Redis 性能优化实战
Redis 作为内存数据库,其性能表现非常出色,单机 OPS 很容易达到 10万以上,这主要得益于其高效的内存数据结构、单线程无锁设计、IO 多路复用等技术实现。但是在线上生产环境的使用中,我们仍然会发现在使用 Redis 的时候其性能和预期是不符的,例如出现了明显的延迟等,如果我们能从 Redis 的实现结合操作系统的一些原理来进行分析,就可以比较全面的定位问题,并且能够想出比较高效的解决办法。
本文的相关示例都是基于 Redis 6.x 版本运行的。
首先,对于 Redis 操作变慢的原因可能有两个方面:
- 应用到 Redis 服务之间的网络出现问题,导致延迟变大,比如带宽被过多的占用等情况。
- Redis 操作本身存在问题,比如有些复杂度比较高的指令导致了慢查询等。
如果是第一种情况,我们应该重点排查网络的问题,当然也有可能是 Redis 发送了大量的数据导致网络资源被占满。第二种情况更加常见,我们可以将当前的性能和基准性能进行比较,定位是否出现了操作变慢的情况。
通常我们可以在当前环境正常的前提下,做一次基准性能测试,并将结果保存下来,方便后续排查问题,可以运行下面的命令进行 60s 的测试:
# 如果有密码的话要添加密码参数
redis-cli -h 127.0.0.1 -p 6379 --intrinsic-latency 60
结果示例如下:
Max latency so far: 1 microseconds.
Max latency so far: 15 microseconds.
Max latency so far: 18 microseconds.
Max latency so far: 37 microseconds.
Max latency so far: 49 microseconds.
Max latency so far: 66 microseconds.
Max latency so far: 81 microseconds.
Max latency so far: 145 microseconds.
Max latency so far: 169 microseconds.
Max latency so far: 301 microseconds.
Max latency so far: 769 microseconds.
Max latency so far: 959 microseconds.
Max latency so far: 1343 microseconds.
Max latency so far: 2183 microseconds.
Max latency so far: 2457 microseconds.
Max latency so far: 5108 microseconds.
881760112 total runs (avg latency: 0.0680 microseconds / 68.05 nanoseconds per run).
Worst run took 75067x longer than the average latency.
那么可以看到,这一分钟内最大的延迟是 5108 微秒也就是 5.1 毫秒,平均每次查询是 68.05 纳秒。可以多次执行得到平均的统计。
我们还可以采样一段时间内 Redis 的最小、最大以及平均访问延迟:
# 每秒输出一次统计的结果
redis-cli -h 127.0.0.1 -p 6379 --latency-history -i 1
结果示例如下:
min: 0, max: 1, avg: 0.33 (97 samples) -- 1.01 seconds range
min: 0, max: 3, avg: 0.26 (96 samples) -- 1.01 seconds range
min: 0, max: 4, avg: 0.36 (95 samples) -- 1.00 seconds range
min: 0, max: 1, avg: 0.26 (96 samples) -- 1.00 seconds range
min: 0, max: 1, avg: 0.30 (96 samples) -- 1.01 seconds range
min: 0, max: 1, avg: 0.31 (96 samples) -- 1.00 seconds range
min: 0, max: 15, avg: 0.51 (95 samples) -- 1.01 seconds range
这个是每秒输出一行,时间的单位是毫秒,比如第一行表示范围是 0 ~ 1ms,平均是 0.33ms,可以通过多次输出计算整体的范围。
当我们将测试的结果保存下来之后,当遇到性能瓶颈的时候,我们可以和最初测试的基准性能区间进行比较,如果延迟比基准性能高 2 倍以上,说明当前 Redis 实例确实变慢了,然后我们就可以考虑找到变慢的因素并进行优化,下面我们将通过不同的角度来进行分析对 Redis 的性能进行分析及调优。
1. 分析命令的复杂度是否过高
我们可以查询 Redis 的慢日志,查看哪些命令的耗时比较久,首先关于慢日志的配置有下面两个:
# 默认配置
slowlog-log-slower-than 10000
slowlog-max-len 128
其中 slowlog-log-slower-than 表示时间的阈值,也就是命令执行的时间超过阈值,则会记录到慢日志中,这个单位是微秒,当前配置也就是说当命令执行超过 10ms 时会被记录。slowlog-max-len 表示慢日志保存的条数,默认只保存最近的 128 条。
那么我们下面可以查询当前的慢日志,首先进入到 Redis 客户端中,然后执行:
slowlog get 10
返回的结果依次包括:慢日志编号、执行时间戳、执行耗时(微秒)、命令和参数、客户端 IP 和端口以及客户端名称。
当找到慢查询的命令后,我们就可以分析当前的命令是否是复杂度过高,比如 HGETALL、SORT、SUNION、ZUNION、ZUNIONSTORE 等复杂度在 O(N) 或者以上的命令,而且看一下当前 N 的值是不是比较大。
这个时候有两种原因会造成延迟变大:
- N 比较大,操作数据结构会占用比较多的 CPU 资源。
- N 比较大,并且需要返回大量数据到客户端,占用过多的网络资源而导致延迟变大。
对于前者,我们只需要查看 Redis 的 CPU 利用率,如果利用率过高,那么就要考虑操作这个数据结构复杂度过高导致 CPU 飙升。如果 CPU 利用率不高,但是执行命令时 Redis 的网络带宽会升高,那么要考虑命令返回的数据量过大导致网络带宽占用过高。
另外,由于 Redis 是单线程执行命令,如果前面的命令没有执行完毕,后面的命令也会一直排队等待,客户端的延迟也会升高,基于这种情况我们对应的优化思路如下:
- 对于复杂度过高的命令要慎重使用,如果确实会导致 CPU 飙升,我们应该考虑将数据在客户端做一些处理来减轻 Redis 的负担,如果数据量过大,我们应该采用渐进式的方式获取数据到客户端,或者采用其他更好的逻辑来实现。
- 如果执行 O(N) 大小的命令,那么要确保 N 尽量要小 (推荐在 100 以内),这样可以及时的返回,其实这本身也是一个 bigkey 的问题。
2. 分析是否操作了 bigkey
如果慢日志中的命令复杂度大部分都不太高,而是有很多 GET、SET、DEL 这样的命令,那么我们要小心是不是存在了 bigkey,我们可以查看慢日志中参数的长度来定位可能的 bigkey,但不一定是参数比较长,也有可能 value 比较长。
那么先简要说一下什么是 bigkey,当 Redis 实例写入数据时需要为新的数据分配内存空间,相应的,从 Redis 中删除数据时,也会释放对应的空间,在传输数据时,也会通过网络发送至少同等容量的字节流。
那么如果我们写入的 key 或者 value 非常大,在分配空间、释放空间以及传输数据时都会比较耗时,这种 key 或者 value 我们统称为 bigkey。
所以当出现上面的情况时,我们需要排查我们的业务代码,看是否存在写入 bigkey 的情况,如果存在的话,尽可能想办法进行优化。
如果 Redis 实例有很多客户端都在用,或者说可能已经有 bigkey 写入到 Redis 中了,Redis 本身也提供了扫描 bigkey 的命令,我们可以扫描一下 bigkey 的分布,例如执行下面的命令:
redis-cli -h 127.0.0.1 -p 6379 --bigkeys
# 为了节省资源,每扫描 100 个 key 休眠 0.1s
redis-cli -h 127.0.0.1 -p 6379 --bigkeys -i 0.1
# 指定不同的库编号
redis-cli -h 127.0.0.1 -p 6379 -n 2 --bigkeys
执行完之后结果是以类型展示的,即每个类型会输出一个最大的 key 以及具体的大小,不过执行的时候也会输出对应的进度,可以看到更多的一些可能的 bigkey。
扫描 bigkey 的实现原理就是在 Redis 中运行 SCAN 命令,遍历整个实例中所有的 key,针对不同 key 的类型分别执行 STRLEN、LLEN、HLEN、SCARD、ZCARD 等命令来获取对应的长度。
不过在执行这个命令分析之前要注意一些问题:
- 执行扫描的时候,Redis 的 CPU 利用率会升高,所以最高放在非业务高峰期运行。或者添加 -i 参数控制一下每次扫描一批后休眠的时间,但是总的分析时间会增大。
- 扫描结果中对于容器类型的 key,比如 List、Hash 以及 Set 等,只能扫描元素个数最多的 key,但实际的空间占用并不一定是最大的,这点也需要注意。
综上,当确定了 bigkey 之后,我们就可以更好地分析业务应用在哪些地方使用了这些 bigkey,从而对程序进行优化。
另外,我们还需要在事后删除 Redis 中的 bigkey,对于早期的 Redis 3.0 以前的版本来说,删除容器需要渐进式逐个删除子元素,最后再删除最外层的 key,但是在 Redis 4.0 版本之后提供了异步删除 key 的命令 UNLINK,这个命令是在后台异步删除 key,不会阻塞当前的主线程,可以降低对业务的影响。不过我们当前使用的是 Redis 6.0 版本,只需要修改下面的配置:
lazyfree-lazy-user-del yes
这样就可以放心地执行 DEL 命令删除,Redis 会自动将删除操作转为后台去运行。
3. 分析是否存在大量集中过期的 key
如果出现一种比较奇怪的现象:在平时操作 Redis 时并没有很大的延迟出现,但是在某些时间点会突然延迟变高,过后又恢复正常。这种延迟的时间点比较有规律,总是间隔固定的时间或者整点就会出现延迟。
这种情况,我们就要重点排查业务中是否存在大量的 key 集中过期的情况,如果确实存在这种情况,那么这个过期的时间段内 CPU 负载会比较高,这个时候客户端再有其他操作时延迟就会明显变大。
Redis 中 key 的过期主要有下面两种形式:
- 当访问这个 key 时,才会判断这个 key 是否过期,如果发现已经过期将不会返回给客户端并且从实例中删除 key。
- Redis 内部存在一个定义任务,默认每 100ms 运行一次,在源码的
serverCron->databasesCron中执行activeExpireCycle这里面定义了删除的逻辑,每次从全局哈希表中取 20 个 key,然后判断并删除其中过期的 key,当过期的数量占总数小于 10% 或者整体运行时间超过 25ms 时,则停止循环。这部分的主要逻辑如下:
for (j = 0; j < dbs_per_call && timelimit_exit == 0; j++) {
/* Expired and checked in a single loop. */
unsigned long expired, sampled;
redisDb *db = server.db+(current_db % server.dbnum);
/* Increment the DB now so we are sure if we run out of time
* in the current DB we'll restart from the next. This allows to
* distribute the time evenly across DBs. */
current_db++;
/* Continue to expire if at the end of the cycle there are still
* a big percentage of keys to expire, compared to the number of keys
* we scanned. The percentage, stored in config_cycle_acceptable_stale
* is not fixed, but depends on the Redis configured "expire effort". */
do {
unsigned long num, slots;
long long now, ttl_sum;
int ttl_samples;
iteration++;
/* If there is nothing to expire try next DB ASAP. */
if ((num = dictSize(db->expires)) == 0) {
db->avg_ttl = 0;
break;
}
slots = dictSlots(db->expires);
now = mstime();
/* When there are less than 1% filled slots, sampling the key
* space is expensive, so stop here waiting for better times...
* The dictionary will be resized asap. */
if (slots > DICT_HT_INITIAL_SIZE &&
(num*100/slots < 1)) break;
/* The main collection cycle. Sample random keys among keys
* with an expire set, checking for expired ones. */
expired = 0;
sampled = 0;
ttl_sum = 0;
ttl_samples = 0;
// config_keys_per_loop = 20 + 20/4*effort(default=0) = 20
if (num > config_keys_per_loop)
num = config_keys_per_loop;
/* Here we access the low level representation of the hash table
* for speed concerns: this makes this code coupled with dict.c,
* but it hardly changed in ten years.
*
* Note that certain places of the hash table may be empty,
* so we want also a stop condition about the number of
* buckets that we scanned. However scanning for free buckets
* is very fast: we are in the cache line scanning a sequential
* array of NULL pointers, so we can scan a lot more buckets
* than keys in the same time. */
// max_buckets = 20 * 20 = 400
long max_buckets = num*20;
long checked_buckets = 0;
// 条件1:当采样的 key 大于或等于 20 时将退出循环
while (sampled < num && checked_buckets < max_buckets) {
for (int table = 0; table < 2; table++) {
if (table == 1 && !dictIsRehashing(db->expires)) break;
unsigned long idx = db->expires_cursor;
idx &= db->expires->ht[table].sizemask;
dictEntry *de = db->expires->ht[table].table[idx];
long long ttl;
/* Scan the current bucket of the current table. */
checked_buckets++;
while(de) {
/* Get the next entry now since this entry may get
* deleted. */
dictEntry *e = de;
de = de->next;
ttl = dictGetSignedIntegerVal(e)-now;
if (activeExpireCycleTryExpire(db,e,now)) expired++;
if (ttl > 0) {
/* We want the average TTL of keys yet
* not expired. */
ttl_sum += ttl;
ttl_samples++;
}
sampled++;
}
}
db->expires_cursor++;
}
total_expired += expired;
total_sampled += sampled;
/* Update the average TTL stats for this database. */
if (ttl_samples) {
long long avg_ttl = ttl_sum/ttl_samples;
/* Do a simple running average with a few samples.
* We just use the current estimate with a weight of 2%
* and the previous estimate with a weight of 98%. */
if (db->avg_ttl == 0) db->avg_ttl = avg_ttl;
db->avg_ttl = (db->avg_ttl/50)*49 + (avg_ttl/50);
}
/* We can't block forever here even if there are many keys to
* expire. So after a given amount of milliseconds return to the
* caller waiting for the other active expire cycle. */
if ((iteration & 0xf) == 0) { /* check once every 16 iterations. */
elapsed = ustime()-start;
// 运行时间大于 timelimit=25ms 也退出循环
// timelimit = config_cycle_slow_time_perc*1000000/server.hz/100 = 25*1000us = 25ms
if (elapsed > timelimit) {
timelimit_exit = 1;
server.stat_expired_time_cap_reached_count++;
break;
}
}
/* We don't repeat the cycle for the current database if there are
* an acceptable amount of stale keys (logically expired but yet
* not reclaimed). */
} while (sampled == 0 ||
(expired*100/sampled) > config_cycle_acceptable_stale);
}
详细的代码参考:https://github.com/redis/redis/blob/6.2/src/expire.c
基于上面的第二个主动删除策略,如果同时出现大量过期的 key,那么频繁删除会占用比较大的 CPU 资源,此时如果业务应用再访问就有可能出现延迟的情况。还需要注意的时,过期删除是在后台执行,哪怕删除的 key 属于 bigkey 本身耗时较长,但是也不会记录到慢日志中,因为慢日志只记录主动执行的命令,我们只有通过业务侧的感知来排查具体的原因,这种情况值得我们注意。
另外在 Redis 中执行 INFO 命令可以获得实例当前的统计信息,其中 expired_keys 表示实例从启动到目前为止累计删除过期 key 的数量,如果我们配置了监控,就可以看到在很短的时间内这个指标突然增大,如果有规律出现,基本上就能够很快定位到批量过期的问题。
如果我们确实排查到这类问题,那么可以采用下面的可选方案来应对:
- 为了避免集中过期,我们可以在程序中分散设置过期时间,这样就不会导致大量的 key 同时过期,对 Redis 的影响也就比较小。
- 可以对过期的 key 开启 lazyfree 机制,这样会在后台异步删除过期的 key,不会阻塞主线程的运行。
开启 lazyfree 过期删除可以修改如下的配置:
lazyfree-lazy-expire yes
4. 分析是否存在内存淘汰
默认情况下 Redis 实例的 maxmemory 配置为 0,也就是不限制内存的大小,但是假如我们限制了 maxmemory 的大小,并且设置了数据淘汰的策略,那么当实例的内存占用达到限制时,Redis 会按照既定的淘汰策略淘汰数据,使得整个实例的内存占用维持在 maxmemory 设置之下,这个时候如果数据操作比较频繁,那么淘汰数据也需要消耗 CPU 资源,这个时候客户端执行指令就会感觉到延迟变大的情况了。
常见的数据淘汰策略有下面这些:
- allkeys-lru:淘汰最近最少使用的 key,无论 key 本身是否设置过期时间。
- volatile-lru:只淘汰最近最少访问并且设置了过期时间的 key。
- allkeys-random:随机淘汰 key,无论 key 本身是否过期。
- volatile-random:随机淘汰设置了过期时间的 key。
- volatile-ttl:在所有设置了过期时间的 key 中,淘汰距当前过期时间最短的 key
- allkeys-lfu:淘汰访问频率最低的 key,无论 key 是否设置过期时间。
- volatile-lfu:只淘汰访问频率最低并且设置了过期时间的 key。
- noeviction:不进行任何淘汰,但是当实例内存达到上限时,拒绝客户端写入数据。
关于淘汰策略的详细说明可以参考文档:https://redis.io/docs/reference/eviction/
一般我们比较常用的就是 LRU 和 LFU 相关的策略,但是这个策略也并不是精确地找到最近最少使用以及访问频率最低的 key,而是基于采样的近似值。对于 LRU 策略,Redis 每次从所有 key 中采样一批数据,这个批量的大小可以通过 maxmemory-samples 参数进行配置,每次从这个采样的结果中计算出一个最近最少使用的 key,然后删除掉,再不断的进行采样-删除的操作,直到内存使用小于 maxmemory 配置的值则结束这个过程。之所以不使用精确的 LRU 是因为这个过程会耗费很大的内存和计算处理,而近似的算法同样可以达到类似的效果,但是占用的资源将显著降低。对于 LFU 也是类似,不同的是 LRU 采用了概率计数器来实现淘汰,思路仍然是近似的算法。
所以,Redis 淘汰 key 的过程就是删除数据的过程,因此也会增大应用操作的延迟,而且淘汰的越频繁或者客户端的 OPS 越高,延迟也会越明显。特别是如果被淘汰的数据中存在 bigkey,这个延迟会更明显,bigkey 的危害到处都是,所以在业务中一定要避免使用 bigkey。
针对于数据淘汰,我们可以采用下面的一些策略来避免:
- 避免存储 bigkey。
- 在允许的情况下修改淘汰策略,比如使用随机的淘汰策略,这个策略执行的更快。
- 开启 lazyfree 配置,将淘汰 key 的操作放到后台线程中执行。
最后,还可以配置 Redis Cluster,降低单个实例的压力。
5. 分析是否存在持久化的问题
持久化的问题可以分为两个方面来探讨,一方面是我们都比较熟悉的子进程持久化大量数据占用过多资源的问题,另一方面可能是我们更容易忽略的,也就是 fork 系统调用本身的耗时过大问题。
5.1 fork 子进程时耗时过长
我们知道 Redis 的持久化是通过子进程的方式来异步执行,从而减少对主进程的影响,子进程的创建是通过 fork 调用进行的,通常来说 fork 操作比较快,而且子进程不需要拷贝主进程的内存,只需要共享主进程的内存空间,利用操作系统的写时复制(Copy on Write)技术实现高效的读写访问。
但是假如 Redis 本身实例占用的内存空间非常大,fork 过程中需要将主进程的页表复制给子进程,从而实现内存的共享,如果内存空间非常大,那么页表也会占用一定的空间,所以在完成 fork 的时候可能会因为页表拷贝引起 CPU 的突增,从而出现短暂的的阻塞,这段时间内的操作延迟就会增大,如果恰巧此时 Redis 实例比较繁忙,已经占用很大一部分 CPU 时间,那么这个影响会更明显。
那么我们改如何确认这部分是否存在异常呢?
和上面一样,我们可以执行 INFO 命令,查看其中的 latest_fork_usec 结果,这个单位是微秒,通常来说这个值也就是几百到几千微秒,如果看起来大的明显,比如达到了几百毫秒甚至秒级,那么就要考虑当前的内存是不是太大了,是不是需要进行优化了。另外如果是虚拟机的话,正常 fork 的时间也会比物理机长。
同时我们也应该根据业务情况,减少持久化子进程创建的数量,也就是调整持久化策略,尽可能拉长每次持久化之间的时间间隔,在数据安全性和性能之间进行平衡。
如果是在配置了主从复制的场景,可以在一部分 Slave 节点开启持久化,其他节点都关闭持久化,这样业务系统只访问主节点以及未开启持久化的从节点,也可以保证不受 fork 阻塞的影响。
在主从复制过程中,Master 进程除了向 Slave 进程发送数据之外,进程中还会存在一个环形缓冲区,当断开的 Slave 节点重新和 Master 建立连接之后,Slave 会从断开前的偏移开始获取数据,从而实现增量的数据更新。但是假如这个缓冲区满了,Redis Master 会覆写掉之前的数据,如果子进程断开的时间过长,重新恢复后请求的偏移在 Master 实例的缓冲区中没有找到,这个时候就会执行全量的复制,这个时候主节点无论如何都会创建子进程来生成 RDB,然后再进行一次全量的数据同步,此时也会占用大量的带宽,而 Master 实例环形缓冲区的大小也是可以调整的,所以我们考虑在内存大小允许的情况下,尽可能调大这个缓冲区的大小,尽量在大部分情况下都执行增量的数据同步,避免全量的数据同步。这个参数由 repl-backlog-size 来设置,这个大小默认是 1MB,我们可以根据实际情况调大,但注意不要影响当前实例的正常运行。
所以,我们总结出下面一些常见的解决思路:
- 控制 Redis 实例的内存尽量在 10GB 以内,也就是页表整体大小小于 20MB,降低持久化子进程的
fork时间。 - 如果是 Redis 实例只做缓存用,没有重要的业务数据,那么可以调小持久化的频率或者关闭持久化。
- 如果配置了主从机制,那么可以在其中的某些 Slave 节点执行持久化,保证其他节点的性能。
- 适当调大
repl-backlog-size的值,降低主从节点全量同步数据的概率。
5.2 持久化配置是否合理
其实无论配置了哪种持久化方式,持久化的完全重写都是通过 fork 子进程的方式执行,子进程一定会占用单独的 CPU 资源,或多或少都会对主进程造成一定的影响。对于 RDB 持久化,主进程和子进程之间没有通信,只是主进程新操作的数据会导致地址空间变大,而 AOF 持久化,主进程本来就会有持续不断地系统调用,在 AOF 重写期间,主进程和子进程之间会有增量的数据同步,所以 AOF 持久化对 Redis 性能的影响可能会更明显。
所以我们重点来关注 AOF 持久化的情况下所引起的问题,当开启 AOF 持久化之后,Redis 执行写命令后,会通过系统调用 write 将命令写入文件缓冲区,然后根据配置的 AOF 刷盘策略,将文件系统内存缓冲区的数据通过系统调用 fsync 真正的写到磁盘上。
Redis 有 3 种 AOF 刷盘策略:
- always:主线程每次执行写操作后立即刷盘,这种方案会有非常繁忙的系统 I/O,但是数据的安全性最高。
- no:主线程只写内存缓冲区,至于刷盘的实际则交由操作系统执行,这种方案性能是最好的,但是丢失数据的可能性最大。
- everysec:主线程每次写操作只写内存缓冲区,由后台线程每隔 1s 执行一次刷盘操作,这种方案对性能影响较小,同时最多丢失 1s 的数据,是前两种方案的折衷。
首先是对于 always 策略,对于每个操作 Redis 主线程都会将这个命令写入到磁盘中才返回,由于磁盘操作相较于内存操作慢两个数量级,那么这种配置会严重拖慢速度,导致延迟增大,所以任何情况下都不要配置 always 策略。
然后再看 no 策略,这个策略每次写入命令只写入内存缓冲区,开销仅仅是一个系统调用级别,所以对 Redis 的影响非常小,不会导致延迟增加,但是当 Redis 异常宕机后会丢失相当一部分数据,而且大小是不确定的,所以除非我们对数据丢失不敏感,例如只用作缓存,这种情况下可以配置 no 策略,其余情况下不建议配置。
最后是 everysec 策略, 这个策略主进程写完就立即返回,刷盘的操作是放到后台线程中执行,所以大部分情况下这种方法是推荐的。但是,总有一些特殊的情况,假如主进程的写入非常频繁,那么后台的刷盘操作就会被阻塞住,但是主线程一直在接收请求,不断地执行 write 调用,当刷盘的性能跟不上写入的速度时,fsync会阻塞很长时间,在这个阻塞过程中 write 也会阻塞住,直到 fsync 成功刷新后才可以继续恢复执行,这个时候其他 Redis 操作的延迟都会增大。
但是绝大部分情况下不会有这么频繁的操作,不过存在特别需要注意的情况就是在 AOF rewrite 的同一时间段内存在大量的写入,因为 AOF rewrite 本来就占用了很大的磁盘 I/O,这个时候再执行 fsync 就很容易出现阻塞的情况,主进程的 write 也会跟着阻塞导致延迟变大。对于这种情况,可以修改配置让 Redis 在 AOF rewrite 期间不触发 fsync 操作:
no-appendfsync-on-rewrite yes
但是如果在 AOF rewrite 期间实例宕机,那么会丢失很多的数据,所以这个参数要权衡利弊后设置。
另外就是注意检查是否有 Redis 实例之外的其他程序频繁操作硬盘,如果有的话也可能引起 Redis 的延迟,最好让 Redis 在独立的环境中运行。
最后,在硬件存储的层面,建议 Redis 持久化配置到 SSD,和机械硬盘相比会有出色的性能,特别是可以减少持久化过程中带来的延迟增加问题。
6. 操作系统级别优化
6.1 关闭内存大页
在 RDB 和 AOF rewrite 期间,还有一个方面很容易导致性能问题,这就是 Linux 的内存大页机制。我们知道现代操作系统管理内存是按照分页方式来实现的,每个常规内存页大小是 4KB,内存申请和释放的最小单元就是页,同时通过页表在实现虚拟页面和物理页帧的一一对应。
从 Linux 内核 2.6.38 版本开始支持内存的大页机制,允许大于 4K 的内存页面,在 Linux 上如果开启之后将允许程序申请以 2MB 为单位的页面,也就是说原来 4KB 的最小单元变成了 2MB。
当然内存大页有非常多的优点,首先就是页表项的节省,大页的页表空间比原来节省了 512 倍,同时根据局部性原理,TLB 缓存命中率也会比较高,因此内存的访问效率会更高效,所以大页适合的场景就是大量连续内存的访问。
有利就有弊,大页的申请和释放速度会比普通页面慢很多,其实大页主要应对的还是读多写少的情况或者是连续读写的情况,而 Redis 中更常见的是随机读写,特别是随机写的情况下大页带来的损耗会非常严重。
我们来分析下如果开启了大页,在持久化期间会有什么样的问题。
当 Redis 通过 fork 子进程的方式执行 RDB 或者 AOF rewrite 时,子进程共享主进程的地址空间,不过在这个时候主进程是可以继续执行写请求的,而写进来的请求,操作系统将采用 Copy on Write 的方式操作内存。也就是说当对原有数据进行修改时,由于子进程也会共享这份数据,所以 Redis 修改这块数据的内容时,操作系统会先将这块内存的数据拷贝出来,再修改这块内存的数据,然后当访问修改的数据时也会访问这块内存的数据,而不是原来的数据,这就是写时复制的实现原理。
但是,我们想因为 Redis 大部分的修改都是根据 key 来修改,所以操作大概率都是随机访问,并不是连续访问,所以假如客户端每次只修改 10 个字节的数据,但是由于开启了内存大页,Redis 也要申请 2MB 的空间,将原有内容拷贝过去,然后再修改这 10 个字节的内容。当存在大量这样的操作时,每次一小部分数据的修改都要至少涉及到 2MB 的页面创建、复制和修改,这会导致操作时的延迟增加,同时内存占用也会快速增长。
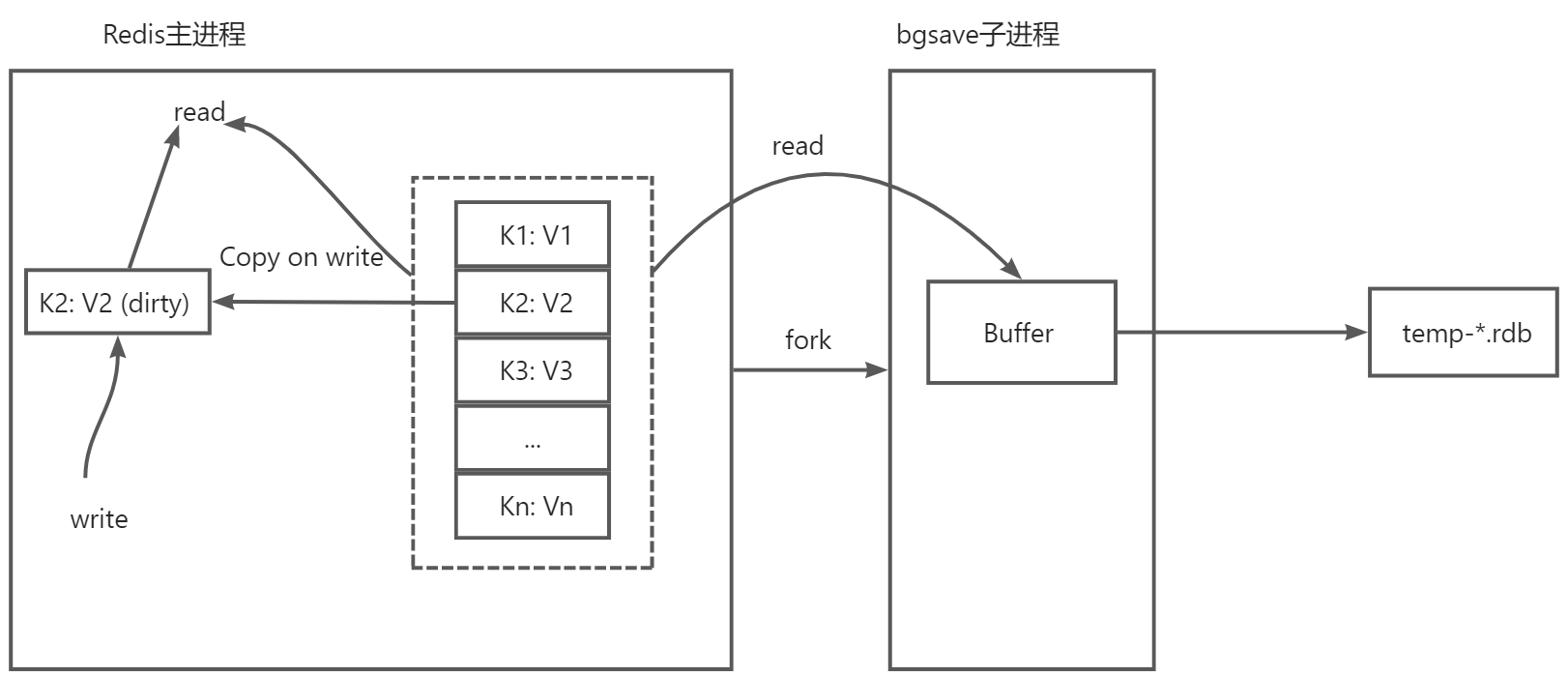
所以,总结一下是当开启内存大页后,Redis 持久化期间的操作延迟和写放大会非常明显,因此对于 Redis 来说并不适合内存大页的这种应用场景,仍然是常规页面比较合适。
对于这个问题的解决方法,我们只需要关闭内存大页就可以了,我们可以查看下面的内核参数:
cat /sys/kernel/mm/transparent_hugepage/enabled
如果返回的结果是 [always] madvise never 则表示开启了内存大页,我们可以关闭它:
echo never >/sys/kernel/mm/transparent_hugepage/enabled
查看内存大页的大小设置可以执行:
cat /sys/kernel/mm/transparent_hugepage/hpage_pmd_size
返回单位是字节,这个就是开启大页之后每次申请页面的大小,通常都是 2MB,关于 Linux 内存大页可以参考:https://www.kernel.org/doc/html/next/admin-guide/mm/transhuge.html
6.2 关闭交换分区
如果我们发现 Redis 突然变得非常慢,每次操作都是几百毫秒甚至几秒,而且慢查询都是复杂度比较低的命令,如果恰好系统开启了交换分区,那么这个时候我们要考虑检查 Redis 是否被交换到了 Swap 中,如果确实使用了 Swap 那么性能也就很难得到保证。
操作系统采用多道程序设计来管理众多的进程,每个进程本身看自己拥有完整且连续的地址空间,操作系统本身相当于对 CPU 和内存做了虚拟化,当多个进程同时运行时而物理内存的空间不够时,操作系统会通过页面置换策略将一部分程序内存空间交换到 Swap 中,当这部分内存需要访问时再从 Swap 中换出,从而保证程序的正常运行。
页面的置换虽然可以保证程序本身能够运行,但是对于 Redis 这样的对性能要求极高的服务,磁盘的延时比内存慢好几个数量级,这个延迟在 Redis 操作中就会非常明显,所以当我们发现 Redis 有这种迹象时,首先需要确认,先找到 Redis 的进程 ID,例如:
ps aux | grep redis-server
然后查看每个内存区域交换分区的占用情况:
grep '^Swap:' /proc/$PID/smaps
这个看到的结果会有很多行值,因为每一个 VMA(虚拟内存区域)都有自己对应的统计,每个 VMA 其实就是一段匿名内存,如果我们看到交换分区某些 VMA 中值比较大,就需要注意了。我们可以采用命令对所有的 Swap 求和:
grep '^Swap:' /proc/$PID/smaps | awk '{sum+=$2}END{print sum}'
这样就可以看到当前 Redis 实例总体的交换空间占用,如果这个结果比较大,比如达到了几百兆甚至 GB 级别的大小,必然会导致 Redis 性能的急剧下降。
我们这个时候首先要排查是否有其他进程占用了比较多的内存,导致 Redis 的内存被交换出去,如果是这样要将其他的程序迁移出去,让 Redis 独立运行。再或者是 Redis 本身占用的内存确实比较大,物理内存确实不够用,这种情况下可以考虑扩展物理内存或者部署 Redis Cluster 来解决。不过一般的情况下,如果交换分区存在,即使内存还有可用的空间,那么操作系统也倾向于将一部分不常用的程序内存换出到交换分区中,因此我们首先要做的是减少交换分区使用倾向或者关闭交换分区:
# 减小交换分区使用倾向
sysctl -w vm.swappiness=0 >> /etc/sysctl.conf
也可以关闭交换分区:
swapoff -a
不过这样是临时关闭,如果永久关闭可以取消 /etc/fstab 中的自动挂载,以后重启交换分区将不会被重新加载。
关闭交换分区后,我们可以排查 Redis 本身的内存的问题:
- 如果存在其他进程占用比较多的内存,可以将其他的程序迁移到另外的服务器,防止对 Redis 造成影响。
- 优化业务设计,减小 Redis 实例的内存占用。
- 对 Redis 进行内存碎片整理,优化内存使用。
- 增大 Redis 所在机器的物理内存。
- 部署 Redis Cluster,将数据分散到集群中存储。
其中方案 3 是进行碎片整理,我们可以通过执行 INFO 命令查看 Redis 内存的使用情况:
# Memory
used_memory:361929012
used_memory_human:345.16M
used_memory_rss:658710801
used_memory_rss_human:628.20M
...
mem_fragmentation_ratio:1.82
其中 used_memory 是 Redis 实际存储占用的内存大小,used_memory_rss 是 Redis 向操作系统实际申请的内存大小,由于 Redis 中存在着频繁的内存操作,所以导致两者偏离逐渐增大,所以引入了一个内存碎片率的参数 mem_fragmentation_ratio ,这个计算方法就是 used_memory_rss/used_memory ,也就是两者的比值。如果这个值比较大,比如大于 1.5 ~ 2,说明内存碎片率比较大,实际上 Redis 不应该占用这么多的内存,这个时候就可以考虑进行碎片整理从而释放一部分空间。
Redis 支持自动碎片整理,主要有下面几个参数:
# 开启自动碎片整理,默认关闭
activedefrag yes
# 内存占用小于 500M,不进行碎片整理
active-defrag-ignore-bytes 500mb
# 内存碎片率超过 50% 开始整理
active-defrag-threshold-lower 50
# 内存碎片率超过 100% 将尽最大努力整理
active-defrag-threshold-upper 100
# 限制内存碎片整理占用 CPU 使用率的最小值
active-defrag-cycle-min 1
# 限制内存碎片整理占用 CPU 使用率的最大值
active-defrag-cycle-max 25
# 操作 set/hash/zset/list 每次 scan 数量的最大值
active-defrag-max-scan-fields 1000
配置开启之后,Redis 就可以正常进行碎片整理了,不过碎片整理也是在主线程中执行,整理时也会消耗不少的 CPU 资源,我们虽然做了 CPU 最高使用率的限制,但是仍然可能会一定程度上增大请求的延迟,这同样是一个需要权衡的问题。
6.3 配置内存过载申请处理
Redis 运行时有时候客户端操作会出现下面的报错:
MISCONF Redis is configured to save RDB snapshots, but it is currently not able to persist on disk. Commands that may modify the data set are disabled, because this instance is configured to report errors during writes if RDB snapshotting fails (stop-writes-on-bgsave-error option). Please check the Redis logs for details about the RDB error.
这个错误其实是表示无法保存快照,并且出现错误时,客户端无法操作,会导致程序阻塞,这种报错如果排除硬盘问题,很大可能是因为内存不足导致的,具体可以查看的 Redis 的日志,如果日志报错大致为:Can’t save in background: fork: Cannot allocate memory. 那么基本就可以确定是内存分配失败的错误了,有可能是内存确实不够了,导致分配失败,这种情况可以参考前面提到的处理方法解决。但是如果内存还有很多空闲,却仍然报错,原因可能就处在持久化阶段,同样还是 fork 子进程的时候,操作系统可能认为当前的空间不足从而阻止 fork 操作的执行,正常程序的虚拟空间都比较大,但是实际用的却远远没有那么多,在没有写时复制之前对于 fork 来说理论上内存会加倍,但是上面我们提到过现代操作系统都会共享主进程的地址空间,因此 fork 并不会真正占用太大的实际内存,而操作系统默认设置下会严格按照理论上进行限制,最终导致 fork 失败,这就要提到内核参数 vm.overcommit_memory 了。
内核参数 vm.overcommit_memory 的取值可以为 0,1,2,默认情况下为 0,表示启发式过度使用处理,简单理解是系统认为内存够用则放行,反之则拒绝,因此在 fork 时会很容易失败。如果为 1 则表示直接分配,永远不做检查,这种情况特别适合页表地址空间很大,但是实际使用内存很少的情况,或者说页表是稀疏的情况下适合使用。如果为 2 表示不要过度使用,这种情况下总的可分配空间计算为:(total_RAM - total_huge_TLB) * overcommit_ratio / 100 + total_swap,其中 total_RAM 表示总的物理内存,total_huge_TLB 表示为大页面预留的内存,overcommit_ratio 为另一个内核参数,表示内存百分比过载值,默认为 50,也就是 50%,total_swap 表示交换空间,也就是说这种情况下限制为物理内存减去预留内存的一半再加上交换空间,如果申请的虚拟内存大于这个值,那么就会拒绝了,这个值的严格程度是介于 0 和 1 之间的。关于内核参数的具体文档可以参考:http://man7.org/linux/man-pages/man5/proc.5.html
如果我们仔细观察,在 Redis 服务启动时,日志中会给出警告建议 vm.overcommit_memory 值设置为 1,如果确实出现了上面的报错,那么我们就很有必要调整这个内核参数了:
sysctl -w vm.overcommit_memory=1 > /etc/sysctl.conf
调整这个参数之后,Redis 再 fork 子进程时通常都不会再出现错误了。
6.4 CPU 核心绑定
我们通常不用为 Redis 绑定 CPU 核心,而是由操作系统自己调度即可,性能基本上没有什么影响。如果手动做了绑核,有可能性能反而下降,因为 Redis 不仅有主线程,还会创建子进程、子线程执行持久化、异步写盘、lazyfree 删除过期数据、释放连接等各类耗时操作,如果我们将 Redis 进程绑定到 1 个 CPU 核心,那么其中的线程和子进程都会集成主进程的 CPU 亲和性,本来 Redis 采用多线程、子进程的目的就是为了利用多核的特性,减少主进程的开销,绑核之后反而所有的进程、线程都堆在一个核上,只能不断抢占 CPU 资源,导致性能降低和延迟增大。
所以,即使要绑定 CPU,也是绑定多个 CPU,让所有子进程、线程都可以各自使用独立的核心而不会相互干扰,同时也要减小进程和线程上下文切换的开销,因此手动设置还是非常麻烦的。但是 Redis 从 6.0 开始,本身就支持对 CPU 核心的配置,不需要再用传统的方式绑核了,我们来看下主要的配置:
# 设置 Redis Server 和 IO 线程使用的 CPU 核心:0,2,4,6, 下面 2 是步长:
# server-cpulist 0-7:2
#
# 设置后台 bio 线程绑定到 CPU 核心:1,3
# bio-cpulist 1,3
#
# 设置 AOF rewrite 子进程绑定到 CPU 核心:8,9,10,11
# aof-rewrite-cpulist 8-11
#
# 设置 RDB 子进程绑定到 CPU 核心:1,10,11
# bgsave-cpulist 1,10-11
通过上面的配置就可以使得 Redis 启动时自动绑定 CPU 核心,避免 CPU 的抢占和上下文切换的开销。我们还需要格外注意当前系统的 NUMA 架构情况,尽量让同一个 Redis 实例用到的所有 CPU 核心都在同一个 NUMA 节点上,从而降低跨 NUMA node 通信的开销。
不过在绝大多数情况下,我们重点应该优化 Redis 的慢查询、bigkey 等和业务结合上的存在的瓶颈,这部分是最容易出现明显问题的,当优化好这部分之后,通常 Redis 的性能也就不存在瓶颈了,绑定核心能带来的提升远不如从业务和 Redis 使用上优化带来的提升。所以,除非要求非常严苛的条件,并且对计算机体系结构有必要的了解,否则我们不建议做绑核的配置。
6.5 避免大量的短连接
通常情况下我们使用各类编程语言中的 Redis 客户端库,都是采用连接池或者至少是单个长连接的情况,这些库目前已经足够成熟了。但是如果研发人员使用不当,比如每次操作都创建新的连接或者每个线程中都新创建连接,这种情况下其实 TCP 的握手连接和挥手关闭过程也会带来一定的开销,当访问频率特别高的时候,整体的延迟就比较明显了。
可以查看 Redis 服务当前的连接数量,来确认是否有大量的短连接存在:
netstat -an | grep :6379
一方面是看连接数量是不是比较大,另外还要看客户端的端口是不是经常变化,如果变化非常频繁,则对应的客户端代码需要考虑优化,这种情况下修改业务代码和使用逻辑,改为长连接执行命令那么这部分性能就可以提高。
对于客户端代码,除了优化大量的短连接,还可以考虑使用 Pipeline、Lua 等封装多个频繁的操作,降低多次执行命令的通信开销并增大吞吐,也可以比较好地提升性能。
以上就是 Redis 在生产环境中常见的实战优化经验,虽然解决问题的方法有时候比较简单,但是其中涉及到的知识点是丰富的,会涵盖:CPU、内存、存储、网络、数据结构和算法、操作系统等众多的知识点,如果能够比较好地吸收并利用,不仅对于 Redis,对于其他系统的优化都会带来帮助或启发。
当前文章的内容参考了微信公众号 [水滴与银弹] 的总结,在此对作者表示感谢!查看原文请点击打开链接。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号