PROTECTING CLASSIFIERS AGAINST ADVERSARIAL ATTACKS USING GENERATIVE MODELS
测试用
PROTECTING CLASSIFIERS AGAINST ADVERSARIAL ATTACKS USING GENERATIVE MODELS
Abstract
在推断的时候,这个网络能找到一个和输入相近的输出,但是把对抗扰动给过滤掉了。
Introduction
对现行的对抗防御又做了三种分类:
- 对抗训练(改变训练数据)
- 蒸馏(改变训练过程以减小梯度)
- 尝试移除对抗噪声
结果是,都存在一定的局限性,都可能只对黑盒或者白盒的某一种场景效果好,不能两者兼顾。
It is, therefore, expected that legitimate samples will be close to some point in the range of G, whereas adversarial samples will be further away from the range of G
这句有点??,但是是他设计的出发点,让真实图片靠近GAN的生成范围,但是对抗样本远离它。
Related Work
Attack algorithm
白盒:选用了FGSM(简单),Rand+FGSM(简单并且有助于跳出梯度遮蔽)和CW攻击(目前最强的白盒攻击中的一种)。
黑盒:替身攻击
Defense algorithm
Adversarial training
对抗训练,可能导致梯度遮蔽
Defensive distillation
防御蒸馏,说是能学到一个更平滑的网络,平滑在数据点附近的梯度信息,这样就很难用白盒正面攻击。但是感觉道理和梯度遮蔽很像(刚好一正一反,一个是扭曲梯度,一个是磨平梯度),都很容易被黑盒攻击给规避掉。
MagNet
思路是用一大堆reformer(其实是auto encoder) 把图像投影到他们的manifold上,但是说是一大堆,其实每次只随机的使用其中的一个,因此有一定的随机抗性。
和本文方法的区别在于(1)本文用的是GAN。(2)用的是梯度下降(GD),然后说这个效果好,尤其是面对白盒攻击。至于为啥不知道,后面看看
GAN
本文使用的是W-GAN(嘻嘻)
Proposed Defense-GAN
Denoise adversarial examples 给对抗样本降噪。
At test time, prior to feeding an image x to the classifier, we project it onto the range of the generator by minimizing the reconstruction error \(||G(z)-x||^2_2\) using L steps of GD.
Motivation
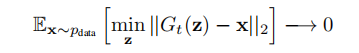
通过对WGAN算法公式的分析,推导出当\(p_g\rightarrow p_{data}\)的时候,\(p_{data}\)上的x在上述那个式子里的期望为0。
the addition of the GAN reconstruction loss minimization step should not affect the performance of the classifier on natural, legitimate samples, as such samples should be almost exactly recovered.
说最小化GAN重建loss这一步不会影响判别器在正常图像上的精度,因为这些图片可以被几乎正确恢复
然后他们又假设这个东西能消除对抗噪声(草)
Algorithm
看懂了,给定一个输入的图像\(\textbf{x}\)和生成器(应该是预先训练好的)\(G\),先通过\(\mathop{\min}\limits_x||G(z)-\textbf{x}||^2_2\) 这一步找到一个最优隐变量\(z^*\),然后给分类器输入\(G(z^*)\)。
就像上图这样,注意因为上面那个优化问题据说是个高度非优化问题,因此通过随机生成\(z\),然后进行固定\(L\)步的梯度下降算法来试出来。
有两种分类器的训练策略?暂时是无监督模式(???)分类器用原始数据训练,然后用\(G\)来重建。写的很模棱两可,感觉有歧义,看不懂。
看懂了,它的意思是,GAN是直接按照WGAN的方式训练的,然后分类器可以考虑直接用原始图片训练,也可以用经过GAN重建的图片来进行训练。
The GAN is trained on the available classifier training dataset in an unsupervised manner. The classifier can be trained on the original training images, their reconstructions using the generator G, or a combination of the two.
因为纯净图片和他们的重建效果是一样的,因此这两种训练理论上不会有太大差距。
他们的方法有这几个特点:
- 不改变原有的分类器模型
- 只要GAN的表现能力足够强,则不需要重新训练原有的classifier,并且defense-GAN带来的表现损失应该不明显
- 应该可以用于防御任何攻击,因为这个防御设计之初就没有考虑到针对哪种模型,只是利用了GAN的生成能力而已。
- 这个模型是非线性的(非线性的一直不知道咋判断),然后因为存在GD的loop,所以白盒的GD攻击应该很难实现。
Experiments
-Rec 代表分类器是用重建后的图像训练的。-orig表示是用原图训练。
Black-Box Attacks
黑盒攻击的条件设置:数据集只有150个,然后用合成的图片进行数据增强,并且一起扔进目标的classifier获取坐标,训练替身使者。
MNIST和F-MNIST的结果如下:
结论:
- Rec和Ori的效果相近
- 在不同的分类器和替身的环境设置下表现较为连续(都在比较高的水平)
- 对抗训练,表现不稳定,并且当对攻击的情报不足的时候(比如对抗训练的第二栏被错误的设置为\(\epsilon=0.15\))同时要注意,对抗训练只是针对某一种攻击模式的(比如这里的\(l_\infin\)攻击),没办法防其它的。
- F-MNIST的表现差很多,但是这也是因为扰动\(\epsilon=0.3\)有点太大了,甚至人眼都分辨不出来
Effect of L and R
可见,L越大,无攻击的时候准确度是越来越高的(废话),有攻击的时候L在超过一定程度的时候效果反而下降了。因为可能这个时候学到了一点对抗扰动,失效了,
R是越大越好的,因为这是个非凸优化问题,可能找到很多的local minima。
Effect of Adversarial noise norm \(\epsilon\)
看图:
Attack Detection
回去看看ROC和AUC的的定义8。看起来效果还不错,就是判断重建后的图和原来图差多少,差的多说明有对抗扰动。\(\epsilon\)越小,越难达到好的效果。
- 感觉,\(\epsilon\)越大,判断的效果越好,\(\epsilon\)越小,净化的效果越好。
White-Box Attacks
效果可太tm好了。包括就算告诉攻击者随机的起点z,也没办法攻破。
分析说明,因为有一个\(L\)步的循环,因此白盒攻击者要”Un-roll“前面的网络,然后GD基本无法进行。\(L\)越大效果越好。
Conclusion
虽然这个效果挺好的,但是两个问题,第一个是如果\(G\)训练得不好,没办法很好的表示出数据的分布,效果就会大打折扣。第二个是超参数\(L\)和\(R\)的选取会对效果产生很关键的影响,尤其是面对的攻击方式未知的时候。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号