

【Redis 配置文件&持久化 02】
一、解析redis.conf配置文件
1、Units单位 (redis.conf文件的第一部分内容)

--> 配置大小单位,开头定义了一些基本的度量单位,只支持bytes,不支持bit
--> 对大小写不敏感
2、GENERAL
--> daemonize yes 设置后台启动,默认情况下是no,设置成yes为后台启动
--> pidfile /var/run/redis_6379.pid 进程管道pid文件(没有指定文件时,运行起来以后会保存在/var/run/redis_6379.pid 内)
-->tcp-backlog 511
tcp-backlog 设置tcp的backlog,backlog其实是一个连接队列,backlog队列总和=未完成三次握手队列 + 已经完成三次握手队列。 在高并发环境下你需要一个高backlog值来避免慢客户端连接问题。注意Linux内核会将这个值减小到/proc/sys/net/core/somaxconn的值,所以需要确认增大somaxconn和tcp_max_syn_backlog两个值 来达到想要的效果
--> bind 端口的绑定(目前是自己连自己所以为bind 127.0.0.1,如果链接其他机器,直接bind 127.0.0.1 192.168.1.111)
--> timeout 0 ( 客户端空闲N秒后关闭连接(0为禁用,即:不关闭,一直连着))
--> tcp-keepalive 300 (单位为秒,如果设置为0,则不会进行Keepalive检测,建议设置成300 )
多台redis集群模式,多台redis之间保持链接的时间
--> loglevel notice 日志级别
#指定服务器的详细级别。 包含下面几个级别: # debug(大量信息,对开发/测试很有用) # verbose(许多很少有用的信息,但不像调试级别那样一团糟) # notice(稍微啰嗦一点,你可能想在生产中得到什么) # warning(只记录非常重要/关键的消息)
-->logfile 日志名称
# Specify the log file name. Also the empty string can be used to force # Redis to log on the standard output. Note that if you use standard # output for logging but daemonize, logs will be sent to /dev/null #指定日志文件名。空字符串也可以用来强制 # Redis登录到标准输出。请注意,如果您使用标准 #输出日志,但被后台化后,日志将被发送到/dev/null
--> syslog-enabled no 是否把日志输出到syslog中,默认no不输出
--> syslog-ident redis 指定syslog里的日志标志,即:日志名称为redis开头
--> syslog-facility local0 指定syslog设备,值可以是USER或LOCAL0-LOCAL7 默认为0
3、SNAPSHOTTING快照
-->Save 秒钟,写操作次数
RDB是整个内存的压缩过的Snapshot,RDB的数据结构,可以配置复合的快照触发条件, 默认 save 900 1 或15分钟内改了1次。 save 300 10 或5分钟内改了10次, save 60 10000 或是1分钟内改了1万次,
如果想禁用RDB持久化的策略,只要不设置任何save指令,或者给save传入一个空字符串参数也可以
-->stop-writes-on-bgsave-error yes
默认是yes,如果配置成no,表示你不在乎数据不一致或者有其他的手段发现和控制
-->rdbcompression yes
默认为yes,rdbcompression:对于存储到磁盘中的快照,可以设置是否进行压缩存储。如果是的话,redis会采用LZF算法进行压缩。如果你不想消耗CPU来进行压缩的话,可以设置为关闭此功能
-->rdbchecksum yes
默认为yes,rdbchecksum:在存储快照后,还可以让redis使用CRC64算法来进行数据校验,但是这样做会增加大约
10%的性能消耗,如果希望获取到最大的性能提升,可以关闭此功能
--> dbfilename dump.rdb 快照默认名称为dump.rdb
--> dir 目录
4、REPLICATION复制
5、SECURITY安全
//查看redis的密码 127.0.0.1:6379> config get requirepass 1) "requirepass" //默认密码 2) "" //设置密码 127.0.0.1:6379> config set requirepass "12345" //设置以后需要输入密码才可访问 127.0.0.1:6379> auth 12345 OK //访问验证 127.0.0.1:6379> ping pong
6、LIMITS
--> maxclients 10000
设置redis同时可以与多少个客户端进行连接。默认情况下为10000个客户端。当你
无法设置进程文件句柄限制时,redis会设置为当前的文件句柄限制值减去32,因为redis会为自
身内部处理逻辑留一些句柄出来。如果达到了此限制,redis则会拒绝新的连接请求,并且向这
些连接请求方发出“max number of clients reached”以作回应。
-->maxmemory <bytes>
设置redis可以使用的内存量。一旦到达内存使用上限,redis将会试图移除内部数据,移除规则可以
通过maxmemory-policy来指定。如果redis无法根据移除规则来移除内存中的数据,或者设置了“不允许移除”, 那么redis则会针对那些需要申请内存的指令返回错误信息,比如SET、LPUSH等。 但是对于无内存申请的指令,仍然会正常响应,比如GET等。如果你的redis是主redis(说明你的redis有从redis),
那么在设置内存使用上限时,需要在系统中留出一些内存空间给同步队列缓存,只有在你设置的是“不移除”的情况下,才不用考虑这个因素
-->maxmemory-policy 默认为noeviction(真实线上环境一般会调整清除策略,而不是默认的noeviction)
缓存过期清除策略
(1)volatile-lru:使用LRU算法移除key,只对设置了过期时间的键 (2)allkeys-lru:使用LRU算法移除key (3)volatile-random:在过期集合中移除随机的key,只对设置了过期时间的键 (4)allkeys-random:移除随机的key (5)volatile-ttl:移除那些TTL值最小的key,即那些最近要过期的key (6)noeviction:不进行移除。针对写操作,只是返回错误信息
-->maxmemory-samples 默认是5
设置样本数量,LRU算法和最小TTL算法都并非是精确的算法,而是估算值,所以你可以设置样本的大小,
redis默认会检查这么多个key并选择其中LRU的那个
7、APPEND ONLY MODE追加

常见配置redis.conf介绍
参数说明 redis.conf 配置项说明如下: 1. Redis默认不是以守护进程的方式运行,可以通过该配置项修改,使用yes启用守护进程 daemonize no 2. 当Redis以守护进程方式运行时,Redis默认会把pid写入/var/run/redis.pid文件,可以通过pidfile指定 pidfile /var/run/redis.pid 3. 指定Redis监听端口,默认端口为6379,作者在自己的一篇博文中解释了为什么选用6379作为默认端口,因为6379在手机按键上MERZ对应的号码,而MERZ取自意大利歌女Alessia Merz的名字 port 6379 4. 绑定的主机地址 bind 127.0.0.1 5.当 客户端闲置多长时间后关闭连接,如果指定为0,表示关闭该功能 timeout 300 6. 指定日志记录级别,Redis总共支持四个级别:debug、verbose、notice、warning,默认为verbose loglevel verbose 7. 日志记录方式,默认为标准输出,如果配置Redis为守护进程方式运行,而这里又配置为日志记录方式为标准输出,则日志将会发送给/dev/null logfile stdout 8. 设置数据库的数量,默认数据库为0,可以使用SELECT <dbid>命令在连接上指定数据库id databases 16 9. 指定在多长时间内,有多少次更新操作,就将数据同步到数据文件,可以多个条件配合 save <seconds> <changes> Redis默认配置文件中提供了三个条件: save 900 1 save 300 10 save 60 10000 分别表示900秒(15分钟)内有1个更改,300秒(5分钟)内有10个更改以及60秒内有10000个更改。 10. 指定存储至本地数据库时是否压缩数据,默认为yes,Redis采用LZF压缩,如果为了节省CPU时间,可以关闭该选项,但会导致数据库文件变的巨大 rdbcompression yes 11. 指定本地数据库文件名,默认值为dump.rdb dbfilename dump.rdb 12. 指定本地数据库存放目录 dir ./ 13. 设置当本机为slav服务时,设置master服务的IP地址及端口,在Redis启动时,它会自动从master进行数据同步 slaveof <masterip> <masterport> 14. 当master服务设置了密码保护时,slav服务连接master的密码 masterauth <master-password> 15. 设置Redis连接密码,如果配置了连接密码,客户端在连接Redis时需要通过AUTH <password>命令提供密码,默认关闭 requirepass foobared 16. 设置同一时间最大客户端连接数,默认无限制,Redis可以同时打开的客户端连接数为Redis进程可以打开的最大文件描述符数,如果设置 maxclients 0,表示不作限制。当客户端连接数到达限制时,Redis会关闭新的连接并向客户端返回max number of clients reached错误信息 maxclients 128 17. 指定Redis最大内存限制,Redis在启动时会把数据加载到内存中,达到最大内存后,Redis会先尝试清除已到期或即将到期的Key,当此方法处理 后,仍然到达最大内存设置,将无法再进行写入操作,但仍然可以进行读取操作。Redis新的vm机制,会把Key存放内存,Value会存放在swap区 maxmemory <bytes> 18. 指定是否在每次更新操作后进行日志记录,Redis在默认情况下是异步的把数据写入磁盘,如果不开启,可能会在断电时导致一段时间内的数据丢失。因为 redis本身同步数据文件是按上面save条件来同步的,所以有的数据会在一段时间内只存在于内存中。默认为no appendonly no 19. 指定更新日志文件名,默认为appendonly.aof appendfilename appendonly.aof 20. 指定更新日志条件,共有3个可选值: no:表示等操作系统进行数据缓存同步到磁盘(快) always:表示每次更新操作后手动调用fsync()将数据写到磁盘(慢,安全) everysec:表示每秒同步一次(折衷,默认值) appendfsync everysec 21. 指定是否启用虚拟内存机制,默认值为no,简单的介绍一下,VM机制将数据分页存放,由Redis将访问量较少的页即冷数据swap到磁盘上,访问多的页面由磁盘自动换出到内存中(在后面的文章我会仔细分析Redis的VM机制) vm-enabled no 22. 虚拟内存文件路径,默认值为/tmp/redis.swap,不可多个Redis实例共享 vm-swap-file /tmp/redis.swap 23. 将所有大于vm-max-memory的数据存入虚拟内存,无论vm-max-memory设置多小,所有索引数据都是内存存储的(Redis的索引数据 就是keys),也就是说,当vm-max-memory设置为0的时候,其实是所有value都存在于磁盘。默认值为0 vm-max-memory 0 24. Redis swap文件分成了很多的page,一个对象可以保存在多个page上面,但一个page上不能被多个对象共享,vm-page-size是要根据存储的 数据大小来设定的,作者建议如果存储很多小对象,page大小最好设置为32或者64bytes;如果存储很大大对象,则可以使用更大的page,如果不 确定,就使用默认值 vm-page-size 32 25. 设置swap文件中的page数量,由于页表(一种表示页面空闲或使用的bitmap)是在放在内存中的,,在磁盘上每8个pages将消耗1byte的内存。 vm-pages 134217728 26. 设置访问swap文件的线程数,最好不要超过机器的核数,如果设置为0,那么所有对swap文件的操作都是串行的,可能会造成比较长时间的延迟。默认值为4 vm-max-threads 4 27. 设置在向客户端应答时,是否把较小的包合并为一个包发送,默认为开启 glueoutputbuf yes 28. 指定在超过一定的数量或者最大的元素超过某一临界值时,采用一种特殊的哈希算法 hash-max-zipmap-entries 64 hash-max-zipmap-value 512 29. 指定是否激活重置哈希,默认为开启(后面在介绍Redis的哈希算法时具体介绍) activerehashing yes 30. 指定包含其它的配置文件,可以在同一主机上多个Redis实例之间使用同一份配置文件,而同时各个实例又拥有自己的特定配置文件 include /path/to/local.conf
二、持久化之RDB
RDB(redis database)
1、是什么?
在指定的时间间隔内将内存中的数据集快照写入磁盘,也就是行话讲 的Snapshot快照,它回复时将快照文件直接读到内存里、
Redis会单独创建(fork)一个子进程来进行持久化,会先将数据写入到一个临时文件中,待持久化过程结束了,在用这个临时文件替换上次持久化好的文件。
整个过程中,主进程是不进行任何IO操作的,这就确保了极高的性能,如果需要进行大规模数据的恢复,且对于数据回复的完整性不是非常敏感,那RDB方式要比
AOP方式更加的高效,RDB的缺点是最后一次持久化后的数据可能丢失。
2、Fork
fork的作用就是赋值一个与当前进程一样的进程。新进程的所有数据(变量、环境变量、程序计数器等)数值都和原进程一直,但是是一个全新的进程,并作为原进程的子进程
3、rdb保存的是dump.rdb文件
4、配置位置-->上一步的SNAPSHOTTING快照
5、如何触发RDB快照+如何恢复
举例说明:
1)vim redis.conf文件,可以看到SNAPSHOTTING标签下save保存策略
默认情况为:
save 900 1
save 300 10
save 60 10000
为了测试方便,修改为save 120 10 -->120分钟修改10次保存快照
2)启动redis服务并登录,然后在2分钟内修改10次文件
redis-server /opt/bak_redis_conf/redis.conf redis-cli -p 6379 //2分钟内修改10次 set k1 v1 set k2 v2 ... set k10 v10
3)等待2分钟,查看/usr/local/bin路径下保存的dump.rdb快照文件

此时快照生成的时间是15:14
4)备份此dump.rdb文件,实际工作中会备份到其他的服务器上

5)人为破坏数据,已验证数据恢复策略

6)恢复数据(将备份文件dump.rdb移动到redis安装目录并启动服务即可,config get dir获取目录)
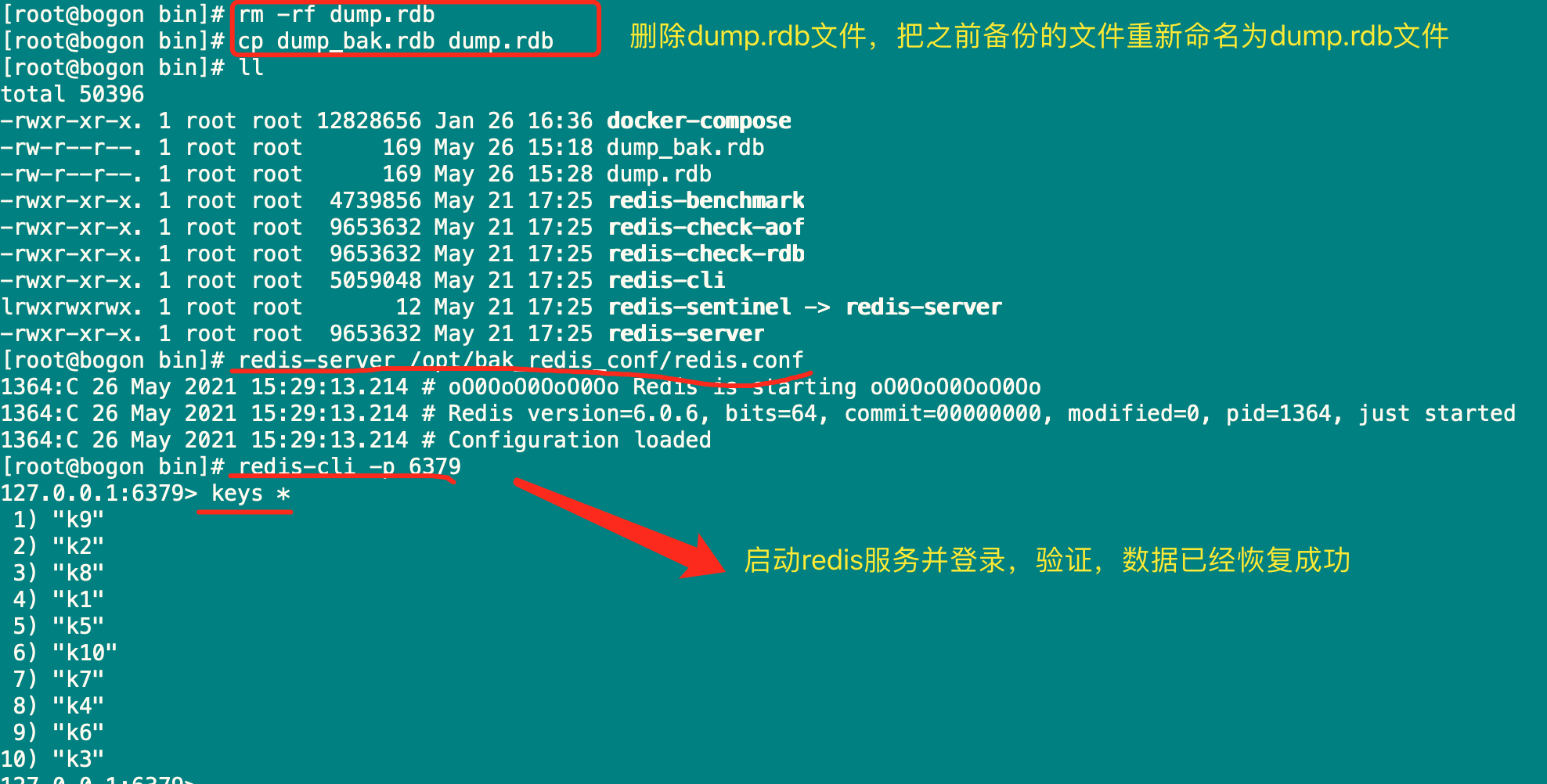
注意:重点是save保存机制,以及恢复时识别dump.rdb
如果是有特别紧急的情况,需要立马保存快照,可以直接输入save命令保存快照
Save:save时只管保存,其它不管,全部阻塞
bgsave:Redis会在后台异步进行快照操作,快照同时还可以响应客户端请求。可以通过lastsave,命令获取最后一次成功执行快照的时间
6、优势&劣势
优势:适合大规模的数据恢复,对数据完整性和一致性要去不高
劣势:在一定间隔时间做一次备份,所以如果reids意外down掉的话,就会丢失最后一次快照的所有修改;fork的时候,内存中的数据被克隆一份,大致2被的彭总需要考虑
7、如何停止:
动态所有停止RDB保存规则的方法:redis-cli config set save ""
小总结:

三、持久化之AOF
AOF(append only file)
1、是什么
以日志的形式来记录每个写操作,将redis执行过的所有写指令记录下来(读操作不记录),只许追加文件但不可以改写文件,redis启动之初会读取该文件重新构建数据,换言之,redis重启的话就根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作
2、Aof保存的是appendonly.aof文件
3、配置位置-->上一步的APPEND ONLY MODE
4、如何触发+恢复
举例验证
1)vim redis.conf文件,可以看到APPEND ONLY MODE标签,下的appendonly no
修改no为yes,开启服务
2)启动redis服务,登录redis并传值
redis-server /opt/bak_redis_conf/redis_aof.conf redis-cli -p 6379 127.0.0.1:6379> set k1 v1 OK 127.0.0.1:6379> set k2 v2 OK 127.0.0.1:6379> set k3 v3 OK 127.0.0.1:6379> FLUSHALL OK 127.0.0.1:6379> shutdown not connected> exit
备份:appendonly.aof文件会把所有操作的内容都记录下来,并且生成在/usr/local/bin目录下
3)正常恢复 -->重启redis然后会自动重新加载数据
异常恢复:如果aof文件被损坏,需要用redis-check-aof --fix进行修复,然后重启redis进行重新加载
|-- 人为的修改一下appendonly.aof文件,在文件最后加上几列数字或字母


重启后发现不能正常进入redis,并且查看/usr/local/bin下既有aof文件又有rdb文件,同样可以从没有成功登陆redis说明redis持久化首先找aof文件,然后才会去找rdb文件
|-- 修复aof文件
[root@bogon bin]# redis-check-aof --fix appendonly.aof 0x 76: Expected \r\n, got: 6a6b AOF analyzed: size=180, ok_up_to=110, diff=70 This will shrink the AOF from 180 bytes, with 70 bytes, to 110 bytes Continue? [y/N]: y Successfully truncated AOF
4) 重启redis验证数据是否恢复
5、rewire
1)AOF采用文件追加方式,文件会越来越大为避免出现此种情况,新增加了重写机制,当AOF文件的大小超过所设定的阈值时redis就会启动AOF文件的内容压缩,只保留可以回复数据的最小指令集,可以使用命令bgrewriteaof
2)重写原理:AOF文件持续写入而过大时,会fork出一条新进程来将文件重写(也是先写临时文件最后在rename),遍历新进程的内存中数据,每条记录有一条set语句。重写aof文件的操作,并没有读取旧的aofa文件,而是将整个内存中的数据库内容用命令的方式重写一个新的aof文件,这点和快照有点类似
3)触发重写的机制:redis会记录上次重写时AOF大小,默认配置当AOF文件大小是上次rewrite后大小的一倍且文件大于64M时触发
6、优势
appendfsync always 同步持久化 每次发生数据变更会被立即记录到磁盘 性能较差但数据完整性比较好
appendfsync everysec 异步操作,每秒记录 如果一秒内宕机,有数据丢失
appendfsync no 从不同步
7、劣势
相同数据集的数据而言aof文件要远大于rdb文件,恢复速度慢于rdb
aof运行效率要慢于rdb,每秒同步策略效率较好,不同步效率和rdb相同
四、如何选择RDB还是AOF
1、RDB持久化方式能够在指定的时间间隔对数据进行快照存储
2、AOF持久化方式记录每次对服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据,AOF命令以redis协议追加保存每次写的操作到文件末尾。
redis还能对AOF文件进行后台重写,使的AOF文件的体积不至于过大
3、只做缓存:如果你只希望你的数据在服务器运行的时候存在,也没必要使用任何的持久化
4、同时开启两种持久化方式
|-- 在这种情况下,当redis重启的时候会优先载入AOF文件来恢复原始的数据,因为在通常情况下AOF文件保存的数据集要比RDB文件保存的数据集要完整.
|-- RDB的数据不实时,同时使用两者时服务器重启也只会找AOF文件。那要不要只使用AOF呢?建议不要,因为RDB更适合用于备份数据库(AOF在不断变化不好备份),
快速重启,而且不会有AOF可能潜在的bug,留着作为一个万一的手段。
5、性能建议
因为RDB文件只用作后备用途,建议只在Slave上持久化RDB文件,而且只要15分钟备份一次就够了,只保留save 900 1这条规则。 如果Enalbe AOF,好处是在最恶劣情况下也只会丢失不超过两秒数据,启动脚本较简单只load自己的AOF文件就可以了。代价一是带来了持续的IO,二是AOF rewrite的最后将rewrite过程中产生的新数据写到新文件造成的阻塞几乎是不可避免的。只要硬盘许可,应该尽量减少AOF rewrite的频率,AOF重写的基础大小默认值64M太小了,可以设到5G以上。默认超过原大小100%大小时重写可以改到适当的数值。 如果不Enable AOF ,仅靠Master-Slave Replication 实现高可用性也可以。能省掉一大笔IO也减少了rewrite时带来的系统波动。代价是如果Master/Slave同时倒掉,会丢失十几分钟的数据,启动脚本也要比较两个Master/Slave中的RDB文件,载入较新的那个。新浪微博就选用了这种架构
