

【Redis 事务&主从复制 03】
一、Redis的事务
1、是什么?
一次执行多个命令,本质是一组命令的集合。一个事务中的所有命令都会序列化,按顺序地串行化执行而不会被其他命令插入,不许加塞
2、目的
一个队列中,一次性,顺序行,排他性的执行一系列命令
3、如何操作
1)常用命令
discard 取消事务,放弃执行事务快内的所有命令
exec 执行所有事务块内的命令
multi 标记一个事务块的开始
unwatch 取消watch命令对所有key的监视
watch key[key...] 监视一个(或多个)key,如果在事务执行之前这个(或这些)key被其他命令所改动,那么事务将被打断
2)正常执行
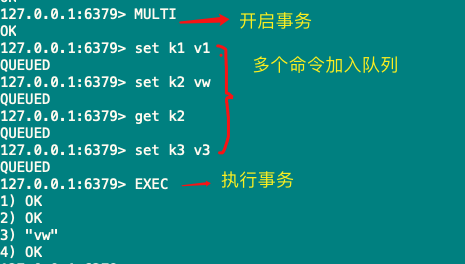
3)取消事务

4)只要有一个命令错误,其他命令执行失败
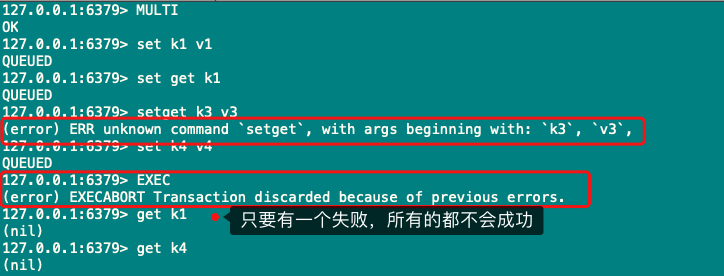
5)命令语法成功,逻辑错误,执行事务只会让错误的命令失败,其他命令成功

4)5)之间的区别
单独命令时报错,这样整个事务的执行都会失败
单独的每一条命令是正确的,执行事务的时候只会让存在问题的命令失败,其他命令仍然会成功
6)watch监控 针对多个用户对key的修改,watch用来监控key修改,unwatch取消key的监控
4、阶段
|-- 开启:以MULTI开始一个事务
|-- 入队:将多个命令入队到事务中,接到这些命令并不会立即执行,而是放到等待执行的事务队列里面
|-- 执行: 由exec命令触发事务
5、特性
|-- 单独的隔离操作:事务中所有命令都会序列化,按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断
|-- 没有隔离级别的概念:队列中的命令没有提交之前不会实际的被执行,因为事务提交前任何指令都不会被实际执行
|-- 不保证原子性:redis同一个事务中如果有一条命令执行失败,其后的命令仍然会被执行,没有回滚
二、Redis的发布订阅
进程间的一种消息通信模式:发送者pub发送消息,订阅者sub接受消息
三、Redis的主从复制,读写分离
1、是什么?
长说的主从复制,主机数据更新后根据配置和策略,自动同步到备机的master/slave机制,Master以写为主,Slave以读为主
2、能干什么?
读写分离
容灾恢复
3、如何操作
1)配从(库)不配主(库)
2)命令:从库配置:slaveof 主库IP 主库端口
|-- 每次与master断开后,都需要重新连接,除非你配置进redis.conf文件
|-- info replication 查看库信息(包含是master还是slave,主备状态等)
4、常用场景
场景1:一主二备
#案例
1> 拷贝多个redis.conf文件,分别为redis-6379.conf,redis-6380.conf,redis-6381.conf
2> 分别修改上面三个conf文件
daemonize yes port 6379 (6380 /6381) pidfile /var/run/redis6379.pid (redis6380.pid/redis6381.pid) logfile "redis6379.log" (redis6380.log/redis6381.log) dbfilename dump6379.rdb (dump6380.rdb/dump6381.rdb)
3> 分别启动三台redis
redis-server 127.0.0.1:6379 redis-cli -p 6379 redis-server 127.0.0.1:6380 redis-cli -p 6380 redis-server 127.0.0.1:6381 redis-cli -p 6381
4> 主机6379设置值,6380,6381设置备机,验证数据是否备份
//主机传值 127.0.0.1:6379> set k1 v1 OK 127.0.0.1:6379> set k2 v2 OK 127.0.0.1:6379> set k3 v3 OK //设置6380 6381为备机 127.0.0.1:6380> SLAVEOF 127.0.0.1 6379 OK 127.0.0.1:6380> keys * 1) "k1" 2) "k3" 3) "k2" 127.0.0.1:6381> SLAVEOF 127.0.0.1 6379 OK 127.0.0.1:6381> keys * 1) "k3" 2) "k1" 3) "k2" //用keys * 查看结果的值,数据已经备份完成
5> info replication 查看各个服务器状态
//6379主机信息 127.0.0.1:6379> info replication # Replication role:master //角色 master connected_slaves:2 //连接2个slave slave0:ip=127.0.0.1,port=6380,state=online,offset=13248,lag=1 slave1:ip=127.0.0.1,port=6381,state=online,offset=13248,lag=1 master_replid:668727d2394aa22a3b97b419ccc0f36c4a0b93e2 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:13248 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:13248 //6380备机信息 127.0.0.1:6380> info replication # Replication role:slave //角色 slave master_host:127.0.0.1 master_port:6379 master_link_status:up //连接状态 up master_last_io_seconds_ago:4 master_sync_in_progress:0 slave_repl_offset:13262 slave_priority:100 slave_read_only:1 connected_slaves:0 master_replid:668727d2394aa22a3b97b419ccc0f36c4a0b93e2 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:13262 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:12843 repl_backlog_histlen:420 //6381备机信息 127.0.0.1:6381> info replication # Replication role:slave master_host:127.0.0.1 master_port:6379 master_link_status:up master_last_io_seconds_ago:1 master_sync_in_progress:0 slave_repl_offset:13276 slave_priority:100 slave_read_only:1 connected_slaves:0 master_replid:668727d2394aa22a3b97b419ccc0f36c4a0b93e2 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:13276 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:12871 repl_backlog_histlen:406
6> 常见问题
|-- 主机挂掉备机数据是否丢失 -->不丢失,并且角色仍然是slave
127.0.0.1:6379> shutdown not connected> exit 127.0.0.1:6380> keys * 1) "k1" 2) "k3" 3) "k2" 127.0.0.1:6381> keys * 1) "k3" 2) "k1" 3) "k2"
|-- 主机重启,备机会自动连接主机并同步数据
|-- 备机挂掉,需要重新连接主机
SLAVEOF 127.0.0.1 6379
|-- 主机可读可写,从机只能读不能写
127.0.0.1:6379> set k9 v9 OK 127.0.0.1:6380> set k9 v99 (error) READONLY You can't write against a read only replica. 127.0.0.1:6381> set k9 v999 (error) READONLY You can't write against a read only replica. //从上面结果可以看出,从机只能读不能写
场景2:备机传递
上一个slave可以是下一个slave的master,slave同样可以接受其他slaves的连接和同步请求,那么该slave就被当做链条中下一个master,可以有效的减轻master的写压力
通俗一点讲,79是主机,80既可以作为81的主机又可以作为79的备机
特点:
中途变更转向:会清除之前的数据,重新建立拷贝最新的
设置方式:slaveof 新主库IP 新主库端口
#案例
1> 设置81的主机为80
127.0.0.1:6381> SLAVEOF 127.0.0.1 6380
2> 79新建数据,80,81仍然可以数据传递
127.0.0.1:6379> set k7 v7 OK 127.0.0.1:6380> get k7 "v7" 127.0.0.1:6381> get k7 "v7" //80,81仍然可以数据传递,获取79set的值,这叫薪火相传
3> info replication查看79,80,81的身份信息
//79 127.0.0.1:6379> info replication # Replication role:master connected_slaves:1 //只连接一个slave slave0:ip=127.0.0.1,port=6380,state=online,offset=2725,lag=1 //并且是80 master_replid:9a5a6b8f556368a0683a2c26247af61b9f98f333 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:2725 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:2725 //80 # Replication role:slave //角色仍然是slave master_host:127.0.0.1 master_port:6379 //80的master是79 master_link_status:up master_last_io_seconds_ago:9 master_sync_in_progress:0 slave_repl_offset:2725 slave_priority:100 slave_read_only:1 //80虽然是81的主机,但是仍然只有读的权限,没有写的权限 connected_slaves:1 //80也有一个连接他的slave 并且是81 slave0:ip=127.0.0.1,port=6381,state=online,offset=2725,lag=0 master_replid:9a5a6b8f556368a0683a2c26247af61b9f98f333 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:2725 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:895 repl_backlog_histlen:1831 //81 127.0.0.1:6381> info replication # Replication role:slave //角色slave master_host:127.0.0.1 master_port:6380 //master是80
场景3:反客为主(备机升级主机)
主机挂掉,使当前数据库停止与其他数据库的同步,转成主数据库
#案例
1> 79主机,80,81都是79的slave
2> 79挂掉,设置80位主机,81位为80的备机
127.0.0.1:6380> SLAVEOF no one //设置80为主机 OK 127.0.0.1:6380> set k8 v8 OK 127.0.0.1:6381> SLAVEOF 127.0.0.1 6380 //设置81为备机 OK 127.0.0.1:6381> get k8 "v8"
5、复制原理
1)slave启动成功连接到master后会发送一个sync命令
2)master接到命令后启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令,在后台进程执行完毕之后,master将传送整个数据文件到slave,以完成一次完全同步
3)全量复制:而slave服务在接收到数据库文件数据后,将其存盘并加载到内存中
4)增量复制:Master继续将新的所有收集到的修改命令依次传给slave,完成同步
5)但是只要是重新连接master,一次完全同步(全量复制)将被自动执行
6、哨兵模式
反客为主的自动版,能够后台监控主机是否故障,如果故障了根据投票数自动将从库转换为主库
步骤
1)79为主,80,81是79的两个备
2)自定义的/back_redis_conf目录下新建sentinel.conf文件,名字绝不能错
3)配置sentinel.conf,内容为: sentinel monitor 被监控数据库名字(自己起名字) 127.0.0.1 6379 1 上面最后一个数字1,表示主机挂掉后salve投票看让谁接替成为主机,得票数多少后成为主机
[root@bogon bak_redis_conf]# touch sentinel.conf
[root@bogon bak_redis_conf]# vim sentinel.conf
sentinel monitor host6379 127.0.0.1 6379 1
4)启动哨兵
redis-sentinel /opt/bak_redis_conf/sentinel.conf

5)79挂掉,80,81会被投票新选master,谁的票多谁就是master

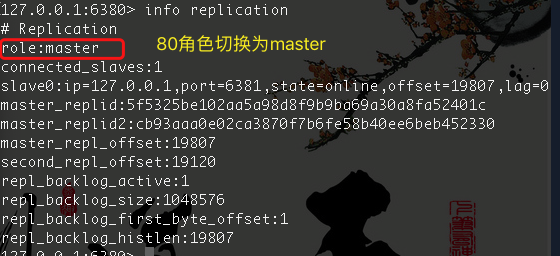
6)验证80 数据是否传到81
127.0.0.1:6380> set k8 v8 OK 127.0.0.1:6381> get k8 "v8"
7)79重新启动,会被哨兵检测到重新设置成80的备机
127.0.0.1:6379> get k8 "v8" 127.0.0.1:6379> info replication # Replication role:slave master_host:127.0.0.1 master_port:6380 master_link_status:up master_last_io_seconds_ago:1 master_sync_in_progress:0 slave_repl_offset:49336 slave_priority:100 slave_read_only:1 connected_slaves:0 master_replid:5f5325be102aa5a98d8f9b9ba69a30a8fa52401c master_replid2:0000000000000000000000000000000000000000 master_repl_offset:49336 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:48502 repl_backlog_histlen:835
原理:原先的主机挂掉以后,sentinel会检测到并根据投票选出新的master,原先的主机重新启动以后,也会被设置成新主机的备机
一组sentinel能同时监控多个master
7、复制的缺点:
由于所有的写操作都是先在Master上操作,然后同步更新到Slave上,所以从Master同步到Slave机器有一定的延迟,当系统很繁忙的时候,延迟问题会更加严重,Slave机器数量的增加也会使这个问题更加严重。
