
List和Dictionary泛型类查找效率存在巨大差异,前段时间亲历了一次。事情的背景是开发一个匹配程序,将书籍(BookID)推荐给网友(UserID),生成今日推荐数据时,有条规则是同一书籍七日内不能推荐给同一网友。
同一书籍七日内不能推荐给同一网友规则的实现是程序不断优化的过程,第一版程序是直接取数据库,根据BookID+UserID查询七日内有无记录,有的话不进行分配。但随着数据量的增大,程序运行时间越来越长,于是开始优化。第一次优化是把所有七日内的数据取出来,放到List<T>中,然后再内存中进行查找,发现这样效率只是稍有提高,但不明显。第二次优化采用了Dictionary<TKey, TValue>,意外的发现效果不是一般的好,程序效率提高了几倍。
下面是伪代码,简化了程序代码,只是为说明List和Dictionary效率的差别,并不具备实际意义。


/// <summary> /// 集合类效率测试 /// </summary> public class SetEfficiencyTest { static List<TestModel> todayList = InitTodayData(); static List<TestModel> historyList = InitHisoryData(); public static void Run() { CodeTimer.Time("ListTest", 1, ListTest); CodeTimer.Time("DictionaryTest", 1, DictionaryTest); } public static void ListTest() { List<TestModel> resultList = todayList.FindAll(re => { if (historyList.Exists(m => m.UserID == re.UserID && m.BookID == re.BookID)) { return false; } return true; }); } public static void DictionaryTest() { Dictionary<int, List<string>> bDic = new Dictionary<int, List<string>>(); foreach (TestModel obj in historyList) { if (!bDic.ContainsKey(obj.UserID)) { bDic.Add(obj.UserID, new List<string>()); } bDic[obj.UserID].Add(obj.BookID); } List<TestModel> resultList = todayList.FindAll(re => { if (bDic.ContainsKey(re.UserID) && bDic[re.UserID].Contains(re.BookID)) { return false; } return true; }); } /// <summary> /// 初始化数据(今日) /// </summary> /// <returns></returns> public static List<TestModel> InitTodayData() { List<TestModel> list = new List<TestModel>(); for (int i = 0; i < 10000; i++) { list.Add(new TestModel() { UserID = i, BookID = i.ToString() }); } return list; } /// <summary> /// 初始化数据(历史) /// </summary> /// <returns></returns> public static List<TestModel> InitHisoryData() { List<TestModel> list = new List<TestModel>(); Random r = new Random(); int loopTimes = 60000; for (int i = 0; i < loopTimes; i++) { list.Add(new TestModel() { UserID = r.Next(0, loopTimes), BookID = i.ToString() }); } return list; } /// <summary> /// 测试实体 /// </summary> public class TestModel { /// <summary> /// 用户ID /// </summary> public int UserID { get; set; } /// <summary> /// 书ID /// </summary> public string BookID { get; set; } } }
输出如下:
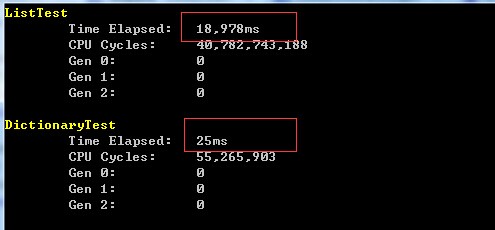
真是想不到,两者效率相差这么多。接下来研究下两者差异巨大的原因。
List<T>.Exists()函数的实现:
public bool Exists(Predicate<T> match) { return this.FindIndex(match) != -1; } public int FindIndex(Predicate<T> match) { return this.FindIndex(0, this._size, match); } public int FindIndex(int startIndex, int count, Predicate<T> match) { if (startIndex > this._size) { ThrowHelper.ThrowArgumentOutOfRangeException(ExceptionArgument.startIndex, ExceptionResource.ArgumentOutOfRange_Index); } if (count < 0 || startIndex > this._size - count) { ThrowHelper.ThrowArgumentOutOfRangeException(ExceptionArgument.count, ExceptionResource.ArgumentOutOfRange_Count); } if (match == null) { ThrowHelper.ThrowArgumentNullException(ExceptionArgument.match); } int num = startIndex + count; for (int i = startIndex; i < num; i++) { if (match(this._items[i])) { return i; } } return -1; }
List<T>.Exists 本质是通过循环查找出该条数据,每一次的调用都会重头循环,所以效率很低。显然,这是不可取的。
Dictionary<TKey, TValue>.ContainsKey()函数的实现:
public bool ContainsKey(TKey key) { return this.FindEntry(key) >= 0; } // System.Collections.Generic.Dictionary<TKey, TValue> private int FindEntry(TKey key) { if (key == null) { ThrowHelper.ThrowArgumentNullException(ExceptionArgument.key); } if (this.buckets != null) { int num = this.comparer.GetHashCode(key) & 2147483647; for (int i = this.buckets[num % this.buckets.Length]; i >= 0; i = this.entries[i].next) { if (this.entries[i].hashCode == num && this.comparer.Equals(this.entries[i].key, key)) { return i; } } } return -1; }
Dictionary<TKey, TValue>.ContainsKey() 内部是通过Hash查找实现的,所以效率比List高出很多。
最后,给出MSDN上的建议:
1.如果需要非常快地添加、删除和查找项目,而且不关心集合中项目的顺序,那么首先应该考虑使用 System.Collections.Generic.Dictionary<TKey, TValue>(或者您正在使用 .NET Framework 1.x,可以考虑 Hashtable)。三个基本操作(添加、删除和包含)都可快速操作,即使集合包含上百万的项目。
2.如果您的使用模式很少需要删除和大量添加,而重要的是保持集合的顺序,那么您仍然可以选择 List<T>。虽然查找速度可能比较慢(因为在搜索目标项目时需要遍历基础数组),但可以保证集合会保持特定的顺序。
3.您可以选择 Queue<T> 实现先进先出 (FIFO) 顺序或 Stack<T> 实现后进先出 (LIFO) 顺序。虽然 Queue<T> 和 Stack<T> 都支持枚举集合中的所有项目,但前者只支持在末尾插入和从开头删除,而后者只支持从开头插入和删除。
4.如果需要在实现快速插入的同时保持顺序,那么使用新的 LinkedList<T> 集合可帮助您提高性能。与 List<T> 不同,LinkedList<T> 是作为动态分配的对象链实现。与 List<T> 相比,在集合中间插入对象只需要更新两个连接和添加新项目。从性能的角度来看,链接列表的缺点是垃圾收集器会增加其活动,因为它必须遍历整个列表以确保没有对象没有被释放。另外,由于每个节点相关的开销以及每个节点在内存中的位置等原因,大的链接列表可能会出现性能问题。虽然将项目插入到 LinkedList<T> 的实际操作比在 List<T> 中插入要快得多,但是找到要插入新值的特定位置仍需遍历列表并找到正确的位置。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号