浏览器缓存
浏览器缓存
浏览器缓存是浏览器在本地磁盘对用户最近请求过的文档进行存储,当访问者再次访问同一页面时,浏览器就可以直接从本地磁盘加载文档。
所以根据上面的特点,浏览器缓存有下面的优点:
-
减少冗余的数据传输
-
减少服务器负担
-
加快客户端加载网页的速度
浏览器缓存是Web性能优化的重要方式。那么浏览器缓存的过程究竟是怎么样的呢?
在浏览器第一次发起请求时,本地无缓存,向web服务器发送请求,服务器起端响应请求,浏览器端缓存。过程如下:
在第一次请求时,服务器会将页面最后修改时间通过Last-Modified标识由服务器发送给客户端,客户端记录修改时间;服务器还会生成一个Etag,并发送给客户端。
浏览器后续再次进行请求时: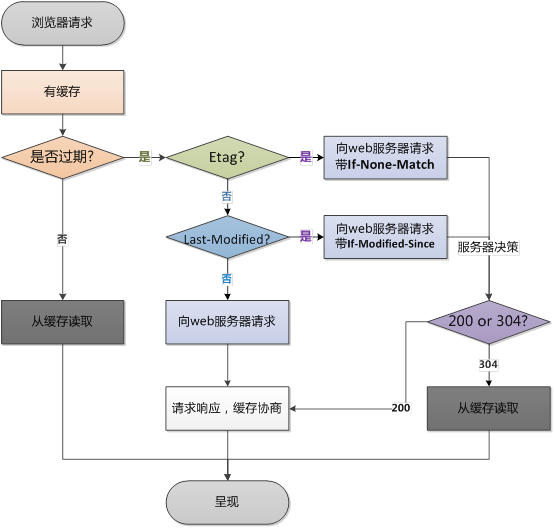
浏览器缓存主要分为强强缓存(也称本地缓存)和协商缓存(也称弱缓存)。根据上图,浏览器在第一次请求发生后,再次发送请求时:
-
浏览器请求某一资源时,会先获取该资源缓存的header信息,然后根据header中的
Cache-Control和Expires来判断是否过期。若没过期则直接从缓存中获取资源信息,包括缓存的header的信息,所以此次请求不会与服务器进行通信。这里判断是否过期,则是强缓存相关。后面会讲Cache-Control和Expires相关。 -
如果显示已过期,浏览器会向服务器端发送请求,这个请求会携带第一次请求返回的有关缓存的header字段信息,比如客户端会通过
If-None-Match头将先前服务器端发送过来的Etag发送给服务器,服务会对比这个客户端发过来的Etag是否与服务器的相同,若相同,就将If-None-Match的值设为false,返回状态304,客户端继续使用本地缓存,不解析服务器端发回来的数据,若不相同就将If-None-Match的值设为true,返回状态为200,客户端重新机械服务器端返回的数据;客户端还会通过If-Modified-Since头将先前服务器端发过来的最后修改时间戳发送给服务器,服务器端通过这个时间戳判断客户端的页面是否是最新的,如果不是最新的,则返回最新的内容,如果是最新的,则返回304,客户端继续使用本地缓存。
强缓存
强缓存是利用http头中的Expires和Cache-Control两个字段来控制的,用来表示资源的缓存时间。强缓存中,普通刷新会忽略它,但不会清除它,需要强制刷新。浏览器强制刷新,请求会带上Cache-Control:no-cache和Pragma:no-cache
Expires
Expires是http1.0的规范,它的值是一个绝对时间的GMT格式的时间字符串。如我现在这个网页的Expires值是:expires:Fri, 14 Apr 2017 10:47:02 GMT。这个时间代表这这个资源的失效时间,只要发送请求时间是在Expires之前,那么本地缓存始终有效,则在缓存中读取数据。所以这种方式有一个明显的缺点,由于失效的时间是一个绝对时间,所以当服务器与客户端时间偏差较大时,就会导致缓存混乱。如果同时出现Cache-Control:max-age和Expires,那么max-age优先级更高。如我主页的response headers部分如下:
cache-control:max-age=691200
expires:Fri, 14 Apr 2017 10:47:02 GMT那么表示资源可以被缓存的最长时间为691200秒,会优先考虑max-age。
Cache-Control
Cache-Control是在http1.1中出现的,主要是利用该字段的max-age值来进行判断,它是一个相对时间,例如Cache-Control:max-age=3600,代表着资源的有效期是3600秒。cache-control除了该字段外,还有下面几个比较常用的设置值:
-
no-cache:不使用本地缓存。需要使用缓存协商,先与服务器确认返回的响应是否被更改,如果之前的响应中存在ETag,那么请求的时候会与服务端验证,如果资源未被更改,则可以避免重新下载。
-
no-store:直接禁止游览器缓存数据,每次用户请求该资源,都会向服务器发送一个请求,每次都会下载完整的资源。
-
public:可以被所有的用户缓存,包括终端用户和CDN等中间代理服务器。
-
private:只能被终端用户的浏览器缓存,不允许CDN等中继缓存服务器对其缓存。
Cache-Control与Expires可以在服务端配置同时启用,同时启用的时候Cache-Control优先级高。
协商缓存
协商缓存就是由服务器来确定缓存资源是否可用,所以客户端与服务器端要通过某种标识来进行通信,从而让服务器判断请求资源是否可以缓存访问。
普通刷新会启用弱缓存,忽略强缓存。只有在地址栏或收藏夹输入网址、通过链接引用资源等情况下,浏览器才会启用强缓存,这也是为什么有时候我们更新一张图片、一个js文件,页面内容依然是旧的,但是直接浏览器访问那个图片或文件,看到的内容却是新的。
这个主要涉及到两组header字段:Etag和If-None-Match、Last-Modified和If-Modified-Since。上面以及说得很清楚这两组怎么使用啦~复习一下:
Etag和If-None-Match
Etag/If-None-Match返回的是一个校验码。ETag可以保证每一个资源是唯一的,资源变化都会导致ETag变化。服务器根据浏览器上送的If-None-Match值来判断是否命中缓存。
与Last-Modified不一样的是,当服务器返回304 Not Modified的响应时,由于ETag重新生成过,response header中还会把这个ETag返回,即使这个ETag跟之前的没有变化。
Last-Modify/If-Modify-Since
浏览器第一次请求一个资源的时候,服务器返回的header中会加上Last-Modify,Last-modify是一个时间标识该资源的最后修改时间,例如Last-Modify: Thu,31 Dec 2037 23:59:59 GMT。
当浏览器再次请求该资源时,request的请求头中会包含If-Modify-Since,该值为缓存之前返回的Last-Modify。服务器收到If-Modify-Since后,根据资源的最后修改时间判断是否命中缓存。
如果命中缓存,则返回304,并且不会返回资源内容,并且不会返回Last-Modify。
为什么要有Etag
你可能会觉得使用Last-Modified已经足以让浏览器知道本地的缓存副本是否足够新,为什么还需要Etag呢?HTTP1.1中Etag的出现主要是为了解决几个Last-Modified比较难解决的问题:
-
一些文件也许会周期性的更改,但是他的内容并不改变(仅仅改变的修改时间),这个时候我们并不希望客户端认为这个文件被修改了,而重新GET;
-
某些文件修改非常频繁,比如在秒以下的时间内进行修改,(比方说1s内修改了N次),If-Modified-Since能检查到的粒度是s级的,这种修改无法判断(或者说UNIX记录MTIME只能精确到秒);
-
某些服务器不能精确的得到文件的最后修改时间。
Last-Modified与ETag是可以一起使用的,服务器会优先验证ETag,一致的情况下,才会继续比对Last-Modified,最后才决定是否返回304

 浙公网安备 33010602011771号
浙公网安备 33010602011771号