TCP编程
tcp 面向连接 流
本文我们需要掌握的主要知识是『理解TCP是面向连接的协议』、『理解TCP是流式的』。
这两个知识点非常关键,只有掌握了这两个基本问题,才能进一步理解TCP协议的真正运作机制,以及网络编程中所遇到和需要解决的问题。
在接下来的章节中,我们需要在基于TCP协议的基础上掌握解决高性能网络编程中几个经典议题:
-
字节流数据的读取方式
-
从TCP-socket中高效的读取数据
-
数据传输的封装
-
单线程服务器
-
单线程IO多路复用服务器
-
多线程服务器
-
多线程IO多路复用服务器
以上问题是网络编程中非常经典的topic,每个议题几乎都对应一个或一些问题场景,以及一些相应的解决方案(线程池、内存池等),这些问题产生的原因有些是因为TCP本身的特性,有些是计算机IO体系的特性,当我们将上面问题全部理解掌握后,计算机网络编程的大纲轮廓以及一些关键议题我们就能心中有数了。
今天这个章节我们在铺垫了『理解TCP是面向连接的协议』、『理解TCP是流式的』后,再来解决:
- 字节流数据的读取方式
- 从TCP-socket中高效的读取数据
这两个议题。
理解TCP是面向连接的协议
为什么TCP要设计成面向链接、面向链接,究竟是在链接什么?
在回答这2个问题之前,我们先来看3幅图:
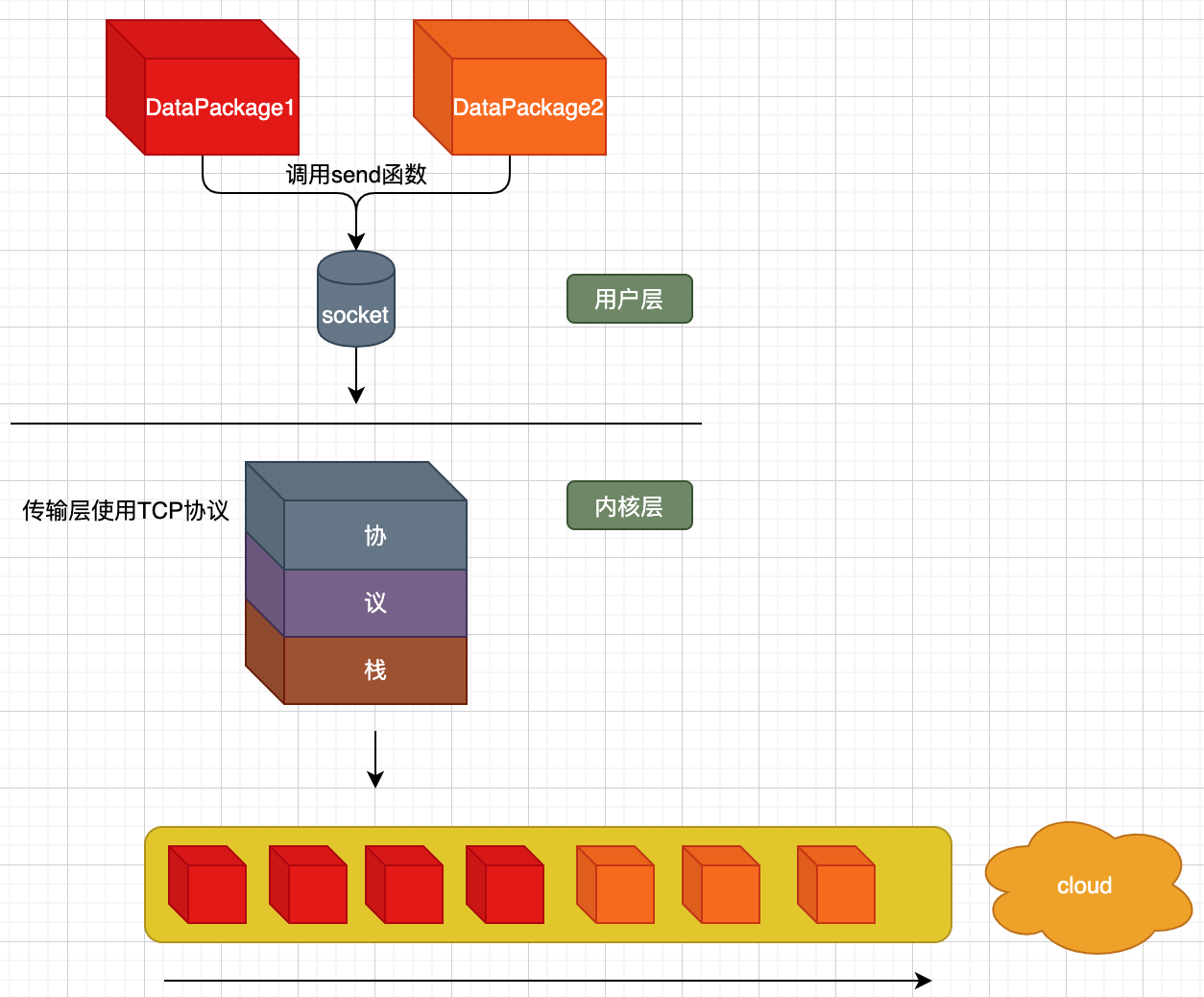
从这幅图中我们需要明白,我们调用2次send,发送用户态数据,当2个『用户数据包』从用户层进入内核协议栈后,并不一定是2个,也并不一定会立马发出去,有可能(极有可能)在网络上被分成了N个数据包,到目前为止,似乎这一点与UDP没啥差别。
第二幅图:
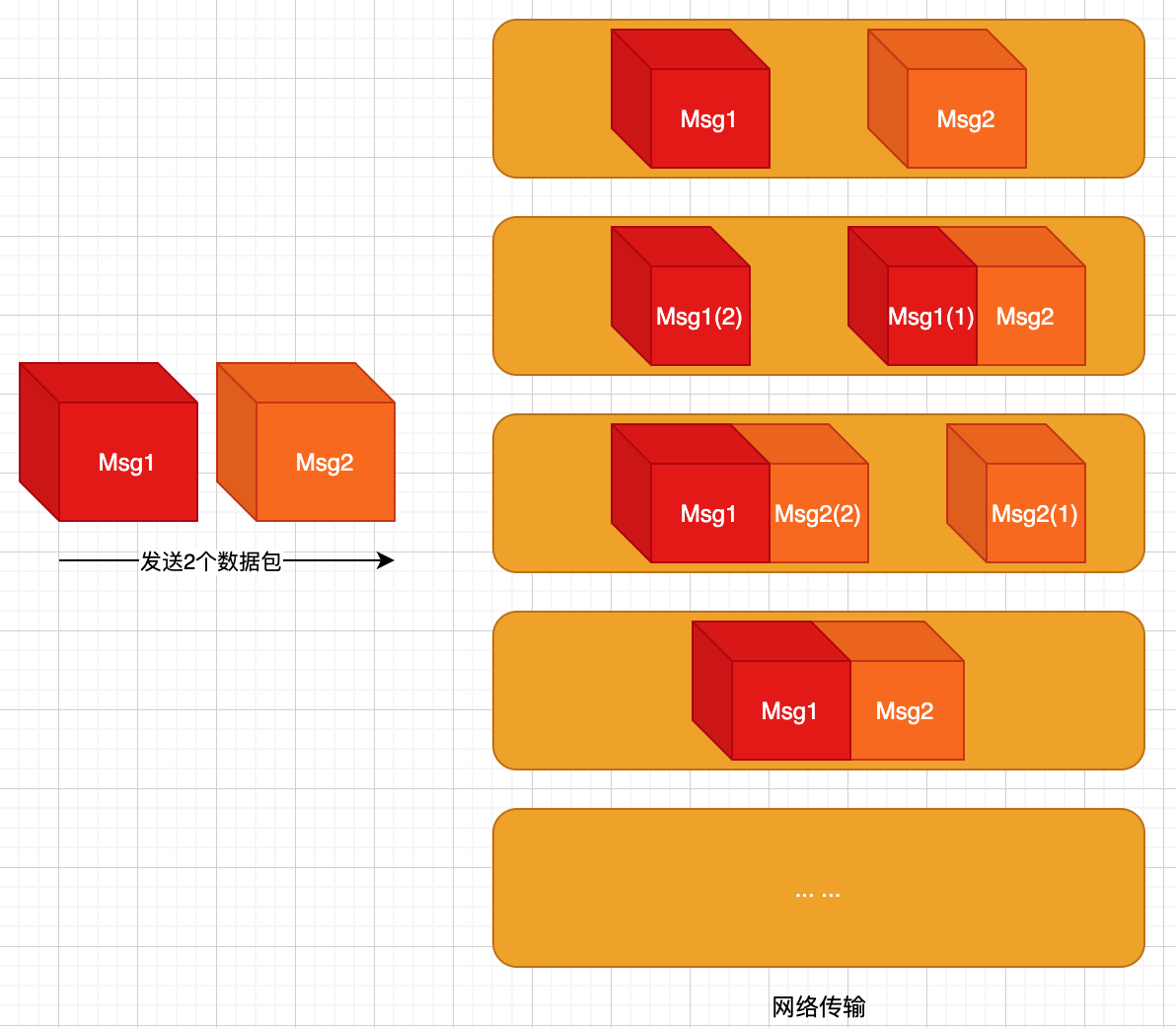
TCP是流式协议,发送的是字节流,当用户态发送2个数据包,进入协议栈后,发送出去的并没有用户视角的那个『逻辑清晰边界分明的数据包』的概念,有的只是一系列的字节流。
TCP能承若的只是,当用户态首先send了一个数据包A,然后send了一个数据包B后,TCP保证在对端协议栈中数据包A里面的字节排在数据包B里面字节的前面,在TCP眼里,没有用户态眼里的那个数据包A、数据包B,TCP眼里有的只是一系列字节。
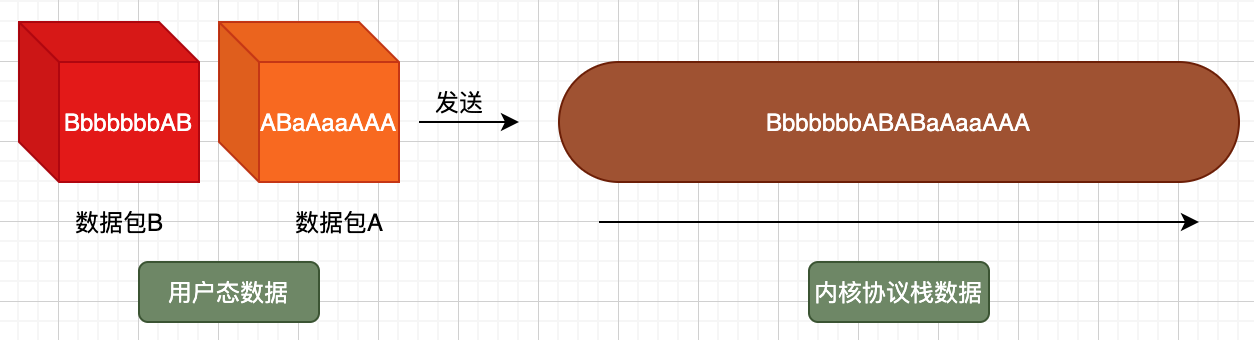
在用户态我们有棱角分明的数据包A、B,但在协议栈中看到的只有字节流,TCP协议并不认识什么数据包A、B,因此当这些字节流传输到对端后,需要用户进程根据逻辑自己将这些数据流重新组装成数据包A、B
第三幅图:
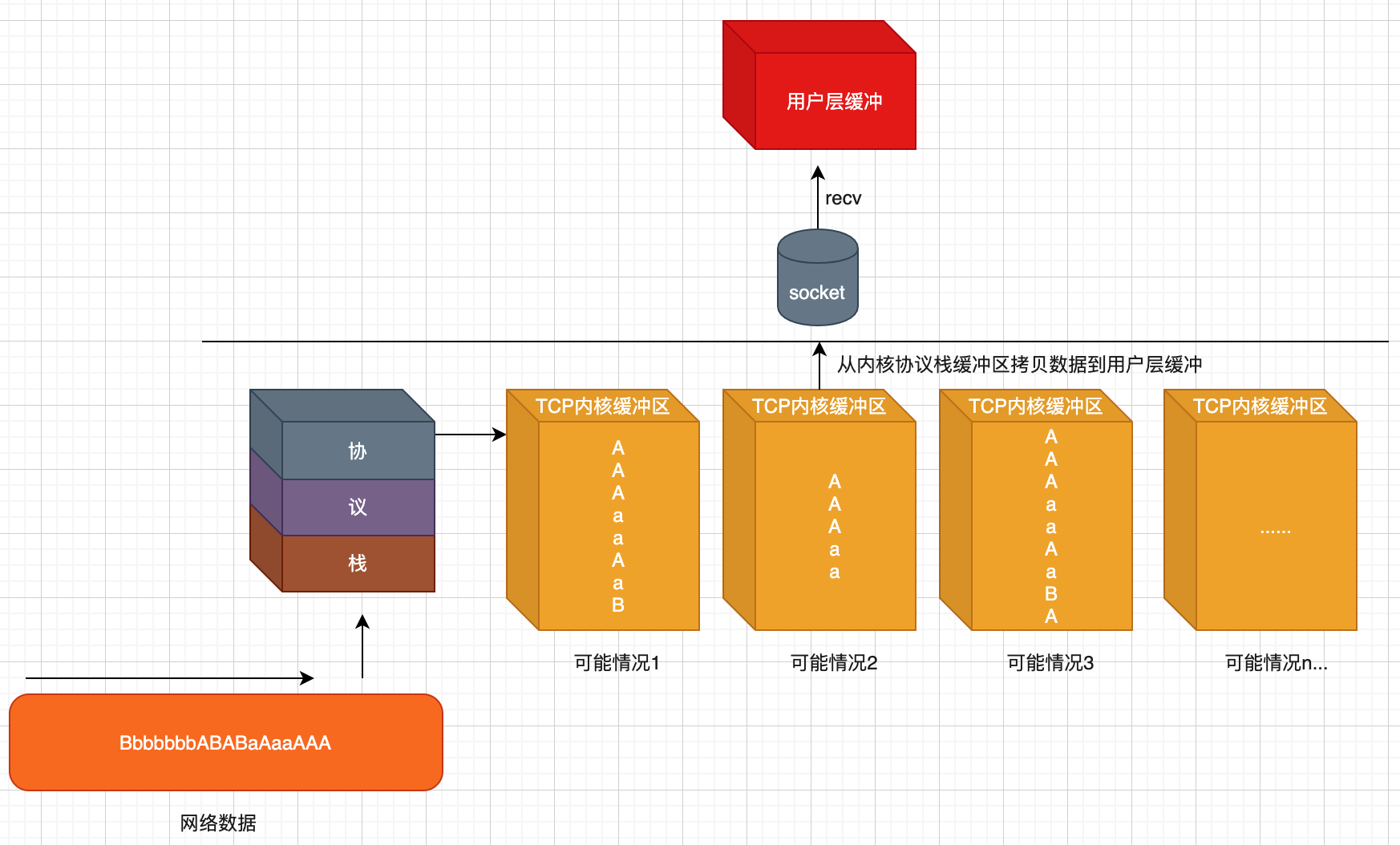
我们接受数据recv发送数据send本质都是在通过socket提供的接口往内核协议栈中的缓冲区中拷贝或写入数据。
读写数据的方式分为
- 阻塞
- 非阻塞
两种方式。当我们使用阻塞的方式recv(读)时,如果内核缓冲区中有数据,那么内核缓冲区中的数据会根据用户所提供的长度拷贝进用户提供的用户缓冲区,然后内核缓冲区清空对应的数据,接着函数返回,使用非阻塞的读时函数会立马返回。
当我们使用阻塞的方式send(写)时,如果内核缓冲区能装得下用户的这些数据,那么将用户提供的数据拷贝进内核协议栈缓冲区,然后立马返回,如果装不下,则能装多少是多少,然后阻塞住send(写)函数,直到用户缓冲区中的数据全部被拷贝进内核协议栈缓冲区。(如果是非阻塞的写,则立马返回,有多少空间就写多少数据)。这个send(写)函数还有一个特性是,当对端TCP退出关闭时,这时候往内核缓冲区中写入数据时会立马返回。写入的数据长度为0,用户层可以根据这个特性判断对端是否断开连接。
根据上面三(四)幅图,我们知道了几件事情:
- TCP保证字节是有序到达的(数据到达对端协议栈后,先发送的字节肯定排在后发送的字节的前面(tcp就干这事的))
- TCP的世界里没有用户眼中的数据包的概念。(TCP不搀和业务逻辑)
- TCP不保证协议栈的缓冲区中有没有数据,有多少数据。
- TCP不保证协议栈的缓冲区能不能写,什么时候能写。
- TCP协议栈不保证数据什么时候发送。(它有自己的发送逻辑,并不代表你send时它就会发送数据出去)
我们在知道了以上几个事实后,应该明白,发送端调用一次send发送10字节接收端调用一次recv接受数据,接受到了几个字节?答案是不知道。尽管极大可能是10字节,但有可能是1字节,有可能是8字节,有可能接受到了20字节(发送端调用了多次send)
此刻,我们似乎明白了所谓TCP是字节流协议到底所谓何事,也明白了在处理数据时遵循处理字节流数据该有的行为准则(不假设肯定读取了多少字节数据),这部分代码我们放在本章下面细节讨论部分。在此之前我需要回答TCP所谓的面向链接协议究竟是什么意思,为了什么,链接在哪里?
我们先来看下网络数据包传输的复杂性:
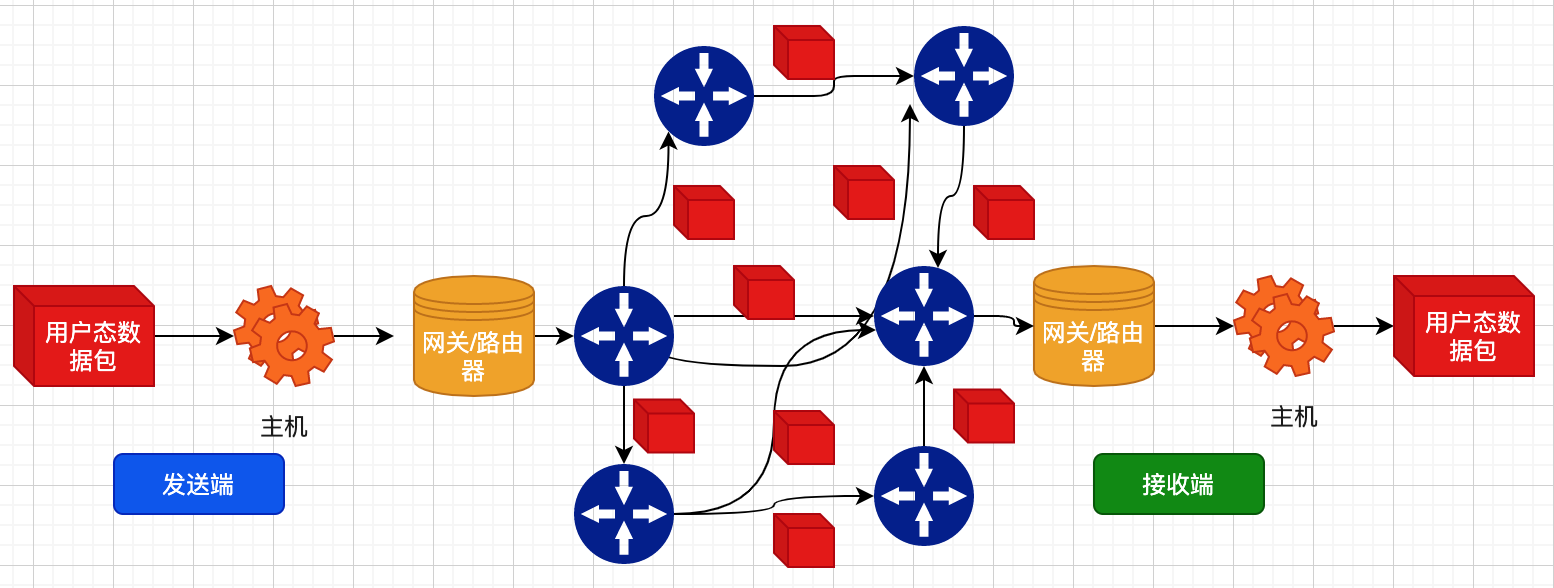
从用户层来讲,理论上用户可以发一个无限大(内存足够)的数据包,但是实际情况是由于通信链路的限制,一个来自用户层的大包会被切分成很多网络上的小包,在对端主机网络协议栈集合。然后拷贝到对端主机的用户层,底层的细节对用户是透明的,在用户态的眼里就是一端发送了一个数据包,另一端接受到了一个数据包。
这是『面向链接』的第一层概念,好像两端主机之间通过了某根通信线路链在一起一样,但实际不是,只是『看起来』这样,是TCP协议的机制才能『看起来』两端直接是有线链接通信一样,这就是面向链接的第一层理解。
而第二层理解则是基于『TCP是怎么让网络上这些小包最终成为一个有序集合的?』
要回答这个问题就要理解TCP是面向链接的第二层概念。

用户数据经过协议栈,被分成了一个个小包。每个小包都被分配了一个『序列号』,就是因为这个序列号的存在,就从逻辑上让一个个这样的小包形成了一个逻辑链路,好像被前后链接起来了一样。
这就是为什么TCP能够让乱序到来的网络数据包在协议栈中恢复有序的秘密所在。
基于序列号,衍生出了一系列操作,无论是超时重传,快速重传,慢启动,接受、发送窗口,滑动窗口等等概念和操作,几乎都是站在数据包序列号的基础上进行的。
谈到TCP,我们总是说诸如三次握手、四次挥手,其实可以是N次握手,M次挥手,这本质是在两端协议栈做状态协商,目的就是在同步双方的序列号(以及一些诸如接收窗口大小信息的互换等)。
所以说,TCP的链接,本质是在两端协议栈里维护了一个对端的协议栈的信息而已,这些信息能够维护数据包的有序到达,完整到达,以及高效到达。
字节流数据的读取方式
//readn.cpp
//从sockfd中读取定长字节流数据的标准方式
int readn(socket fd,char *buf,int bLen){
int needReadLen = bLen;//一共需要读取多少个字节
int recvReadLen = 0;//本次读取了多少个字节
while(needReadLen > 0){//只要需要读取的字节不为0,就一直循环去读
recvReadLen = recv(fd,buf,needReadLen,0);//从协议栈缓存中读取指定长度的内容,当然,并不一定就真的能读到这么多,可能可以,可能不足,到底读了多少,recv函数会返回真实的结果
if(recvReadLen < 0){//如果返回负数,则代表网络出错
return -1;
}
if(recvReadLen == 0){//读取为0 则意味这对端socket关闭
return bLen - needReadLen;//返回真实读取到的数据长度
}
buf += recvReadLen;//往后移动用户缓冲区的首地址指针,每次移动的步幅等于上一次从协议栈缓冲中读取到的数据长度
needReadLen -= recvReadLen;//伴随着每一次成功的读取,最终需要读取的数据越来越少
}
return bLen;//循环退出,读取完毕,返回最终读取到的数据长度
}
上面就是从TCP-socket流中读取指定长度数据的标准写法
//tcp数据流的处理
int main(){
socket client = //...
unsigned int msgLen;
int rc = readn(client,&msgLen,sizeof(unsigned int));
if(rc == sizeof(unsigned int)){//读取成功
//
msgLen = (unsigned int)ntohl(msgLen);//网络字节序转为本地主机字节序
if(msgLen > 0){
//开始读取recLen长度数据...
char *msg[msgLen] = {0};
rc = readn(client,msg,msgLen);//读取指定长度的消息
if(rc == msgLen){
//成功获取用户msg数据包
}else{
//获取失败
}
}
}else{
//读取出错...
}
return 0;
}
所以,TCP数据流的常见操作方法就是先读取一个定长的数据,从定长数据中获取一个完整的用户数据包有多大,然后再次去读取这个用户数据包。(注意本地与网络字节序的转换)
上面的函数工作的很好,但效率上存在一个问题,就是在循环中调用recv函数,这其实是将内核协议栈缓冲中的数据拷贝进用户提供的用户态缓冲中,并且是循环反复的拷贝,这是导致效率低下的根源。
2个思路解决这个问题
- 零拷贝方案(一种设计思路,本章不讲)
- 用户态设计一个大尺寸缓存从协议栈中拷贝数据,再准备一个消息数据缓存,从大尺寸缓存中读取数据
#pragma pack(1)
struct DataHeader{
int dataSize;
short cmd;//消息类型
DataHeader(){
dataSize = sizeof(DataHeader);
cmd = CMD_INIT;
}
};
struct LoginPack:public DataHeader{
char username[32];
char password[32];
char extInfo[32];
LoginPack(){
dataSize = sizeof(LoginPack);
cmd = CMD_LOGIN;
}
};
#pragma pack()
#define RECV_BUFF_SZIE 10240
char _szRecv[RECV_BUFF_SZIE] = {0};//接受缓冲区(从协议栈拷数据出来
char _szMsgBuf[RECV_BUFF_SZIE * 10] = {0};//用户消息(业务)缓冲区
int _lastPos = 0;//缓冲区当前的下标位置
int RecvData(SOCKET cSock){
//从协议栈缓冲区拷贝一大块数据(当然,有可能填不满),这种大缓冲的方式在处理高频大流量数据传输时更显著的提高协议栈效率增加吞吐量,_szRecv用户缓冲区的目的就是尽快清空协议栈缓冲
int nLen = (int)recv(cSock, _szRecv, RECV_BUFF_SZIE, 0);
if (nLen <= 0)//对端断开连接或者网络错误
{
return -1;
}
//从接受缓冲区拷贝数据到用户消息缓冲区
memcpy(_szMsgBuf+_lastPos/*从当前指针位置往后拷贝,一开始下标指针位于数组开头*/, _szRecv, nLen);
_lastPos += nLen;//buf指针往后移动
while (_lastPos >= sizeof(DataHeader)){//如果当前消息缓冲中的数据已足够(至少有一个包头的长度
DataHeader* header = (DataHeader*)_szMsgBuf;//从消息缓冲中获取头部数据
if(_lastPos >= (header->dataSize)){
//用户消息缓冲区没有用到的部分的长度
int nSize = _lastPos - header->dataLength;
//处理消息
handleMsg(header);
//用户消息缓冲区后面的数据往前面移
memcpy(_szMsgBuf, _szMsgBuf + header->dataLength, nSize);
_lastPos = nSize;
}else{
break;
}
}
}
在本章中,我们最后研究了2个议题
- 怎么实现一个定长的TCP数据读取函数
- 怎么提高
recv的性能,提升其吞吐量。
第二个议题采用的是一个大容量的用户区缓冲区,这种方式也可以用来做TCP数据流的拆装工作。
当然,可以将2种方式结合起来使用,设计一个从字节数组中读取定长字节流的函数。
posted on 2021-12-28 09:38 shadow_fan 阅读(90) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号