
【Python】 垃圾回收机制和gc模块
垃圾回收机制和gc模块
Py的一个大好处,就是灵活的变量声明和动态变量类型。虽然这使得学习py起来非常方便快捷,但是同时也带来了py在性能上的一些不足。其中相关内存比较主要的一点就是py不会对已经销毁的对象所占据的内存做自动的释放内存空间的工作。
在细看内存释放工作之前,有必要先来了解一下py的垃圾回收机制。
■ 垃圾回收机制
Python中,主要依靠gc(garbage collector)模块的引用计数技术来进行垃圾回收。所谓引用计数,就是考虑到Python中变量的本质不是内存中一块存储数据的区域,而是对一块内存数据区域的引用。所以python可以给所有的对象(内存中的区域)维护一个引用计数的属性,在一个引用被创建或复制的时候,让python,把相关对象的引用计数+1;相反当引用被销毁的时候就把相关对象的引用计数-1。当对象的引用计数减到0时,自然就可以认为整个python中不会再有变量引用这个对象,所以就可以把这个对象所占据的内存空间释放出来了。
引用计数技术在每次引用创建和销毁时都要多做一些操作,这可能是一个小缺点,当创建和销毁很频繁的时候难免带来一些效率上的不足。但是其最大的好处就是实时性,其他语言当中,垃圾回收可能只能在一些固定的时间点上进行,比如当内存分配失败的时候进行垃圾回收,而引用计数技术可以动态地进行内存的管理。
如果说效率只是一个不足的话,那么引用计数存在一些比较致命的软肋使得其一直不被接受为一种可以广泛运用的垃圾回收机制,这便是对循环引用的处理。在Python中有一些类型比如tuple,list,dict等,其作为容器类型可以包含若干个对象。如果某个对象就是它本身,或者两个对象中互相包含对方,那么就构成了一个循环引用。比如下面这段代码:

import sys class Test(): def __init__(self): pass t = Test()
k = Test() t._self = t print sys.getrefcount(t) #sys.getrefcount函数用来查看一个对象有几个引用
print sys.getrefcount(k)
####结果####
3
2
getrefcount函数查看一个对象存在几个引用关系,一般状态下的普通变量如上面的k,返回值都是2。不是1是因为把k作为参数传递给函数的时候,要先复制一份引用,然后把这个引用赋给形式参数供函数运行,在函数运行过程中,会保持这个引用始终升高为2。
从上面运行的结果可以看出来,Test类实例t由于添加了一个自己对自己的引用,相当于:
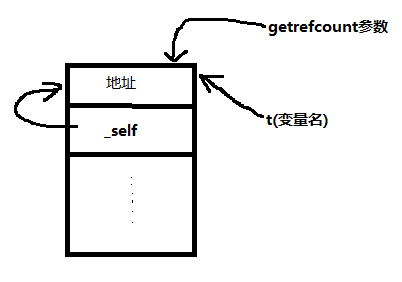 这样总共三个引用。
这样总共三个引用。
del语句可以消除一个引用关系。对于没有_self这样的自我引用的情况下,del(k)相当于销毁了变量名到内存地址的这一层引用关系,自getrefcount执行完成之后,这部分内存就可以得到释放了。但是如果存在_self这个自我引用的话,即使消除了del(t)这个引用关系,这个对象的引用计数仍然是1。得不到销毁,所以会造成内存泄露。
可以看到,基于引用计数的垃圾回收机制因为循环引用的存在可能会导致内存泄露,所以python在引用计数的基础上也增加了其他几种垃圾回收的方式。这里简单提一下。
● 标记-清除的回收机制
针对循环引用这个问题,比如有两个对象互相引用了对方,当外界没有对他们有任何引用,也就是说他们各自的引用计数都只有1的时候,如果可以识别出这个循环引用,把它们属于循环的计数减掉的话,就可以看到他们的真实引用计数了。基于这样一种考虑,有一种方法,比如从对象A出发,沿着引用寻找到对象B,把对象B的引用计数减去1;然后沿着B对A的引用回到A,把A的引用计数减1,这样就可以把这层循环引用关系给去掉了。
不过这么做还有一个考虑不周的地方。假如A对B的引用是单向的, 在到达B之前我不知道B是否也引用了A,这样子先给B减1的话就会使得B称为不可达的对象了。为了解决这个问题,python中常常把内存块一分为二,将一部分用于保存真的引用计数,另一部分拿来做为一个引用计数的副本,在这个副本上做一些实验。比如在副本中维护两张链表,一张里面放不可被回收的对象合集,另一张里面放被标记为可以被回收(计数经过上面所说的操作减为0)的对象,然后再到后者中找一些被前者表中一些对象直接或间接单向引用的对象,把这些移动到前面的表里面。这样就可以让不应该被回收的对象不会被回收,应该被回收的对象都被回收了。
● 分代回收
分代回收策略着眼于提升垃圾回收的效率。研究表明,任何语言,任何环境的编程中,对于变量在内存中的创建/销毁,总有频繁和不那么频繁的。比如任何程序中总有生命周期是全局的、部分的变量。
而在垃圾回收的过程中,其实在进行垃圾回收之前还要进行一步垃圾检测,即检查某个对象是不是垃圾,该不该被回收。当对象很多,垃圾检测将耗费大量的时间而真的垃圾回收花不了多久。对于这种多对象程序,我们可以把一些进行垃圾回收频率相近的对象称为“同一代”的对象。垃圾检测的时候可以对频率较高的“代”多检测几次,反之,进行垃圾回收频率较低的“代”可以少检测几次。这样就可以提高垃圾回收的效率了。至于如何判断一个对象属于什么代,python中采取的方法是通过其生存时间来判断。如果在好几次垃圾检测中,该变量都是reachable的话,那就说明这个变量越不是垃圾,就要把这个变量往高的代移动,要减少对其进行垃圾检测的频率。
■ gc模块的介绍
根据以上的介绍,我们知道了python对于垃圾回收,采取的是引用计数为主,标记-清除+分代回收为辅的回收策略。对于循环引用的情况,一般的自动垃圾回收方式肯定是无效了,这时候就需要显式地调用一些操作来保证垃圾的回收和内存不泄露。这就要用到python内建的垃圾回收模块gc模块了。
最常见的gc模块的使用就是用gc.collect()方法。那就先来看下这个方法把:
import sys import gc a = [1] b = [2] a.append(b) b.append(a) ####此时a和b之间存在循环引用#### sys.getrefcount(a) #结果应该是3 sys.getrefcount(b) #结果应该是3 del a del b ####删除了变量名a,b到对象的引用,此时引用计数应该减为1,即只剩下互相引用了#### try: sys.getrefcount(a) except UnboundLocalError: print 'a is invalid' ####此时,原来a指向的那个对象引用不为0,python不会自动回收它的内存空间#### ####但是我们又没办法通过变量名a来引用它了,这就导致了内存泄露#### unreachable_count = gc.collect() ####gc.collect()专门用来处理这些循环引用,返回处理这些循环引用一共释放掉的对象个数。这里返回是2####
可以看到,没有gc模块的时候,我们对循环引用是束手无策的,在调用了一些gc模块的方法之后,它会实现上面“垃圾回收机制”部分中提到的一些策略比如“标记-清除”来进行垃圾回收。因为有了这个模块的封装,我们就不用关心具体的实现了。
然而collect方法也不是万能的。有些时候它并不能有效地回收所有该回收的对象。比如下面这样一段代码:
class A(): def __init__(self): pass def __del__(self): pass class B(): def __init__(self): pass def __del__(self): pass a = A() b = B() a._b = b b._a = a del a del b print gc.collect() #结果是4 print gc.garbage #结果是[<__main__.A instance at 0x0000000002296448>, <__main__.B instance at 0x0000000002296488>]
可以看到,对我们自定义类的对象而言,collect方法并不能解决循环引用引起的内存泄露,即使在collect过后,解释器中仍然存在两个垃圾对象。
这里需要明确一下,之前对于“垃圾”二字的定义并不是很明确,在这里的这个语境下,垃圾是指在经过collect的垃圾回收之后仍然保持unreachable状态,即无法被回收,且无法被用户调用的对象应该叫做垃圾。gc模块中有garbage这个属性,其为一个列表,每一项都是当前解释器中存在的垃圾对象。一般情况下,这个属性始终保持为空集。
那么为什么在这种场景下collect不起作用了呢?这主要是因为我们在类中重载了__del__方法。__del__方法指出了在用del语句删除对象时除了释放内存空间以外的操作。一般而言,在使用了del语句的时候解释器会首先看要删除对象的引用计数,如果为0,那么就释放内存并执行__del__方法。在这里,首先del语句出现时本身引用计数就不为0(因为有循环引用的存在),所以解释器不释放内存;再者,执行collect方法时照理由应该会清除循环引用所产生的无效引用计数从而达到del的目的,对于这两个对象而言,python无法判断调用它们的__del__方法时会不会要用到对方那个对象,比如在进行b.__del__()时可能会用到b._a也就是a,如果在那之前a已经被释放,那么就彻底GG了。为了避免这种情况,collect方法默认不对重载了__del__方法的循环引用对象进行回收,而它们俩的状态也会从unreachable转变为uncollectable。由于是uncollectable的,自然就不会被collect处理,所以就进入了garbage列表。
collect返回4的原因是因为,在A和B类对象中还默认有一个__dict__属性,里面有所有属性的信息。比如对于a,有a.__dict__ = {'_b':<__main__.B instance at xxxxxxxx>}。a的__dict__和b的__dict__也是循环引用的。但是字典类型不涉及自定义的__del__方法,所以可以被collect掉。所以garbage里只剩下两个了。
有时候garbage里也会出现那两个__dict__,这主要是因为在前面可能设置了gc模块的debug模式,比如gc.set_debug(gc.DEBUG_LEAK),会把所有已经回收掉的unreachable的对象也都加入到garbage里面。set_debug还有很多参数诸如gc.DEBUG_STAT|DEBUG_COLLECTABLE|DEBUG_UNCOLLECTABLE|DEBUG_SAVEALL等等,设置了相关参数后gc模块会自动检测垃圾回收状况并给出实时地信息反映。
● gc.get_threshold()
这个方法涉及到之前说过的分代回收的策略。python中默认把所有对象分成三代。第0代包含了最新的对象,第2代则是最早的一些对象。在一次垃圾回收中,所有未被回收的对象会被移到高一代的地方。
这个方法返回的是(700,10,10),这也是gc的默认值。这个值的意思是说,在第0代对象数量达到700个之前,不把未被回收的对象放入第一代;而在第一代对象数量达到10个之前也不把未被回收的对象移到第二代。可以是使用gc.set_threshold(threashold0,threshold1,threshold2)来手动设置这组阈值。
【说了一大堆,但其实我自己也还没有太搞明白,本来python核心编程这本书在身边的话还可以参阅一下,现在这些也就是一些网上碎片化信息的拼接。总之上面的话中可能有很多漏洞和错误,还是请看到这篇文章的人谨慎相信。】


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧