【ES HTTP-索引/文档增删改查&映射操作 01】
一、数据存储:
- 结构化数据,一般会用二维的表结构来存储,如:mysql等关系型数据库
- 非结构化数据,即无法用关系型数据库存储的数据,如:日志、通讯记录、报表、视频、图片等,一般会把这种类型的数据存储在NoSQL中,如:MongoDB,redis,Hbase等,并且是以k-v形式保存的,可以通过key来查询
- 半结构化数据,将数据的结构和内容混在一起,比如:xml,html,这样的数据一般也会保存在MongoDB这样的nosql种,但是一个缺点是查询内容不太容易
- Elaticsearch,简称为 ES,ES 是一个开源的高扩展的分布式全文搜索引擎,是整个 Elastic Stack 技术栈的核心。它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理 PB 级别的数据
二、docker安装elasticsearch7.8和kibana7.8
1、先设置系统参数max_map_count,否则 Elasticsearch 无法启动
/etc/sysctl.conf 文件添加vm.max_map_count=262144
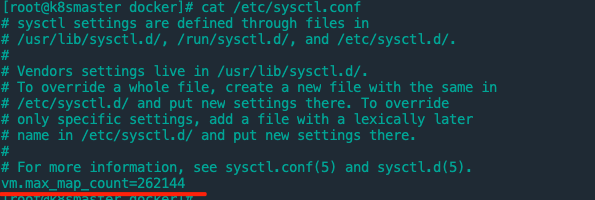
执行更新命令:sysctl -p
2、创建共通网络,elasticsearch和kibana或者集群可以互相访问
docker network create es-net
3、拉取ES和kinana镜像
docker pull elasticsearch:7.8.0
docker pull elastic/kibana:7.8.0
4、创建映射容器的文件目录
# 用于挂载es插件目录和数据 创建01目录仅代表节点 mkdir -p -m 777 /mydata/es/01/plugins mkdir -p -m 777 /mydata/es/01/data mkdir -p -m 777 /mydata/es/01/logs
如果想创建多借点就继续映射02、03用于创建多个ES容器节点
6、启动ES
docker run --name=es-01 \ --restart=always \ --privileged \ --net es-net \ -p 9200:9200 \ -p 9300:9300 \ -v /mydata/es/01/plugins:/usr/share/elasticsearch/plugins \ -v /mydata/es/01/data:/usr/share/elasticsearch/data \ -v /mydata/es/01/logs:/usr/share/elasticsearch/logs \ -e node.name=es-01 \ -e node.master=true \ -e network.host=es-01 \ -e discovery.seed_hosts=es-01 \ -e cluster.initial_master_nodes=es-01 \ -e cluster.name=es-cluster \ -e "ES_JAVA_OPTS=-Xms256m -Xmx256m" \ -d elasticsearch:7.8.0
如果想多个节点集群,那么一开始所有的ES容器创建就要进行设置,有几个设置几个
-e discovery.seed_hosts=es-01,es-02,es-03,es-04 \
设置主节点
-e cluster.initial_master_nodes=es-01 \
别的属性按照自身设置即可(基本不用改,修改下对应的容器名字即可)
7、浏览器输入http://docker所在服务器的ip:9200 出现以下信息即为成功:
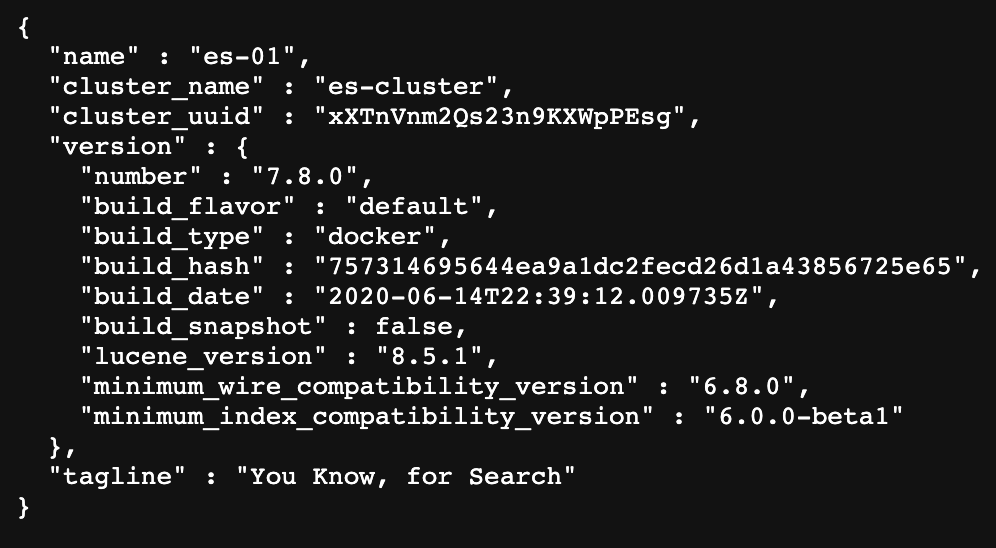
问题:浏览器输入地址后无法打开
第一步:进入ES容器内:
docker exec -it a02ec37af784 /bin/bash
第二步:修改elasticsearch.yml文件
vi config/elasticsearch.yml #添加下面两行文件,并修改host为本机IP地址 http.cors.enabled: true http.cors.allow-origin: "*" network.host: 172.16.137.131
其中:
http.cors.enabled: true:此步为允许elasticsearch跨域访问,默认是false。
http.cors.allow-origin: “*”:表示跨域访问允许的域名地址(*表示任意)。

第三步:重启docker
docker restart es-01
再次浏览器输入,显示成功
8、创建kibana容器
docker run --name kibana -p 5601:5601 --restart=always --network=es-net -e ELASTICSEARCH_HOSTS=http://es-01:9200 -d elastic/kibana:7.8.0
-e ELASTICSEARCH_HOSTS=http://es-01:9200 \ 设置es的访问路径
浏览器输入:http://docker所在服务器的ip:5601 出现以下信息即为成功
三、Elasticsearch基本操作
1、数据格式
Elasticsearch是面向文档型数据库,一条数据在这里就是一个文档(相当于关系型数据库的一行)。下面是ES存储文档数据和MySQL存储数据的概念进行一个类比
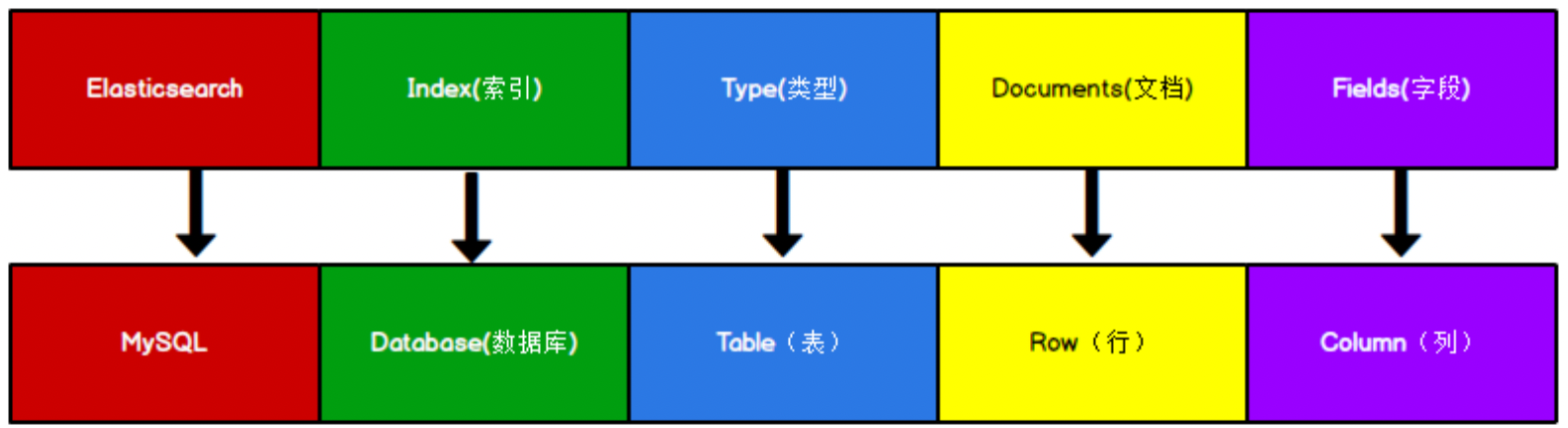
ES里的index可以被看做是一个库,Type相当于表(ES7.x版本Type的概念已经被删除了),Documents相当于表的行
ES为了能快速准确的查询,用到了一个特殊的概念用于查询和存储,这个概念叫倒排索引
|-- 以下对比正排索引和倒排索引来了解ES倒排索引查询的原理
正排(向)索引:
id content
-------------------
1001 my name is tom
1002 my name is jack
用ID来查询结果会很快,因为ID可以被作为主键,如果用content中的name查询因为有很多,所以会遍历整个数据库所以会很慢
倒排索引
keyword id
------------------
name 1001,1002
tom 1001
name关键字查询,会匹配上1001,1002两个ID的数据,tom关键字查询会匹配上1001的数据,所以也能看出来ES是以关键字作为检索条件的,这样的优势是快速查询劣势就是无法精准查询
2、HTTP操作
2.1、索引操作
1)创建索引
对比关系型数据库,创建索引就等同于创建数据库
Postman中,向ES服务器发PUT请求:http://172.16.137.131:9200/house

注意:创建索引库的分片数默认1片,7.0.0之前的Elasticsearch版本默认是5片
重复添加索引,会返回错误信息,因为put类型是具有密等性的
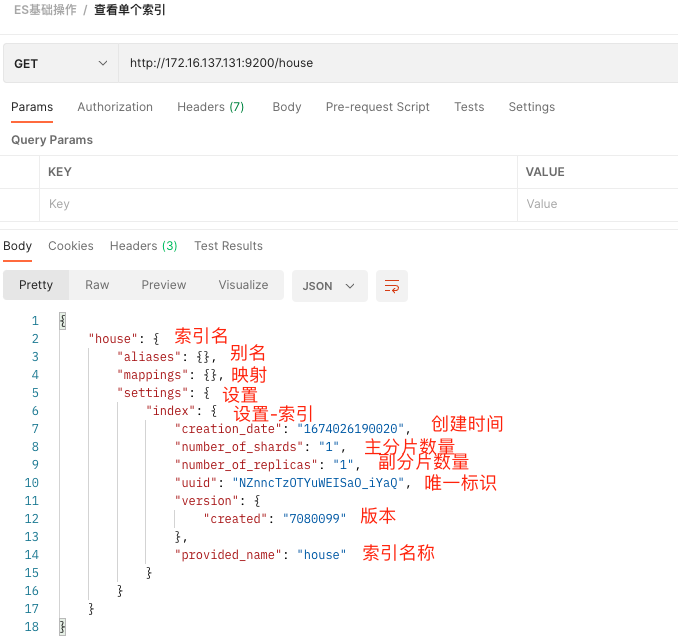
2)查看单个索引
向ES服务器发GET请求:http://172.16.137.131:9200/house
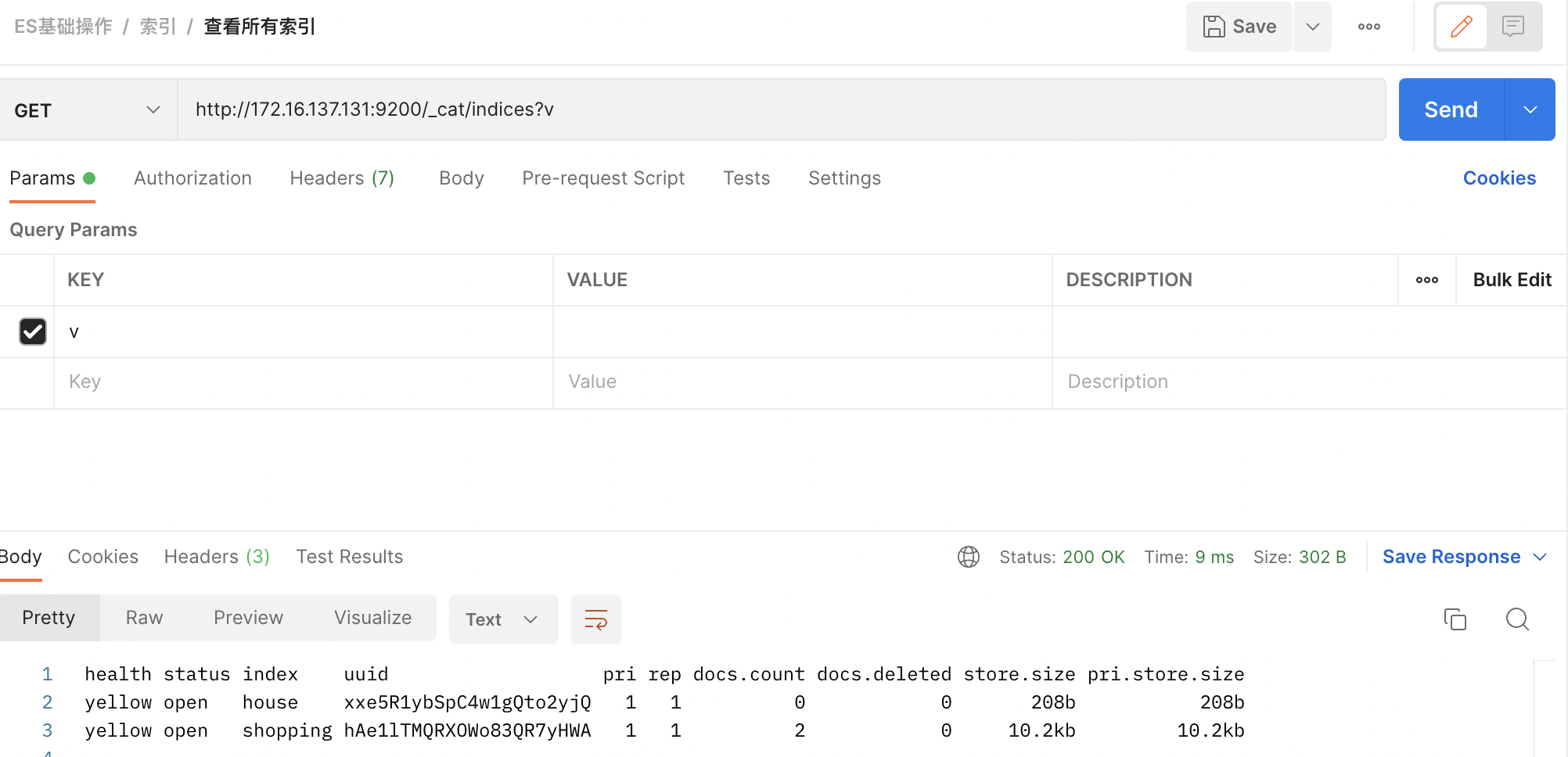
3)查看所有索引
向ES服务器发GET请求:http://172.16.137.131:9200/_cat/indices?v
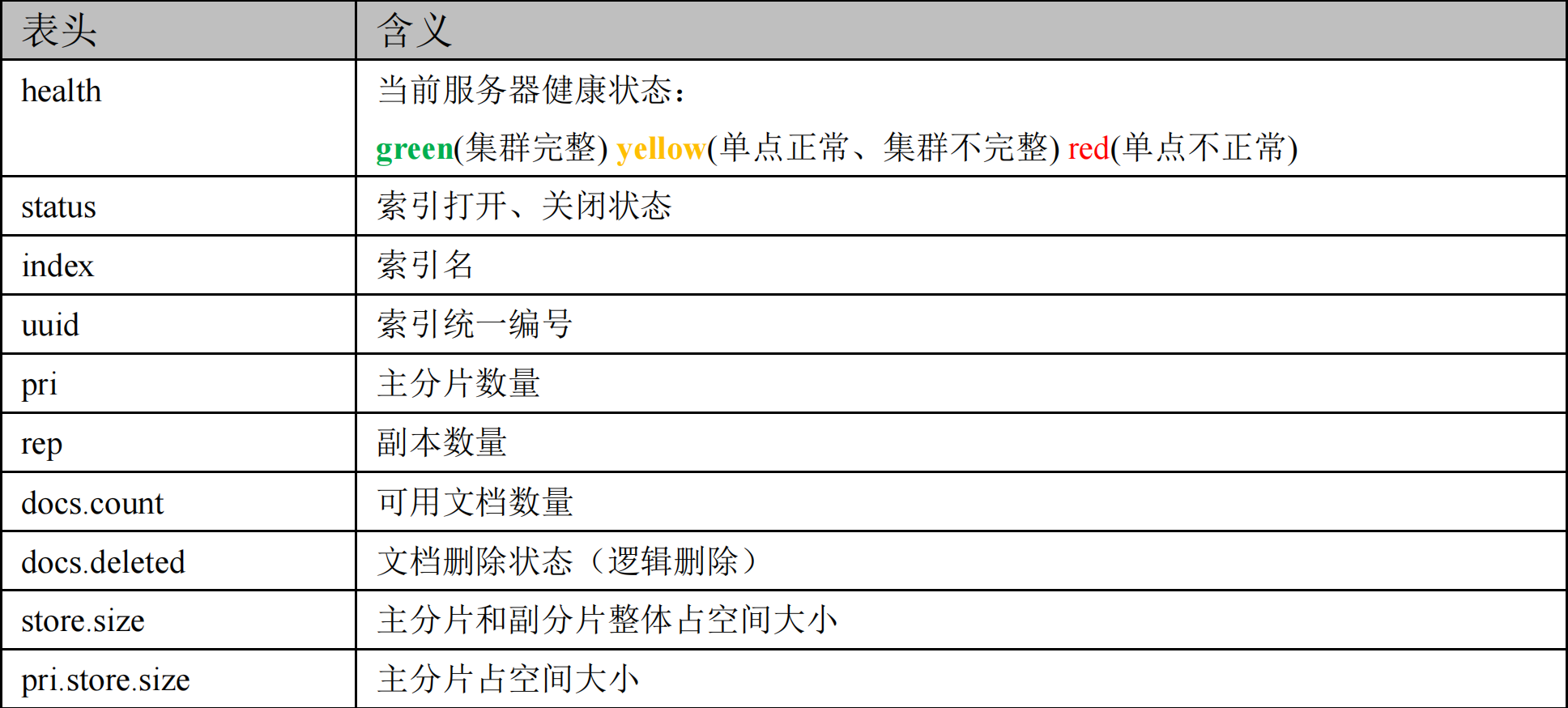
_cat查看的意思,indices表示索引,类似MySQL中的show tables
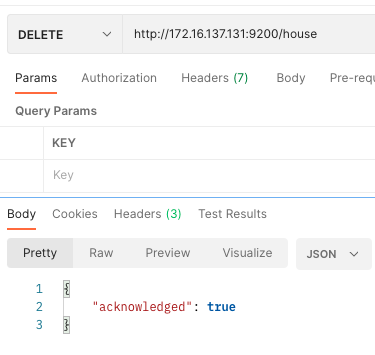
4)删除索引
向ES服务器发DELETE请求:http://172.16.137.131:9200/house
2.2、文档操作
1)创建文档 --类比插入表数据,添加的数据格式是JSON格式
发送POST请求:http://172.16.137.131:9200/shopping/_doc
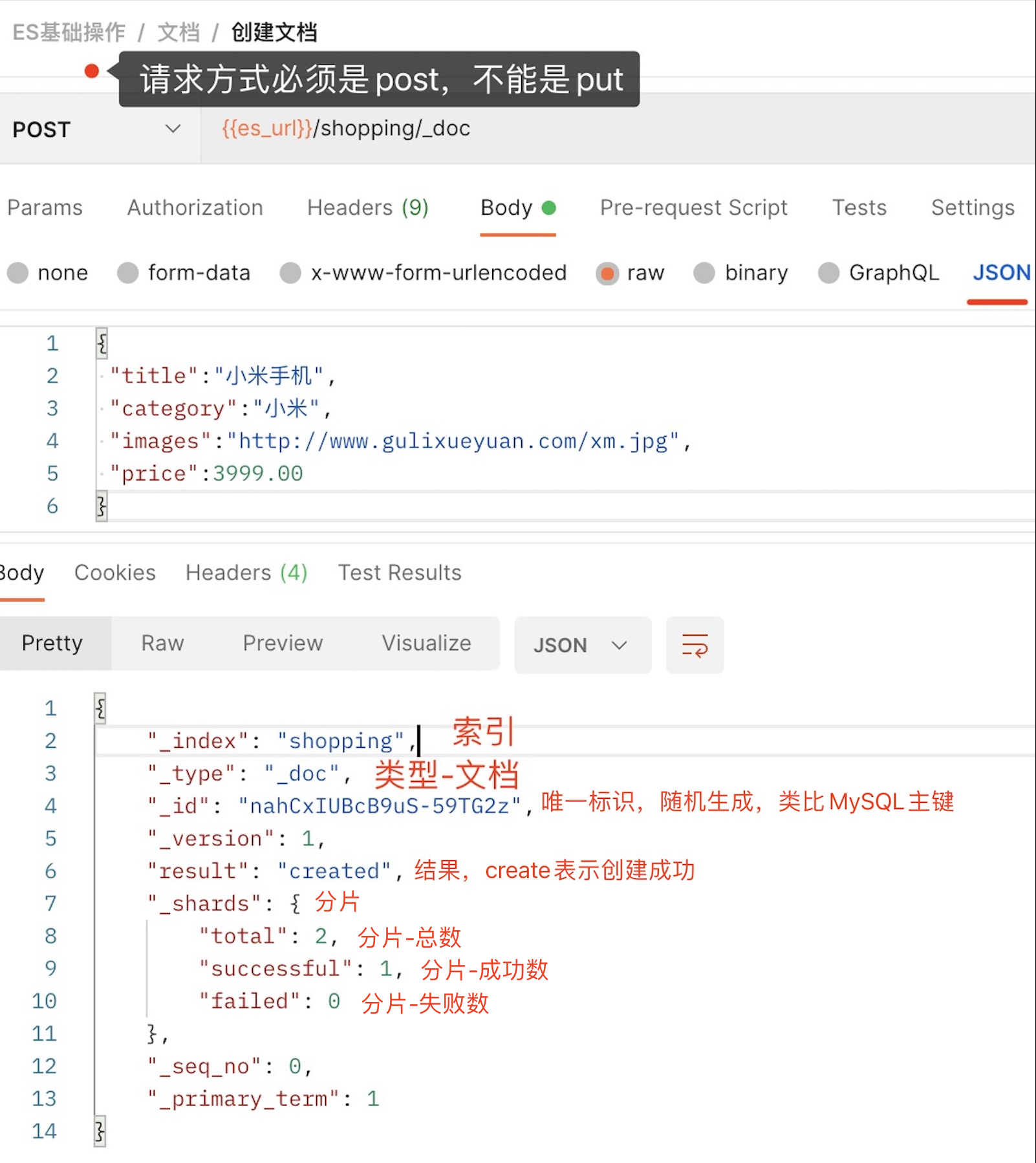
上面的ID由于没有指定,所以默认情况下ES会随机生成一个,如果想要自定义唯一性标识符,可以在创建时指定http://172.16.137.131:9200/shopping/_doc/1001
2)查看文档 --查看文档时,需要指明文档的唯一性标识,类似于MySQL中数据的主键查询
发送GET请求:http://172.16.137.131:9200/shopping/_doc/10010

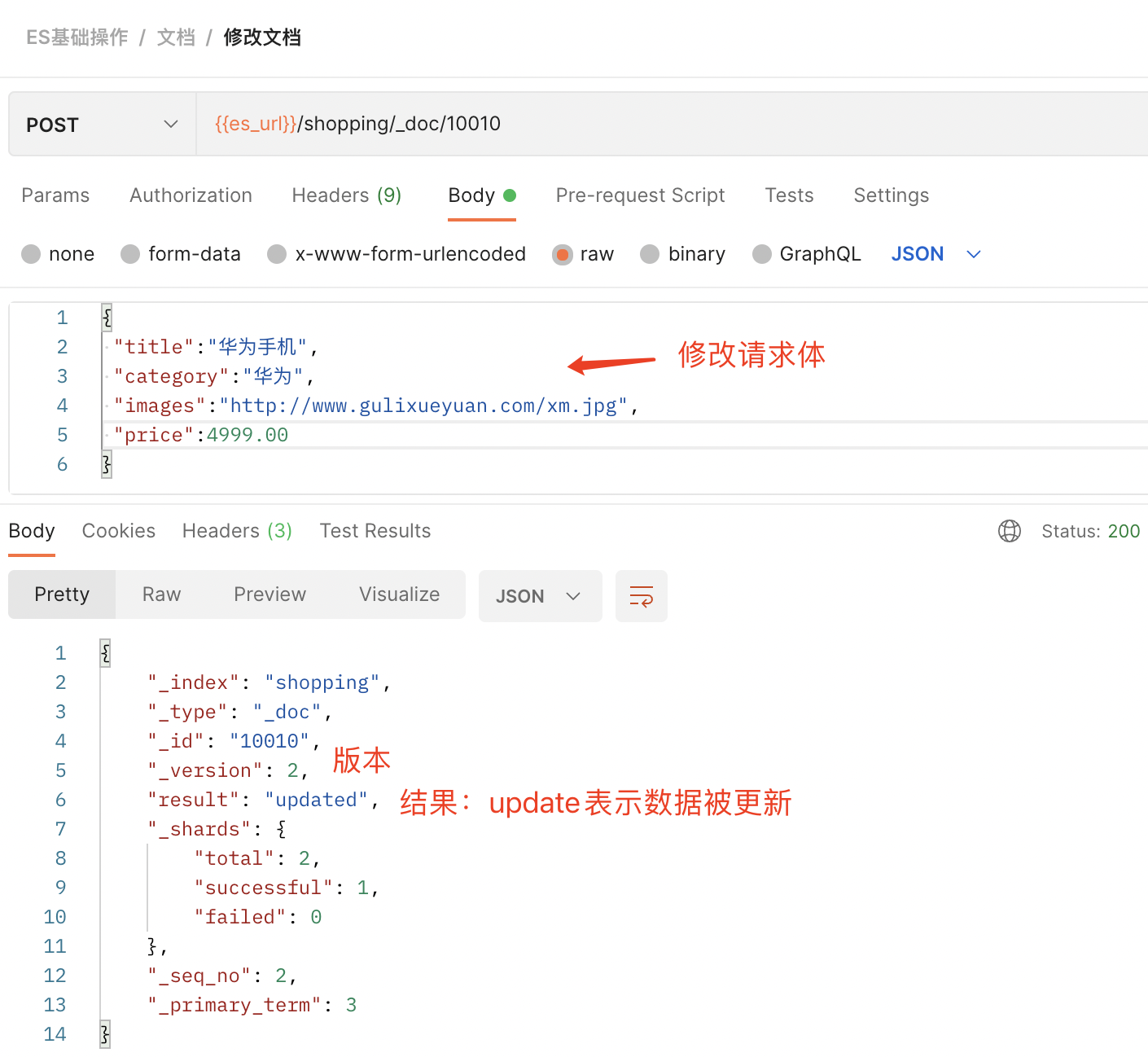
3)修改文档
发送POST请求:{{es_url}}/shopping/_doc/10010
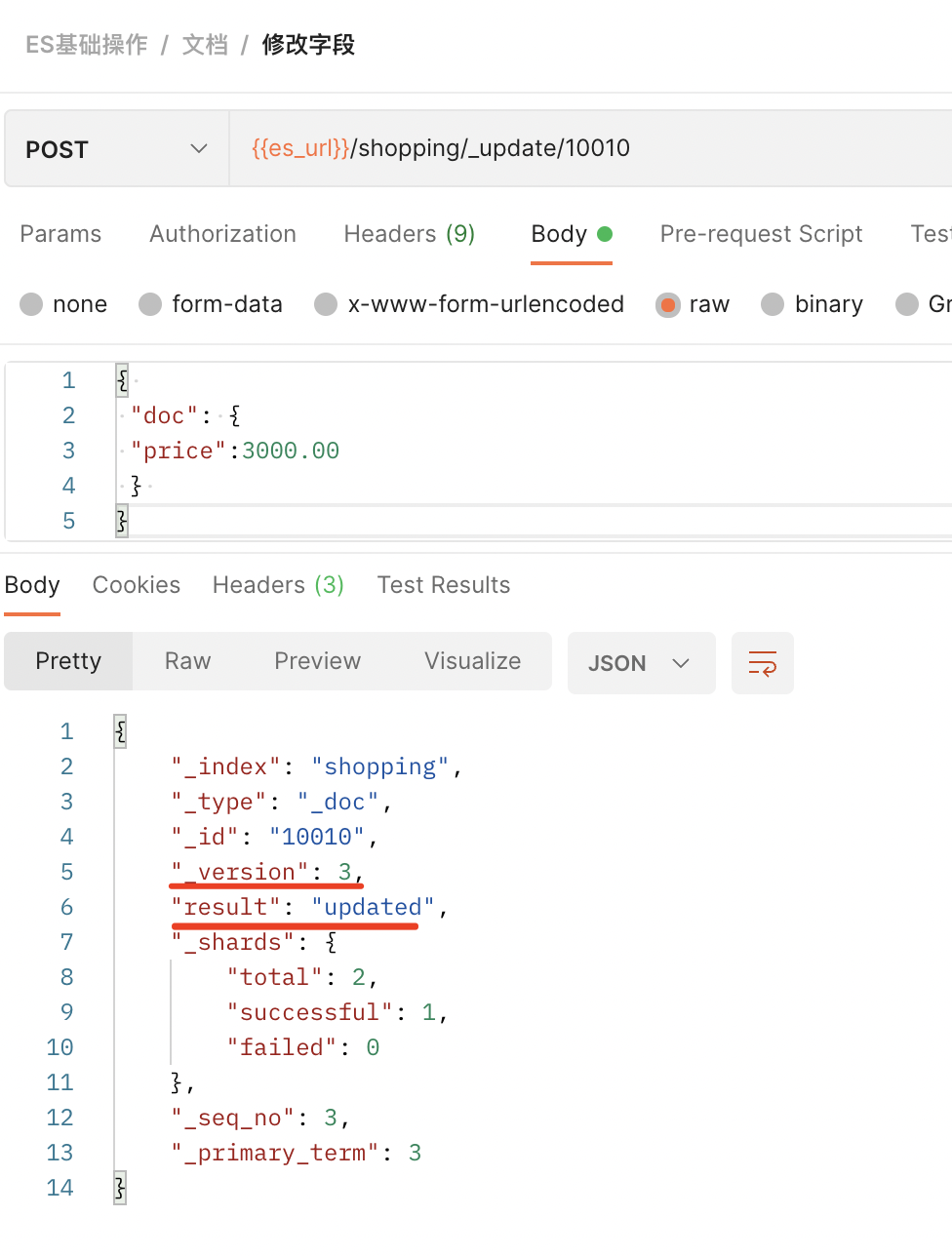
4)修改字段 --只修改一条数据的局部信息
发送POST请求:{{es_url}}/shopping/_update/10010
请求体内容: { "doc": { "price":3000.00 } }
5)删除文档 --这里的删除是逻辑删除
发送DELETE请求:{{es_url}}/shopping/_doc/10011

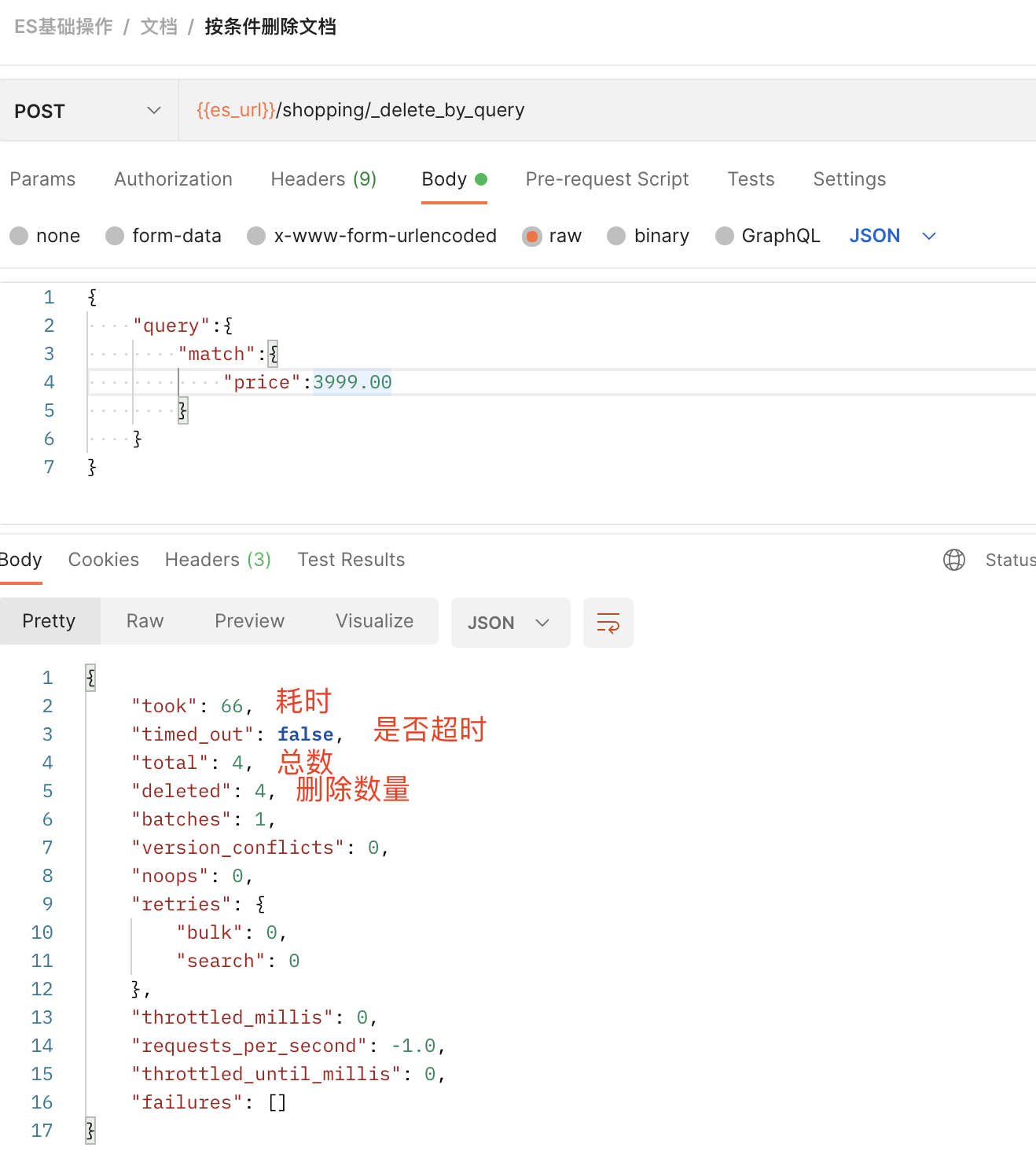
6)条件删除文档
一般删除数据都是根据唯一标识进行删除,实际操作时,也可以根据条件对多条数据进行删除
# 删除shopping索引下price=3999的所有数据
发送POST请求:{{es_url}}/shopping/_delete_by_query
//请求体 { "query":{ "match":{ "price":3999.00 } } }
2.3、映射关系
创建了索引库就相当于创建了database,接下来就需要建映射了(映射类似于数据库中的表结构)创建数据库表需要设置字段名称,类型,长度,约束等,索引库也一样,需要知道这个类型下
有哪些字段,每个字段有哪些约束信息,这就叫做映射
1)创建映射
发送PUT请求:{{es_url}}/shopping/_mapping
//请求体内容 {
"properties": {
"name": {
"type": "text",
"index": true
},
"sex": {
"type": "text",
"index": false
},
"age": {
"type": "long",
"index": false
}
}
}
映射数据说明:
- 字段名:任意填写,下面指定许多属性,例如:title、subtitle、images、price
- type:类型,ES中支持的数据类型非常丰富,说几个关键的:
- String类型,又分为两种:
- text:可分词
- keyword 不可分词,数据会作为完整字段进行匹配
-
Numerical:数值类型,分两类
- 基本数据类型:long、integer、short、byte、double、float、half_float
- 浮点数的高精度类型Lscaled_float
- Date:日期类型
- Array:数组类型
- Object:对象
- index:是否索引,默认为true,也就是说不进行任何配置,所有字段都会被索引
- true:字段会被索引,则可以用来进行搜索
- false:字段不会被索引,不能用来搜索
- store:是否将数据进行独立存储,默认为false
- 原始的文本会存储在_source里面,默认情况下提取出来的字段都不是独立存储的是从_source里面提取出来的,要想独立存储需要设置store:true,获取独立存储的字段要比_source中解析快的多,但是也会占用更多的空间,所以需要根据实际业务需求来设置
- analyzer:分词器,这里的ik_max_word即使用ik分词器
- String类型,又分为两种:
2)查看映射
发送GET请求:{{es_url}}/shopping/_mapping


3)索引映射关联
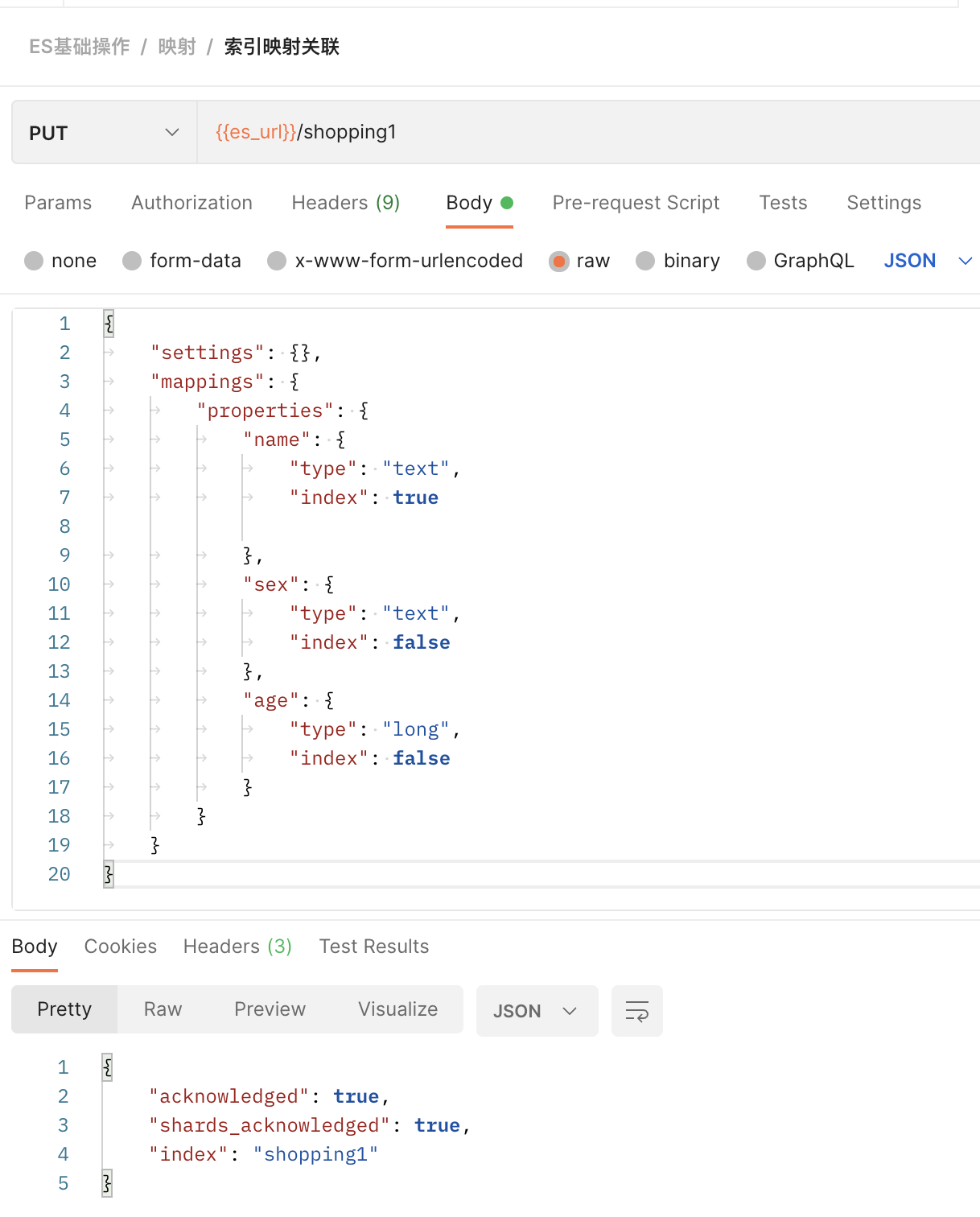
发送PUT请求:{{es_url}}/shopping1
//请求体内容 { "settings": {}, "mappings": { "properties": { "name": { "type": "text", "index": true }, "sex": { "type": "text", "index": false }, "age": { "type": "long", "index": false } } } }