
TCP编程中的自定义消息
TCP编程中的自定义消息
本章我们讨论的主题是「TCP编程中的自定义消息」
网络编程(服务器编程)这个话题是非常庞大的,核心topic是跨主机通信,在这个主题下可以(必须)引发出非常多其他的外延概念与知识。跨主机的通信本身就是在进行进程间的通信,本机中的进程间通信方式有很多(如管道、共享内存等等),但这些本质上还是在同一个虚拟内存中(物理内存页)中玩,并不反直觉,而只有「跨主机的进程间通信」是一个有点「匪夷所思」的事情,好在这些黑魔法得益于伯克利大学开发的socket接口,让黑魔法得以实现。说网络编程是socket编程未免太过狭隘片面,在网络编程中,大部分时间我们围绕着「handler」或者说「File-handler」做文章(在微软的语境下被翻译为句柄,文件句柄)。
socket编程几乎就是围绕sockset文件句柄编程,它需要(必须)解决几个问题:
- 怎么高效的
accept(接受)对端的connect(链接)生成socket文件句柄 - 怎么高效的读(
read)写(write)这些文件句柄
这里的高效是指最大限度的利用系统与硬件的性能(利用系统的特性、压榨硬件的性能)。
在解决这2个问题的过程中衍生出了更多的其他主题,如:
- IO多路复用(
select,poll,epoll,IOCP) - 阻塞IO、非阻塞IO
- 同步IO、异步IO
- 线程池、进程池、内存池
这些概念(方案)终极目的都是在解决怎么更好更快的读写socket文件句柄。
我们会逐步解决这些问题,现在面临的第一个问题是:「怎么让跨主机的两个进程正常的交流」。
我们采用的网络协议(传输层)为TCP,看中的是它的2个特性:
- 有序
- 可靠
其中,有序指的是,发送端与接收端,两端之间保持严格的发送时序,以时间流逝为参考系。(讲人话就是,当发送端发送数据时,若A数据排在B数据的前面,那接受端中必定是A数据排在B数据前面,这无需质疑),可靠指的是「传输」的可靠,你始终可以相信TCP使命必达,所谓使命必达是指TCP协议会排除万难使出浑身解数确保数据能够正常的传送的对端。(这是TCP的信念,所以它才会有重传机制、流控机制)。
在我们这个章节中,对TCP的核心认知是:「stream」流。
TCP是面向连接的流式协议。这句话2个点:
- 面向连接
- 流式
面向连接指的是通信双方需要在各自端中维护一个状态,这些状态是通过「协商」而得,因此,只要2端想要现在通信,以后通信,那么双方就必须维持住这些状态,现在维护,以后也要维护,直到一段close.
流式指的是TCP传来的数据形式的字节序列,前后紧密排列的字节序列,这些序列没有边界,不分高低贵贱你我他,从TCP角度上看只是一串似乎永无尽头的字节序列而已,直到程序员给这串字节序列赋予逻辑意义。
认识到TCP时流式协议是一个基本,但又重要的事情。这能让我们在利用socket进行tcp编程时少很多莫秒奇妙的问题,在此不妨重申一遍:TCP是流式协议。
这意味着:
发送方发送数据->ABCDEFGHIJKLMN->
接收方接收到的数据是:
->ABCDEFGHIJKLMN->或者->AB然后CDEF接着GHIJKLMN->或者->ABC然后DE接着FGHI继续JKLMN->或者->ABC然后DEFGH接着I继续JKLMN->或者
... ...
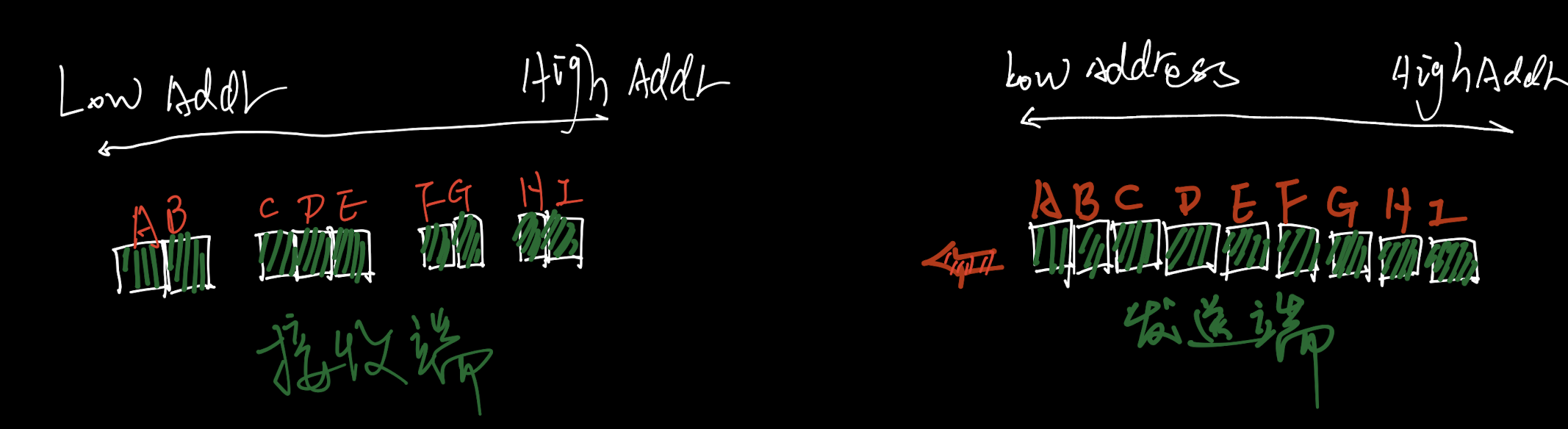
可以发现,发送方发送一些数据后,接收方接收数据的规律就是「没有规律」
发送方只是调用了1次send(或者write)函数把这串字节数据发送出去,而接收方确调用了N次(N=1、2、3、4...)recv(或者read)函数来读取这些数据,而每次读取内容的多少也没有规律,但始终保证的是,数据->ABCDEFGHIJKLMN->的字节顺序在发送与接收端始终是保持一致的。
那么,显然我们利用TCP编程需要解决的一个基础问题就是,如何解读这些字节流。
这些字节流之间没有边界,我们如何知道发送端是想发多少字节数据给我们呢?
基本2种方式:
- 事先约定特殊字符,每个字符去对比,发现约定好的字符后,就知道,字节流到此为止了,之前收到的所有数据就是对端想要发送给我的
- 事先约定发送长度,而我们约定用N个字节的整数来表示将要发送的数据长度,这样,只要我们事先读取N个字节,然后就知道这个整数值了
以上2种是基本的处理框架,在此朴素的思想上,逐渐扩展(自定义包头),最终形成私有协议。(私有协议本质就是看2端「事先」约定了什么了)
接下来,我们通过私有协议,来实现用户信息的传输(姓名,年龄),用户的年龄我们可以用定长的1字节(uint_8)来定义,而姓名则显然是不定长的,这就要求我们自定义协议了。
(注:通常我们说的自定义协议是指用户层的协议,可以认为是一种用户传输数据的格式,数据组织方式)
接下来我们通过代码的方式来说明自定义数据格式(协议)的TCP传输:
/*
模板代码,创建listen_fd,监听socket
*/
int creat_listenfd(){
struct sockaddr_in addr;
addr.sin_family = AF_INET;
//指定监听端口,htons函数用来将主机字节序转为网络字节序(host address to network address,short int data type),因为socket用来做跨主机通信,所以需要「兼容」所有CPU类型的主机,因此我们不能假设本机字节序与远程字节序有关联,因此我们在指定端口时,无论本地主机字节序是什么,我们都将其转化为网络字节序(其实就是大端字节序),这样,只要编程人员都遵循这个开发范式,那么就能统一字节序了。
addr.sin_port = htons(10000);
addr.sin_addr.s_addr = INADDR_ANY;
int sock = socket(AF_INET,SOCK_STREAM,0);
if(sock<0){return -1;}
int v = 1;
//设置监听地址复用
setsockopt(sock,SOL_SOCKET,SO_REUSEADDR,&v, sizeof(v));
int ret = bind(sock,(struct sockaddr*)&addr, sizeof(addr));
if(ret<0){
perror("bind error\r\n");
close(sock);
return -1;
}
ret = listen(sock,5);
if(ret<0){
perror("listen error\r\n");
close(sock);
return -1;
}
return sock;
}
/*
socket提供的recv或者read接口并不承诺读取的字节数,比如read(fd,buf,1024),我们的本意是读取1024个字节到buf中,而实际上当read返回时buf中并不一定读取了1024个字节,这个并非bug,而是feature。
这本质是TCP是流式协议的体现,因此我们需要实现自己的read_n函数,这个函数的特性是,只有当读取到我们希望大小的数据,或者,读取出错(或者对端关闭)时才返回。
*/
int read_n(int fd,uint8_t *buf,int num,uint8_t mode){
int flag = 0;
if(mode == 1){
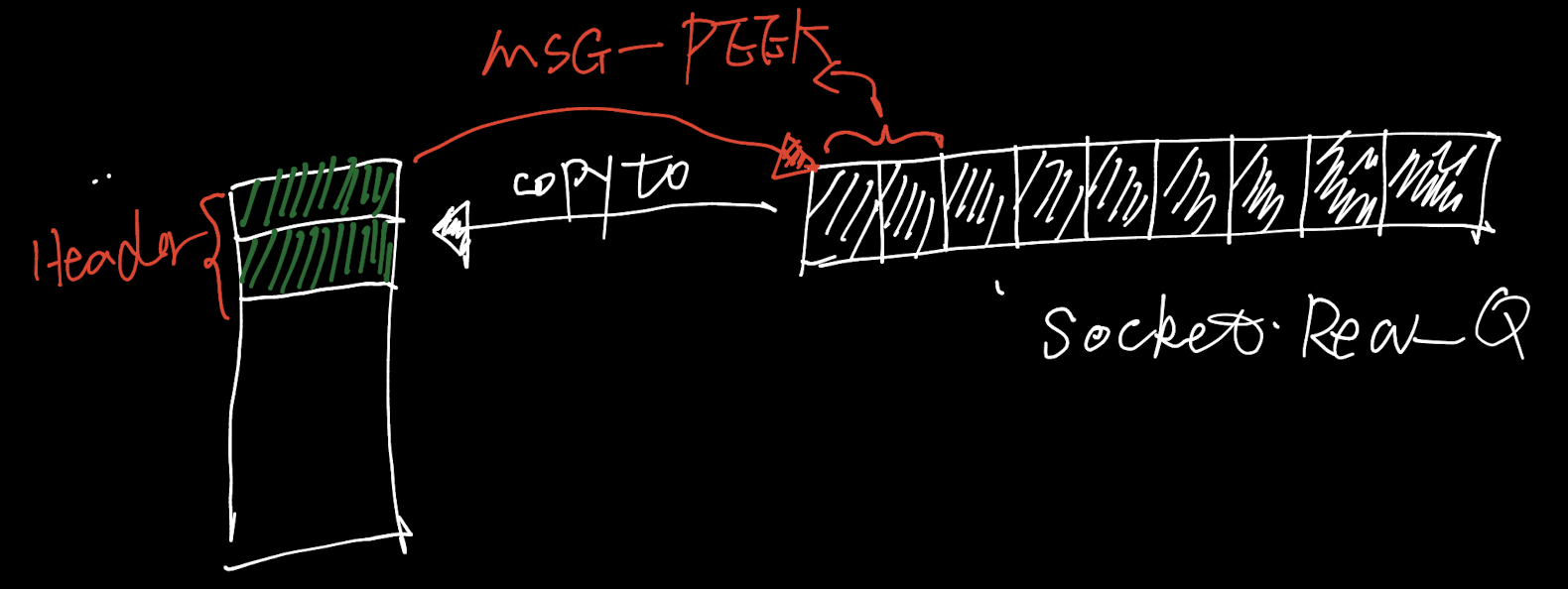
//采用这种模式从socket的fd中读取数据时是采用的拷贝的方式,而不是移动的方式。这意味着使用这种模式读取socket中的数据时,socket队列中的数据会保留,等下次读取socket时依然能够读到这些数据。(这样的模式有什么应用场景呢?看下面读取自定义协议数据时就知道了)
flag = MSG_PEEK;
}
uint8_t *tmp_buf = buf;
int should_readlen = num;
int readed_len = 0;
//不停的从socket中读取数据,直到读取的长度符合我们的要求才中断循环,除非读取出错或者对端关闭
while (1){
if(readed_len == should_readlen){break;}
int l = (int) recv(fd,tmp_buf,should_readlen,flag);
//l是recv读取的有效字节长度,小于0时通常意味着读取操作,但是,当socket为非阻塞模式时,读取这个socket文件句柄时也可能返回小于0的值,这意味着可能并不是读取错误,而只是此刻没有数据可读而已。(在socket的阻塞模式下,当读取socket,而其此刻又没有数据可读时,recv函数会一致阻塞不会返回)
if(l<0){
if(errno == EAGAIN || errno == EWOULDBLOCK){continue;}
perror("read error\r\n");
break;
}
if(l == 0){//对端close了socket
break;
}
tmp_buf += l;
should_readlen -= l;
readed_len += l;
}
return readed_len;//返回已读取的数据长度
}
以上,我们的基础准备工作已经完成,接下来我们只需要创建监听socket,等待客户端连接,然后我们根据约定的协议格式开始读取数据即可。
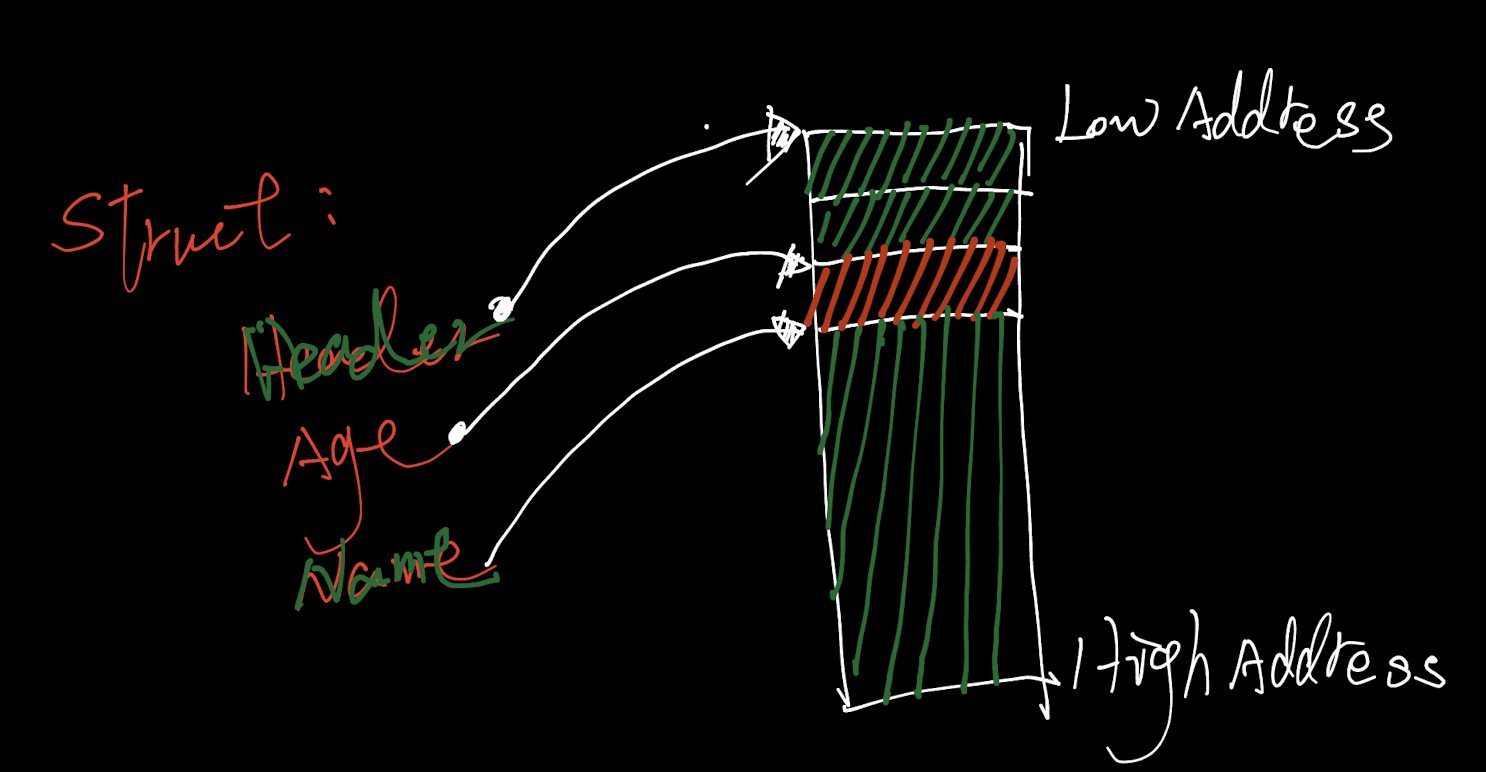
//定义好数据格式,UserInfo是我们需要传输的数据,分为2部分,分为固定长度的协议头,以及不定长的数据负载(padyload),协议头是我们自定义协议的核心,在这里,简单起见我们只设计了1个表示数据长度的字段,而实际中包头的数据更复杂,比如会设计版本号(用来做协议升级兼容)、业务会话id(用来做拆包,一个业务包有可能超出TCP传输的限制长度,需要分多次传输,最终根据会话id组合成一个完整的业务包)、是否压缩(用来表示当前的数据是否被压缩过)、压缩格式、校验和......总之,包头的字段丰富多彩,可以根据实际业务来设计。
//为了避免跨主机通信间因为计算机体系结构的不同在在结构体数据对其方式上不同,而引发错误,我们让我们的结构体字段间不存在padding,字段与字段值在内存中紧密排列(当然,还有其他方式来避免产生这样的问题,比如精心编排字段类型的顺序或者添加padding字段来控制,但直接指定1字节对齐方式似乎是最简单偷懒的方式(尽管其效率可能不是最高的))
#pragma pack(push,1)
typedef struct PHeader{
uint16_t package_len;//
}Header;
typedef struct UINFO{
Header ok_header;
//uint16_t age;
uint8_t age;
char name[0];/*柔性数组,我们实现并不清楚用户名究竟占几个字节,无论这个数组有多长都无法避免过长或者过短的问题,所以我们所以将其设置为0长度,此刻其在结构体中并不占空间,直到我们人为的malloc一个长度的内存空间*/
}UserInfo;
#pragma pack(pop)
int main() {
//这里的服务器设计我们只为了展示协议的设计,在IO多路复用,多线程/进程服务N个客户端方面并没有涉及,这属于后续文章内容
int listen_fd = creat_listenfd();
if(listen_fd<0){return -1;}
struct sockaddr addr;
socklen_t addr_sz = sizeof(addr);
int client = accept(listen_fd,&addr,&addr_sz);
if(client<0){
perror("accept new client error\r\n");
close(listen_fd);
return -1;
}
printf("------ get a new client -------\r\n");
uint16_t pk_len = 0;//用pk_len来记录对端传过来的包的总长度(根据协议约定,发送端在发送数据时,需要讲整个包的长度写在包头结构体的package_len字段中,包头的长度为2字节)
while (1){
pk_len = 0;
//从client中读取定长2个字节,这2个字节数据表示的是接下来整个数据包的长度,我们在读取时采用的模式时1(MSG_PEEK),这表示我们的读取动作并不会影响socket接收队列中已经接收到的数据(我们并没有真正的从client中「读走」2字节,只是peek了2字节而已(copy))
int l = read_n(client,(uint8_t*)&pk_len, sizeof(pk_len),1);
if(l<0){
perror("peek data error\r\n");
break;
}
if(l == 0){
printf("remote closed\r\n");
break;
}
//将读取到的多字节数据从网络字节序转换为主机字节序
pk_len = ntohs(pk_len);
//创建对端给定的数据长度大小的结构体内存
UserInfo *userinfo = malloc(pk_len);
bzero(userinfo,pk_len);
//从client读取指定长度的数据,从用默认的读取方式(会从client中「读走」数据)
l = read_n(client,(uint8_t*)userinfo,pk_len,0);
if(l<0){
perror("read payload error\r\n");
break;
}
if(l == 0){
printf("read payload,remote closed\r\n");
break;
}
//userinfo->age = ntohs(userinfo->age);
printf("age = %d\r\n",userinfo->age);
printf("name = %s\r\n",userinfo->name);
printf("-----------------------------\r\n");
free(userinfo);
}
close(client);
close(listen_fd);
return 0;
}
以上,就是我们服务端的设计(这里只讨论协议的传输,而不考虑高性能服务器的设计)
而对于客户端:
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <string.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <fcntl.h>
#include <arpa/inet.h>
#include <errno.h>
//前后端一致的数据协议结构
#pragma pack(push,1)
typedef struct PHeader{
uint16_t package_len;
}Header;
typedef struct UINFO{
Header ok_header;
uint8_t age;
char name[0];
}UserInfo;
#pragma pack(pop)
int main() {
struct sockaddr_in addr;
addr.sin_family = AF_INET;
addr.sin_port = htons(10000);
inet_pton(AF_INET,"xxx",&addr.sin_addr);
int sock = socket(AF_INET,SOCK_STREAM,0);
if(sock<0){
perror("create sock error\r\n");
return -1;
}
int ret = connect(sock,(struct sockaddr*)&addr, sizeof(addr));
if(ret<0){
perror("connect server failed\r\n");
close(sock);
return -1;
}
printf("connect server sucuess\r\n");
int count = 0;
while (1){
if(count>=10000){break;}
count += 1;
int stv = (int)random() % 4;
stv = 0.5;
// sleep(stv);
uint16_t type = (uint16_t)random()%65535;
uint32_t cmd = (uint32_t)random()%3245634567;
uint8_t age = random() % 150;
//
char tmp[] = {'x','w','a','g','o','p','l'};
int index = random() % 7;
char name[128];
bzero(name,128);
sprintf(name,"name:%c%d",tmp[index],cmd);
uint16_t pk_len = 3 + strlen(name) + 1;//2个字节的包头+1个字节的age+字符串长度+1个字节的字符末尾'\0'空间
UserInfo *uinfo = malloc(pk_len);
bzero(uinfo,pk_len);
uinfo->ok_header.package_len = htons(pk_len);//注意多字节序数据类型的主机字节序转网络字节序
uinfo->age = age;//age是单字节,并不存在字节序问题
strcpy(uinfo->name,name);
//普通的send即可,底层socket会负责将我们的数据发送出去。当然,我们并不能确保调用1次send就能够将这个数据包发送出去(尽管这通常没有什么问题),在这里我们简化了设计,默认其1次调用就能成功发送完成所给定的数据,是实际上,我们应该设计合理的write_n函数,设计思路与read_n无异
int l = (int) send(sock,uinfo,pk_len,0);
if(l<0){
perror("send error\r\n");
break;
}
if(l == 0){
printf("remoet closed\r\n");
break;
}
printf("name = %s\r\n",uinfo->name);
printf("-------------------------\r\n");
}
close(sock);
printf("client out\r\n");
return 0;
}
以上,就是我们的前后端设计,用来传输自定义协议,这是一个最小模型,是2中最常见的私有协议设计模型之一(另一个是使用特殊分割符来标志数据边界),掌握了这个模型的基本结构后,我们可以在此基础上扩展丰富其协议功能,以及在这种思路的指导下,自行掌握另一种协议设计方式。
posted on 2021-12-31 23:55 shadow_fan 阅读(358) 评论(0) 编辑 收藏 举报

