
Flink Standalone集群部署
Flink Standalone模式部署集群是最简单的一种部署方式,不依赖于其他的组件,另外还支持YARN/Mesos/Docker等模式下的部署,这里使用的flink版本为最新的稳定版1.9.1版本,对应的Scala版本是2.11,二进制包为:flink-1.9.1-bin-scala_2.11.tgz,即将安装的环境为内网4个节点,其中1个jobmanager,3个taskmanager,角色分配如下:
bigdata1 - jobmanager
bigdata2, bigdata3, bigdata4 - taskmanager
老规矩,配置flink前必须做下面的基础准备:
1). JDK环境,1.8.x或者更高,Oracle JDK或者OpenJDK都可以,二进制包解压的方式安装要配置好JAVA_HOME
2). 主机名和hosts配置文件集群内完全对应,准确配置.
3). 集群之间保证通信正常,关闭防火墙或者提前设置好规则.
4). 集群所有节点配置ssh免密,否则后续启动集群的时候还需要输入密码.
5). 集群配置时间同步服务,ntp或者chrony服务,这个应该是大数据组件集群的标配
然后准备安装flink,flink的安装目录为了便于维护所有的安装位置都要一致,这里是/opt/flink-1.9.1,首先在其中1个节点bigdata1上开始配置:
解压安装包并进入安装目录: tar -xvzf flink-1.9.1-bin-scala_2.11.tgz -C /opt && cd /opt/flink-1.9.1
编辑配置文件:conf/flink-conf.yaml,对于独立集群有下面的配置项需要修改:
jobmanager.rpc.address: bigdata1 jobmanager.rpc.port: 6123 jobmanager.heap.size: 2048m taskmanager.heap.size: 4096m taskmanager.numberOfTaskSlots: 4 parallelism.default: 1
简单来看一下jobmanager.rpc.address表示jobmanager rpc通信绑定的地址,这里就是jobmanager的主机名
jobmanager.rpc.port是jobmanager的rpc端口,默认是6123
jobmanager.heap.size 这个是 jobmanager jvm进程的堆内存大小,默认是1024M,这里设置成2048m,也就是2G
taskmanager.heap.size 这个是taskmanager jvm进程的堆内存大小,也就是实际运行任务的jvm最大所能占用的堆内存,默认也是1024m,这里设置成4g
taskmanager.numberOfTaskSlots 这个表示每个taskmanager所能提供的slots数量,也就是flink节点的计算能力,这个和算子的并行度配合使用,每个slot运行1个pipeline[source,transformation,slink],多个slot使得flink的subtasks是并行的,这个一般设置成和机器cpu核数一致,比如我们这里是3个taskmanager,每个taskmanager是4个slots,那么这个集群的slots个数为12.
parallelism.default 这个是默认任务的并行度,也就是说当代码中或者提交时没指定并行度,则按照这里的并行度执行任务,并行度是按照整个集群来算的,比如上面slots个数为12,那么支持subtasks最大的并行度就是12,因为在代码中通常会针对单个任务设置并行度,所以这里的默认并行度可以不设置.
上面这几项是flink独立集群最基本的配置,另外还有关于rest和web ui的配置,如果需要可以配置一下,我这里按照默认的配置:
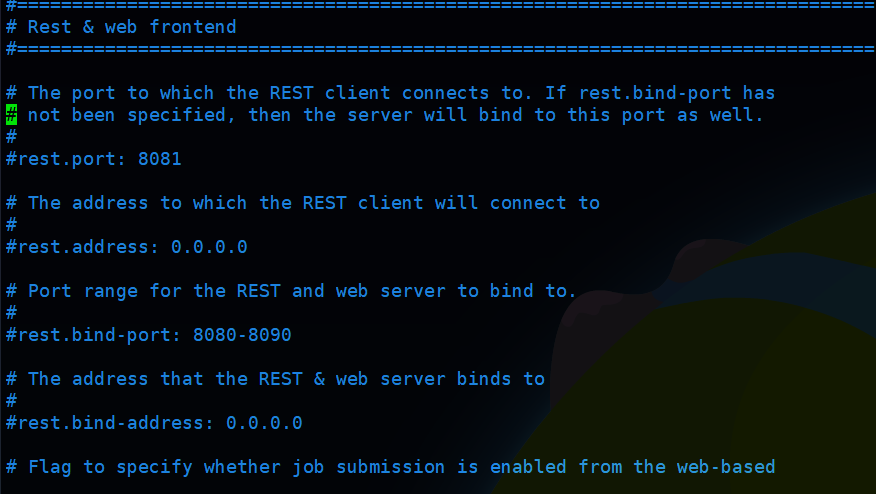

web ui和jobmanager同时运行,端口默认为8081,可以根据需要修改,另外还有个参数:web.submit.enable,也就是是否可以从界面提交任务,默认是开启的,取消注释就可以关闭.
确认上面配置无误之后,保存配置
然后配置masters和slaves的节点文件,
conf/masters,配置jobmanager的机器列表,这里独立集群非HA模式下配置为:bigdata1:8081
conf/slaves,配置taskmanager的机器列表,这里配置如下:
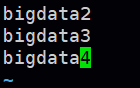
确认上面配置正常全部保存,接下来就可以从bigdata1将配置好的flink分发到其他3个节点:
scp -r /opt/flink-1.9.1 bigdata2:/opt scp -r /opt/flink-1.9.1 bigdata3:/opt scp -r /opt/flink-1.9.1 bigdata4:/opt
然后从任意1个节点可以启动集群,启动命令为: bin/start-cluster.sh 执行之后jobmanager和taskmanager就全部启动了,通过jps可以查看到相应的进程,jobmanager的进程为StandaloneSessionClusterEntrypoint,其余3个taskmanager的进程为TaskManagerRunner,然后可以访问浏览器界面查看web ui,这里是:http://bigdata1:8081
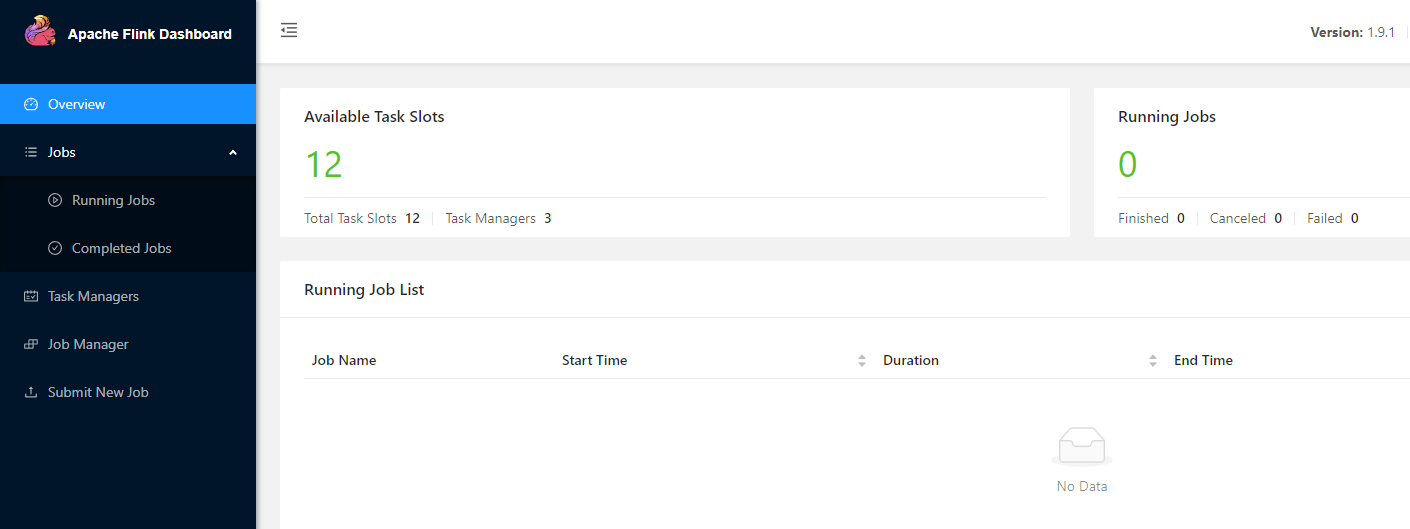
这样,flink standalone模式的集群就配置完成了
停止集群命令: bin/stop-cluster.sh 执行之后所有节点的进程都会停止
单个jobmanager的启动或停止: bin/jobmanager.sh start|start-foreground|stop|stop-all
单个taskmanager的启动或停止: bin/taskmanager.sh start|start-foreground|stop|stop-all
其中start-foreground是在前台启动,单独启动的命令一方面可以用在cluster启动或者停止失败的时候执行,另一方面可以用于flink集群运行时向其中加入节点,主要是运行时添加配置好的taskmanager节点,这样可以为集群动态扩容,添加之后稍微等一下,web界面就可以看到可用的slots和task managers数量发生变化了.
参考文档:https://ci.apache.org/projects/flink/flink-docs-release-1.9/zh/ops/deployment/cluster_setup.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号