
【Python random&re&time模块&正则表达式&os模块&sys模块 08】
一、常用模块rendom
什么叫模块? import time time这样的就叫模块
模块都是C写的,所有的模块当中也是一对代码,这一对代码引入以后就可以直接使用
模块的分类
- 内置模块
- 扩展模块\第三方模块 (比如:django,pandas等)
- 自定义模块
1、random模块 (随机函数)
随机的规则:在某一个范围中能够抽到每一个值的概率都是相同的
import random
ret=random.random() #0~1之间的随机数
print(ret)
# 100-200之间的随机整数
ret2 = random.randint(100,200) #-->randint取随机整数,左右都是闭区间【】
print(ret2)
ret3 = random.randrange(100,200,50) #randrange(start,end,end)
print(ret3)
lst = [1,2,3,4,5,6,7]
random.shuffle(lst) #shuffle随机打乱列表内的元素,常用于扑克牌洗牌
print(lst)
ret4 = random.choices([1,2,'zx',[1,2,3]]) #随机取一个值
print(ret4)
ret5 = random.sample([1,2,'alex',[1,2,3]],20) #随机取多个值
print(ret5)
二、正则表达式
正则表达式 : 只和字符串打交道 # 第一: 从一大段文字中,获取符合条件的内容 # 爬虫 # 第二: 检测某一个字符串,是否完全符合规则 # 表单的验证 # 并不会真的请求银行,具体手机,具体的邮件 # 总是根据一些规则来先判断是否合法
1)字符组
- 匹配所有数字:[1-9]
- 匹配所有小写字母:[a-z]
- 匹配所有大写字母:[A-Z]
- 匹配所有字母数字:[0-9a-zA-Z],
- |-这里的匹配规则只能从ascii码小的值到大的值,可以一次取多个区间:[0-9a-f] a 的ascii是97 A是64
2)元字符
- \d [0-9] 一样的意思
- \w [0-9a-zA-Z_] 表示:数字字母下划线中文
- \s \t \n 匹配所有的空白符\制表符\换行符
- \D \W \S 匹配所有非数字\匹配所有非数字字母下划线\匹配所有非空白
- . 匹配除了换行符之外的任意一个字符
- ^ $ 匹配一个字符串的开始,$匹配一个字符串的结束
- [] [^] 字符组 非字符组
- | () 或 用来规范符号的作用域
3)量词
- {n} 表示匹配n次
- {n,} 表示匹配至少n次
- {n,m} 表示最少匹配n次,最多匹配m次
- ? 0或1次
- + 1-无穷大
- * 0-无穷大
#案例:匹配手机号码
1[3-9]\d{9}
#案例:匹配任意一个正整数
[1-9]\d*
#案例:匹配任意一个小数
\d+\.\d+ ===>\d+表示长度的数字 \.是把.转义使用的
#案例:匹配整数或小数
\d*(\.\d+)? ===>通过()进行了分组,然后通过?确定要么是整数,要么就是小数,保证10.这样的数字是匹配不上的
注意:
- 只写元字符 一个元字符表示一位字符上的内容
- 元字符量词 量词只约束前面的一个元字符\
- (元字符元字符)量词 量词只能加一个
所有的正则表达式在工具中如果匹配成功,直接放到r'' 就可以直接使用 --> 意思是防止转义
三、re模块
1)findall、search、match方法
import re # findall匹配所有匹配项目 ret = re.findall('\d+','hello123,world456') print(ret) #['123', '456'] # search从头开始往后找,任何地方有符合条件的都返回一个,并且分组后只返回第一个 ret1 = re.search('\d+','hello123,world456') print(ret1) print(ret1.group()) #123
# match从头开始匹配,如果开始部分匹配到了匹配成功,如果开始部分没有匹配到就是匹配失败
ret1 = re.match('\d+','123hello123,456world456')
print(ret1)
print(ret1.group()) #123
# findall中的分组优先 ret3 = re.findall('\d+(\.\d+)?','hello123.222,world456.555') print(ret3)#['.222', '.555'] ''' 执行的结果为什么会出现这种情况,其实findall会把123.222和456.555都取出来, 但是由于分组优先的规则所以把.后面的内容取出来了, 那么如何解决? ''' ret4 = re.findall('\d+(?:\.\d+)?','hello123.222,world456.555') print(ret4) #['123.222', '456.555'] '''只需要在\.前面加上?:即可解决'''
#案例:手机号码的验证
import re phone = input('请输入手机号码:') regex = r'^1[2-9]\d{9}$' ret = re.search(regex,phone) if ret: print('手机号是合法的 %s'%phone) else: print('手机号是不合法的!')
如果用match,regex=r'1[2-9]\d{9}$' regex中就不需要^
#了解内容:根据正则进行切割
ret = re.split(r'\d+',r'alex84wusir78') print(ret)
2)sub 替换方法
# sub替换方法 语法:sub(正则表达式,要替换的内容,待替换的字符串,替换的个数) ret = re.sub(r'\d','W','alex789wusir234',1) print(ret) #alexW89wusir234
3)subn 替换方法
# subn替换方法2 返回值是一个元组,第一项是结果,第二项是替换次数 ret = re.subn(r'\d+','W','alex789wusir234',2) print(ret) #('alexWwusirW', 2)
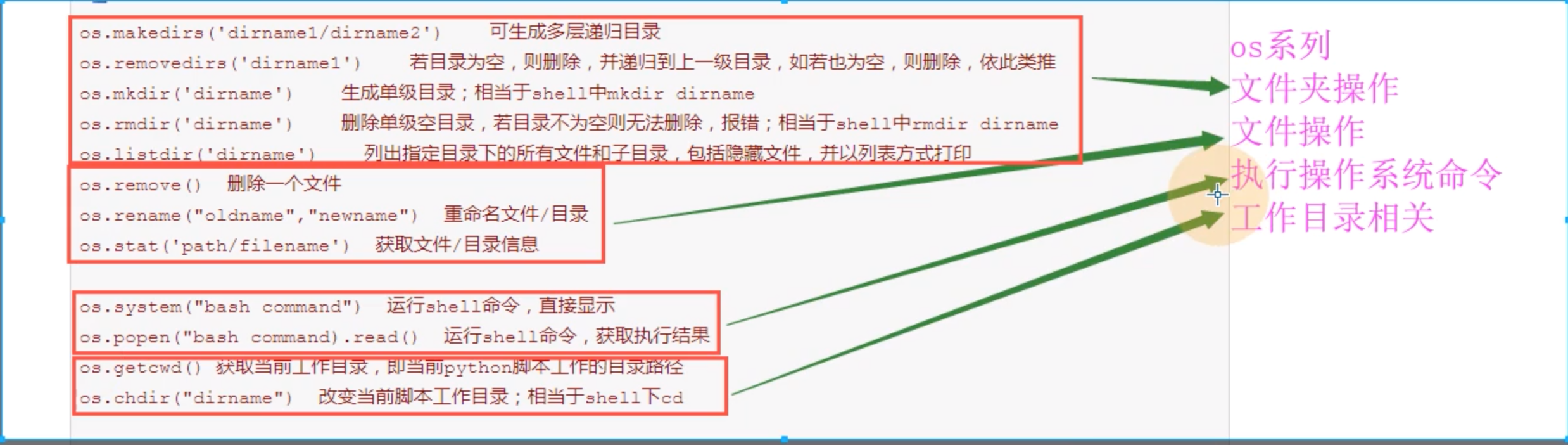
四、os模块
- os.path.getsize(绝对路径) 获取文件的大小,但是不能获取文件夹的准确大小
- os.path.isfile(绝对路径) 判断是否是文件
- os.path.isdir(绝对路径) 判断是否是文件夹
- os.path.join(文件夹的名字,名字) 跨平台的文件路径的拼接
- os.listdir('文件夹的名字') 显示这个文件夹下的所有名字(包括文件和文件夹)
#案例:计算文件夹的大小
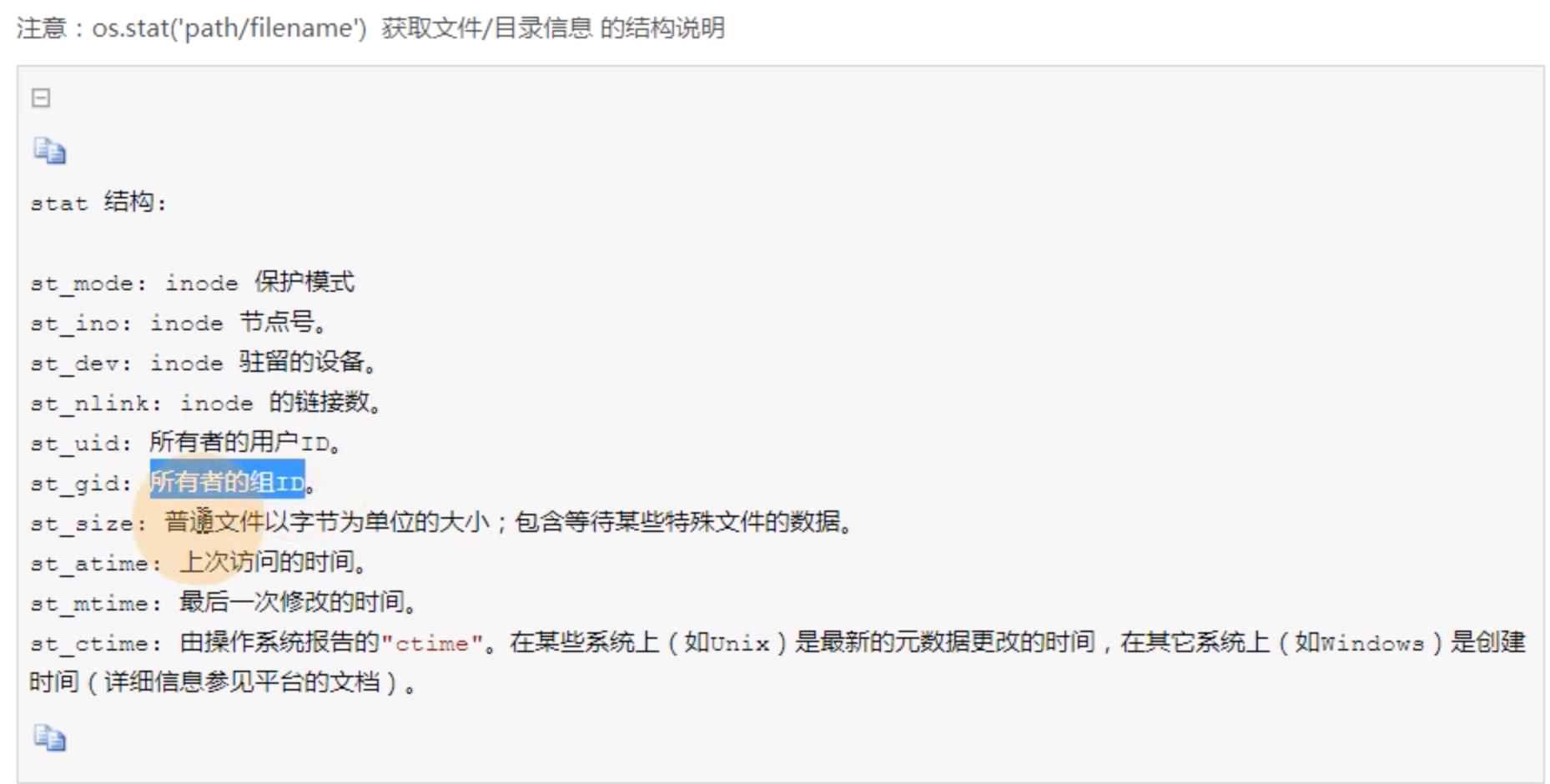
import os def path_size(path): # 判断是不是文件夹 if os.path.isdir(path): sum_size = 0 # 获取path路径下文件的名称,最终生成的是一个列表 dir_name = os.listdir(path) # 遍历列表 for name in dir_name: # 把列表和路径拼接在一起 file_path = os.path.join(path,name) # 如果是一个文件,则计算所有文件的大小并相加求和,否则(文件夹)利用递归再次进行剥离计算此文件夹路径下的文件大小 print(file_path) if os.path.isfile(file_path): sum_size +=os.path.getsize(file_path) else: path_size(file_path) return sum_size #判断是文件,然后计算文件大小 elif os.path.isfile(path): # print('这是一个文件') return os.path.getsize(path) else: print('这不是一个文件或文件夹') path1 = r'/Users/wufq/Documents/pythonSenio/day03' path2 = r'/Users/wufq/Documents/pythonSenio/day03/eval和exec函数.py' path3 = r'/Users/wufq/Documents/pythonSenio/day03/dir1/dir_son1' ret1 = path_size(path3) print(ret1)
os
os.path

#举例:
path = r'/Users/wufq/Documents/pythonSenio/day03/eval和exec函数.py' ret = os.path.split(path) ret1 = os.path.split(r'/Users/wufq/Documents/pythonSenio/day03') print('split1------>',ret) print('split2------>',ret1) ret = os.path.dirname(path) print('dirname------>',ret) ret = os.path.basename(path) print('basename------->',ret) 执行结果: split1------> ('/Users/wufq/Documents/pythonSenio/day03', 'eval和exec函数.py') split2------> ('/Users/wufq/Documents/pythonSenio', 'day03') dirname------> /Users/wufq/Documents/pythonSenio/day03 basename-------> eval和exec函数.py
注意:os.path.split 切割路径形成元组,但是永远切割的是最后一个内容,比如路径最后一个是eval和exec函数.py,那么切割是就会切成结果1这样子,如果路径最后一个是day03,那么切割时就会切成结果2的样子,反正就会把最后一个元素切出来,分成两半,dirname取split切割后路径的第一个元素,basename取split切割后路径的第二个元素
五、时间模块
5.1、time模块
# 1、时间戳时间 -->1970年截止到当前时间 ret = time.time() print(ret) # 2、结构化时间 tm_isdst:夏令时 ret1 = time.localtime() print(ret1) #time.struct_time(tm_year=2022, tm_mon=5, tm_mday=4, tm_hour=11, tm_min=49, tm_sec=49, tm_wday=2, tm_yday=124, tm_isdst=0) # 格式化时间 --->time模块的格式化不识别中文 ret2=time.strftime('%Y-%m-%d %H:%M:%S') print(ret2) #2022-05-04 11:58:05

三种格式之间的转换 -->会这三种转换就可以了
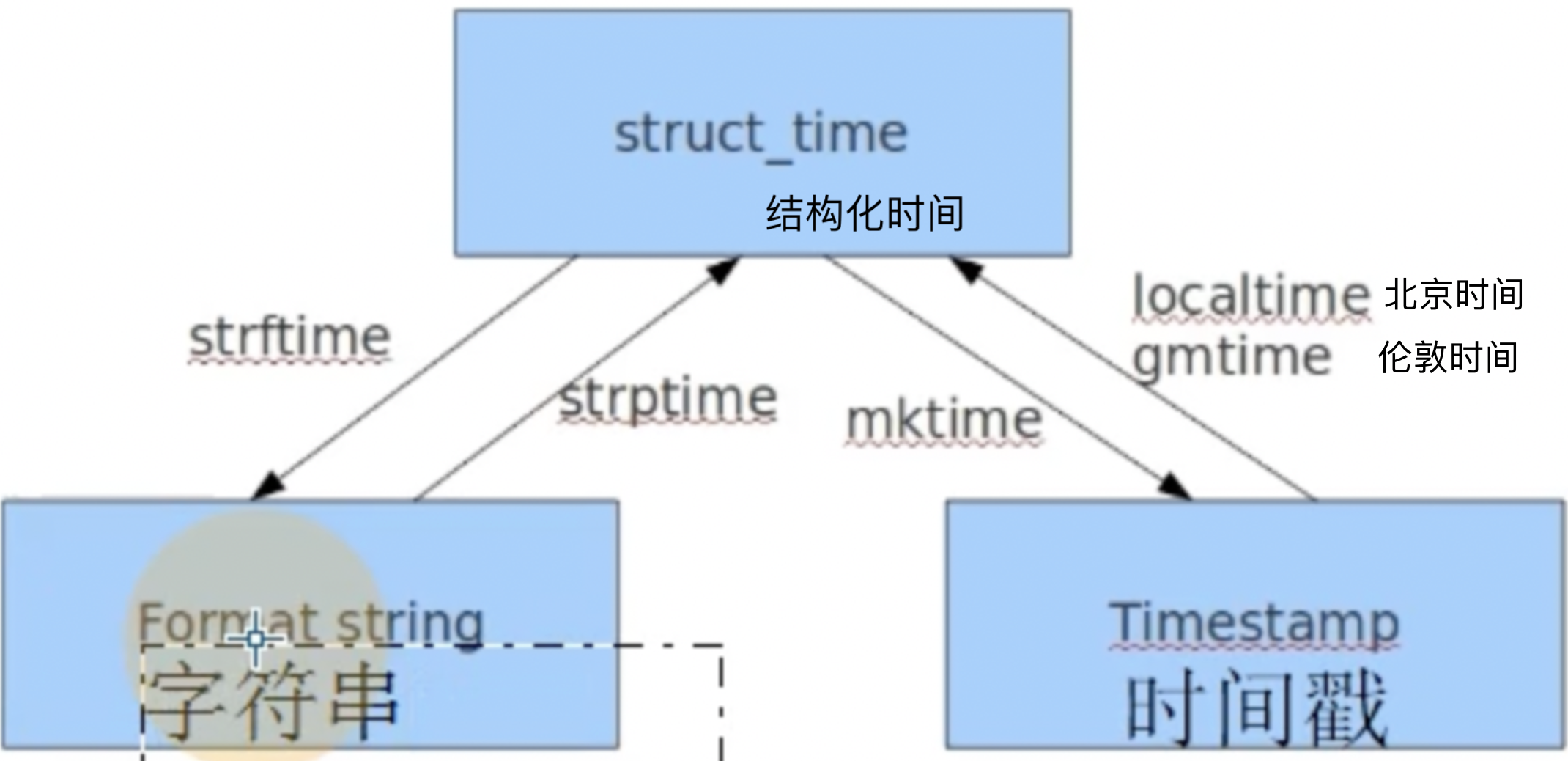
# 案例:三种时间格式相互转换
# 字符串-->时间戳 str_time = '20220501 12:20:10' struct_time = time.strptime(str_time,'%Y%m%d %H:%M:%S') #注意:%Y%m%d这个格式必须和需要转换的字符串内时间的格式保持一致
# 结构化-->时间戳 time_stamp = time.mktime(struct_time) print('字符串-->时间戳:',time_stamp) # 时间戳-->结构化时间 time_stamp1= 2000000000 struct_time1 = time.localtime(time_stamp1) print('时间戳-->结构化时间:',struct_time1) # 结构化时间-->字符串 struct_time2 = time.localtime() str_time1 = time.strftime('%Y-%m-%d %H:%M:%S',struct_time2) print('结构化时间-->字符串:',str_time1) 执行时间: 字符串-->时间戳: 1651378810.0 时间戳-->结构化时间: time.struct_time(tm_year=2033, tm_mon=5, tm_mday=18, tm_hour=11, tm_min=33, tm_sec=20, tm_wday=2, tm_yday=138, tm_isdst=0) 结构化时间-->字符串: 2022-05-04 13:34:24
5.2、datetime模块 -->好处就是可以做时间运算
from datetime import datetime # 1、获取当前时间:datetime.now() now_time = datetime.now() print('当前时间:',now_time) # 2、获取当前格林威治时间 t_time = datetime.utcnow() print('格林威治时间:',t_time) # 3、datetime的另外一种便捷用法:单独获取年,月 日等 print('年:',now_time.year) print('月:',now_time.month) print('日:',now_time.day) # 4、创建一个指定的时间 dt = datetime(2022, 10, 1, 12, 20, 30) print('自定义设置日期格式:',dt)
执行结果:
当前时间: 2022-05-04 14:01:50.802844
格林威治时间: 2022-05-04 06:01:50.802892
年: 2022
月: 5
日: 4
自定义设置日期格式: 2022-10-01 12:20:3
|-- 字符串转datetime格式 ,用strptime
s1 = '2017/9/30' dt1 = datetime.strptime(s1,'%Y/%m/%d') print(dt1) #2017-09-30 00:00:00
|-- datetime格式转字符串,用strftime
dt2 = datetime(2019, 8, 11, 17, 8,0) ret2 = dt2.strftime('%Y年%m月%d日 %H点%M分') print(ret2) #2019年08月11日 17点08分
# 应用场景:用数据库里面取出来时间,然后转换成字符串进行操作
# 案例1:算当前月的1号对应的0点的时间戳时间
import time def get_stamp(): strt = time.strftime('%Y-%m-01 00:00:00') # print(strt) #2022-05-01 00:00:00 stru = time.strptime(strt,'%Y-%m-%d %H:%M:%S') stamp = time.mktime(stru) return stamp time_1=get_stamp() print(time_1)
#案例2:t2的时间 t1的时间 t2-t1经历了多少年 月 日 时 分 秒
''' 思路: 1、把t1,t2的时间转换成时间戳 2、两个时间戳相减,得到的也是一个时间戳 3、把相减的时间戳在转换成结构化时间 ''' t1 = '2017-7-11 11:11:11' t2 = '2019-9-03 08:43:07' def sub_time(t1,t2): stru_t1 = time.strptime(t1,'%Y-%m-%d %H:%M:%S') stamp_t1 = time.mktime(stru_t1) stru_t2 = time.strptime(t2, '%Y-%m-%d %H:%M:%S') stamp_t2 = time.mktime(stru_t2) #abs是求绝对值 -->原因:t1,t2并不清楚谁大谁小,所以求个绝对值 stamp_t2t1 = abs(stamp_t2-stamp_t1) stru_t2t1 = time.gmtime(stamp_t2t1) # stru_t2t1这个值是从1970年1月1号截止到现在的时间,所以需要减去1970 1 1号才能算出来t1,t2相差了多少 return (stru_t2t1.tm_year - 1970, stru_t2t1.tm_mon - 1, stru_t2t1.tm_mday - 1, stru_t2t1.tm_hour, stru_t2t1.tm_min, stru_t2t1.tm_sec) ret = sub_time(t1,t2) print(ret) #(2, 1, 22, 21, 31, 56)
六、sys模块
1、sys.modules
- sys.modules 描述的是当前执行代码位置,解释器中导入的所有模块都会被放到字典中
- 字典的key就是模块的名字,对应的value是这个模块对应的在内存中的位置
import time import sys ''' 因为sys.modules解释器中会把导入的所有模块都存到字典中,而字典的key就是模块的名字,value是模块的内存地址 所以直接可以通过sys.modules['time'] 这种字典的key来取value,然后调用对应的方法 比如:sys.modules['time'].time()== time.time() 他两就完全是一样的 ''' print(sys.modules['time'].time()== time.time()) #True
2、sys.path
- 能不能导入一个模块就要看这个模块所在的路径在不在sys.path中
- 如果在sys.path中寻找数据的时候,能够找到一个文件,那么就不继续往下走了
- pycharm会自动的把当前的项目路径添加到sys.path中来,在实际的生产环境中不应该出现这个值
3、sys.argv
- 在执行当前文件的时候传递一些参数到python代码中来
