

【B站学习(存档)】U-Net网络结构讲解(语义分割)
本课程B站链接:https://www.bilibili.com/video/BV1Vq4y127fB/
主要介绍unet的网络结构。详见2015年的论文
-
unet结构图
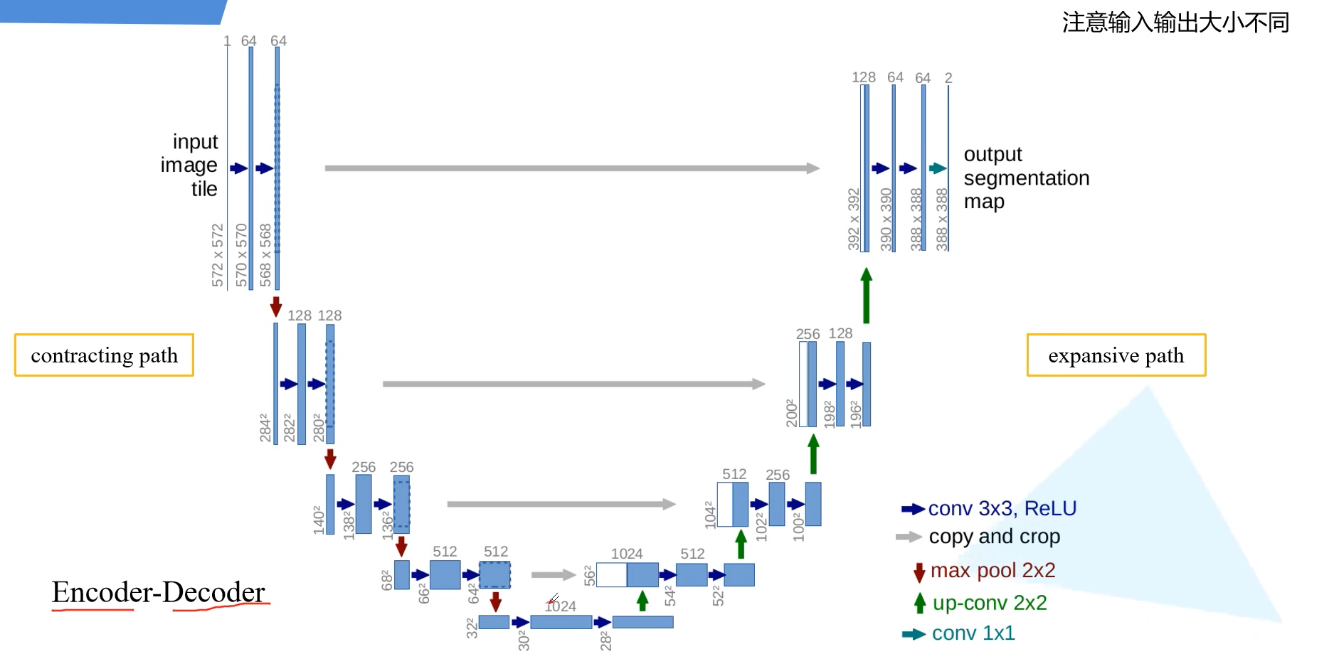
【详解】典型的encoder-decoder结构 -
左边是encoder,也就是提取特征和下采样的部分;右边decoder解码是一系列上采样,得到最终的一个分割图
-
图中每个长条的矩形对应的都是一个特征层,箭头都是一种操作
-
从输入开始看,输入是572x572的单通道的图片为例,首先进行一个卷积操作(步距为1,no padding)通过卷积层之后,高和宽都会减少,当时15年还没有BN。经过两个卷积层后进行下采样(max poooling),2x2,高和宽就会减半,channel不会变化,还是64。接着再进行两个3x3卷积层,(每次下采样后都会将channel进行翻倍,64-128)。右半部分:绿色的是上采样(其实是转置卷积,可回看视频,经过之后会将特征层的高和宽放大两倍,channel减半),1024-512,对应蓝色部分;灰色箭头是copy和crop,左边的高和宽是64x64,右边得到的是56x56大小的,无法进行直接拼接,所以对左边的特征层进行中心裁剪,和右边的蓝色部分进行拼接,拼接之后channel为1024。后面依次进行上采样。直到最后得到宽和高388x388,最后经过一个灰色的箭头卷积层,这个卷积核的个数和我们分类的类别个数是一致的,论文中只分割前景和背景。输出的结构就是388x388x2。(注意最后1x1的卷积的没有激活函数)
-
注意得到的分割图和原图并不一样
-
反思:现在主流的实验方式并非严格按照论文中的方式去实现,而是在卷积层加上一个padding,即每次经过3x3卷积层,不会改变特征层的高和宽,并且会在卷积和ReLu之间加上一个BN(效果:在拼接的时候不要中心裁剪了,最后得到的高和宽和我们输入的高和宽保持一致)。
-
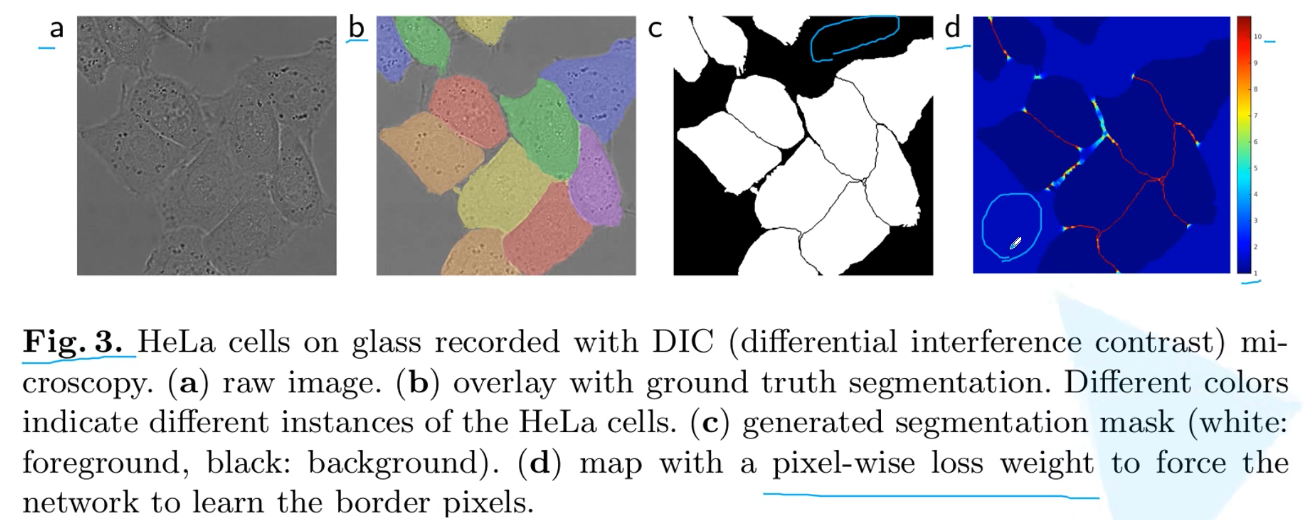
针对特别大(高分辨率的)图片,一般每次只分割一个patch,相邻两个预测区域之间一般会有一个重叠的部分,称为overlap,能够更好的分割边界区域
*pixel-wise loss的方案:细胞与细胞之间的背景取,赋予大的权重,对于大片的背景区域,施加小的权重


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix