C内存操作API的实现原理
我们在编写C代码时,会使用两种类型的内存,一种是栈内存,另外一种是堆内存,其中栈内存的申请和释放是由编译器来隐式管理的,我们也称为自动内存,这种变量是最简单而且最常用的,然后就是堆内存,堆的申请和释放都由程序员显式完成,因此使用起来也必须小心谨慎,以避免缺陷。
在C语言中通常是使用malloc/free来动态申请堆内存空间,所以我们有必要对malloc大致如何分配内存有一定的了解,事实上malloc/free不完全是系统调用,而是glibc提供的一组函数,malloc内部会涉及到brk()和mmap()这两种系统调用。
那么具体什么时候使用brk,什么时候使用mmap呢?其实这个取决于分配阈值mmap_threshold的定义,默认值为128K,如果每次申请分配的内存小于128K时,会通过brk申请内存,否则如果申请分配的内存大于或等于128K,则通过mmap申请内存,当然需要有可用的mmap映射区域,具体还受限于n_mmaps参数限制。
那么说说brk,这种实现方式比较简单,就是将用户空间的堆顶指针向高地址移动,从而获得新的内存空间,另外还有sbrk这个是通过传入增量来移动堆顶指针,其实内部也是调用了brk,无论是哪种方式malloc分配的内存都是虚拟内存,并没有建立到物理内存的映射,此时进程的页表并没有这些映射关系,当我们访问已经分配的虚拟地址空间时,操作系统会查找页表,此时会引发缺页异常,然后操作系统最终会建立起虚拟内存和物理内存之间的映射关系,就可以写入并访问数据了。对于brk/sbrk或者mmap时都属于系统调用,具体并没有建立映射关系,而是仅仅将虚拟空间新的地址指针更新到进程控制块中mm_struct的标识中,仅此而已,因此这个调用速度也是相当快的,等后续真正访问内存的时候才会逐渐建立页表项。
可以简单做下面的测试,例如:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(int argc, char const *argv[])
{
void *ptr = malloc(8*sizeof(int));
printf("start addr: %llx\n", ptr);
printf("pid: %d\n", getpid());
getchar();
free(ptr);
printf("free.\n");
getchar();
return 0;
}
上面用malloc申请了8个int大小的空间,在linux下进程运行时可以通过/proc/[pid]/maps查看进程堆和栈的使用状态,我们运行起来会首先打印出进程pid信息,例如:

然后我们可以新开一个窗口查看进程maps信息:
cat /proc/667/maps
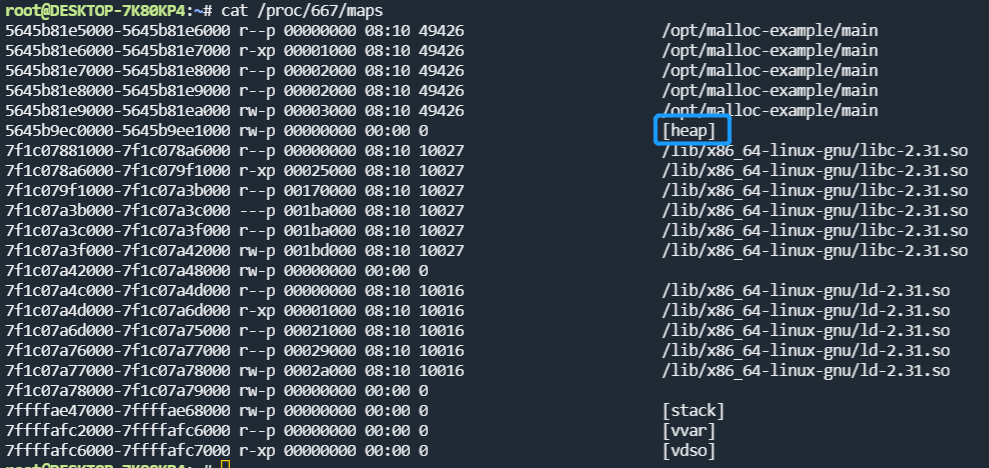
其中heap部分表示堆,前面的地址范围就是当前进程堆的虚拟地址空间,可以看到范围是5645b9ec0000-5645b9ee1000,大小正好是132KB,而看我们程序打印的起始地址5645b9ec02a0是正好落在这个范围内的,但是比起始地址大了672B,这个后面再说,我们再执行一下回车让free语句执行,然后再次以同样的方法查看maps文件,我们会发现堆的大小没有变化,也就是说内存并没有真正地归还给操作系统,而是由malloc的内存池进行管理,方便再次快速申请。
当申请较小的空间时,malloc会一次性向操作系统申请132KB的空间,这样即使之后程序中再申请时也不需要发起系统调用了,从而提高性能,而程序即使释放内存也不会真正归还给操作系统,而是继续放到malloc内存池中,下次再申请内存时可以直接使用,也是为了提高性能,我们可以在上面代码中多申请几次内存,只要总量不超过128K我们会发现heap范围仍然是132K的大小。但是当我们单次申请的内存超过128K时,则会通过mmap方式来申请,并且使用free释放后内存就会立即归还给操作系统,同样可以使用上面代码做一下实验,不过申请内存的时候需要写128*1024或者更大的值,我们这里申请132K的内存,运行起来后我们可以看到程序输出的起始地址:

然后可以查看对应的maps文件:

现在我们不用关心[heap]部分,根据程序的输出可以找到7f133604d000-7f133606f000这个地址范围,后面没有任何标记表示使用mmap申请的匿名内存,由于我们申请了132K,这里的大小是136K,比实际的多4K,仔细看我们上面的地址最后是010,因为malloc本身使用了16个字节保存该内存块的描述信息,所以我们真正用地址的要向后偏移16个字节。
然后我们执行回车后再次查看maps文件,就会发现刚才这行不见了:

所以申请的空间确实归还给操作系统了。
最后可以总结下brk方式和mmap方式的异同,对于brk/sbrk调用方式申请的内存,在调用free释放内存的时候,并不会把内存归还给操作系统,而是挂到malloc内存池中,提供下次使用,而通过mmap申请内存时在释放时,会把内存归还给操作系统,从而真正地释放物理内存。
其实我们也可以单独使用brk/sbrk来申请内存使用:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(int argc, char const *argv[])
{
printf("pid: %d\n", getpid());
intptr_t memory_size = 8 * sizeof(int);
void *ptr = sbrk(0);
printf("start addr: %llx\n", (long unsigned int) ptr);
getchar();
ptr += memory_size;
int ok = brk(ptr);
if(ok == -1) {
printf("memory allocation failed!\n");
return ok;
}
int *p = (int *) (ptr - memory_size);
for(int i = 0; i < memory_size / sizeof(int); i++) {
p[i] = i + 2;
}
for(int i = 0; i < memory_size / sizeof(int); i++) {
printf("%d ", p[i]);
}
printf("\n");
printf("end addr: %llx\n", (long unsigned int) sbrk(0));
getchar();
// free memory
sbrk(-memory_size);
getchar();
}
上面代码含义也比较简单,我们运行时首先打印出当前堆的起始地址:

然后我们查看当前进程的maps文件:

可以看到只要程序创建,默认堆的大小就是132K,因为使用brk方式,这里堆的结束地址就是我们的起始地址,因为brk指针就是指向堆顶的,然后我们再向下执行一步:
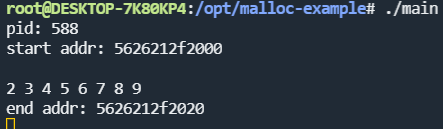
这时候我们会看到brk指向的位置就是起始地址加上我们申请内存空间的大小,也就是加了32B,然后再看maps文件有什么变化:

仔细看maps文件中堆的地址后4位其实是增长到0x3000,刚好增长了4K,是因为在操作系统中内存分配的最小单元就是1个内存页面,所以每次都会分配4K的空间,如果此时brk再往上移动,只要不超过4K我们堆的大小也是不变的,然后我们再向后执行释放掉内存,具体的图就不再截了,这时候会将内存归还给操作系统,所以会发现[heap]的范围又回到最开始的情况了。
上面是brk/sbrk的简单使用,但是我们自己管理空间内存很容易出错,所以我们只需要了解下原理,在实际使用的时候仍然使用malloc/free进行操作即可,那么使用brk/sbrk方式有什么优势呢?
我们知道初次分配内存如果不使用的话,那么是不会真正在物理空间中创建页面以及建立页表项的,只有当使用页面时会触发缺页异常,操作系统会处理该异常即寻找空闲物理空间并添加页表项,然后回到原来的代码继续执行,这时候才可以向内存中写入数据,由于使用brk申请的内存,后续不会归还给操作系统,那么这块内存只会触发一次缺页异常,后续可以重复利用,因此当频繁进行申请和释放时存在很大的性能优势,虽然brk也属于系统调用,但是如果释放中间部分的内存,brk指针不移动,那么由malloc管理空闲地址链表,所以也就不会进行系统调用。而mmap每次都要执行系统调用,进行用户态和内核态的切换,释放内存会真正移除所有的页表项,每次申请内存后使用都会发生缺页异常,所以不适合频繁分配内存的场景,同时会消耗过多的CPU,而brk方式就比较快而且轻量,这些都是brk相对于mmap的优势。
我们可以使用下面一段代码来测试brk/sbrk和mmap之间的性能差距:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/time.h>
#include <sys/mman.h>
#define MEM_LEN 32 * 1024
int main(int argc, char const *argv[])
{
struct timeval s, e;
double delta;
gettimeofday(&s, NULL);
// malloc分配内存
for(int i = 0; i < 100000; i++) {
void *ptr = malloc(MEM_LEN);
// memset(ptr, 0, MEM_LEN);
free(ptr);
}
gettimeofday(&e, NULL);
delta = (e.tv_sec - s.tv_sec) + (e.tv_usec - s.tv_usec) / 1e6;
printf("brk/sbrk time: %lfs\n", delta);
gettimeofday(&s, NULL);
// malloc分配内存
for(int i = 0; i < 100000; i++) {
void *ptr = mmap(NULL, MEM_LEN,
PROT_READ | PROT_WRITE, MAP_SHARED | MAP_ANON,
-1, 0);
if(ptr == MAP_FAILED) {
printf("mmap error!\n");
return -1;
}
// memset(ptr, 0, MEM_LEN);
if(munmap(ptr, MEM_LEN) == -1) {
printf("munmap error!\n");
return -1;
}
}
gettimeofday(&e, NULL);
delta = (e.tv_sec - s.tv_sec) + (e.tv_usec - s.tv_usec) / 1e6;
printf("mmap time: %lfs\n", delta);
return 0;
}
上面我们分别使用malloc/free和mmap/munmap来创建大小相同的32KB内存,反复分配并释放10万次,统计对应的时间:

可以发现brk方式耗时仅3.6ms,而mmap耗时0.20秒,这个耗时的差距在于mmap每次都需要发起系统调用修改进程信息,而brk只需要调用1次,注意代码不要开优化,否则malloc那里时间是0,这样看在当前机器环境下每次mmap或munmap的调用在1微秒以内。
如果我们注释掉上面的memset代码会发现时间差距更明显:

那么这时候时间差距不仅是系统调用,还包括缺页异常的处理时间,所以mmap明显更慢了,注意使用mmap创建内存的大小必须是页面大小的整数倍,这里相当于创建了8个页面,根据时间开销看当前机器环境下每次缺页异常的处理时间大致在2微秒左右。
那么brk/sbrk相对于mmap有什么劣势呢?
因为brk分配的内存大多都是非常小的块,如果频繁无规律的申请以及释放,会产生大量的内存碎片,而且更容易导致内存泄露,用valgrind之类的工具也无法检测,碎片过多可能会影响系统中其他进程的运行,可能会引起不稳定,所以malloc中阈值设置为128K也是一种折中的考虑。
根据上面的原理,我们可以总结下日常开发中内存使用上面的一些小技巧:
-
如果我们需要一些比较小的空间,那么可以多次申请或者释放,并且同一块内存的申请和释放尽量连续中间不要穿插其他内存的申请和释放,以保证重复利用,也就是说不要多块内存交叉申请及释放,以防止出现过多的内存碎片,而且用完及时释放掉归还给malloc,下次用再申请即可。
-
如果我们需要大块的内存时,最好一次申请,后续多次复用,直到不用的时候再释放,不要在循环内频繁申请和释放大块内存,降低CPU的消耗。
-
虽然brk/sbrk也可以用来申请内存,但是容易出错,所以坚持使用标准的malloc/free。
-
不要忘记为指针分配内存,否则在向空指针拷贝内存时会出现段错误(segmentation fault)。
-
要为数据分配足够的内存,如果数据长度大于分配的内存长度,会出现缓冲区溢出,虽然可能不会报错,但是会出现很多意想不到的结果。
-
分配的内存读之前要初始化,虽然用malloc正确分配了内存,但是如果没有写入直接读取可能会读到一些异常或者有害的值,同样导致莫名奇妙的结果,所以请一定先填入正确的值再读取,或者使用memset填充固定的值。
最后,感谢您的耐心阅读,如有错误欢迎指正!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号