一台计算机控制的机器出现在1940年代晚期,叫数控机器, Computer Numerical Control(CNC)
03:32 1960年 Unimate,第一个商业贩卖的 可编程工业机器人
2.机器人控制的回路
04:08 负反馈回路 negative feedback loop
05:17 比例-积分-导数控制器 Proportional–Integral–Derivative controller PID 控制器
通过控制三个值,比例值——实际值和理想值差多少,积分值——一段时间误差的总和,前两者用来修正错误:导数值(微分值)——期望值和实际值之间的变化率,用来避免未来的错误,这也叫预期控制,来控制进程。
3.机器人三定律 Three Laws of Robotics
——让机器人不要伤害人类
第38课 计算机心理学
0、计算机中用到的心理学原理
社会心理学 认知心理学 行为心理学 感知信息学
1、易用度
指人造物体,比如软件,达到目的的效率有多高
2、颜色强度排序和颜色排序
人类擅长给颜色强度排序,所以颜色强度很适合现实连续值;而人类不擅长给颜色排序,所以如果数据没有顺序,用不同颜色就很合适,如分类数据。
3、分组更好记
信息分块会更好记。分块是指把信息分成更小,更有意义的块,如电话号码分块,界面设计分块。
4、直观功能
直观功能为如何操作物体提供线索,如平板用于推,旋钮用来转,直观功能做得好,用户只需要看一眼就知道怎么搞,而不需要其他东西来说明。ex.门把手让人想拉开门,但如果门需要推开,那这就是个不好的直观功能,不如直接采用平板门来的好。
5、认出VS回想
和直观功能相关的一个心理学概念是认出和回想,这就是选择题比填空题简单的原因。一般来说,用感觉触发记忆会容易得多,比如文字、图片和声音,所以我们用图标表示功能,如垃圾桶表示回收站。但是,让所有菜单选项好找好记,有时候意味着用的时候会慢一些。这与另一个心理学概念冲突:"专业知识”,当你用界面熟悉之后,速度会更快一些,所以 好的界面应该提供多种方法来实现目标,一个好例子是复制粘贴,可以在"编辑"的下拉菜单中找到,也可以用快捷键,两者都不耽误,鱼与熊掌兼得。
6、让机器有一定的情商以及Facebook的研究
我们也希望电脑能有一点情商,能根据用户的状态做出合适地反应,让使用电脑更加愉快。因为情绪会影响日常活动,比如学习,沟通和决策,情感系统会用传感器,录声音,录像(你的脸)以及生物指标,比如出汗和心率,得到的数据和计算模型结合使用,模型会估算用户的情绪,给最好的回应用户。
7、用软件修正注视位
心理学研究也表明,如果想说服,讲课,或引起注意 ,眼神注视非常重要。为此,研究人员开发了计算机视觉和图形软件 来纠正头部和眼睛,看视频的人会觉得对方在直视他们
8、把机器人做得像人
人也喜欢像人的机器人。人机交互,简称HRI,是一个研究人类和计算机交互的领域。

恐怖谷原理
9、开放性问题
计算机该不该对人类说谎等
第 39 集:教育科技
1.通过调速,暂停等技巧,加强学习效率
2.大型开放式在线课程 - Massive Open Online Courses (MOOC)
3.智能辅导系统 - Intelligent Tutoring Systems
4.判断规则 - Production rule
5.域模型 - Domain Model
判断规则和选择算法,组合在一起成为域模型
6.贝叶斯知识追踪 Bayesian knowledge tracing
把学生的知识掌握当成隐藏变量,根据学生答题的正确度,更新学生掌握程度的估算值。具体而言,贝叶斯知识追踪有一组方程,会用这四个概率,更新学生模型,评估其掌握程度。
学生已经学会的概率
瞎猜的概率
失误的概率
做题过程中学会的概率
7.自适应性程序
一种算法,选择适合学生的问题,让学生学。
8.教育数据挖掘 Educational Data Mining
看学生答题时停顿的时间,观察学生停顿和加速视频的时间段,看论坛问题,来评估学生的程度。
第 40 集:奇点,天网,计算机的未来
1.普适计算 Ubiquitous Computing
计算机融入生活的方方面面
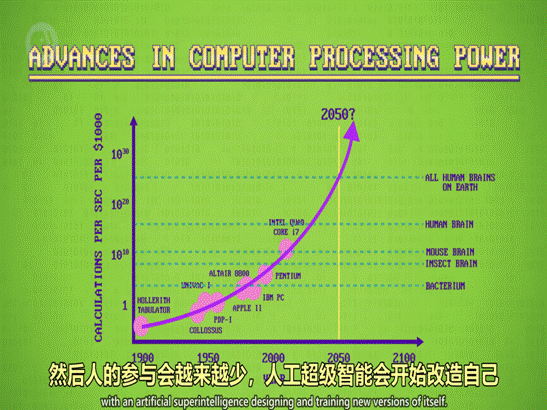
2.奇点 Singularity
——智能科技的失控性发展
3.把工作分为4个象限,讨论自动化带来的影响


 浙公网安备 33010602011771号
浙公网安备 33010602011771号