
Redis持久化技术浅析
Redis是一种内存数据库,数据都存储在内存中,因此可以快速地直接基于内存中的数据结构进行高性能的操作,但是所有数据都在内存中,一旦服务器宕机,内存中的数据就会全部丢失,数据将无法恢复,因此Redis也有自己的持久化机制,但是要注意这个持久化和普通数据库的持久化不同,持久化文件必须全部读取到内存才可以使用,而不是按需加载,同时后续会将最新的修改写入到磁盘。
Redis持久化有两种机制,分别是:AOF(Append Only File)和RDB(Redis Database)。
1.持久化全局入口
以Redis 5.0的源码进行分析,入口在server.c代码中,在main函数中会调用server初始化:
// https://github.com/redis/redis/blob/5.0/src/server.c
void initServer(void) {
// ...
server.hz = server.config_hz;
// ...
/* Create the timer callback, this is our way to process many background
* operations incrementally, like clients timeout, eviction of unaccessed
* expired keys and so forth. */
// 添加定时任务事件回调
if (aeCreateTimeEvent(server.el, 1, serverCron, NULL, NULL) == AE_ERR) {
serverPanic("Can't create event loop timers.");
exit(1);
}
// ...
}
int main(int argc, char **argv) {
// ...
server.supervised = redisIsSupervised(server.supervised_mode);
int background = server.daemonize && !server.supervised;
if (background) daemonize();
// Server初始化
initServer();
if (background || server.pidfile) createPidFile();
redisSetProcTitle(argv[0]);
redisAsciiArt();
checkTcpBacklogSettings();
// ...
aeSetBeforeSleepProc(server.el,beforeSleep);
aeSetAfterSleepProc(server.el,afterSleep);
aeMain(server.el);
aeDeleteEventLoop(server.el);
return 0;
}
首先在main函数中调用initServer()进行服务初始化,初始化内容包括:信号监听、DB初始化、添加各类回调任务等,看到其中添加了serverCron这个回调函数,这里面就负责持久化相关的实现,具体的调用频次是依赖于server.config_hz的配置,在redis.conf中有相关的配置:
# Redis calls an internal function to perform many background tasks, like
# closing connections of clients in timeout, purging expired keys that are
# never requested, and so forth.
#
# Not all tasks are performed with the same frequency, but Redis checks for
# tasks to perform according to the specified "hz" value.
#
# By default "hz" is set to 10. Raising the value will use more CPU when
# Redis is idle, but at the same time will make Redis more responsive when
# there are many keys expiring at the same time, and timeouts may be
# handled with more precision.
#
# The range is between 1 and 500, however a value over 100 is usually not
# a good idea. Most users should use the default of 10 and raise this up to
# 100 only in environments where very low latency is required.
hz 10
这个值默认是10,也就是说每秒会执行10次后台任务,也就是每间隔100ms执行1次,如果提高这个值的设置会使空闲时CPU的占用更高,如果需要更低的延迟可以将参数适当调大,但是不要超过100,hz的范围被限制在[1, 500]
具体的事件驱动是由专门的异步库来封装,上面调用到的aeCreateTimeEvent和asMain都在ae.c中进行了封装:
// https://github.com/redis/redis/blob/5.0/src/ae.c
/* Include the best multiplexing layer supported by this system.
* The following should be ordered by performances, descending. */
#ifdef HAVE_EVPORT
#include "ae_evport.c"
#else
#ifdef HAVE_EPOLL
#include "ae_epoll.c"
#else
#ifdef HAVE_KQUEUE
#include "ae_kqueue.c"
#else
#include "ae_select.c"
#endif
#endif
#endif
// ...
void aeMain(aeEventLoop *eventLoop) {
eventLoop->stop = 0;
while (!eventLoop->stop) {
if (eventLoop->beforesleep != NULL)
// 由server.c定义回调, 用于前置准备文件描述符
eventLoop->beforesleep(eventLoop);
// 事件处理
aeProcessEvents(eventLoop, AE_ALL_EVENTS|AE_CALL_AFTER_SLEEP);
}
}
// ...
Redis在aeMain中不断循环进行事件处理,这里底层使用的异步库分别为:evport、epoll、kqueue、select这几个,其中evport属于Solaris 10平台,然后epoll属于linux平台,kqueue属于BSD和OS X平台,最后的选择是select方式,其中evport/epoll/kqueue的复杂度都是O(1),select基于描述符扫描,复杂度是O(n)。
然后再回到server.c中重点来看一下serverCron函数的逻辑:
// server.h 静态定义
#define CONFIG_DEFAULT_DYNAMIC_HZ 1 /* Adapt hz to # of clients.*/
#define CONFIG_DEFAULT_HZ 10 /* Time interrupt calls/sec. */
#define CONFIG_MIN_HZ 1
#define CONFIG_MAX_HZ 500
#define MAX_CLIENTS_PER_CLOCK_TICK 200 /* HZ is adapted based on that. */
#define run_with_period(_ms_) if ((_ms_ <= 1000/server.hz) || !(server.cronloops%((_ms_)/(1000/server.hz))))
// ...
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) {
// ...
server.hz = server.config_hz;
/* Adapt the server.hz value to the number of configured clients. If we have
* many clients, we want to call serverCron() with an higher frequency. */
// 动态调整任务处理频率
if (server.dynamic_hz) {
while (listLength(server.clients) / server.hz >
MAX_CLIENTS_PER_CLOCK_TICK)
{
server.hz *= 2;
if (server.hz > CONFIG_MAX_HZ) {
server.hz = CONFIG_MAX_HZ;
break;
}
}
}
// ...
/* We need to do a few operations on clients asynchronously. */
clientsCron();
/* Handle background operations on Redis databases. */
databasesCron();
/* Start a scheduled AOF rewrite if this was requested by the user while
* a BGSAVE was in progress. */
if (server.rdb_child_pid == -1 && server.aof_child_pid == -1 &&
server.aof_rewrite_scheduled)
{
rewriteAppendOnlyFileBackground();
}
/* Check if a background saving or AOF rewrite in progress terminated. */
if (server.rdb_child_pid != -1 || server.aof_child_pid != -1 ||
ldbPendingChildren())
{
int statloc;
pid_t pid;
// WNOHANG 非阻塞 WUNTRACED 表示当进程收到SIGTTIN, SIGTTOU, SIGSSTP, SIGTSTOP时也会返回
if ((pid = wait3(&statloc,WNOHANG,NULL)) != 0) {
int exitcode = WEXITSTATUS(statloc);
int bysignal = 0;
if (WIFSIGNALED(statloc)) bysignal = WTERMSIG(statloc);
if (pid == -1) {
serverLog(LL_WARNING,"wait3() returned an error: %s. "
"rdb_child_pid = %d, aof_child_pid = %d",
strerror(errno),
(int) server.rdb_child_pid,
(int) server.aof_child_pid);
} else if (pid == server.rdb_child_pid) {
backgroundSaveDoneHandler(exitcode,bysignal);
if (!bysignal && exitcode == 0) receiveChildInfo();
} else if (pid == server.aof_child_pid) {
backgroundRewriteDoneHandler(exitcode,bysignal);
if (!bysignal && exitcode == 0) receiveChildInfo();
} else {
if (!ldbRemoveChild(pid)) {
serverLog(LL_WARNING,
"Warning, detected child with unmatched pid: %ld",
(long)pid);
}
}
updateDictResizePolicy();
closeChildInfoPipe();
}
} else {
/* If there is not a background saving/rewrite in progress check if
* we have to save/rewrite now. */
for (j = 0; j < server.saveparamslen; j++) {
struct saveparam *sp = server.saveparams+j;
/* Save if we reached the given amount of changes,
* the given amount of seconds, and if the latest bgsave was
* successful or if, in case of an error, at least
* CONFIG_BGSAVE_RETRY_DELAY seconds already elapsed. */
if (server.dirty >= sp->changes &&
server.unixtime-server.lastsave > sp->seconds &&
(server.unixtime-server.lastbgsave_try >
CONFIG_BGSAVE_RETRY_DELAY ||
server.lastbgsave_status == C_OK))
{
serverLog(LL_NOTICE,"%d changes in %d seconds. Saving...",
sp->changes, (int)sp->seconds);
rdbSaveInfo rsi, *rsiptr;
rsiptr = rdbPopulateSaveInfo(&rsi);
rdbSaveBackground(server.rdb_filename,rsiptr);
break;
}
}
/* Trigger an AOF rewrite if needed. */
if (server.aof_state == AOF_ON &&
server.rdb_child_pid == -1 &&
server.aof_child_pid == -1 &&
server.aof_rewrite_perc &&
server.aof_current_size > server.aof_rewrite_min_size)
{
long long base = server.aof_rewrite_base_size ?
server.aof_rewrite_base_size : 1;
long long growth = (server.aof_current_size*100/base) - 100;
if (growth >= server.aof_rewrite_perc) {
serverLog(LL_NOTICE,"Starting automatic rewriting of AOF on %lld%% growth",growth);
rewriteAppendOnlyFileBackground();
}
}
}
/* AOF postponed flush: Try at every cron cycle if the slow fsync
* completed. */
if (server.aof_flush_postponed_start) flushAppendOnlyFile(0);
/* AOF write errors: in this case we have a buffer to flush as well and
* clear the AOF error in case of success to make the DB writable again,
* however to try every second is enough in case of 'hz' is set to
* an higher frequency. */
run_with_period(1000) {
if (server.aof_last_write_status == C_ERR)
flushAppendOnlyFile(0);
}
// ...
server.cronloops++;
return 1000/server.hz;
}
有几个重点需要解释一下:
- 最上面的动态调整任务频率的逻辑是,如果配置文件中
dynamic-hz配置项打开表示自动根据客户端数量自动调整任务的频率,这个配置项默认是开启的,如果客户端的数量除以当前的hz值大于MAX_CLIENTS_PER_CLOCK_TICK的值,会将实际的任务执行频率变成之前的两倍,直到不符合while条件或者大于CONFIG_MAX_HZ的值都会退出循环,其中MAX_CLIENTS_PER_CLOCK_TICK的值是200,CONFIG_MAX_HZ的值是500。客户端数量除以当前配置的频率,表示每个客户端需要多少次周期才可以有一次被处理的机会,如果客户端数量太多导致平均大于200个周期才可以处理,会导致响应过慢所以这个时候将当前的处理频率加倍,但是如果超过500又会导致CPU占用比较高,因此最高会将频率调整为500,从而保证客户端的响应的实时性。 - 如果此时由用户请求重写AOF文件并且此时也没有正在执行的AOF或RBD持久化进程在运行,则会启动重写任务。
- 然后就到了比较核心的持久化逻辑部分,如果此时正在有持久化任务在执行中或者存在脚本没有执行完,那么则获取子进程的状态用于资源的回收,否则将判断是否达到持久化的条件,从而后台执行持久化的任务。
主要分析下持久化的判断部分,调用wait3函数除了获取子进程的状态还可以获得子进程的资源信息,由rusage结构体指针带出来,参数WNOHANG表示wait no hang,主进程不会阻塞等待子进程而是会马上返回,如果子进程都处于正常运行状态,直接返回0,上面的逻辑都会跳出,如果返回的不是0说明子进程执行完了,子进程执行完之后如果主进程还存在并且没有显示调用wait相关的函数,那么子进程的状态会变为defunct状态而成为僵尸进程,Redis会在执行下一个周期任务时再次进来拿到进程状态,如果返回的pid和RDB或者AOF子进程的pid一致,则会执行相关的回收工作,也就是backgroundSaveDoneHandler或者backgroundRewriteDoneHandler操作,主要是做一些状态的设置,最后会执行updateDictResizePolicy函数开启rehash操作。
反过来如果此时没有运行任何的持久化任务,就进入else分支,遍历相应的配置参数,如果满足key的修改个数和时间的限制则优先执行RDB持久化的任务,然后判断如果开启AOF并且此时没有其他任务运行,且满足当前的文件大小大于最小的重写大小阈值则出发AOF的重写。最小的限制由配置文件中的auto-aof-rewrite-min-size配置,默认是64M,满足条件也不一定进行重写,而是将当前大小和基准大小进行比较,当比基准大小大1倍以上时才触发重写,基准大小在启动Redis服务时被设置为AOF文件的初始大小并且在每一次重写完成后更新为重写后的大小,具体可以参考aof.c中backgroundRewriteDoneHandler和loadAppendOnlyFile这两个函数的源码。
最后上面的run_with_period函数表示多个周期执行1次的意思,具体可以参考server.h中定义的宏,如果设置的值小于周期,也就是每个周期都执行,否则会用设置时间除以周期时间,得到余数,余数是0时则执行一次,也就是指定周期个数执行一次,具体循环通过cronloops变量来计数。
然后就要进入到具体的持久化逻辑中了,下面主要来分析一下RDB和AOF持久化的大致过程。
2.RDB持久化
RDB持久化是Redis首选的默认持久化方式,通常我们叫做内存快照,表示内存中的数据在某一个时刻的状态记录,执行RDB持久化就是将当前内存中的数据写入到磁盘的过程,当Redis重新启动时,会从快照中恢复数据,RDB是比较紧凑的存储格式,写入和恢复速度都比较快,但是每一次持久化都是全量的数据写入,所以当数据规模越大的时候,写入的RDB文件也越大,磁盘写入的开销也会变大,所以要配置合适的参数在适当的时候执行持久化,避免频繁的持久化操作。
另外由于Redis是单线程的,如果在主线程中执行持久化必然会带来线程的阻塞,所以自动的持久化操作是采用fork一个子进程的方式来完成,这样不会影响主进程的运行,另外Redis还提供两个命令用于手动进行持久化,分别是save和bgsave,其中save是同步方式执行,会阻塞其他所有的操作,所以几乎不怎么使用,在某些极端情况下例如当Linux系统进程耗尽的时候为了保存数据可能会用到,通常bgsave命令用的会比较多一些,这个和后台自动的RDB持久化操作是一样的,只是以手动的方式触发。
和RDB相关的持久化配置如下:
save 900 1
save 300 10
save 60 10000
stop-writes-on-bgsave-error yes
rdbcompression yes
rdbchecksum yes
dbfilename dump.rdb
dir ./
其中save配置决定持久化的时机,例如默认情况下,900s变动的key超过1个则进行持久化,300s变动的key超过10个则进行持久化,60s变动的key超过10000个则进行持久化,多个持久化的条件是或的关系,只要1个条件触发就会执行,如果想关闭RDB持久化则可以注释掉所有的指令或者配置为空:
save ""
这样也就关闭了RDB持久化。
RDB持久化的操作在函数rdbSaveBackground中,大致的源码如下:
int rdbSaveBackground(char *filename, rdbSaveInfo *rsi) {
pid_t childpid;
long long start;
if (server.aof_child_pid != -1 || server.rdb_child_pid != -1) return C_ERR;
server.dirty_before_bgsave = server.dirty;
server.lastbgsave_try = time(NULL);
openChildInfoPipe();
start = ustime();
if ((childpid = fork()) == 0) {
int retval;
/* Child */
closeClildUnusedResourceAfterFork();
redisSetProcTitle("redis-rdb-bgsave");
retval = rdbSave(filename,rsi);
if (retval == C_OK) {
size_t private_dirty = zmalloc_get_private_dirty(-1);
if (private_dirty) {
serverLog(LL_NOTICE,
"RDB: %zu MB of memory used by copy-on-write",
private_dirty/(1024*1024));
}
server.child_info_data.cow_size = private_dirty;
sendChildInfo(CHILD_INFO_TYPE_RDB);
}
exitFromChild((retval == C_OK) ? 0 : 1);
} else {
/* Parent */
server.stat_fork_time = ustime()-start;
server.stat_fork_rate = (double) zmalloc_used_memory() * 1000000 / server.stat_fork_time / (1024*1024*1024); /* GB per second. */
latencyAddSampleIfNeeded("fork",server.stat_fork_time/1000);
if (childpid == -1) {
closeChildInfoPipe();
server.lastbgsave_status = C_ERR;
serverLog(LL_WARNING,"Can't save in background: fork: %s",
strerror(errno));
return C_ERR;
}
serverLog(LL_NOTICE,"Background saving started by pid %d",childpid);
server.rdb_save_time_start = time(NULL);
server.rdb_child_pid = childpid;
server.rdb_child_type = RDB_CHILD_TYPE_DISK;
updateDictResizePolicy();
return C_OK;
}
return C_OK; /* unreached */
}
void updateDictResizePolicy(void) {
if (server.rdb_child_pid == -1 && server.aof_child_pid == -1)
dictEnableResize();
else
dictDisableResize();
}
可以看到进入rdbSaveBackground函数后,首先执行fork调用开辟1个子进程用于执行持久化的操作,父进程主要是执行了updateDictResizePolicy将全局哈希表的rehash关闭,就直接返回了,然后子进程会修改进程名为redis-rdb-bgsave然后进入rdbSave函数:
// server.h
#define REDIS_AUTOSYNC_BYTES (1024*1024*32) /* fdatasync every 32MB */
/* Save the DB on disk. Return C_ERR on error, C_OK on success. */
int rdbSave(char *filename, rdbSaveInfo *rsi) {
char tmpfile[256];
char cwd[MAXPATHLEN]; /* Current working dir path for error messages. */
FILE *fp;
rio rdb;
int error = 0;
snprintf(tmpfile,256,"temp-%d.rdb", (int) getpid());
fp = fopen(tmpfile,"w");
if (!fp) {
char *cwdp = getcwd(cwd,MAXPATHLEN);
serverLog(LL_WARNING,
"Failed opening the RDB file %s (in server root dir %s) "
"for saving: %s",
filename,
cwdp ? cwdp : "unknown",
strerror(errno));
return C_ERR;
}
rioInitWithFile(&rdb,fp);
if (server.rdb_save_incremental_fsync)
rioSetAutoSync(&rdb,REDIS_AUTOSYNC_BYTES);
if (rdbSaveRio(&rdb,&error,RDB_SAVE_NONE,rsi) == C_ERR) {
errno = error;
goto werr;
}
/* Make sure data will not remain on the OS's output buffers */
if (fflush(fp) == EOF) goto werr;
if (fsync(fileno(fp)) == -1) goto werr;
if (fclose(fp) == EOF) goto werr;
/* Use RENAME to make sure the DB file is changed atomically only
* if the generate DB file is ok. */
if (rename(tmpfile,filename) == -1) {
char *cwdp = getcwd(cwd,MAXPATHLEN);
serverLog(LL_WARNING,
"Error moving temp DB file %s on the final "
"destination %s (in server root dir %s): %s",
tmpfile,
filename,
cwdp ? cwdp : "unknown",
strerror(errno));
unlink(tmpfile);
return C_ERR;
}
serverLog(LL_NOTICE,"DB saved on disk");
server.dirty = 0;
server.lastsave = time(NULL);
server.lastbgsave_status = C_OK;
return C_OK;
werr:
serverLog(LL_WARNING,"Write error saving DB on disk: %s", strerror(errno));
fclose(fp);
unlink(tmpfile);
return C_ERR;
}
// https://github.com/redis/redis/blob/5.0/src/rio.c
void rioInitWithFile(rio *r, FILE *fp) {
*r = rioFileIO;
r->io.file.fp = fp;
r->io.file.buffered = 0;
r->io.file.autosync = 0;
}
// 设置自动提交
void rioSetAutoSync(rio *r, off_t bytes) {
serverAssert(r->read == rioFileIO.read);
r->io.file.autosync = bytes;
}
/* Returns 1 or 0 for success/failure. */
static size_t rioFileWrite(rio *r, const void *buf, size_t len) {
size_t retval;
retval = fwrite(buf,len,1,r->io.file.fp);
r->io.file.buffered += len;
if (r->io.file.autosync &&
r->io.file.buffered >= r->io.file.autosync)
{
fflush(r->io.file.fp);
redis_fsync(fileno(r->io.file.fp));
r->io.file.buffered = 0;
}
return retval;
}
首先Redis子进程创建了一个临时文件,名为:temp-<pid>.rdb,然后调用rioInitWithFile初始化了rio,这个是Redis自己封装的IO库,然后如果在redis.conf中开启了rdb-save-incremental-fsync配置则会启动自动刷盘,默认这个参数是开启的,每次写入字节的大小由宏REDIS_AUTOSYNC_BYTES定义,为32M,在rioFileWrite可以看到当写入字节数大于autosync的值时,会执行flush操作将数据写入到磁盘,默认文件是先写入操作系统缓存中,刷盘时机不确定,开启自动刷新后一方面可以提高数据的可靠性,另一方面也可以避免最终刷盘带来的性能开销。
然后会调用rdbSaveRio执行具体的数据持久化操作,最终执行完毕后会将临时文件重命名为dump.rdb,这里rename调用是原子性的。另外Redis执行异常处理的技巧是将资源关闭操作定义为一个label也就是werr,然后在遇到错误时通过goto统一跳转执行,这是在C中异常处理的常用模式。
然后大致看一下rdbSaveRio执行的操作:
// rdb.h
#define RDB_VERSION 9
#define RDB_SAVE_NONE 0
int rdbSaveRio(rio *rdb, int *error, int flags, rdbSaveInfo *rsi) {
dictIterator *di = NULL;
dictEntry *de;
char magic[10];
int j;
uint64_t cksum;
size_t processed = 0;
if (server.rdb_checksum)
rdb->update_cksum = rioGenericUpdateChecksum;
snprintf(magic,sizeof(magic),"REDIS%04d",RDB_VERSION);
if (rdbWriteRaw(rdb,magic,9) == -1) goto werr;
if (rdbSaveInfoAuxFields(rdb,flags,rsi) == -1) goto werr;
if (rdbSaveModulesAux(rdb, REDISMODULE_AUX_BEFORE_RDB) == -1) goto werr;
for (j = 0; j < server.dbnum; j++) {
redisDb *db = server.db+j;
dict *d = db->dict;
if (dictSize(d) == 0) continue;
di = dictGetSafeIterator(d);
/* Write the SELECT DB opcode */
if (rdbSaveType(rdb,RDB_OPCODE_SELECTDB) == -1) goto werr;
if (rdbSaveLen(rdb,j) == -1) goto werr;
/* Write the RESIZE DB opcode. We trim the size to UINT32_MAX, which
* is currently the largest type we are able to represent in RDB sizes.
* However this does not limit the actual size of the DB to load since
* these sizes are just hints to resize the hash tables. */
uint64_t db_size, expires_size;
db_size = dictSize(db->dict);
expires_size = dictSize(db->expires);
if (rdbSaveType(rdb,RDB_OPCODE_RESIZEDB) == -1) goto werr;
if (rdbSaveLen(rdb,db_size) == -1) goto werr;
if (rdbSaveLen(rdb,expires_size) == -1) goto werr;
/* Iterate this DB writing every entry */
while((de = dictNext(di)) != NULL) {
sds keystr = dictGetKey(de);
robj key, *o = dictGetVal(de);
long long expire;
initStaticStringObject(key,keystr);
expire = getExpire(db,&key);
if (rdbSaveKeyValuePair(rdb,&key,o,expire) == -1) goto werr;
/* When this RDB is produced as part of an AOF rewrite, move
* accumulated diff from parent to child while rewriting in
* order to have a smaller final write. */
if (flags & RDB_SAVE_AOF_PREAMBLE &&
rdb->processed_bytes > processed+AOF_READ_DIFF_INTERVAL_BYTES)
{
processed = rdb->processed_bytes;
aofReadDiffFromParent();
}
}
dictReleaseIterator(di);
di = NULL; /* So that we don't release it again on error. */
}
/* If we are storing the replication information on disk, persist
* the script cache as well: on successful PSYNC after a restart, we need
* to be able to process any EVALSHA inside the replication backlog the
* master will send us. */
if (rsi && dictSize(server.lua_scripts)) {
di = dictGetIterator(server.lua_scripts);
while((de = dictNext(di)) != NULL) {
robj *body = dictGetVal(de);
if (rdbSaveAuxField(rdb,"lua",3,body->ptr,sdslen(body->ptr)) == -1)
goto werr;
}
dictReleaseIterator(di);
di = NULL; /* So that we don't release it again on error. */
}
if (rdbSaveModulesAux(rdb, REDISMODULE_AUX_AFTER_RDB) == -1) goto werr;
/* EOF opcode */
if (rdbSaveType(rdb,RDB_OPCODE_EOF) == -1) goto werr;
/* CRC64 checksum. It will be zero if checksum computation is disabled, the
* loading code skips the check in this case. */
cksum = rdb->cksum;
memrev64ifbe(&cksum);
if (rioWrite(rdb,&cksum,8) == 0) goto werr;
return C_OK;
werr:
if (error) *error = errno;
if (di) dictReleaseIterator(di);
return C_ERR;
}
/* Save a few default AUX fields with information about the RDB generated. */
int rdbSaveInfoAuxFields(rio *rdb, int flags, rdbSaveInfo *rsi) {
int redis_bits = (sizeof(void*) == 8) ? 64 : 32;
int aof_preamble = (flags & RDB_SAVE_AOF_PREAMBLE) != 0;
/* Add a few fields about the state when the RDB was created. */
if (rdbSaveAuxFieldStrStr(rdb,"redis-ver",REDIS_VERSION) == -1) return -1;
if (rdbSaveAuxFieldStrInt(rdb,"redis-bits",redis_bits) == -1) return -1;
if (rdbSaveAuxFieldStrInt(rdb,"ctime",time(NULL)) == -1) return -1;
if (rdbSaveAuxFieldStrInt(rdb,"used-mem",zmalloc_used_memory()) == -1) return -1;
/* Handle saving options that generate aux fields. */
if (rsi) {
if (rdbSaveAuxFieldStrInt(rdb,"repl-stream-db",rsi->repl_stream_db)
== -1) return -1;
if (rdbSaveAuxFieldStrStr(rdb,"repl-id",server.replid)
== -1) return -1;
if (rdbSaveAuxFieldStrInt(rdb,"repl-offset",server.master_repl_offset)
== -1) return -1;
}
if (rdbSaveAuxFieldStrInt(rdb,"aof-preamble",aof_preamble) == -1) return -1;
return 1;
}
static int rdbWriteRaw(rio *rdb, void *p, size_t len) {
if (rdb && rioWrite(rdb,p,len) == 0)
return -1;
return len;
}
首先头部写入了REDIS+<RDB_VERSION>的字符串,当前RDB_VERSION的值为9,也就是写入REDIS0009,然后会执行rdbSaveInfoAuxFields写入一些辅助信息,例如Redis的版本、位数、当前时间、内存占用等信息,如果查看rdb文件也可以看到头部的一些信息:
head -c 128 dump.rdb

然后往下会遍历每一个库,获取里面全局哈希表的Iterator,循环迭代,最后调用rdbSaveKeyValuePair将Key和Value保存到文件中,执行具体的保存是在rdbSaveObject函数中,这里面做了所有类型的判断并将其转为字节数组写入。
在函数最后,会写入checksum到文件尾部,这样整个写入就执行完毕并返回等待主进程的回收。
上面是RDB的大致过程,然后来总结一下:
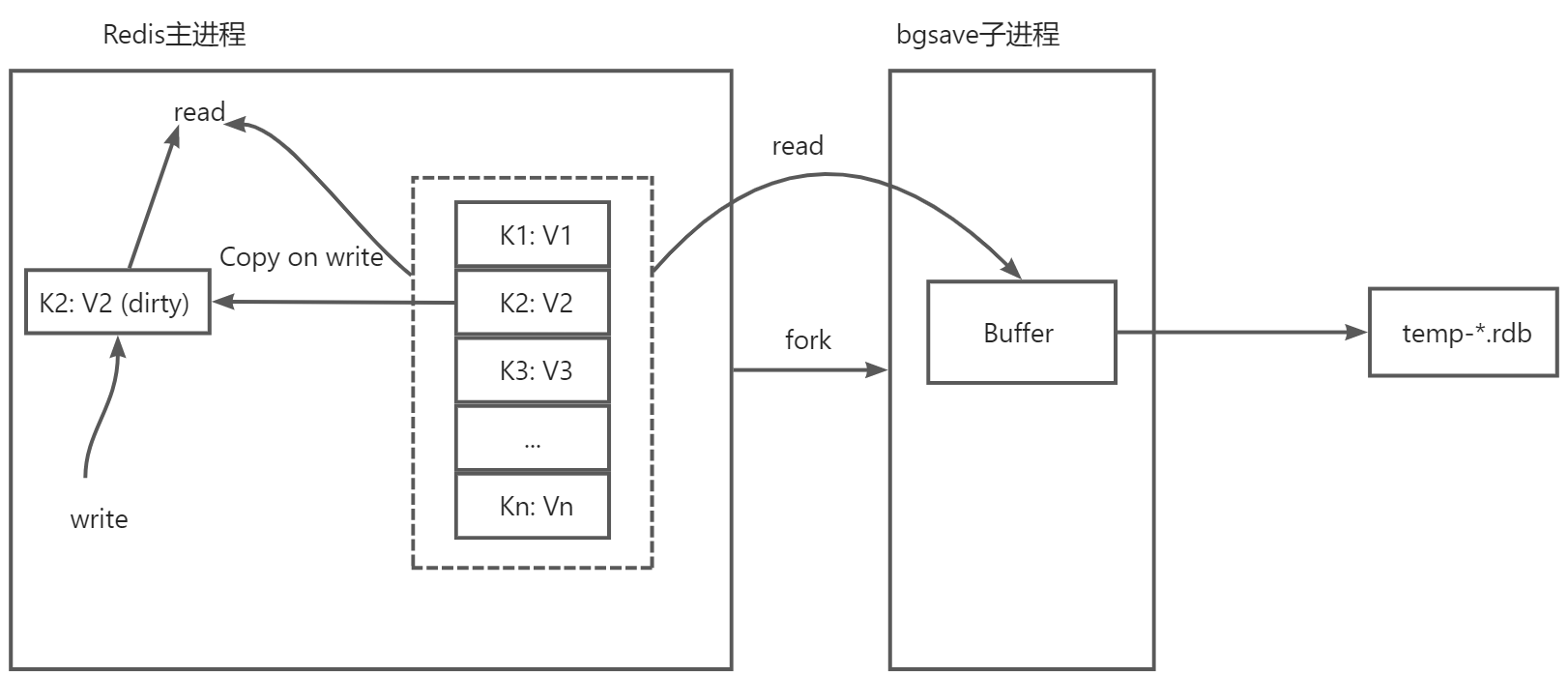
RDB持久化过程中主要的问题就是在生成快照的过程中,数据将如何进行修改的问题,快照其实就是在这一时刻的状态,所以我们不希望快照期间快照本身的数据有变化,但是Redis主线程同时又能够接受请求正常更新数据,更新的内容对快照子进程来说应该是不可见的,因为不希望对快照的状态产生影响,而恰好操作系统解决了这些问题,首先bgsave进程是由主线程fork出来的,因此bgsave进程共享主线程的页表,这点是操作系统为了提升fork的性能所做的优化,这样不需要进行全量的内存拷贝,如果主线程此时来了读操作,那么直接读就可以了,和子进程没有任何影响,但是如果主线程接收到了写操作,那么要修改的这块数据会在主线程中复制一份生成原来数据的副本,主线程会自动将映射指向这块副本空间,然后执行写操作,这时候子进程bgsave仍然是读取到的原来的内存空间,所以保存快照的过程是不受影响的,这就是写时复制(Copy-on-write)技术,在执行快照的同时,正常处理写操作,当子进程运行完毕后,没有引用的这部分内存会被释放掉。
由于快照期间会发生数据的修改,如果两次快照之间数据发生了变化,第二次快照还没有执行服务器就挂掉了,那么这个时候数据仍然会出现丢失的情况,但是如果频繁的执行全量快照,会给磁盘带来巨大的压力,在极端情况下如果持久化过程中执行频繁的写入那么主线程和子进程的内存可能完全不一样了,内存最高占用可以到原来的2倍,在生产环境配置时要调整好自动快照的频率,在性能和可靠性上做一个平衡,Redis也考虑到的频繁执行全量快照的情况,所以在代码中限制在bgsave子进程执行的过程中是无法启动第二个bgsave进程的。
2.AOF
AOF持久化其实是一种类似日志的形式,会将所有执行过的命令写入到日志中,在恢复时读取命令重新执行一遍就完成恢复了,这个和通常的WAL(Write Ahead Log)类似,也叫预写日志,也就是说在实际写入数据前,先把数据记录到日志中,以便在故障时可以自动恢复,从而保证写入的事务性。但是AOF不同的地方在于写的时机正好反过来,可以称之为“写后”日志,也就是Redis先执行命令,在内存中完成数据结构的操作,然后再将命令写入日志,那么Redis为什么要这么做呢?因为考虑到解析语句会带来额外的开销,所以Redis写入aof文件时并不会对命令做正确性检查,所以如果先写aof文件可能会写入一条错误的命令,而先执行再写,在执行阶段出现问题的命令肯定就是不合法的命令,也就不会被记录到aof文件中,这样就避免命令解析校验所带来的开销,主要就是避免记录错误指令,另外就是在命令执行之后写入日志,不会阻塞当前客户端的执行,也就是说客户端不需要等待写操作完成才继续往下执行,只需要等待内存操作完之后客户端就可以直接向下执行,所以也可以提高性能。
写入的格式大致如下:
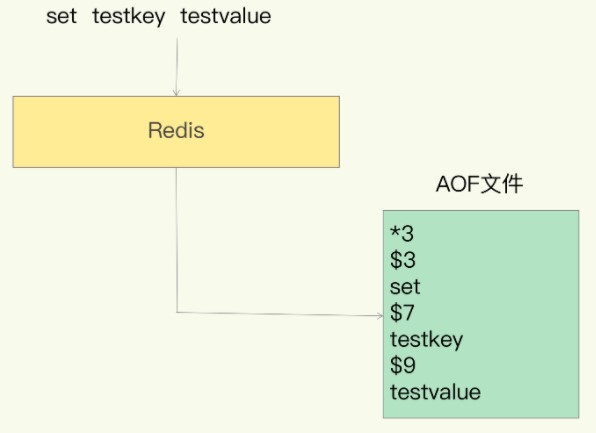
*3表示3个操作符,$3表示下一个指令或者参数的长度,这样依次类推。
AOF也存在一些问题,最明显的就是数据丢失,例如刚执行完一个命令,还没有来得及记录日志服务器就宕机了,这时候这个已经对数据执行的修改也就丢失了,因此会带来数据不一致的风险,如果是用作缓存没什么大碍,如果当做数据库是达不到标准的。另外虽然上面提到过aof后写的方式不会阻塞客户端的执行,但是假如客户端操作比较频繁或者并发比较高,可能会出现下面的情况:
客户端执行 -> 内存操作完毕 -> 写AOF(阻塞其他客户端的操作) -> 客户端执行 -> ...
由于Redis是单线程的方式,虽然第一个客户端执行没有影响,但是如果第二次执行间隔时间很短或者其他客户端执行时,由于要写AOF,因此后续的客户端仍然会等待,正常日志写的比较快没什么问题,如果当磁盘压力非常大的时候,写盘很慢的话,那么客户端的操作也会变卡。
默认情况下AOF持久化的配置如下:
appendonly no
appendfilename "appendonly.aof"
# appendfsync always
appendfsync everysec
# appendfsync no
# rewrite时不执行fsync操作
no-appendfsync-on-rewrite no
# rewrite条件
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
aof-load-truncated yes
# 是否开启混合持久化
aof-use-rdb-preamble yes
默认情况下appendonly选项是关闭的,当打开时才会执行AOF持久化,持久化的文件名称由appendfilename配置。
对于写回的策略由参数appendfsync配置,含义分别如下:
-
always:同步写回,也就是每个写命令执行完成,立刻同步将日志写入aof文件。
-
everysec:每秒写回,当命令执行完成后,先将日志写入aof文件的内存缓冲区,然后每隔1s把缓冲区内容写入磁盘。
-
no:Redis不进行主动写回,而是由操作系统控制写回,每次仅把日志写入aof文件的内存缓冲区,由操作系统决定何时将缓冲区内容写回磁盘。
这3种策略各有优缺点,像always基本可以做到不丢数据,但是每次执行命令都需要落盘操作,所以会影响主线程后续命令的性能,最慢也最安全。而no这种方式性能最高,每次只需要写缓冲区,但是落盘不受控制,完全由操作系统来负责写入,如果宕机可能会丢失比较多的数据。最后默认的策略是everysec,这是另外两种策略的折中,也就是在速度和安全性方面的折中,每秒刷盘从一定程度上提高了性能,在宕机时丢失的数据也控制在1s的区间内,是Redis的默认选项,这3种模式汇总比较如下:
| appendfsync | 含义 | 优点 | 缺点 |
|---|---|---|---|
| always | 同步写回 | 可靠性最高,数据几乎不丢 | 性能低,开销大 |
| everysec | 每秒写回 | 性能较高、可靠性适中 | 数据丢失在1s以内 |
| no | 不主动刷盘 | 高性能 | 可靠性低 |
具体写回策略要根据实际的场景配置,如果不确定,保持默认值。
然后auto-aof-rewrite-percentage和auto-aof-rewrite-min-size这两个参数是表示AOF重写的条件,为什么要进行AOF重写,原因主要如下:
- 单文件大小过大,由于aof是单个文件,如果Redis不断执行命令,那么很容易就达到数十亿甚至上百亿的命令数,因此文件会非常大,效率也会逐渐降低。
- 如果Redis服务重启,那么所有的命令都要依次被重新执行,如果文件太大,要执行的命令也特别多,恢复就会非常缓慢。
针对上面的问题尤其是第2个问题,可以看出aof文件并不能一直无限制的增大,因此需要AOF重写机制,重写机制其实也很好理解,就是Redis根据当前实际存在的数据重新创建新的文件来覆盖原来的文件,比如原来的操作是这样的:
set hello 1
set hello 2
incr hello
hset program java spring
hset program python flask
hset program golang gin
hset program python tornado
hdel program java
其中有些key是做了多次操作的,当前内存中的数据应该是下面这样:
{
"hello": "3",
"program": {
"python": "tornado",
"golang": "gin"
}
}
根据最后的状态生成一遍写入命令即可:
set hello 3
hmset program python tornado golang gin
所以上面的7条过程指令就被压缩为这2条了,按照最终状态重写可以丢掉中间不必要的重复过程,这样会大大减小文件的体积。
上面两个重写条件参数的含义如下:
auto-aof-rewrite-percentage: 默认为100,表示当AOF日志大小增长至指定百分比时触发重写,通过上面的代码可以看出来Redis会以上次重写后的AOF文件大小作为基准大小,如果初次启动则以当前大小作为基准大小,然后拿当前大小和基准大小做比较,当当前大小超出基准大小指定的的百分比后,重写会被触发。例如当前配置为100,AOF文件初始大小为300M,当文件大小大于:300 + 300 * 100% = 600M时则触发重写,如果我们将该项配置为0则表示禁用重写。
auto-aof-rewrite-min-size: 指定AOF文件重写要达到的最小字节数,这样可以避免过早地重写,比如刚开始大小可能为10K,那么按照比例在20K时就会进行重写,这样太频繁,因此指定最小大小后,即使百分比达到,也不进行重写,需要超过这个指定文件的大小且满足百分比时才进行重写,默认这个最小大小是64M,所以是当AOF文件达到64M且超过基准大小的100%则触发重写操作。
然后aof-load-truncated配置项表示当文件被截断时读取到EOF后会做什么操作,可能是由于文件系统或者其他原因导致文件没有读取完就结束,默认是允许这种情况并且正常启动服务的仅会在日志中给出提示,如果想让Redis此时停下来可以配置为no,并且可以使用redis-check-aof工具尝试修复。最后需要注意的就是允许截断并不表示允许文件损坏,如果文件出现损坏,无论这个配置是开启还是关闭Redis都会报错退出。
aof-use-rdb-preamble表示是否开启混合持久化,默认是开启的,Redis从4.0版本开始就开始支持混合使用AOF和RDB的持久化方法,只是默认是关闭的,从5.0开始就默认将混合持久化打开了,也就是说我们在配置AOF持久化的时候,其实是一种混合的方式,这种混合的方式其实是在AOF的基础上实现的,首先是按照AOF的方式追加命令,当AOF文件满足一定的条件时会触发重写,而这个重写的时机恰好会执行混合持久化的操作,在重写的时候将内容以RDB的格式保存,但是仍然写入AOF文件,当重写完成之后,随后的写操作仍然按照指令文本的方式追加,到下一次重写时仍然转换为RDB重写到文件头部,如此往复,这样在两次快照之间通过比较轻量的AOF持久化来实时保存数据,在重写时压缩为快照以节省大量的空间,写入速度比较快,同时恢复时也可以提升性能:
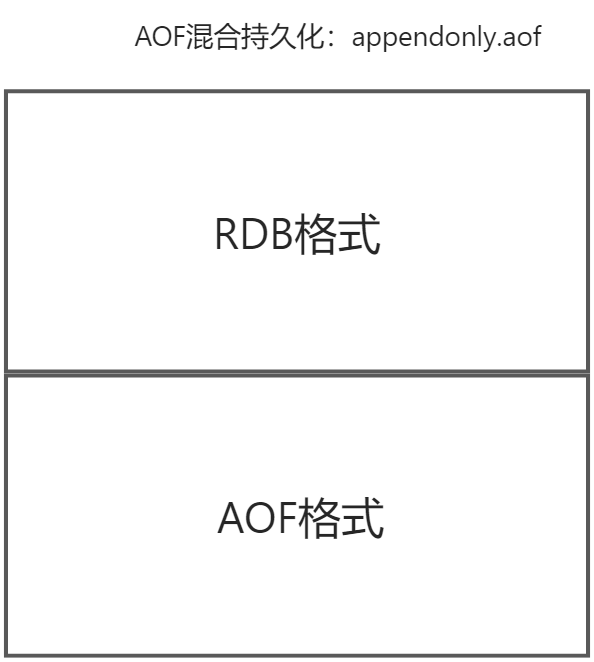
AOF写入要涉及到两个部分,分别是实时写入和AOF重写。
2.1.AOF实时写入
当开启AOF时,Redis在实时处理请求时会先将内容写入一个缓冲区,这个缓冲区在server.h中的redisServer结构体中进行了定义:
struct redisServer {
// ...
/* AOF persistence */
int aof_state; /* AOF_(ON|OFF|WAIT_REWRITE) */
int aof_fsync; /* Kind of fsync() policy */
char *aof_filename; /* Name of the AOF file */
int aof_no_fsync_on_rewrite; /* Don't fsync if a rewrite is in prog. */
int aof_rewrite_perc; /* Rewrite AOF if % growth is > M and... */
off_t aof_rewrite_min_size; /* the AOF file is at least N bytes. */
off_t aof_rewrite_base_size; /* AOF size on latest startup or rewrite. */
off_t aof_current_size; /* AOF current size. */
off_t aof_fsync_offset; /* AOF offset which is already synced to disk. */
int aof_rewrite_scheduled; /* Rewrite once BGSAVE terminates. */
pid_t aof_child_pid; /* PID if rewriting process */
list *aof_rewrite_buf_blocks; /* Hold changes during an AOF rewrite. */
sds aof_buf; /* AOF buffer, written before entering the event loop */
int aof_fd; /* File descriptor of currently selected AOF file */
int aof_selected_db; /* Currently selected DB in AOF */
time_t aof_flush_postponed_start; /* UNIX time of postponed AOF flush */
time_t aof_last_fsync; /* UNIX time of last fsync() */
time_t aof_rewrite_time_last; /* Time used by last AOF rewrite run. */
time_t aof_rewrite_time_start; /* Current AOF rewrite start time. */
int aof_lastbgrewrite_status; /* C_OK or C_ERR */
unsigned long aof_delayed_fsync; /* delayed AOF fsync() counter */
int aof_rewrite_incremental_fsync;/* fsync incrementally while aof rewriting? */
int rdb_save_incremental_fsync; /* fsync incrementally while rdb saving? */
int aof_last_write_status; /* C_OK or C_ERR */
int aof_last_write_errno; /* Valid if aof_last_write_status is ERR */
int aof_load_truncated; /* Don't stop on unexpected AOF EOF. */
int aof_use_rdb_preamble; /* Use RDB preamble on AOF rewrites. */
/* AOF pipes used to communicate between parent and child during rewrite. */
int aof_pipe_write_data_to_child;
int aof_pipe_read_data_from_parent;
int aof_pipe_write_ack_to_parent;
int aof_pipe_read_ack_from_child;
int aof_pipe_write_ack_to_child;
int aof_pipe_read_ack_from_parent;
int aof_stop_sending_diff; /* If true stop sending accumulated diffs
to child process. */
sds aof_child_diff; /* AOF diff accumulator child side. */
// ...
}
这其中定义了AOF相关的所有变量用于数据及状态的保存,aof_buf就是写入的缓冲区,类型是sds简单动态字符串,所有客户端指令的执行是通过void call(client *c, int flags)这个函数来执行:
void call(client *c, int flags) {
// ...
/* Propagate the command into the AOF and replication link */
if (flags & CMD_CALL_PROPAGATE &&
(c->flags & CLIENT_PREVENT_PROP) != CLIENT_PREVENT_PROP)
{
int propagate_flags = PROPAGATE_NONE;
/* Check if the command operated changes in the data set. If so
* set for replication / AOF propagation. */
if (dirty) propagate_flags |= (PROPAGATE_AOF|PROPAGATE_REPL);
/* If the client forced AOF / replication of the command, set
* the flags regardless of the command effects on the data set. */
if (c->flags & CLIENT_FORCE_REPL) propagate_flags |= PROPAGATE_REPL;
if (c->flags & CLIENT_FORCE_AOF) propagate_flags |= PROPAGATE_AOF;
/* However prevent AOF / replication propagation if the command
* implementations called preventCommandPropagation() or similar,
* or if we don't have the call() flags to do so. */
if (c->flags & CLIENT_PREVENT_REPL_PROP ||
!(flags & CMD_CALL_PROPAGATE_REPL))
propagate_flags &= ~PROPAGATE_REPL;
if (c->flags & CLIENT_PREVENT_AOF_PROP ||
!(flags & CMD_CALL_PROPAGATE_AOF))
propagate_flags &= ~PROPAGATE_AOF;
/* Call propagate() only if at least one of AOF / replication
* propagation is needed. Note that modules commands handle replication
* in an explicit way, so we never replicate them automatically. */
if (propagate_flags != PROPAGATE_NONE && !(c->cmd->flags & CMD_MODULE))
propagate(c->cmd,c->db->id,c->argv,c->argc,propagate_flags);
}
// ...
}
void propagate(struct redisCommand *cmd, int dbid, robj **argv, int argc,
int flags)
{
if (server.aof_state != AOF_OFF && flags & PROPAGATE_AOF)
feedAppendOnlyFile(cmd,dbid,argv,argc);
if (flags & PROPAGATE_REPL)
replicationFeedSlaves(server.slaves,dbid,argv,argc);
}
可以看到在call函数中调用了propagate函数,里面会调用feedAppendOnlyFile写入AOF缓冲区:
// aof.c
void feedAppendOnlyFile(struct redisCommand *cmd, int dictid, robj **argv, int argc) {
sds buf = sdsempty();
robj *tmpargv[3];
/* The DB this command was targeting is not the same as the last command
* we appended. To issue a SELECT command is needed. */
if (dictid != server.aof_selected_db) {
char seldb[64];
snprintf(seldb,sizeof(seldb),"%d",dictid);
buf = sdscatprintf(buf,"*2\r\n$6\r\nSELECT\r\n$%lu\r\n%s\r\n",
(unsigned long)strlen(seldb),seldb);
server.aof_selected_db = dictid;
}
if (cmd->proc == expireCommand || cmd->proc == pexpireCommand ||
cmd->proc == expireatCommand) {
/* Translate EXPIRE/PEXPIRE/EXPIREAT into PEXPIREAT */
buf = catAppendOnlyExpireAtCommand(buf,cmd,argv[1],argv[2]);
} else if (cmd->proc == setexCommand || cmd->proc == psetexCommand) {
/* Translate SETEX/PSETEX to SET and PEXPIREAT */
tmpargv[0] = createStringObject("SET",3);
tmpargv[1] = argv[1];
tmpargv[2] = argv[3];
buf = catAppendOnlyGenericCommand(buf,3,tmpargv);
decrRefCount(tmpargv[0]);
buf = catAppendOnlyExpireAtCommand(buf,cmd,argv[1],argv[2]);
} else if (cmd->proc == setCommand && argc > 3) {
int i;
robj *exarg = NULL, *pxarg = NULL;
/* Translate SET [EX seconds][PX milliseconds] to SET and PEXPIREAT */
buf = catAppendOnlyGenericCommand(buf,3,argv);
for (i = 3; i < argc; i ++) {
if (!strcasecmp(argv[i]->ptr, "ex")) exarg = argv[i+1];
if (!strcasecmp(argv[i]->ptr, "px")) pxarg = argv[i+1];
}
serverAssert(!(exarg && pxarg));
if (exarg)
buf = catAppendOnlyExpireAtCommand(buf,server.expireCommand,argv[1],
exarg);
if (pxarg)
buf = catAppendOnlyExpireAtCommand(buf,server.pexpireCommand,argv[1],
pxarg);
} else {
/* All the other commands don't need translation or need the
* same translation already operated in the command vector
* for the replication itself. */
buf = catAppendOnlyGenericCommand(buf,argc,argv);
}
/* Append to the AOF buffer. This will be flushed on disk just before
* of re-entering the event loop, so before the client will get a
* positive reply about the operation performed. */
if (server.aof_state == AOF_ON)
// 写入AOF buffer
server.aof_buf = sdscatlen(server.aof_buf,buf,sdslen(buf));
/* If a background append only file rewriting is in progress we want to
* accumulate the differences between the child DB and the current one
* in a buffer, so that when the child process will do its work we
* can append the differences to the new append only file. */
if (server.aof_child_pid != -1)
// 写入AOF重写子进程的buffer
aofRewriteBufferAppend((unsigned char*)buf,sdslen(buf));
sdsfree(buf);
}
sds catAppendOnlyGenericCommand(sds dst, int argc, robj **argv) {
char buf[32];
int len, j;
robj *o;
buf[0] = '*';
len = 1+ll2string(buf+1,sizeof(buf)-1,argc);
buf[len++] = '\r';
buf[len++] = '\n';
dst = sdscatlen(dst,buf,len);
for (j = 0; j < argc; j++) {
o = getDecodedObject(argv[j]);
buf[0] = '$';
len = 1+ll2string(buf+1,sizeof(buf)-1,sdslen(o->ptr));
buf[len++] = '\r';
buf[len++] = '\n';
dst = sdscatlen(dst,buf,len);
dst = sdscatlen(dst,o->ptr,sdslen(o->ptr));
dst = sdscatlen(dst,"\r\n",2);
decrRefCount(o);
}
return dst;
}
sds sdscatlen(sds s, const void *t, size_t len) {
size_t curlen = sdslen(s);
// sds空间扩容
s = sdsMakeRoomFor(s,len);
if (s == NULL) return NULL;
memcpy(s+curlen, t, len);
sdssetlen(s, curlen+len);
s[curlen+len] = '\0';
return s;
}
feedAppendOnlyFile函数中通过catAppendOnlyGenericCommand生成命令对应的写入文本,然后调用sdscatlen和原来的aof_buf进行拼接,完成了向aof_buf的写入操作。如果此时,执行AOF重写的子进程正在运行,那么还会向子进程的缓冲区写入变化的内容,子进程会一并执行重写,调用的函数是aofRewriteBufferAppend,这个等下再说,然后看一下回写策略的执行部分,入口仍然是在serverCron大循环中:
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) {
// ...
/* AOF postponed flush: Try at every cron cycle if the slow fsync
* completed. */
if (server.aof_flush_postponed_start) flushAppendOnlyFile(0);
// ...
}
void flushAppendOnlyFile(int force) {
ssize_t nwritten;
int sync_in_progress = 0;
mstime_t latency;
if (sdslen(server.aof_buf) == 0) {
/* Check if we need to do fsync even the aof buffer is empty,
* because previously in AOF_FSYNC_EVERYSEC mode, fsync is
* called only when aof buffer is not empty, so if users
* stop write commands before fsync called in one second,
* the data in page cache cannot be flushed in time. */
if (server.aof_fsync == AOF_FSYNC_EVERYSEC &&
server.aof_fsync_offset != server.aof_current_size &&
server.unixtime > server.aof_last_fsync &&
!(sync_in_progress = aofFsyncInProgress())) {
goto try_fsync;
} else {
return;
}
}
if (server.aof_fsync == AOF_FSYNC_EVERYSEC)
sync_in_progress = aofFsyncInProgress();
if (server.aof_fsync == AOF_FSYNC_EVERYSEC && !force) {
/* With this append fsync policy we do background fsyncing.
* If the fsync is still in progress we can try to delay
* the write for a couple of seconds. */
if (sync_in_progress) {
if (server.aof_flush_postponed_start == 0) {
/* No previous write postponing, remember that we are
* postponing the flush and return. */
server.aof_flush_postponed_start = server.unixtime;
return;
} else if (server.unixtime - server.aof_flush_postponed_start < 2) {
/* We were already waiting for fsync to finish, but for less
* than two seconds this is still ok. Postpone again. */
return;
}
/* Otherwise fall trough, and go write since we can't wait
* over two seconds. */
server.aof_delayed_fsync++;
serverLog(LL_NOTICE,"Asynchronous AOF fsync is taking too long (disk is busy?). Writing the AOF buffer without waiting for fsync to complete, this may slow down Redis.");
}
}
/* We want to perform a single write. This should be guaranteed atomic
* at least if the filesystem we are writing is a real physical one.
* While this will save us against the server being killed I don't think
* there is much to do about the whole server stopping for power problems
* or alike */
latencyStartMonitor(latency);
// 将AOF buffer写入内核缓存
nwritten = aofWrite(server.aof_fd,server.aof_buf,sdslen(server.aof_buf));
latencyEndMonitor(latency);
// ...
/* We performed the write so reset the postponed flush sentinel to zero. */
server.aof_flush_postponed_start = 0;
// ...
server.aof_current_size += nwritten;
/* Re-use AOF buffer when it is small enough. The maximum comes from the
* arena size of 4k minus some overhead (but is otherwise arbitrary). */
if ((sdslen(server.aof_buf)+sdsavail(server.aof_buf)) < 4000) {
sdsclear(server.aof_buf);
} else {
sdsfree(server.aof_buf);
server.aof_buf = sdsempty();
}
try_fsync:
/* Don't fsync if no-appendfsync-on-rewrite is set to yes and there are
* children doing I/O in the background. */
if (server.aof_no_fsync_on_rewrite &&
(server.aof_child_pid != -1 || server.rdb_child_pid != -1))
return;
/* Perform the fsync if needed. */
if (server.aof_fsync == AOF_FSYNC_ALWAYS) {
/* redis_fsync is defined as fdatasync() for Linux in order to avoid
* flushing metadata. */
latencyStartMonitor(latency);
redis_fsync(server.aof_fd); /* Let's try to get this data on the disk */
latencyEndMonitor(latency);
latencyAddSampleIfNeeded("aof-fsync-always",latency);
server.aof_fsync_offset = server.aof_current_size;
server.aof_last_fsync = server.unixtime;
} else if ((server.aof_fsync == AOF_FSYNC_EVERYSEC &&
server.unixtime > server.aof_last_fsync)) {
if (!sync_in_progress) {
aof_background_fsync(server.aof_fd);
server.aof_fsync_offset = server.aof_current_size;
}
server.aof_last_fsync = server.unixtime;
}
}
ssize_t aofWrite(int fd, const char *buf, size_t len) {
ssize_t nwritten = 0, totwritten = 0;
while(len) {
nwritten = write(fd, buf, len);
if (nwritten < 0) {
if (errno == EINTR) {
continue;
}
return totwritten ? totwritten : -1;
}
len -= nwritten;
buf += nwritten;
totwritten += nwritten;
}
return totwritten;
}
void aof_background_fsync(int fd) {
bioCreateBackgroundJob(BIO_AOF_FSYNC,(void*)(long)fd,NULL,NULL);
}
int aofFsyncInProgress(void) {
return bioPendingJobsOfType(BIO_AOF_FSYNC) != 0;
}
Redis服务初始化的时候会调用一次flushAppendOnlyFile(0),将变量server.aof_flush_postponed_start初始化为当前的Unix时间戳,然后后续在主进程的循环中不断判断是否满足写入的要求,无论是否满足首先会先调用aofWrite函数将server.aof_buf写入内核缓冲区,然后清空aof_buf,到下一次循环的时候如果看到aof_buf被清空的时候会goto到try_fsync标签部分,如果写回策略配置的是always则直接调用redis_fsync写入,否则如果配置的是everysec那么会调用aof_background_fsync放到后台线程执行,其实是调用bioCreateBackgroundJob将任务添加到队列,这里要涉及到bio操作,bio是采用多线程来实现的,Redis所有的事件、内存数据结构操作都是在主线程中处理,而文件句柄的关闭、AOF刷盘这些系统调用都是采用bio进行专门的管理,在Redis中一共开了3个线程来做这些事:
// bio.h
/* Background job opcodes */
#define BIO_CLOSE_FILE 0 /* Deferred close(2) syscall. */
#define BIO_AOF_FSYNC 1 /* Deferred AOF fsync. */
#define BIO_LAZY_FREE 2 /* Deferred objects freeing. */
#define BIO_NUM_OPS 3
// server.c
void InitServerLast() {
bioInit();
server.initial_memory_usage = zmalloc_used_memory();
}
// bio.c
static pthread_t bio_threads[BIO_NUM_OPS];
static pthread_mutex_t bio_mutex[BIO_NUM_OPS];
static pthread_cond_t bio_newjob_cond[BIO_NUM_OPS];
static pthread_cond_t bio_step_cond[BIO_NUM_OPS];
static list *bio_jobs[BIO_NUM_OPS];
/* Initialize the background system, spawning the thread. */
void bioInit(void) {
pthread_attr_t attr;
pthread_t thread;
size_t stacksize;
int j;
/* Initialization of state vars and objects */
for (j = 0; j < BIO_NUM_OPS; j++) {
pthread_mutex_init(&bio_mutex[j],NULL);
pthread_cond_init(&bio_newjob_cond[j],NULL);
pthread_cond_init(&bio_step_cond[j],NULL);
bio_jobs[j] = listCreate();
bio_pending[j] = 0;
}
/* Set the stack size as by default it may be small in some system */
pthread_attr_init(&attr);
pthread_attr_getstacksize(&attr,&stacksize);
if (!stacksize) stacksize = 1; /* The world is full of Solaris Fixes */
while (stacksize < REDIS_THREAD_STACK_SIZE) stacksize *= 2;
pthread_attr_setstacksize(&attr, stacksize);
/* Ready to spawn our threads. We use the single argument the thread
* function accepts in order to pass the job ID the thread is
* responsible of. */
for (j = 0; j < BIO_NUM_OPS; j++) {
void *arg = (void*)(unsigned long) j;
if (pthread_create(&thread,&attr,bioProcessBackgroundJobs,arg) != 0) {
serverLog(LL_WARNING,"Fatal: Can't initialize Background Jobs.");
exit(1);
}
bio_threads[j] = thread;
}
}
void bioCreateBackgroundJob(int type, void *arg1, void *arg2, void *arg3) {
struct bio_job *job = zmalloc(sizeof(*job));
job->time = time(NULL);
job->arg1 = arg1;
job->arg2 = arg2;
job->arg3 = arg3;
pthread_mutex_lock(&bio_mutex[type]);
listAddNodeTail(bio_jobs[type],job);
bio_pending[type]++;
pthread_cond_signal(&bio_newjob_cond[type]);
pthread_mutex_unlock(&bio_mutex[type]);
}
void *bioProcessBackgroundJobs(void *arg) {
struct bio_job *job;
unsigned long type = (unsigned long) arg;
sigset_t sigset;
/* Check that the type is within the right interval. */
if (type >= BIO_NUM_OPS) {
serverLog(LL_WARNING,
"Warning: bio thread started with wrong type %lu",type);
return NULL;
}
/* Make the thread killable at any time, so that bioKillThreads()
* can work reliably. */
pthread_setcancelstate(PTHREAD_CANCEL_ENABLE, NULL);
pthread_setcanceltype(PTHREAD_CANCEL_ASYNCHRONOUS, NULL);
pthread_mutex_lock(&bio_mutex[type]);
/* Block SIGALRM so we are sure that only the main thread will
* receive the watchdog signal. */
sigemptyset(&sigset);
sigaddset(&sigset, SIGALRM);
if (pthread_sigmask(SIG_BLOCK, &sigset, NULL))
serverLog(LL_WARNING,
"Warning: can't mask SIGALRM in bio.c thread: %s", strerror(errno));
while(1) {
listNode *ln;
/* The loop always starts with the lock hold. */
if (listLength(bio_jobs[type]) == 0) {
// 条件变量等待
pthread_cond_wait(&bio_newjob_cond[type],&bio_mutex[type]);
continue;
}
/* Pop the job from the queue. */
ln = listFirst(bio_jobs[type]);
job = ln->value;
/* It is now possible to unlock the background system as we know have
* a stand alone job structure to process.*/
pthread_mutex_unlock(&bio_mutex[type]);
/* Process the job accordingly to its type. */
if (type == BIO_CLOSE_FILE) {
close((long)job->arg1);
} else if (type == BIO_AOF_FSYNC) {
redis_fsync((long)job->arg1);
} else if (type == BIO_LAZY_FREE) {
/* What we free changes depending on what arguments are set:
* arg1 -> free the object at pointer.
* arg2 & arg3 -> free two dictionaries (a Redis DB).
* only arg3 -> free the skiplist. */
if (job->arg1)
lazyfreeFreeObjectFromBioThread(job->arg1);
else if (job->arg2 && job->arg3)
lazyfreeFreeDatabaseFromBioThread(job->arg2,job->arg3);
else if (job->arg3)
lazyfreeFreeSlotsMapFromBioThread(job->arg3);
} else {
serverPanic("Wrong job type in bioProcessBackgroundJobs().");
}
zfree(job);
/* Lock again before reiterating the loop, if there are no longer
* jobs to process we'll block again in pthread_cond_wait(). */
pthread_mutex_lock(&bio_mutex[type]);
listDelNode(bio_jobs[type],ln);
bio_pending[type]--;
/* Unblock threads blocked on bioWaitStepOfType() if any. */
pthread_cond_broadcast(&bio_step_cond[type]);
}
}
/* Return the number of pending jobs of the specified type. */
unsigned long long bioPendingJobsOfType(int type) {
unsigned long long val;
pthread_mutex_lock(&bio_mutex[type]);
val = bio_pending[type];
pthread_mutex_unlock(&bio_mutex[type]);
return val;
}
首先,在Redis主进程启动的时候在InitServerLast中调用了bioInit初始化了所有的线程并且启动,bioProcessBackgroundJobs就在后台开始运行了,然后会进入无限循环并通过条件变量等待,这个时候当通过aof_background_fsync创建任务时就会调用bioCreateBackgroundJob在任务列表中添加1个节点,并使用pthread_cond_signal唤醒等待的线程,这样就在bioProcessBackgroundJobs线程中执行具体的写入任务,bio部分体现了在并发中锁和条件变量的经典用法。
以上就是AOF实时缓冲区的写入过程,然后简单看一下重写的过程。
2.2.AOF重写
AOF重写是在serverCron当中判断满足重写的条件时执行的操作,具体是调用aof.c中的rewriteAppendOnlyFileBackground函数执行:
// aof.c
int rewriteAppendOnlyFileBackground(void) {
pid_t childpid;
long long start;
if (server.aof_child_pid != -1 || server.rdb_child_pid != -1) return C_ERR;
// 创建父子进程通信的管道
if (aofCreatePipes() != C_OK) return C_ERR;
openChildInfoPipe();
start = ustime();
if ((childpid = fork()) == 0) {
char tmpfile[256];
/* Child */
closeClildUnusedResourceAfterFork();
redisSetProcTitle("redis-aof-rewrite");
snprintf(tmpfile,256,"temp-rewriteaof-bg-%d.aof", (int) getpid());
if (rewriteAppendOnlyFile(tmpfile) == C_OK) {
size_t private_dirty = zmalloc_get_private_dirty(-1);
if (private_dirty) {
serverLog(LL_NOTICE,
"AOF rewrite: %zu MB of memory used by copy-on-write",
private_dirty/(1024*1024));
}
server.child_info_data.cow_size = private_dirty;
sendChildInfo(CHILD_INFO_TYPE_AOF);
exitFromChild(0);
} else {
exitFromChild(1);
}
} else {
/* Parent */
server.stat_fork_time = ustime()-start;
server.stat_fork_rate = (double) zmalloc_used_memory() * 1000000 / server.stat_fork_time / (1024*1024*1024); /* GB per second. */
latencyAddSampleIfNeeded("fork",server.stat_fork_time/1000);
if (childpid == -1) {
closeChildInfoPipe();
serverLog(LL_WARNING,
"Can't rewrite append only file in background: fork: %s",
strerror(errno));
aofClosePipes();
return C_ERR;
}
serverLog(LL_NOTICE,
"Background append only file rewriting started by pid %d",childpid);
server.aof_rewrite_scheduled = 0;
server.aof_rewrite_time_start = time(NULL);
server.aof_child_pid = childpid;
updateDictResizePolicy();
/* We set appendseldb to -1 in order to force the next call to the
* feedAppendOnlyFile() to issue a SELECT command, so the differences
* accumulated by the parent into server.aof_rewrite_buf will start
* with a SELECT statement and it will be safe to merge. */
server.aof_selected_db = -1;
replicationScriptCacheFlush();
return C_OK;
}
return C_OK; /* unreached */
}
int aofCreatePipes(void) {
int fds[6] = {-1, -1, -1, -1, -1, -1};
int j;
if (pipe(fds) == -1) goto error; /* parent -> children data. */
if (pipe(fds+2) == -1) goto error; /* children -> parent ack. */
if (pipe(fds+4) == -1) goto error; /* parent -> children ack. */
/* Parent -> children data is non blocking. */
if (anetNonBlock(NULL,fds[0]) != ANET_OK) goto error;
if (anetNonBlock(NULL,fds[1]) != ANET_OK) goto error;
// 添加回调函数 调用aofChildPipeReadable释放资源
if (aeCreateFileEvent(server.el, fds[2], AE_READABLE, aofChildPipeReadable, NULL) == AE_ERR) goto error;
server.aof_pipe_write_data_to_child = fds[1];
server.aof_pipe_read_data_from_parent = fds[0];
server.aof_pipe_write_ack_to_parent = fds[3];
server.aof_pipe_read_ack_from_child = fds[2];
server.aof_pipe_write_ack_to_child = fds[5];
server.aof_pipe_read_ack_from_parent = fds[4];
server.aof_stop_sending_diff = 0;
return C_OK;
error:
serverLog(LL_WARNING,"Error opening /setting AOF rewrite IPC pipes: %s",
strerror(errno));
for (j = 0; j < 6; j++) if(fds[j] != -1) close(fds[j]);
return C_ERR;
}
重点要注意的是进入函数后首先使用aofCreatePipes创建了用于之后和子进程通信的管道,管道是进程间通信的一种方式:
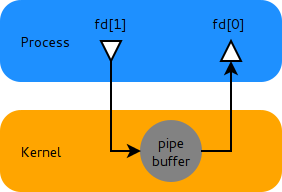
在函数内部通过注册事件最终会调用aofChildPipeReadable函数用于关闭资源,然后父进程在轮询时读取到对应的结果就可以执行不同的操作。
创建管道后就开始执行fork创建执行写入任务的子进程,首先和RDB类似也会创建一个临时文件temp-rewriteaof-bg-<pid>.aof,执行重写操作,完成之后再重命名覆盖之前的文件,子进程创建成功后,父进程做了些简单的状态设置就返回了,但是父进程有个比较重要的操作就是不断将新的客户端操作发送到管道中,前面提到过在实时写入的情况下还会有一步额外的操作:
if (server.aof_child_pid != -1)
// 写入AOF重写子进程的buffer
aofRewriteBufferAppend((unsigned char*)buf,sdslen(buf));
这里调用aofRewriteBufferAppend来写入新提交的数据:
#define AOF_RW_BUF_BLOCK_SIZE (1024*1024*10) /* 10 MB per block */
void aofRewriteBufferAppend(unsigned char *s, unsigned long len) {
// 获取缓存链表最后1个节点
listNode *ln = listLast(server.aof_rewrite_buf_blocks);
aofrwblock *block = ln ? ln->value : NULL;
while(len) {
/* If we already got at least an allocated block, try appending
* at least some piece into it. */
if (block) {
unsigned long thislen = (block->free < len) ? block->free : len;
if (thislen) { /* The current block is not already full. */
memcpy(block->buf+block->used, s, thislen);
block->used += thislen;
block->free -= thislen;
s += thislen;
len -= thislen;
}
}
if (len) { /* First block to allocate, or need another block. */
int numblocks;
block = zmalloc(sizeof(*block));
block->free = AOF_RW_BUF_BLOCK_SIZE;
block->used = 0;
listAddNodeTail(server.aof_rewrite_buf_blocks,block);
/* Log every time we cross more 10 or 100 blocks, respectively
* as a notice or warning. */
numblocks = listLength(server.aof_rewrite_buf_blocks);
if (((numblocks+1) % 10) == 0) {
int level = ((numblocks+1) % 100) == 0 ? LL_WARNING :
LL_NOTICE;
serverLog(level,"Background AOF buffer size: %lu MB",
aofRewriteBufferSize()/(1024*1024));
}
}
}
/* Install a file event to send data to the rewrite child if there is
* not one already. */
if (aeGetFileEvents(server.el,server.aof_pipe_write_data_to_child) == 0) {
aeCreateFileEvent(server.el, server.aof_pipe_write_data_to_child,
AE_WRITABLE, aofChildWriteDiffData, NULL);
}
}
void aofChildWriteDiffData(aeEventLoop *el, int fd, void *privdata, int mask) {
listNode *ln;
aofrwblock *block;
ssize_t nwritten;
UNUSED(el);
UNUSED(fd);
UNUSED(privdata);
UNUSED(mask);
while(1) {
ln = listFirst(server.aof_rewrite_buf_blocks);
block = ln ? ln->value : NULL;
if (server.aof_stop_sending_diff || !block) {
// 数据已经写完 删除注册事件
aeDeleteFileEvent(server.el,server.aof_pipe_write_data_to_child,
AE_WRITABLE);
return;
}
if (block->used > 0) {
nwritten = write(server.aof_pipe_write_data_to_child,
block->buf,block->used);
if (nwritten <= 0) return;
// 将写入到管道的数据空间释放掉
memmove(block->buf,block->buf+nwritten,block->used-nwritten);
block->used -= nwritten;
block->free += nwritten;
}
// 如果block完全写入直接删除当前节点
if (block->used == 0) listDelNode(server.aof_rewrite_buf_blocks,ln);
}
}
注意这里仍然会先写入父进程的用户空间缓冲区中,缓冲区采用创建链表并插入节点的方式来缓存父进程新写入的数据,首先会判断链表剩余空间够不够如果不够会再新创建1个节点把剩余的数据写入,链表每个节点的大小是10M,最后如果没有向子进程管道写入的事件,那么会注册1个用来写入的事件,回调函数是aofChildWriteDiffData,这个函数才是具体执行向子进程管道写入的工作,子进程可以共享管道中的数据。
然后回来看子进程,子进程部分开始调用rewriteAppendOnlyFile函数执行写入操作:
int rewriteAppendOnlyFile(char *filename) {
rio aof;
FILE *fp;
char tmpfile[256];
char byte;
/* Note that we have to use a different temp name here compared to the
* one used by rewriteAppendOnlyFileBackground() function. */
snprintf(tmpfile,256,"temp-rewriteaof-%d.aof", (int) getpid());
fp = fopen(tmpfile,"w");
if (!fp) {
serverLog(LL_WARNING, "Opening the temp file for AOF rewrite in rewriteAppendOnlyFile(): %s", strerror(errno));
return C_ERR;
}
server.aof_child_diff = sdsempty();
rioInitWithFile(&aof,fp);
if (server.aof_rewrite_incremental_fsync)
rioSetAutoSync(&aof,REDIS_AUTOSYNC_BYTES);
if (server.aof_use_rdb_preamble) {
int error;
if (rdbSaveRio(&aof,&error,RDB_SAVE_AOF_PREAMBLE,NULL) == C_ERR) {
errno = error;
goto werr;
}
} else {
if (rewriteAppendOnlyFileRio(&aof) == C_ERR) goto werr;
}
/* Do an initial slow fsync here while the parent is still sending
* data, in order to make the next final fsync faster. */
if (fflush(fp) == EOF) goto werr;
if (fsync(fileno(fp)) == -1) goto werr;
/* Read again a few times to get more data from the parent.
* We can't read forever (the server may receive data from clients
* faster than it is able to send data to the child), so we try to read
* some more data in a loop as soon as there is a good chance more data
* will come. If it looks like we are wasting time, we abort (this
* happens after 20 ms without new data). */
int nodata = 0;
mstime_t start = mstime();
while(mstime()-start < 1000 && nodata < 20) {
if (aeWait(server.aof_pipe_read_data_from_parent, AE_READABLE, 1) <= 0)
{
nodata++;
continue;
}
nodata = 0; /* Start counting from zero, we stop on N *contiguous*
timeouts. */
aofReadDiffFromParent();
}
/* Ask the master to stop sending diffs. */
if (write(server.aof_pipe_write_ack_to_parent,"!",1) != 1) goto werr;
if (anetNonBlock(NULL,server.aof_pipe_read_ack_from_parent) != ANET_OK)
goto werr;
/* We read the ACK from the server using a 10 seconds timeout. Normally
* it should reply ASAP, but just in case we lose its reply, we are sure
* the child will eventually get terminated. */
if (syncRead(server.aof_pipe_read_ack_from_parent,&byte,1,5000) != 1 ||
byte != '!') goto werr;
serverLog(LL_NOTICE,"Parent agreed to stop sending diffs. Finalizing AOF...");
/* Read the final diff if any. */
aofReadDiffFromParent();
/* Write the received diff to the file. */
serverLog(LL_NOTICE,
"Concatenating %.2f MB of AOF diff received from parent.",
(double) sdslen(server.aof_child_diff) / (1024*1024));
if (rioWrite(&aof,server.aof_child_diff,sdslen(server.aof_child_diff)) == 0)
goto werr;
/* Make sure data will not remain on the OS's output buffers */
if (fflush(fp) == EOF) goto werr;
if (fsync(fileno(fp)) == -1) goto werr;
if (fclose(fp) == EOF) goto werr;
/* Use RENAME to make sure the DB file is changed atomically only
* if the generate DB file is ok. */
if (rename(tmpfile,filename) == -1) {
serverLog(LL_WARNING,"Error moving temp append only file on the final destination: %s", strerror(errno));
unlink(tmpfile);
return C_ERR;
}
serverLog(LL_NOTICE,"SYNC append only file rewrite performed");
return C_OK;
werr:
serverLog(LL_WARNING,"Write error writing append only file on disk: %s", strerror(errno));
fclose(fp);
unlink(tmpfile);
return C_ERR;
}
子进程这个时候又创建了1个临时文件temp-rewriteaof-%d.aof,然后和之前写RDB一样初始化rio和自动刷盘,如果此时开启了混合持久化即aof-use-rdb-preamble则调用rdbSaveRio按照RDB的格式写入,否则将调用rewriteAppendOnlyFileRio按照AOF的格式写入,RDB写入和之前基本一样,但是AOF的RDB头部写入部分加了参数RDB_SAVE_AOF_PREAMBLE作为区分,所以不属于严格的快照,而是一个增量的过程,重点部分的代码如下:
// server.h
#define AOF_READ_DIFF_INTERVAL_BYTES (1024*10)
// rdb.c
int rdbSaveRio(rio *rdb, int *error, int flags, rdbSaveInfo *rsi) {
// ...
for (j = 0; j < server.dbnum; j++) {
// ...
/* Iterate this DB writing every entry */
while((de = dictNext(di)) != NULL) {
sds keystr = dictGetKey(de);
robj key, *o = dictGetVal(de);
long long expire;
initStaticStringObject(key,keystr);
expire = getExpire(db,&key);
if (rdbSaveKeyValuePair(rdb,&key,o,expire) == -1) goto werr;
/* When this RDB is produced as part of an AOF rewrite, move
* accumulated diff from parent to child while rewriting in
* order to have a smaller final write. */
if (flags & RDB_SAVE_AOF_PREAMBLE &&
rdb->processed_bytes > processed+AOF_READ_DIFF_INTERVAL_BYTES)
{
processed = rdb->processed_bytes;
aofReadDiffFromParent();
}
}
// ...
}
// ...
}
// aof.c
ssize_t aofReadDiffFromParent(void) {
char buf[65536]; /* Default pipe buffer size on most Linux systems. */
ssize_t nread, total = 0;
while ((nread =
read(server.aof_pipe_read_data_from_parent,buf,sizeof(buf))) > 0) {
server.aof_child_diff = sdscatlen(server.aof_child_diff,buf,nread);
total += nread;
}
return total;
}
当传入RDB_SAVE_AOF_PREAMBLE的flags的时候,并且当处理写入的字节数每增长AOF_READ_DIFF_INTERVAL_BYTES大小时,就会从管道中读取一次父进程的写入并放到子进程的变化缓冲区aof_child_diff中,AOF_READ_DIFF_INTERVAL_BYTES定义的大小是10k,也就是说每写入10k的原有数据,就会从管道中读取一次父进程新增的数据,从而缓解后续写入的压力。
同样如果没有开启混合持久化,则会调用rewriteAppendOnlyFileRio重写AOF文件:
int rewriteAppendOnlyFileRio(rio *aof) {
// 省略...
for (j = 0; j < server.dbnum; j++) {
// ...
di = dictGetSafeIterator(d);
// ...
/* Iterate this DB writing every entry */
while((de = dictNext(di)) != NULL) {
sds keystr;
robj key, *o;
long long expiretime;
keystr = dictGetKey(de);
o = dictGetVal(de);
initStaticStringObject(key,keystr);
expiretime = getExpire(db,&key);
/* Save the key and associated value */
if (o->type == OBJ_STRING) {
/* Emit a SET command */
char cmd[]="*3\r\n$3\r\nSET\r\n";
if (rioWrite(aof,cmd,sizeof(cmd)-1) == 0) goto werr;
/* Key and value */
if (rioWriteBulkObject(aof,&key) == 0) goto werr;
if (rioWriteBulkObject(aof,o) == 0) goto werr;
} else if (o->type == OBJ_LIST) {
if (rewriteListObject(aof,&key,o) == 0) goto werr;
} else if (o->type == OBJ_SET) {
if (rewriteSetObject(aof,&key,o) == 0) goto werr;
} else if (o->type == OBJ_ZSET) {
if (rewriteSortedSetObject(aof,&key,o) == 0) goto werr;
} else if (o->type == OBJ_HASH) {
if (rewriteHashObject(aof,&key,o) == 0) goto werr;
} else if (o->type == OBJ_STREAM) {
if (rewriteStreamObject(aof,&key,o) == 0) goto werr;
} else if (o->type == OBJ_MODULE) {
if (rewriteModuleObject(aof,&key,o) == 0) goto werr;
} else {
serverPanic("Unknown object type");
}
// ...
/* Read some diff from the parent process from time to time. */
if (aof->processed_bytes > processed+AOF_READ_DIFF_INTERVAL_BYTES) {
// 从管道中读取新增的数据合并至aof_child_diff缓冲区
processed = aof->processed_bytes;
aofReadDiffFromParent();
}
}
dictReleaseIterator(di);
di = NULL;
}
return C_OK;
werr:
if (di) dictReleaseIterator(di);
return C_ERR;
}
可以看到除写入的格式不同外,仍然有一段和RDB中非常类似的代码从管道中获取最新的修改。
当数据最终写完之后,返回到rewriteAppendOnlyFile中继续执行,然后继续尝试20ms的时间从主进程获取最新的修改,然后子进程主动向主进程写入!表示关闭管道:
if (write(server.aof_pipe_write_ack_to_parent,"!",1) != 1) goto werr;
而主进程中注册的事件处理会收到子进程的写入:
void aofChildPipeReadable(aeEventLoop *el, int fd, void *privdata, int mask) {
char byte;
UNUSED(el);
UNUSED(privdata);
UNUSED(mask);
if (read(fd,&byte,1) == 1 && byte == '!') {
serverLog(LL_NOTICE,"AOF rewrite child asks to stop sending diffs.");
server.aof_stop_sending_diff = 1;
if (write(server.aof_pipe_write_ack_to_child,"!",1) != 1) {
/* If we can't send the ack, inform the user, but don't try again
* since in the other side the children will use a timeout if the
* kernel can't buffer our write, or, the children was
* terminated. */
serverLog(LL_WARNING,"Can't send ACK to AOF child: %s",
strerror(errno));
}
}
/* Remove the handler since this can be called only one time during a
* rewrite. */
aeDeleteFileEvent(server.el,server.aof_pipe_read_ack_from_child,AE_READABLE);
}
这个时候主进程就会收到子进程发送的信号,然后删除事件注册。
子进程继续向下执行,调用rioWrite写入aof_child_diff缓冲区的内容到文件中,最后刷新缓冲并将文件命名回去,即将temp-rewriteaof-%d.aof重命名为temp-rewriteaof-bg-<pid>.aof文件:
if (rioWrite(&aof,server.aof_child_diff,sdslen(server.aof_child_diff)) == 0)
goto werr;
/* Make sure data will not remain on the OS's output buffers */
if (fflush(fp) == EOF) goto werr;
if (fsync(fileno(fp)) == -1) goto werr;
if (fclose(fp) == EOF) goto werr;
/* Use RENAME to make sure the DB file is changed atomically only
* if the generate DB file is ok. */
if (rename(tmpfile,filename) == -1) {
serverLog(LL_WARNING,"Error moving temp append only file on the final destination: %s", strerror(errno));
unlink(tmpfile);
return C_ERR;
}
serverLog(LL_NOTICE,"SYNC append only file rewrite performed");
return C_OK;
此时子进程执行完毕退出会变为僵尸进程,然后主进程在下一个心跳周期会再次进入serverCron执行回收的操作,代码又回到了开始的位置:
if ((pid = wait3(&statloc,WNOHANG,NULL)) != 0) {
int exitcode = WEXITSTATUS(statloc);
int bysignal = 0;
if (WIFSIGNALED(statloc)) bysignal = WTERMSIG(statloc);
if (pid == -1) {
serverLog(LL_WARNING,"wait3() returned an error: %s. "
"rdb_child_pid = %d, aof_child_pid = %d",
strerror(errno),
(int) server.rdb_child_pid,
(int) server.aof_child_pid);
} else if (pid == server.rdb_child_pid) {
backgroundSaveDoneHandler(exitcode,bysignal);
if (!bysignal && exitcode == 0) receiveChildInfo();
} else if (pid == server.aof_child_pid) {
backgroundRewriteDoneHandler(exitcode,bysignal);
if (!bysignal && exitcode == 0) receiveChildInfo();
} else {
if (!ldbRemoveChild(pid)) {
serverLog(LL_WARNING,
"Warning, detected child with unmatched pid: %ld",
(long)pid);
}
}
updateDictResizePolicy();
closeChildInfoPipe();
}
然后会调用backgroundRewriteDoneHandler回收子进程的资源:
void backgroundRewriteDoneHandler(int exitcode, int bysignal) {
if (!bysignal && exitcode == 0) {
int newfd, oldfd;
char tmpfile[256];
long long now = ustime();
mstime_t latency;
serverLog(LL_NOTICE,
"Background AOF rewrite terminated with success");
/* Flush the differences accumulated by the parent to the
* rewritten AOF. */
latencyStartMonitor(latency);
snprintf(tmpfile,256,"temp-rewriteaof-bg-%d.aof",
(int)server.aof_child_pid);
newfd = open(tmpfile,O_WRONLY|O_APPEND);
if (newfd == -1) {
serverLog(LL_WARNING,
"Unable to open the temporary AOF produced by the child: %s", strerror(errno));
goto cleanup;
}
if (aofRewriteBufferWrite(newfd) == -1) {
serverLog(LL_WARNING,
"Error trying to flush the parent diff to the rewritten AOF: %s", strerror(errno));
close(newfd);
goto cleanup;
}
latencyEndMonitor(latency);
latencyAddSampleIfNeeded("aof-rewrite-diff-write",latency);
serverLog(LL_NOTICE,
"Residual parent diff successfully flushed to the rewritten AOF (%.2f MB)", (double) aofRewriteBufferSize() / (1024*1024));
// ...
/* Rename the temporary file. This will not unlink the target file if
* it exists, because we reference it with "oldfd". */
latencyStartMonitor(latency);
// 重命名操作
if (rename(tmpfile,server.aof_filename) == -1) {
serverLog(LL_WARNING,
"Error trying to rename the temporary AOF file %s into %s: %s",
tmpfile,
server.aof_filename,
strerror(errno));
close(newfd);
if (oldfd != -1) close(oldfd);
goto cleanup;
}
latencyEndMonitor(latency);
latencyAddSampleIfNeeded("aof-rename",latency);
// ...
} else if (!bysignal && exitcode != 0) {
server.aof_lastbgrewrite_status = C_ERR;
serverLog(LL_WARNING,
"Background AOF rewrite terminated with error");
} else {
/* SIGUSR1 is whitelisted, so we have a way to kill a child without
* tirggering an error condition. */
if (bysignal != SIGUSR1)
server.aof_lastbgrewrite_status = C_ERR;
serverLog(LL_WARNING,
"Background AOF rewrite terminated by signal %d", bysignal);
}
cleanup:
aofClosePipes();
aofRewriteBufferReset();
aofRemoveTempFile(server.aof_child_pid);
server.aof_child_pid = -1;
server.aof_rewrite_time_last = time(NULL)-server.aof_rewrite_time_start;
server.aof_rewrite_time_start = -1;
/* Schedule a new rewrite if we are waiting for it to switch the AOF ON. */
if (server.aof_state == AOF_WAIT_REWRITE)
server.aof_rewrite_scheduled = 1;
}
void aofClosePipes(void) {
aeDeleteFileEvent(server.el,server.aof_pipe_read_ack_from_child,AE_READABLE);
aeDeleteFileEvent(server.el,server.aof_pipe_write_data_to_child,AE_WRITABLE);
close(server.aof_pipe_write_data_to_child);
close(server.aof_pipe_read_data_from_parent);
close(server.aof_pipe_write_ack_to_parent);
close(server.aof_pipe_read_ack_from_child);
close(server.aof_pipe_write_ack_to_child);
close(server.aof_pipe_read_ack_from_parent);
}
首先会再次打开子进程生成的AOF文件,然后执行aofRewriteBufferWrite将server.aof_rewrite_buf_blocks中剩余的数据追加到文件中,然后把AOF文件rename为正式的文件,然后使用bio后台线程来关闭所有的资源,包括:管道、文件句柄和缓冲区等,这样就完成了整个AOF的重写过程。
总结一下整体的流程图如下所示:
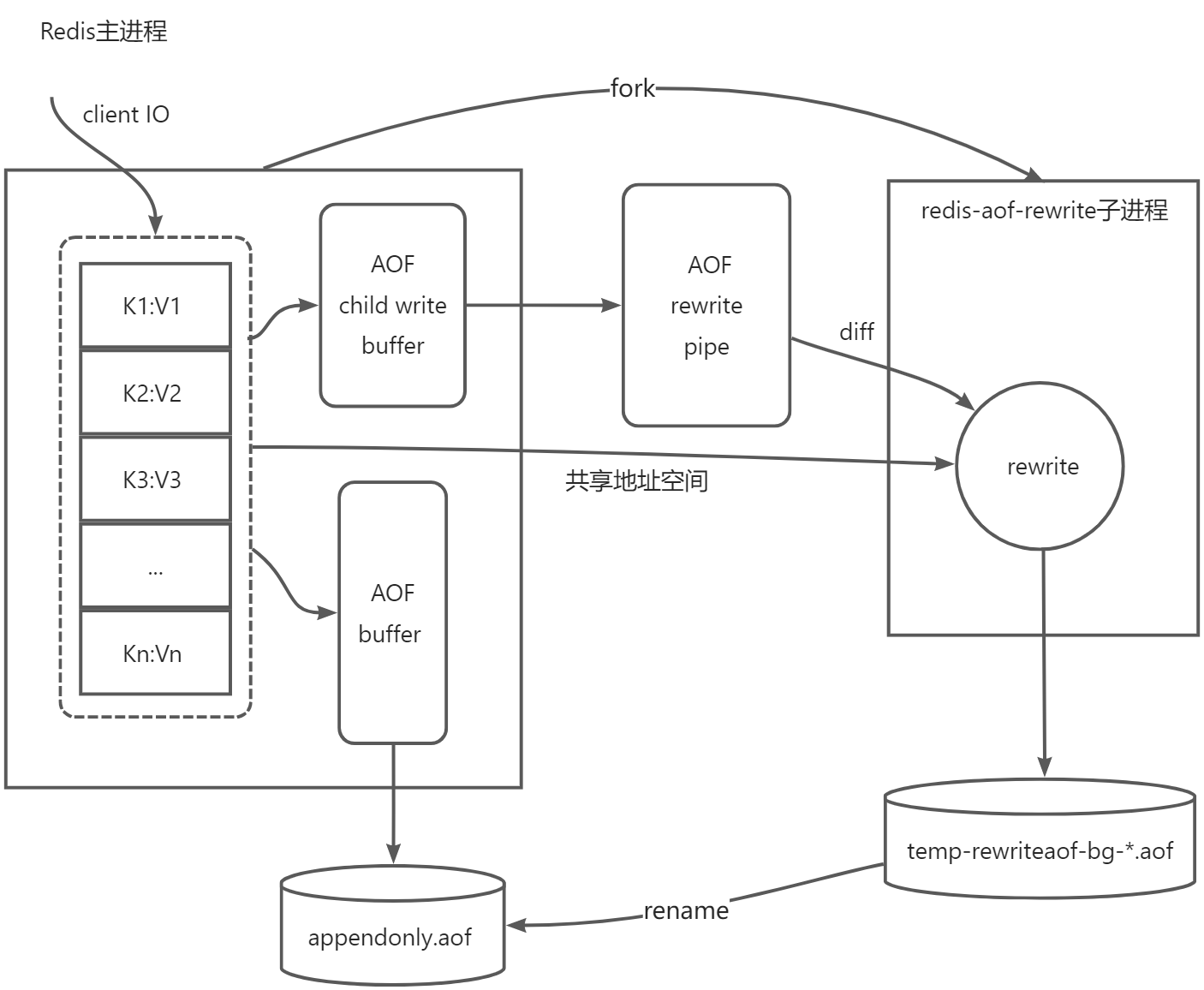
以上就是Redis的RDB和AOF这两种持久化的原理分析,感谢您的阅读,如有错误还望指正~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号