

【clickhouse 优化篇-查询计划&建表优化&数据一致性04】
一、Explan查看执行计划
1、基本语法
- PLAN:用于查看执行计划,默认值。
- header 打印计划中各个步骤的 head 说明,默认关闭,默认值 0;
- description 打印计划中各个步骤的描述,默认开启,默认值 1;
- actions 打印计划中各个步骤的详细信息,默认关闭,默认值 0。
- AST :用于查看语法树;
- SYNTAX:用于优化语法;
- PIPELINE:用于查看 PIPELINE 计划。
- header 打印计划中各个步骤的 head 说明,默认关闭;
- graph 用 DOT 图形语言描述管道图,默认关闭,需要查看相关的图形需要配合
- graphviz 查看;
- actions 如果开启了 graph,紧凑打印打,默认开启。
explain plan header=1, actions=1,description=1 select database,table,count(1) cnt from system.parts where database in ('datasets','system') group by database,table order by database,cnt desc limit 2 by database;
header=1, actions=1,description=1这几个参数默认是没有的,实际工作中为了更加详细的查看,可以加上
2)AST语法树
EXPLAIN AST SELECT number from system.numbers limit 10;
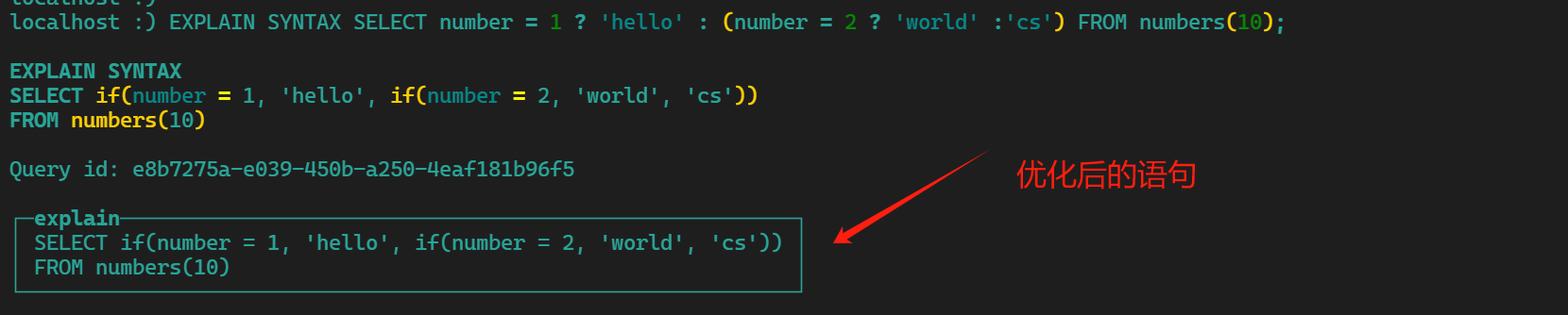
3)SYNTAX语法 -->用于语法优化
EXPLAIN SYNTAX SELECT number = 1 ? 'hello' : (number = 2 ? 'world' :'cs') FROM numbers(10);
4) 查看PLPELINE
EXPLAIN PIPELINE SELECT sum(number) FROM numbers_mt(100000) GROUP BY number % 20; -- 打开其他参数 EXPLAIN PIPELINE header=1,graph=1 SELECT sum(number) FROM numbers_mt(10000) GROUP BY number%20;
二、建表优化
1、数据类型
1.1 时间字段的类型
在hive中建表时数值型或日期时间型一般是以String类型存储的,但是clickhouse最好是直接存储源类型(日期类型就存储日期类型)。
因为:clickhouse底层将DateTime存储为时间戳Long类型,但是不建议存储Long类型,因为DateTime不需要经过函数转换处理。
create table t_type2( id UInt32, sku_id String, total_amount Decimal(16,2), create_time Int32 ) engine=ReplacingMergeTree(create_time) partition by toYYYYMM(toDate(create_time)) --需要进行转换,否则报错 primary key (id) order by (id,sku_id);
从上面的例子可以看出,如果create_time直接存储为dateTime类型就在设置分区的时候就不需要转换了,而可以直接使用,是不是对于性能就更好
1.2 空值存储类型
clickhouse的nullable类型很容易拖累性能,因为存储null列时需要创建额外的文件来存储null标记,并且null列无法被索引。因此除特殊情况发外,clickhouse避免使用null,应该用字段默认值或者指定一个在业务中无意义的值来替代null
案例:
1)创建t_null表、插入数据
CREATE TABLE t_null(x Int8, y Nullable(Int8)) ENGINE TinyLog; INSERT INTO t_null VALUES (1, NULL), (2, 3);
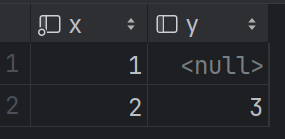
创建的表第二列有一个null
2)对x、y进行相加操作
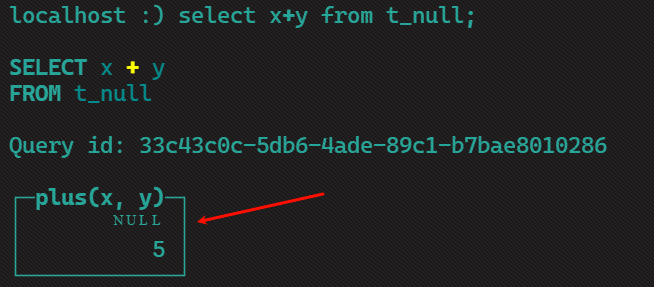
相加时发现1+null的结果=null,所有从侧面表示clickhouse的null值不准确
3)查看存储文件
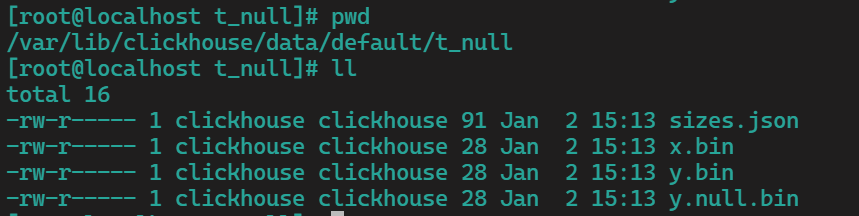
查看发现,这里多一个y.null.bin文件,所以只要是每一列存储一个null值,那么就会多一个null的文件,这样在查询时就会多查一个文件,肯定会拖累性能
2、分区和索引
分区粒度根据业务特点决定,不宜过粗或过细。一般选择按天分区,也可以指定为Tuple(),已单表一亿数据为例,分区大小控制在10-30个 为最佳
必须指定索引列,ClickHouse中的索引列及排序列,通过order by指定,一般在查询条件中经常被用来充当筛选条件的属性被纳入进来;可以是单一维度,也可以是组合维度的索引;
通常需要满足高级列在前、查询频率大的在前原则;还有基数特别大的不适合制作索引
3、表参数
index_granularity是用来控制索引粒度的,默认是8192,如非必须不建议调整
4、写入和删除优化
写入过快报错,报错信息:
1. Code: 252, e.displayText() = DB::Exception: Too many parts(304). Merges are processing significantly slower than inserts 2. Code: 241, e.displayText() = DB::Exception: Memory limit (for query) exceeded:would use 9.37 GiB (attempt to allocate chunk of 301989888 bytes), maximum: 9.31 GiB
处理方式:
- 在服务器内存充裕的情况下增加内存配额,一般通过 max_memory_usage 来实现
- 在服务器内存不充裕的情况下,建议将超出部分内容分配到系统硬盘上,但会降低执行速度,一般通过 max_bytes_before_external_group_by、max_bytes_before_external_sort 参数来实现
备注:这三个参数都在user.xml中
5、常见配置
配置项主要在config.xml或users.xml中,基本上都在user.xml里
5.1、CPU资源
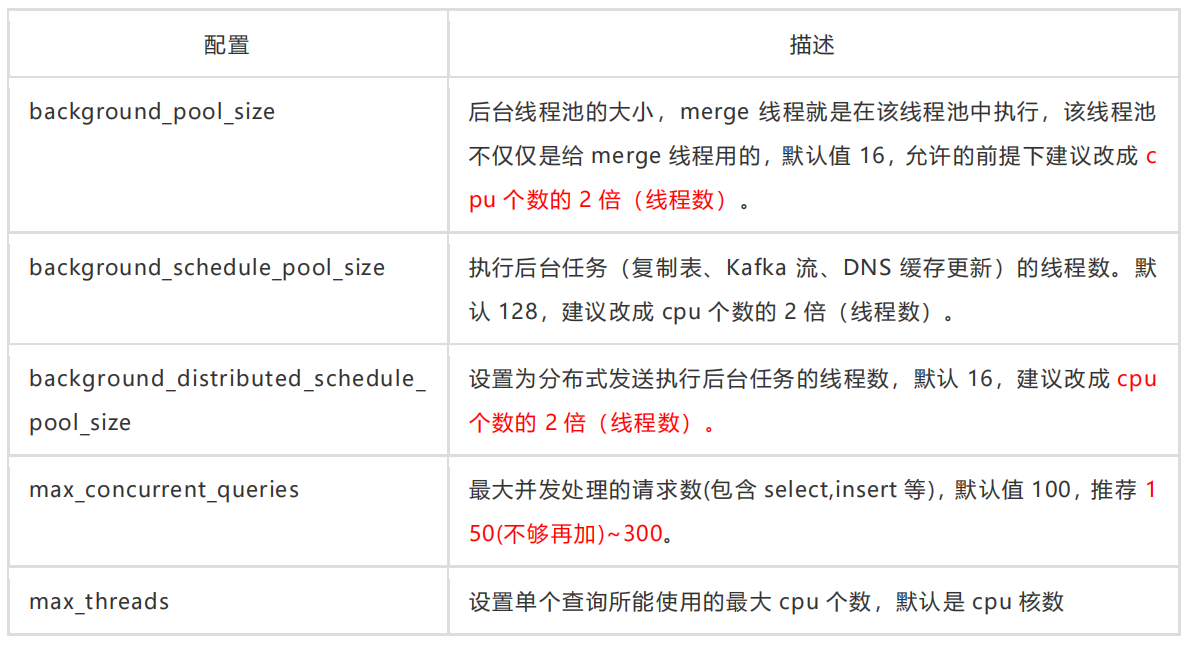
5.2、内存资源

上面的通常位于 config.xml 或 users.xml 中
具体设置类似于这样
<background_pool_size>32</background_pool_size>
解压tar格式的压缩包,用tar -xvf xxx.tar --->一般解压tar.gz文件,用tar -zxvf xxx.tar.gz
