
[机器学习]决策树和随机森林算法简介
决策树和随机森林算法简介
1-决策树
1.1-决策树模型的结构
决策树(decision tree)是一种分类与回归方法,本文主要讨论用于分类的决策树,决策树的结构呈树形结构,在分类问题中,其代表基于特征对数据进行分类的过程,通常可以认为是if-then规则的集合,也可以认为是定义在特征空间与类空间上的条件概率分布。其主要优点是模型可读性好并且分类速度快。训练的时候,利用训练数据根据损失函数最小化的原则建立决策树模型。预测时对于新的数据,利用决策树进行分类。决策树的学习通常包括三个步骤:特征选择,生成决策树,对决策树进行剪枝。这些决策树的思想主要来自Quinlan在1986年提出的ID3算法和1993年提出的C4.5算法,以及Breiman等人在1984年提出的CART算法。
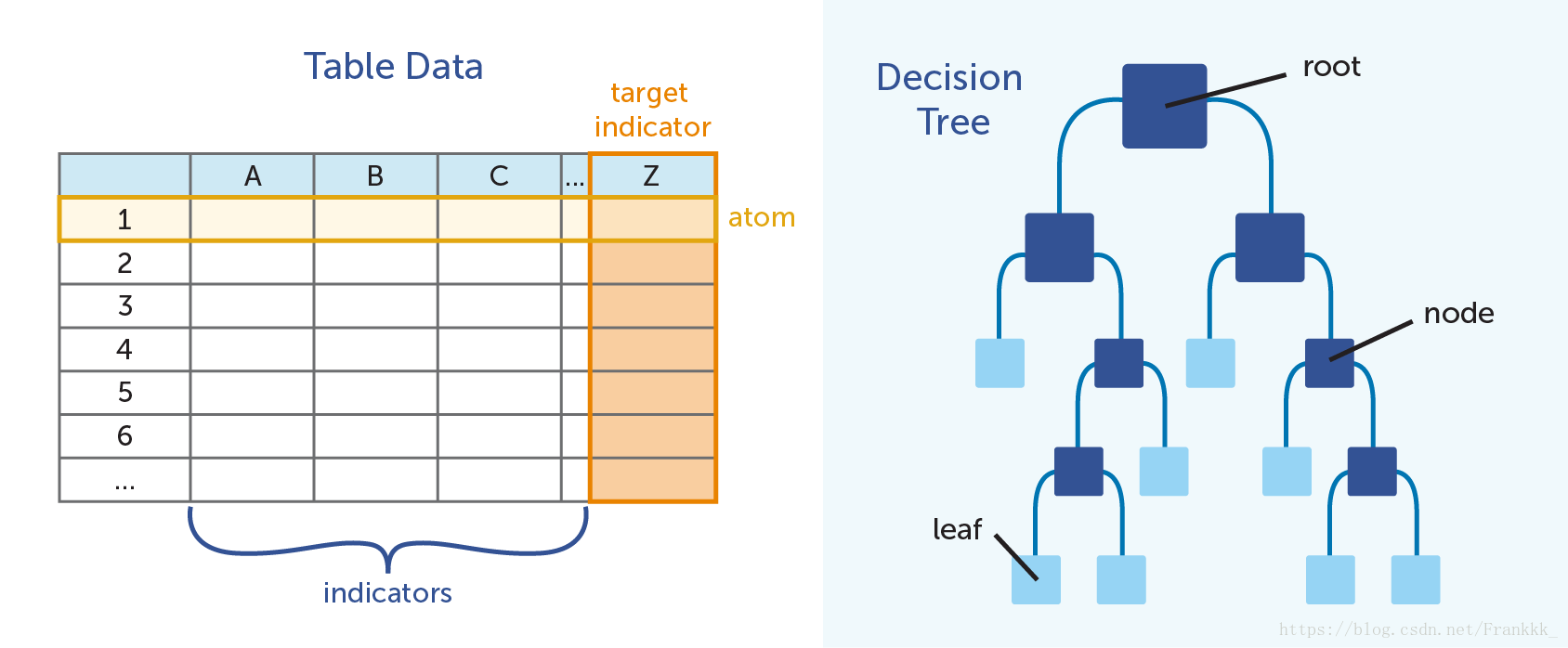
用于分类的决策树是一种对数据进行分类的树形结构。决策树主要由节点(node)和有向边(directed edge)组成。节点有两种类型:内部节点(internal node)以及叶节点(leaf node)。内部节点表示一个特征或者属性,叶节点表示一个类。其结构如图所示:
1.2-特征选择
特征选择在于选取对训练数据具有分类能力的特征,这样可以提高决策树的学习效率,如果利用一个特征进行分类的结果与随机分类的结果没有太大差别,则称这个特征是没有分类能力的。通常扔掉这样的特征对于决策树的学习精度影响不大,通常特征选取的准则是信息增益或者信息增益比。
在信息论中,熵(entropy)是表示随机变量不确定性的度量,设X是一个取有限个值得离散随机度量,其概率分布为:
那么随机变量的熵定义为:
熵越大,随机变量的不确定性越大,从定义可以验证
当或时 ,随机变量完全没有不确定性,当时,,熵取值最大,随机变量的不确定性最大。
条件熵表示在已知随机变量 的条件下随机变量 的不确定性。随机变量给定的条件下随机变量的条件熵(conditional entropy),定义为 给定条件下的条件概率分布的熵对的数学期望
这里,信息增益(information gain)表示得知特征的信息而使得类的不确定性减小的程度。
特征对训练集的信息增益定义为集合的经验熵与特征给定条件下的经验条件熵之差,即
1.3-构建决策树的ID3算法
决策树的算法主要有ID3,C4.5以及CART,ID3算法的核心是在决策树各个节点上应用信息增益准则选取特征,递归构建决策树。
下面得到构建决策树的ID3算法:
输入:训练数据集D,特征集A,阈值;
输出:决策树T.
(1)若D中所有实例属于同一类,则T为单节点树,并将作为该节点的类标记,返回T;
(2)若A=,则T为单节点树,并将D中实例数最大的类作为该节点的类标记,返回T;
(3)否则按照信息增益算法计算A中各特征对D的信息增益,选择信息增益最大的特征;
(4)如果的信息增益小于阈值,则T为单节点树,并将D中实例数最大的类 作为该节点的类标记,返回T;
(5)否则,对的每一可能值,依据将D分割为若干非空子集,将中实例数最大的类作为标记,构建子节点,由节点及其子节点够成树T,返回T;对第i个子节点,以为训练集,以为特征集,递归地调用步1-步5,得到子树,返回。
2-集成学习
集成学习(ensemble learning)通过构建并结合多个学习器来完成学习任务,有时候也被称为多分类器系统(multi-classfier system)、基于委员会的学习(committee-based learning)等。
下图显示出集成学习的一般结构:先构建一组“个体学习器”(individual learner),再用某种策略将它们结合起来。个体学习器通常由一个现有的学习算法由训练数据产生,例如ID3决策树算法,BP神经网络算法等,此时集成中只包含同种类型的个体学习器,例如“决策树集成”中全是决策树,“神经网络集成”中全是神经网络,这样的集成是“同质”的(homogeneous)。同质集成中的个体学习器也称为“基学习器”(base learner),相应的学习算法称为“基学习算法”(base learning algorithm)。集成也可包含不同类型的个体学习器,例如同时包含决策树和神经网络,这样的集成是“异质”的(heterogenous)。异质集成中的个体学习器由不同的学习算法产生,这是就不再有基学习算法;相应的,个体学习器一般不称为基学习器,常称为“组件学习器”(component learner)或直接称为个体学习器。
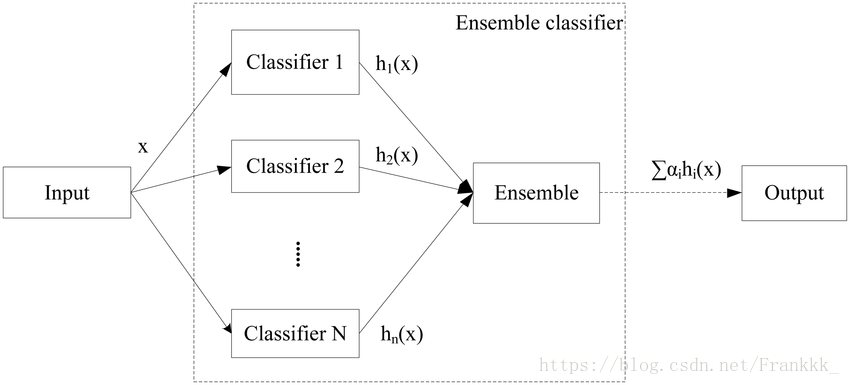
集成学习通过将多个学习器进行结合,常常可以获得比单一学习器更为显著优越的泛化性能。这对“弱学习器”(weak learner)尤为明显,因此集成学习的很多理论研究都是针对弱学习器进行的,而基学习器有时也被直接成为弱学习器。但是需要注意的是,虽然从理论上来说使用弱学习器集成足以获得好的性能,但在实践中出于种种考虑,例如希望使用较少的个体学习器,或是重用关于常见学习器的一些经验等,人们往往会使用比较强的学习器。
根据个体学习器的生成方式,目前的集成学习方法大致可分为两类,即个体学习器间存在强依赖关系、必须串行生成的序列化方法,以及个体学习器间不存在强依赖关系、可同时生成的并行化方法;前者的代表是Boosting,后者的代表是Bagging和“随机森林”(Random Forest)。
3-随机森林算法
随机森林(Random Forest,简称RF)[Breiman,2001a]是Bagging的一个扩展变体,RF在以决策树为基学习器构建Bagging集成的基础上,进一步在决策树的训练过程中引入了随机属性选择。具体来说,传统决策树在选择划分属性时是在当前节点的属性集合(假定有d个属性)中选择一个最优属性;而在RF中,对基决策树的每个节点,先从该节点的属性集合中随机选择一个包含k个属性的子集,然后再从这个子集中选择一个最优属性用于划分。这里的参数k控制了随机性的引入程度:若令k=d,则基决策树的构建与传统决策树相同;若令k=1,则是随机选择一个属性用于划分;一般情况下,推荐值。
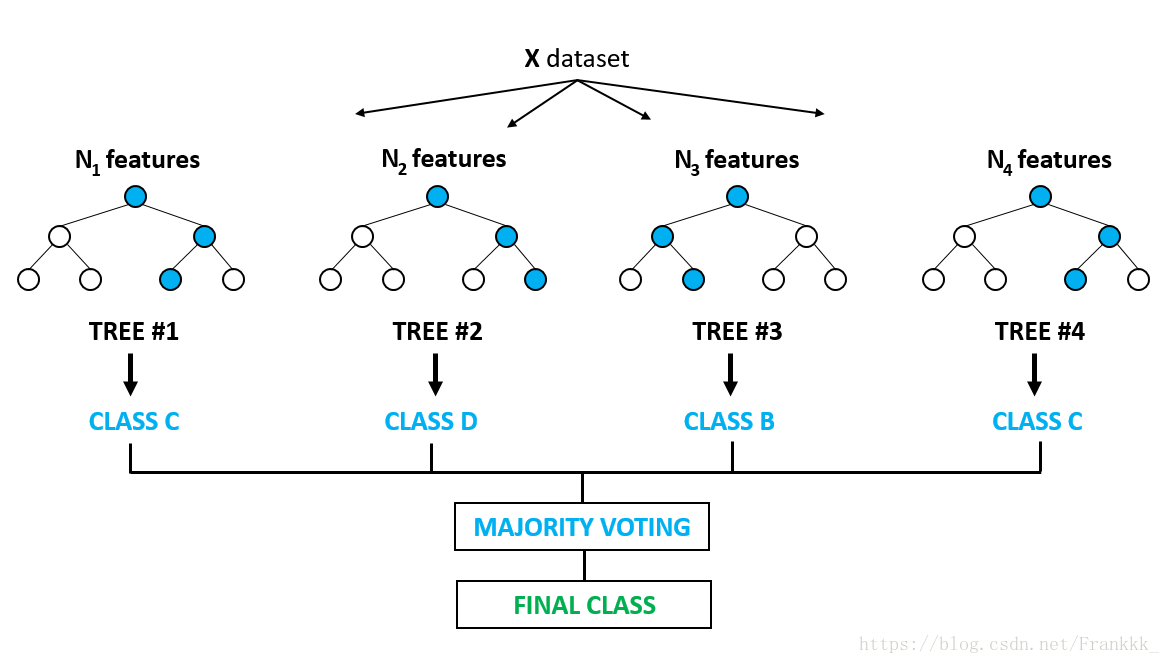
随机森林简单,容易实现,计算开销小,令人惊奇的是,它在很多现实任务中表现出了强大的性能,被誉为“代表集成学习技术水平的方法”。可以看出,随机森丽对Bagging只做了小改动,但是与Bagging中基学习器的“多样性”仅通过样本扰动而来不同,随机森林中基学习器的多样性不仅来自样本扰动,还来自属性扰动,这就使得最终集成的泛化性能可通过个体学习器之间的差异度的增加而进一步提升,决策树的结构如下图:
对于随机森林的编程,可以使用scikit-learn框架
http://scikit-learn.org/stable/user_guide.html#

 浙公网安备 33010602011771号
浙公网安备 33010602011771号