
kafka学习(一)
一 简介
1.1 概述
Kafka是最初由Linkedin公司开发,是一个分布式,分区的,多副本的,多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统)MQ 我自己理解为一种应用程序对应用程序的通信方法,常见可以用于web/Nginx日志,访问日志,消息服务等等,Linkedin于2010年贡献给了Apache基金会成为了顶级开源项目。
主要应用场景是:日志收集系统和消息系统
Kafka的设计目标是:
以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上的数据也能保持常数时间的访问时间;
高吞吐率,即使在非常廉价的商用机器上也能做到单机支持每秒100k条信息的传输
只是Kafka Server间的消息分区 及分布式消费 同时保持 每个partition内的消息顺序传输
············同时支持离线数据处理和实时数据处理
Scale Out支持在线水平拓展
消息系统介绍
一个消息系统负责将数据从一个应用传递到另外一个应用,应用只需要关注数据,无需关注数据在两个或者多个应用间是如何传递的。分布式消息传递基于可靠地消息队列,在客户端应用和消息系统之间异步传递消息。有两种主要的消息传递模式:点对点传递模式,发布-订阅模式,大部分的消息系统使用发布-订阅模式。大部分的消息系统选用发布-订阅模式 Kafka就是一种发布订阅模式
点对点消息传递模式
点对点消息系统中 消息持久化到一个队列中 此时 将有 一个或多个消费者消费队列中的数据 但是一条消息只能被消费一次 当一个消费者消费了一个队列中的某条数据之后 该条数据则从消息队列中删除 该模式即使有多个消费者同时消费数据 也能保证数据处理的顺序,这种架构描述如下:
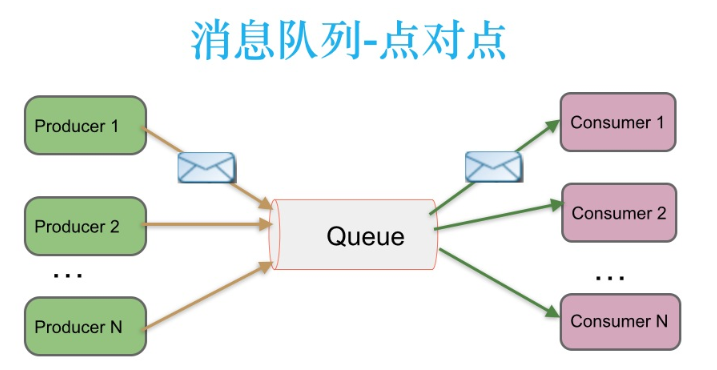
生产者发送一个消息到queue 只是一个消费者能收到
· 发布-订阅消息传递模式
在发布-订阅消息系统中 消息被持久化到一个Topic中,与点对点信息系统不同的是,消费者可以订阅一个或多个topic,消费者可以消费该topic中所有的数据 同一条数据可以被多个消费者消费 ,数据被消费之后不会马上删除。在发布-订阅消息系统中,消费者的生产者称为发布者,消费者称之为订阅者。描述如下
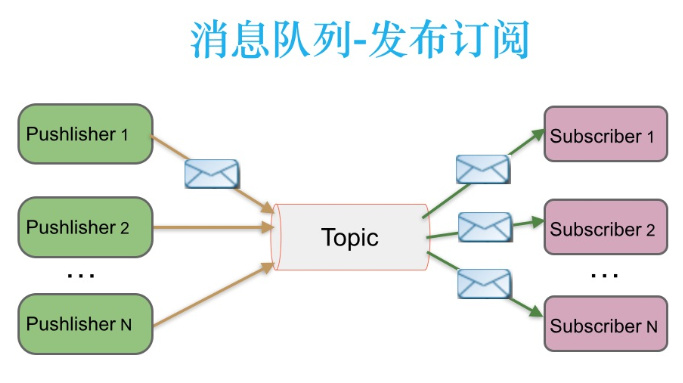
发布者发送到topic的信息 只有订阅了topic的订阅者才会收到信息

 浙公网安备 33010602011771号
浙公网安备 33010602011771号