EasyPR源码剖析(1):概述
EasyPR将把车牌识别划分为了两个过程:即车牌检测(Plate Detection)和字符识别(Chars Recognition)两个过程。
- 车牌检测(Plate Detection):对一个包含车牌的图像进行分析,最终截取出只包含车牌的一个图块。这个步骤的主要目的是降低了在车牌识别过程中的计算量。如果直接对原始的图像进行车牌识别,会非常的慢,因此需要检测的过程。在本系统中,我们使用SVM(支持向量机)这个机器学习算法去判别截取的图块是否是真的“车牌”。
- 字符识别(Chars Recognition):该步骤的主要目的就是从上一个车牌检测步骤中获取到的车牌图像,进行光学字符识别(OCR)这个过程。其中用到的机器学习算法是人工神经网络(ANN)中的多层感知机(MLP)模型。
下图是一个完整的EasyPR的处理流程:

图1 EasyPR的处理流程
EasyPR中PlateDetect与CharsRecognize各包括三个模块。
PlateDetect包括的是车牌定位,SVM训练,车牌判断三个过程,见下图。
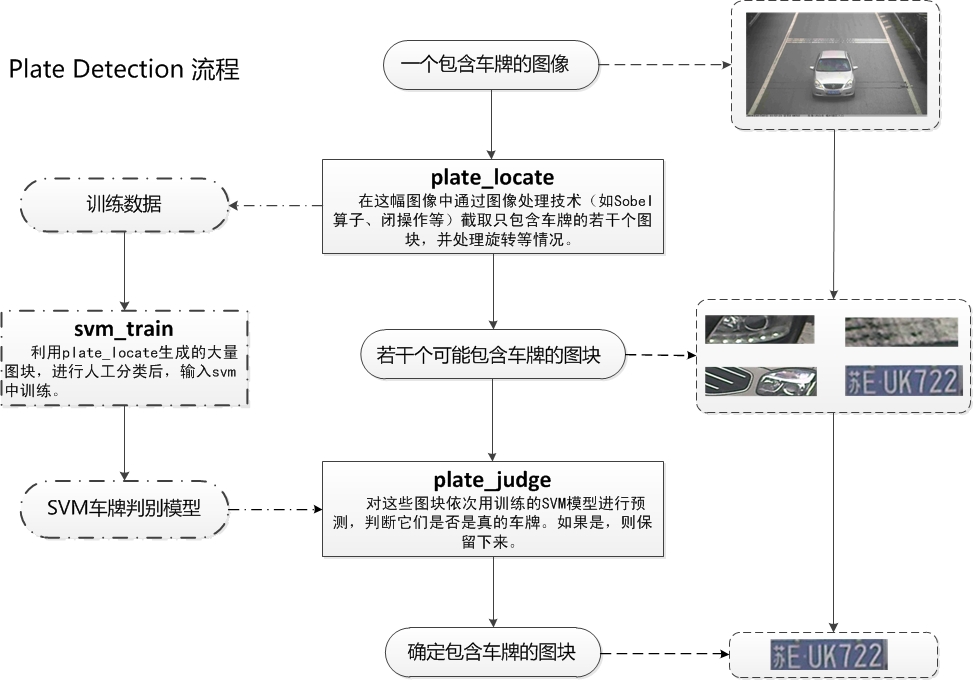
图2 PlateDetect过程详解
通过PlateDetect过程我们获得了许多可能是车牌的图块,将这些图块进行手工分类,聚集一定数量后,放入SVM模型中训练,得到SVM的一个判断模型,在实际的车牌过程中,我们再把所有可能是车牌的图块输入SVM判断模型,通过SVM模型自动的选择出实际上真正是车牌的图块。
PlateDetect过程结束后,我们获得一个图片中我们真正关心的部分,车牌。那么下一步该如何处理呢。下一步就是根据这个车牌图片,生成一个车牌号字符串的过程,也就是CharsRecognize的过程。CharsRecognize包括的是字符分割,ANN训练,字符识别三个过程,具体见下图。
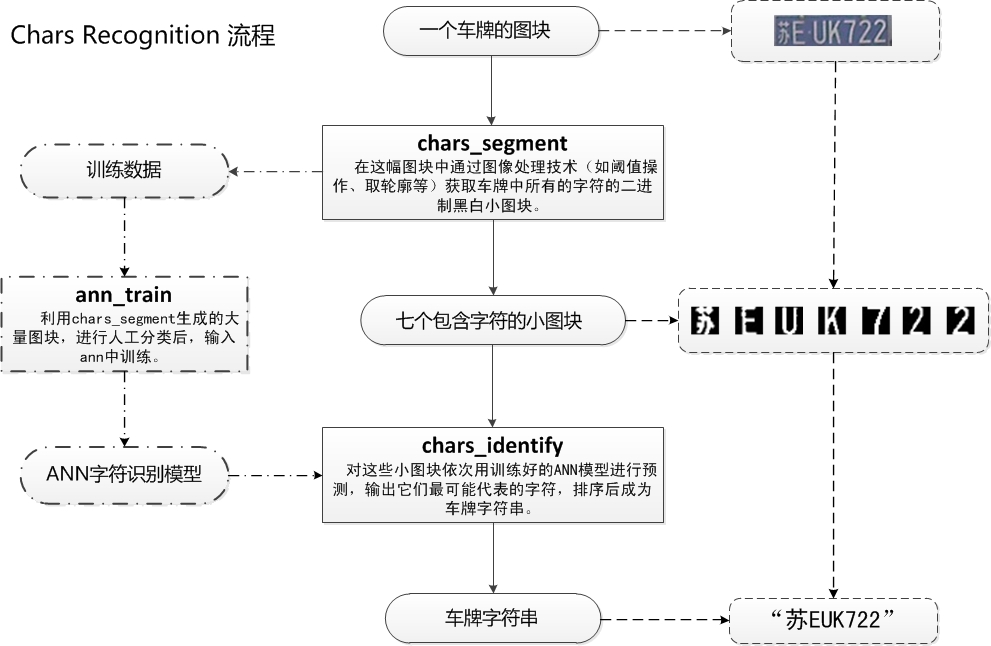
图3 CharsRecognise过程详解
在CharsRecognize过程中,一副车牌图块首先会进行灰度化,二值化,然后使用一系列算法获取到车牌的每个字符的分割图块。获得海量的这些字符图块后,进行手工分类(这个步骤非常耗时间,后面会介绍如何加速这个处理的方法),然后放入神经网络(ANN)的MLP模型中,进行训练。在实际的车牌识别过程中,将得到7个字符图块放入训练好的神经网络模型,通过模型来预测每个图块所表示的具体字符,例如图片中就输出了“苏EUK722”。
至此一个完整的车牌识别过程就结束了,但是在每一步的处理过程中,有许多的优化方法和处理策略。尤其是车牌定位和字符分割这两块,非常重要,它们不仅生成实际数据,还生成训练数据,因此会直接影响到模型的准确性,以及模型判断的最终结果。这两部分会是接下来重点介绍的模块,至于SVM模型与ANN模型,由于使用的是OpenCV提供的类,因此可以直接看openCV的源码或者机器学习介绍的书,来了解训练与判断过程。
posted on 2017-04-26 10:51 freedomker 阅读(5083) 评论(2) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号