【算法】背包问题初探
【01背包问题】
背包问题是一类问题。通常其模型就是往一个背包里面装各种物品,来求一个极限情况时的物品明细或者某些物品属性。把这些描述给具体化可以得到很多不同分化的背包问题。
01背包问题是背包问题中基础的一类。其描述是:
有n个物品分别编号为a1,a2,a3...an。这些物品每个都有两个属性,分别是重量和价值,物品ai对应的重量和价值分别用wi和vi表示。然后我们手里还有一个背包,这个背包有一个容量属性volumn,意思是这个背包能够装下的最重的重量是volumn。
我们要求解的是,在背包不被撑爆的情况下,如何安排物品的放入才能使背包中物品价值vi的总和最大化。
这个问题中的几个细节还需要强调一下:
1. 物品是个不是类,也就是说a1,a2...都只有一个,针对一个物品放入背包的操作只能做一次。对于“类”的背包问题,称为完全背包问题,下面有机会细说
2. 物品无法分割,比如放入背包 二分之一个a1这样的操作是不允许的。要么物品放入,要么不放入。这也是01背包问题中01这个前缀的由来。事实上,对于这种可分割的物品(比如把物品换算成多少钱一斤的糖果,这样感觉上就是一种可分割的背包问题),可以使用贪心算法来解决,还略微简单一些。由于是说明01,所以不展开了。
3. 题目中没有要求恰好装满背包,也就是说允许背包中有空。如果要求恰好装满背包,则可以稍稍修改01背包问题的算法实现。
■ 动态规划求解
很明显,当选取一些物品放入背包之后,剩下物品中还能放入哪些物品受到之前放入物品决策的影响。因此可以通过动态规划的思想来解决。
(尝试了一下能否通过自己的语言来讲一下这个算法从无到有的来龙去脉,不过发现还是搞不太清… 目前先把现成的做法拿过来,等以后有机会再来解释解释原理)
我们构造这样一个二维数组作为动态规划的中间值存储。这个数组的元素res[i][j],指的是从a1到ai这(i-1)个物品中选出若干个物品放入最大承重量为 j 的背包,此时能够取到的物品总价值的最大值。(我不是很能理解为什么 j 是最大承重量为 j 的背包。事实上,我们手中并不存在一个最大承重量是j的背包,这个背包是虚拟的) 显然,所有的res[0][j]代表了0件物品放入承重为j的背包,此时最大价值肯定是0,因为没有物品。相对的,res[i][0]代表了i件物品放入承重为0的背包,由于背包完全不承重,自然一个物品都不能放,所以其总价值也是0。其实到这里已经可以看出来,res这个二维数组的第一行和第一列的所有元素都是0。而我们比较关注的部分的i的取值是1到n,j的取值是1到volumn。
到这里,其实感觉这个二维数组非常像求最长子序列时需要构造的那个东西,也是第一行第一列置0。有了这样一个构造之后,后续数据的填充就不困难了。
对于二维数组中的一个元素res[i][j],其实可以看到,分成是否将ai放入背包两种情况。
1. 如果不将ai放入背包,那么很明显,res[i][j]应该等于res[i-1][j]
2. 如果将ai放入背包,则res[i][j] == res[i-1][j-wi]。这个判断最开始我也想不太明白,主要问题是我们没有在做完全背包问题,总感觉j-wi不精确等于i-1个物品时,取物品的总质量,这样的推断不太可靠。但是后来想了想,加入j-wi和i-1个物品时,取物品的总质量之间有一些“空隙”的话,那么这些空隙必然是不能容纳a(i-1)之前其他未进入背包的物品的,否则物品的总价值还可以继续变大。因此j-wi再加上wi之后,这个空隙还是存在,并且依然不能容纳更多的物品。因此这个等式没毛病。
除了这两种情况之外,其实我们还应该注意到,如果j < wi,那么j-wi变成了负数,显然不是我们期望的。事实上,j < wi的意思是说ai的重量已经超过了当前背包最大承重量,此时ai肯定不能加入背包。因此当j < wi的时候不用考虑第二种情况,直接走第一种情况。(事实上在Python中不这么处理可能不会报错,因为负下标是指从倒数开始计数的,但是这样的话数据肯定不正确了)
填充数据时从1,1位置开始,一直走到最右下角。填充完毕之后,数组中的每个元素都是相应i(对a1,a2...ai这些物品而言)和j(对背包总承重量为j的时候而言)时,可以取到的背包中物品价值最大值的情况。
显然,如果只是求V的最大值的话,直接取最右下角元素的值即可。
如果我们想要求出此时背包中物品的明细,参照以前做最长公共子序列的做法,从右下角元素回溯上去,找出一条路径即可。这次我们关心的,是每一行(即每个i)的物品是否取。
具体而言,可以做一个由n个0构成的数组,对于要取的物品ai,将对应下标是i的元素置为1即可。而判断当前行的那个物品要不要取,就看当前所在数组元素的值的来源即可。如果这个值和同一列上一行的值(即[i-1][j])相同,说明这个物品并没有取。否则就认为取了,然后将当前的j减去这个物品的重量,i再减去1,得到的新的res[i][j]就是没有加入这个物品前背包的状态,以此类推直到走到
综上所述,代码如下:(下面这个代码是附加结构代替递归模式的DP,如果要改造成递归也不困难,就是搞一个填充(i,j)位置的函数,然后按照代码中的逻辑填充数据即可。无非是调用入口的i,j是右下角的i,j)


# -*- coding:utf-8 -*- def knapsack(_weight,_value,_volumn): ''' :param _weight: 物品重量参数列表 :param _value: 物品价值参数列表 :param _volumn: 背包容量 ''' weight = list(_weight) weight.insert(0,0) # 在头上加一个0,方便构造那个二维数组 value = list(_value) value.insert(0,0) volumn = _volumn + 1 # 列数也加1,方便构造二维数组 n = len(weight) res = [[0 for i in range(volumn)] for j in range(n)] for i in range(1,n): for j in range(1,volumn): # 从1,1位置开始填充数据 if j < weight[i]: res[i][j] = res[i-1][j] else: res[i][j] = max(res[i-1][j], res[i-1][j-weight[i]]+value[i]) # j-weight[i],加入i,j的情况下总重量不到j,留出的空档不足以让一个新元素放进来 # 那么减去weight[i]之后留下的空档依然是不够任何一个元素放进来的 # 打印一下整个二维数组看下情况 for row in res: for item in row: print item,'\t', print '' hot = [0] * (n-1) # n是算上了第一个元素0的长度,结果列表里不必包含这个0因此减1 i,j = n-1,volumn-1 while i > 0 and j > 0: if res[i-1][j] == res[i][j]: i -= 1 else: hot[i-1] = 1 # 别忘了这里也要减1 i -= 1 j -= weight[i] print hot if __name__ == '__main__': weight = [2,2,6,5,4] value = [6,3,5,4,6] volumn = 10 knapsack(weight,value,volumn)
上面的测试数据中途生成的整个二维数组应该是这样的:
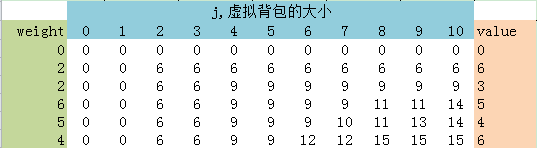
比如看res[2][3]这一格,意思是a1,a2作为可取物品,背包总承重量是3的情况能够取的最大价值。因为a1,a2的重量都是2,所以两者只能取其一放入背包,而a1的价值是6,a2的价值是3,自然取a1入背包比较好。
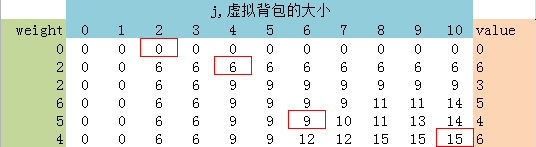
至于回溯路径,从res[5][10]开始回溯的话,标红的几个格子就是几个关键节点,表示V达到格子中的值时是通过了取了第i个物品所致的。
■ 优化
上述算法,如果说物品数量是M件,而背包大小是N的话,那么总体的 时间复杂度是O(M*N)(刚好两层循环)。而空间复杂度很好判断,就是多用了这么一个二维数组结构,是O(M*N)。
和很多DP问题类似,在时间复杂度上,优化的空间不大,但是在空间复杂度上,如果不考虑放入物品的明细,只是求出最大价值的话,可以将二维数组优化为一个一维数组求解。
原理很简单,就是把一维数组视作上面二维数组里面的每一行,然后一遍遍地遍历修改更新数组中的值,使之成为下一行,直到最后一行。
在这个过程中,如何遍历更新数组中的值非常重要。一般我们想到简单的从左到右依次遍历,但是这个动态规划的状态转移方程中,设我们的一维数组是vtable,那么要求是vtable[k] = max(vtable[k], vtable[k-weight] + value),也就是说绝对vtable[k]的值的因素,还有一个vtable[k-weight]这样一个处于vtable左边的值。因此依次遍历如果是从左到右,可能在决定vtable[k]的时候其左端的值被改变从而无法求出正确的值。一般来说,实践上会把遍历的顺序调整为从右到左。整个核心遍历过程的伪代码如下:
for i in 1..M,M是物品个数
for j in N..0,N是背包大小
vtable[j] = max(vtable[j], vtable[j-weight]+value), weight,value是当前i对应物品的属性
可以看到,里层循环的循环顺序是从N到0,倒过来的。基于这个伪代码我们可以很快写出Python的相关代码,并且做一些逻辑的补充和优化:
def knapsack(weights,values,pack): num = len(weights) vtable = [0] * (pack+1) # vtable = [0] + ([float('-inf')] * pack) # 2 for i in range(num): weight = weights[i] value = values[i] for j in range(pack,weight-1,-1): # if j - weight < 0: # 1 # continue vtable[j] = max(vtable[j],vtable[j-weight]+value) return vtable print knapsack([2,2,6,5,4],[6,3,5,4,6],10)
这里可以注意一下,vtable初始化的长度应该是背包最大承重 + 1,因为要在逻辑上考虑背包承重为0的情况。而外层循环的i可以直接从0开始,因为上面二维数组中i是0的情况的那一行已经在vtable的初始化中给出了,即都是0的那行数组。
这段代码的输出是[0, 0, 6, 6, 9, 9, 12, 12, 15, 15, 15],恰好也应该是之前二维数组的最后一行的值。
然后看注释#1处,按照上面给出的伪代码,里层循环应该是for j in range(pack, -1, -1),然后为了避免j - weight是负数的情况,在循环中加上一条continue条件。由于这个循环十分简单,可以直接将j - weight < 0的条件加载循环控制条件中。即range(pack ,weight - 1, -1)。
再看注释#2处。这个地方初始化采用了只有第一项(即j = 0,背包最大承重为0的时候)为0,其余项都初始化为负无穷的策略。这个策略是用来解决“恰好装满”的01背包问题的。方法是这么个方法,但是为什么是这样呢? 经典背包九讲中的解释是,可以理解为,不要求“恰好装满”时,只要背包内物品不超过最大承重量,背包的状态都是合法的,有机会将这种状态记录到结果集中。初始状态下不管j是多大,由于放入的物品是0,即不放入任何物品,总价值自然也是0,所以都初始化为0。 另一方面,如果要求“恰好装满”,除了j=0的状态是合法的外,其余任何大于0的j,放入物品为0时都不属于“装满”状态,因此都不能作为合法状态,一次你初始化为负无穷。
以负无穷表示非法状态的好处是,-inf不管加上的value是多少仍然是-inf。也就是说,非法的状态(比如背包有空隙时),无论再加入多少个什么物品(加入物品的同时j也变大,所以之前的空隙不会被填满)都还是非法的。反过来,合法的状态再加入任何物品,只要不超过实际的背包承重量pack,也都是合法的。
只需要在初始化的时候进行这么一个简单的改造,就可以使得不要求“恰好装满”的变成了要求“恰好装满”的。另外需要指出,这个“恰好装满”的控制条件普适于几乎所有的背包问题。
利用一维数组解01背包问题,不仅仅是空间复杂度降低这个意义而已,很多扩展的背包问题的算法都要基于一维01背包算法,因此应该好好记住。
重申下几个重点。
1. 里层循环的逆序遍历 2. 里层循环循环控制条件优化 3. 数组初始化长度应+1 4. 数组初始化值的不同对应是否恰好装满问题
【完全背包问题】
上面也说过了,完全背包问题中,可选的物品不再是一件件,而是一类类的了。也就是说,每种物品都可以取用无数次放入背包。
■ 预处理
在完全背包的场景中,有一些之前01背包问题中不是很明朗的东西变得很清晰。比如对于物品,我们可以做一个预处理了。预处理包括了两方面:
1. 如果一种物品am和另一种an,满足weights[m] <= weights[n] and value[m] >= value[n],那么我们就可以非常自信地说,an物品可以扔掉了。因为任何一个带有an的分配情况中,把所有的an都换成am,总可以使得重量不超标的情况下总价值增加(准确的说是不减少)。
2. weight[k] > pack的那些ak物品也可以直接扔掉了,因为背包根本装不下这些物品哪怕只有 一件,这个其实在01背包中也是成立的。
对于第二点,实现起来很方便,只要遍历的时候加个条件即可。
对于第一条就要稍微思考一下了。我自己的解决思路是现将weights从小到大排序,同时也将values按照weights排序的顺序进行重新排列。然后从头开始用i遍历这两个数组。由于对于weights而言随着i的增大weights[i]都会增大,因此只要关注values[i]的变化情况。而values[i]这个东西,如果它的值小于之前values中出现过的最大值,那么说明当前的这个i 对应的weights和values应该被舍弃,因为在它之前可以找到一个weights小于它但是values大于它的东西; 反之,如果它的值大于之前的最大值,那么就可以更新最大值。之前的那个最大值要不要也舍弃,这个取决于weights[i]和weights[max_i]是否相同。如果相同,那么相同重量的物品,肯定是取价值大的一种。如果不同,那么不能直接舍弃。
下面是我的代码实现,直接按想法写出来的,比较弱…:
def preprocess(_weights,_values,pack): def double_sort(w,v,left,right): # 因为涉及到同步排序,直接自己用快排实现了 if left >= right: return pivot = w[left] i = idx = left + 1 while i <= right: if w[i] <= pivot: w[idx],w[i] = w[i],w[idx] v[idx],v[i] = v[i],v[idx] idx += 1 i += 1 idx = idx - 1 w[left],w[idx] = w[idx],w[left] v[left],v[idx] = v[idx],v[left] double_sort(w,v,left,idx-1) double_sort(w,v,idx+1,right) weights,values = list(_weights),list(_values) leng = len(weights) double_sort(weights,values,0,leng-1) max,maxIdx,drop = values[0],0,[] # 三个变量分别记录values出现过的最大值,最大值所在下标,所有要被舍弃的物品的下标 for i in range(1,leng): if weights[i] > pack: # 对于出现超重的记录,可以直接将剩余记录都舍弃(因为从小到大排列)就结束了 drop.extend(range(i,leng)) break if max >= values[i]: # 当前value小于历史最大值情况 drop.append(i) else: if weights[maxIdx] == weights[i]: # 两物品同重量情况 drop.append(maxIdx) # 舍弃之前那个,若不同重量则不能舍弃 max = values[i] # 更新历史最大值 maxIdx = i # 返回值中,所有drop中存在的下标的物品都不用了 resWeight = [weights[i] for i in range(leng) if i not in drop] resValue = [values[i] for i in range(leng) if i not in drop] return resWeight,resValue
值得一说的是, 最开始我误以为求的只是性价比,即单纯的value/weight,但是马上发现这样不对劲。比如weights = [2,3]以及values=[20,29]这样两种物品,显然第一种物品的性价比高,而按照上述算法这两种物品都会被保留。如果要求装一个容量是3的背包,那么最大价值显然是装一个重量是3的进去而不是2。因此,2虽然性价比比3高,但是不能直接舍弃3。反过来,如果values=[20,19],此时按照上述算法3会被抛弃。而事实上,装一个容量是3的背包的时候,装一个3进去还不如装一个2进去的价值高,因此可以舍弃3。
■ 主要逻辑
预处理完成后,就可以看看到底如何选择物品来解决完全背包问题了。
按照最上面的二维数组DP解法,可以得到状态转移方程是res[i][j] = max(res[i-1][j], res[i][j-weight] + value)。res[i-1][j]的意思是不取用第i种物品,而res[i][j-weight],由于现在第i种物品可以取用若干次,所以“加取一件第i种物品”后总价值,其来源不应该是“明确不取用第i种物品”的res[i-1][j-weight],而是“有可能取用了若干个第i种物品”的res[i][j-weight]。 所以二维数组的解法,01背包和完全背包相差就只有这么一点细节。
二维数组解法的具体代码就不写了。下面基于这个二维数组的推导式,尝试找用一维数组就能解决的办法。
一维数组的情况,状态转移方程和01问题时一模一样。即vtable[k] = max(vtable[k], vtable[k-weight] + value)。这是可以理解的,因为无论是01还是完全,其取一件物品的时候都面临的是取or不取两个选择。那么不同之处在哪里? 在01问题的时候,我们强调过算法里层循环的逆序特征。回忆一下,那是因为推导res[i][j]的值的时候要用到res[i-1][j-height],而[i-1]在一维数组遍历的时候,指“上一次遍历结果”,因此整个数组要从右往左遍历以求当前值左边的所有值都还保持着“上一次遍历结果”时的状态。而到了完全问题中,用到的值变成了res[i][j-weight],[i]此时表示的,是“本次遍历结果”,即完全问题中,遍历一维数组时要保证当前元素左边的所有元素都是经过本次遍历,而被更新过了的数据。 换言之,遍历顺序变为了从左到右。
事实上,遍历顺序的改变也是唯一的,01问题和完全问题在一维数组DP算法上的差别。伪代码:
for i = 1..M, M是物品种类数
for j = 0..N,N是背包最大承重量
vtable[j] = max(vtable[j], vtable[j-weight] + value),weight和value是当前i对应物品的重量和价值
再次重申,完全问题的算法和01问题的差别只在里层循环遍历方向上,前者逆序,后者顺序(当然是以一维数组DP作为解决算法的前提下)
参照上述伪代码和01问题中的代码,很容易就可以写出完全背包问题的代码:
def totalknap(weights, values, pack): num = len(weights) vtable = [0] * (pack + 1) for i in range(num): weight = weights[i] value = values[i] for j in range(weight,pack+1): # 注意循环控制条件,还是j-weight不小于0 vtable[j] = max(vtable[j], vtable[j-weight] + value) return vtable
当然这段代码里没加预处理。此外,正如上面01问题中提到的,vtable的初始化方式可以控制“是否恰好塞满”这个子问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号