
HBase(二)CentOS7.5搭建HBase1.2.6HA集群
一、安装前提
1、HBase 依赖于 HDFS 做底层的数据存储
2、HBase 依赖于 MapReduce 做数据计算
3、HBase 依赖于 ZooKeeper 做服务协调
4、HBase源码是java编写的,安装需要依赖JDK
1、版本选择
打开官方的版本说明http://hbase.apache.org/1.2/book.html
JDK的选择
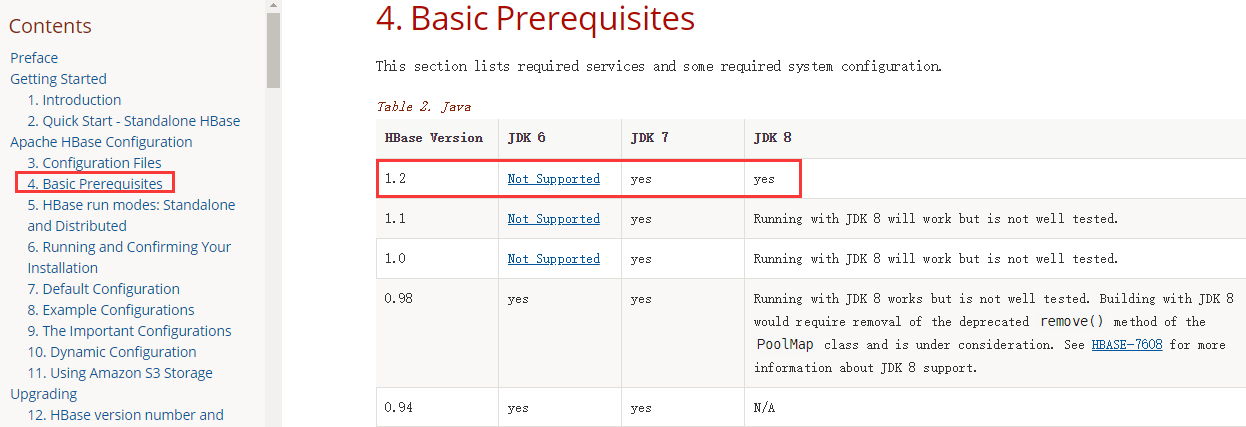
Hadoop的选择

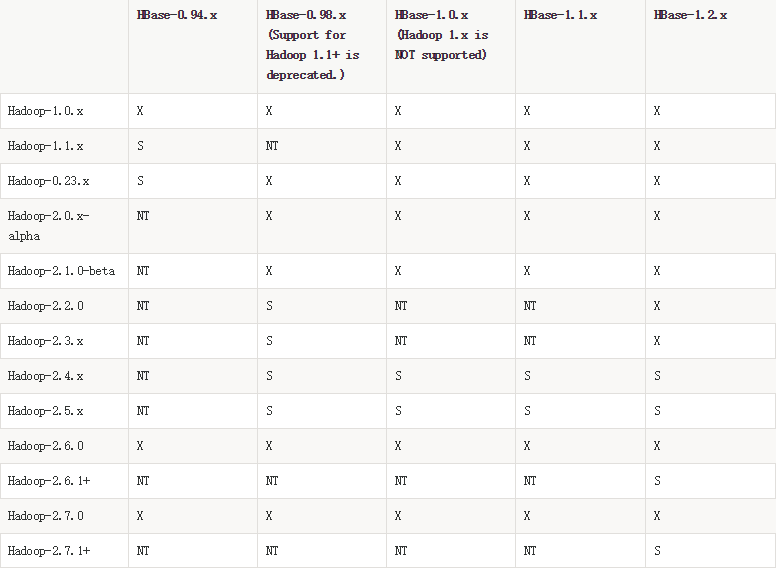
此处我们的hadoop版本用的的是2.7.6,HBase选择的版本是1.2.6
2、下载安装包
官网下载地址:http://archive.apache.org/dist/hbase/

3、完全分布式部署
默认情况下,HBase以独立模式运行。提供独立模式和伪分布模式都是为了进行小规模测试。
对于生产环境,分布式模式是合适的。在分布式模式下,HBase守护程序的多个实例在群集中的多个服务器上运行。
| 节点IP | 节点名称 | Master | BackupMaster | RegionServer | Zookeeper | HDFS |
| 192.168.100.21 | node21 | √ | √ | √ | √ | |
| 192.168.100.22 | node22 | √ | √ | √ | √ | |
| 192.168.100.23 | node23 | √ | √ | √ |
Zookeeper集群安装参考:CentOS7.5搭建Zookeeper3.4.12集群
Hadoop集群安装参考:CentOS7.5搭建Hadoop2.7.6完全分布式集群
二、HBase的集群安装
安装过程参考官方文档:http://hbase.apache.org/1.2/book.html#standalone_dist
1、上传解压缩
解压 HBase 到指定目录:
[admin@node21 software]$ tar zxvf hbase-1.2.6-bin.tar.gz -C /opt/module/
2、修改配置文件
配置文件在/opt/module/hbase-1.2.6/conf目录下
hbase-env.sh 修改内容:
export JAVA_HOME=/opt/module/jdk1.8 export HBASE_MANAGES_ZK=false
hbase-site.xml 修改内容:
<configuration> <property> <name>hbase.rootdir</name> <value>hdfs://mycluster/hbase</value> </property> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> </property> <property> <name>hbase.zookeeper.quorum</name> <value>node21,node22,node23</value> </property> <property> <name>hbase.zookeeper.property.dataDir</name> <value>/opt/module/zookeeper-3.4.12/Data</value> </property> </configuration>
region servers修改内容:
node21
node22
node23
在 conf 目录下创建 backup-masters 文件,添加备机名
$ echo node22 > conf/backup-masters
3、软连接Hadoop配置
[admin@node21 ~]$ ln -s /opt/module/hadoop-2.7.6/etc/hadoop/hdfs-site.xml /opt/module/hbase-1.2.6/conf/
4、替换Hbase依赖的Jar包
由于 HBase 需要依赖 Hadoop,所以替换 HBase 的 lib 目录下的 jar 包,以解决兼容问题:
1) 删除原有的 jar:
[admin@node21 ~]$ rm -rf /opt/module/hbase-1.2.6/lib/hadoop-* [admin@node21 ~]$ rm -rf /opt/module/hbase-1.2.6/lib/zookeeper-3.4.6.jar
2) 拷贝新 jar,涉及的 jar 有:
hadoop-annotations-2.7.6.jar hadoop-mapreduce-client-app-2.7.6.jar hadoop-mapreduce-client-hs-plugins-2.7.6.jar hadoop-auth-2.7.6.jar hadoop-mapreduce-client-common-2.7.6.jar hadoop-mapreduce-client-jobclient-2.7.6.jar hadoop-common-2.7.6.jar hadoop-mapreduce-client-core-2.7.6.jar hadoop-mapreduce-client-shuffle-2.7.6.jar hadoop-hdfs-2.7.6.jar hadoop-mapreduce-client-hs-2.7.6.jar hadoop-yarn-api-2.7.6.jar hadoop-yarn-client-2.7.6.jar hadoop-yarn-common-2.7.6.jar hadoop-yarn-server-common-2.7.6.jar
zookeeper-3.4.12.jar
尖叫提示:这些 jar 包的对应版本应替换成你目前使用的 hadoop 版本,具体情况具体分析。
[admin@node21 ~]$ find /opt/module/hadoop-2.7.6/ -name hadoop-annotations*
然后将找到的 jar 包复制到 HBase 的 lib 目录下即可。
5、分发安装包到其他节点
[admin@node21 ~]$ scp -r /opt/module/hbase-1.2.6/ node22:/opt/module/ [admin@node21 ~]$ scp -r /opt/module/hbase-1.2.6/ node23:/opt/module/
6、配置环境变量
所有服务器都有进行配置
[admin@node21 ~]$ vi /etc/profile
#HBase export HBASE_HOME=/opt/module/hbase-1.2.6 export PATH=$PATH:$HBASE_HOME/bin
使环境变量立即生效
[admin@node21 ~]$ source /etc/profile
7、同步时间
尖叫提示: HBase 集群对于时间的同步要求的比HDFS严格,如果集群之间的节点时间不同步,会导致 region server 无法启动,抛出ClockOutOfSyncException 异常。所以,集群启动之前千万记住要进行 时间同步,要求相差不要超过 30s.
<property> <name>hbase.master.maxclockskew</name> <value>180000</value> <description>Time difference of regionserver from master</description> </property>
三、启动HBase集群
严格按照启动顺序进行
1、启动zookeeper集群
每个zookeeper节点都要执行以下命令
[admin@node21 ~]$ zkServer.sh start
2、启动Hadoop集群
如果需要运行MapReduce程序则启动yarn集群,否则不需要启动
[admin@node21 ~]$ start-dfs.sh
[admin@node22 ~]$ start-yarn.sh
3、启动HBase集群
保证 ZooKeeper 集群和 HDFS 集群启动正常的情况下启动 HBase 集群 启动命令:start-hbase.sh,在哪台节点上执行此命令,哪个节点就是主节点
启动方式 1:
[admin@node21 ~]$ start-hbase.sh starting master, logging to /opt/module/hbase-1.2.6/logs/hbase-admin-master-node21.out node23: starting regionserver, logging to /opt/module/hbase-1.2.6/logs/hbase-admin-regionserver-node23.out node21: starting regionserver, logging to /opt/module/hbase-1.2.6/logs/hbase-admin-regionserver-node21.out node22: starting regionserver, logging to /opt/module/hbase-1.2.6/logs/hbase-admin-regionserver-node22.out node22: starting master, logging to /opt/module/hbase-1.2.6/logs/hbase-admin-master-node22.out
启动方式 2:
$ hbase-daemon.sh start master
$ hbase-daemon.sh start regionserver
观看启动日志可以看到:
(1)首先在命令执行节点启动 master
(2)然后分别在 node21,node22,node23 启动 regionserver
(3)然后在 backup-masters 文件中配置的备节点上再启动一个 master 主进程
尖叫提 示: 如果使用的是 JDK8 以 上 版 本 , 则 应 在 hbase-evn.sh 中 移除 “HBASE_MASTER_OPTS”和“HBASE_REGIONSERVER_OPTS”配置。
4、停止HBase集群
[admin@node21 ~]$ stop-hbase.sh
四、验证启动是否正常
1、检查各进程是否启动正常
主节点和备用节点都启动 hmaster 进程,各从节点都启动 hregionserver 进程,按照对应的配置信息各个节点应该要启动的进程如下所示
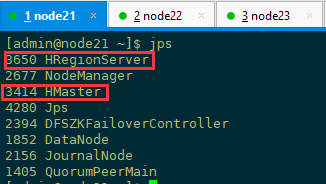
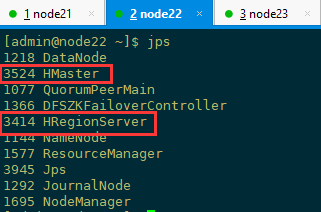
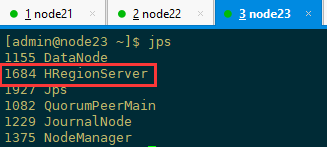
2、通过访问浏览器页面查看
WebUI地址查看:http://node21:16010/master-status
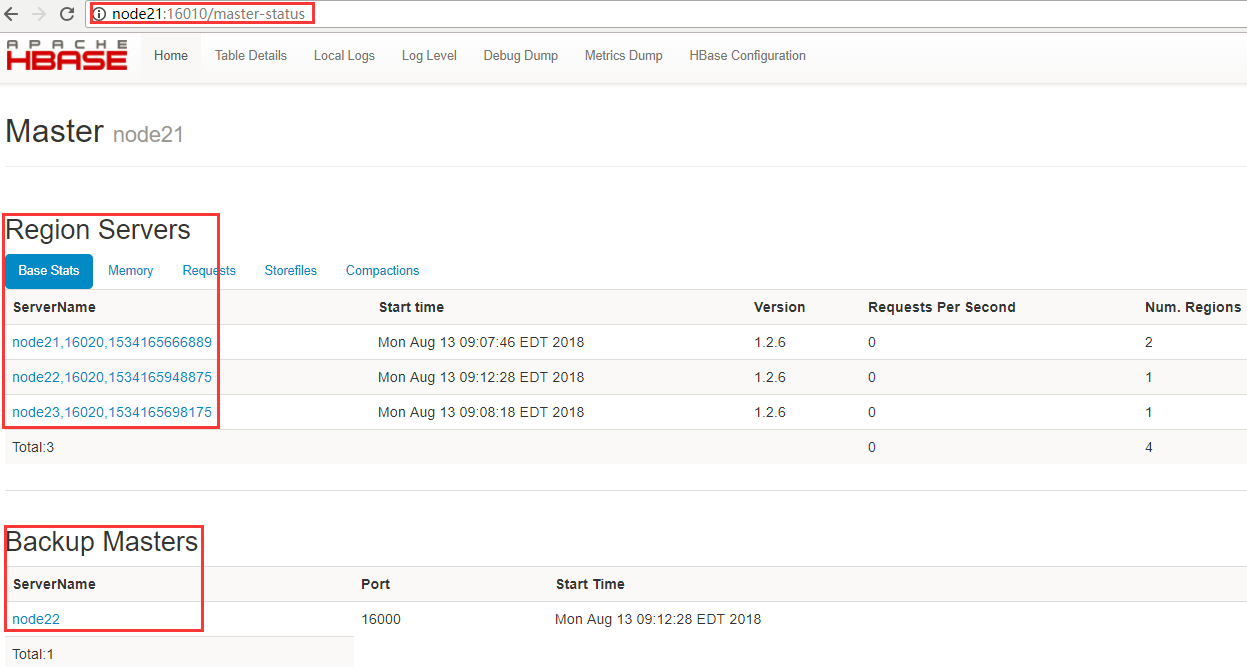
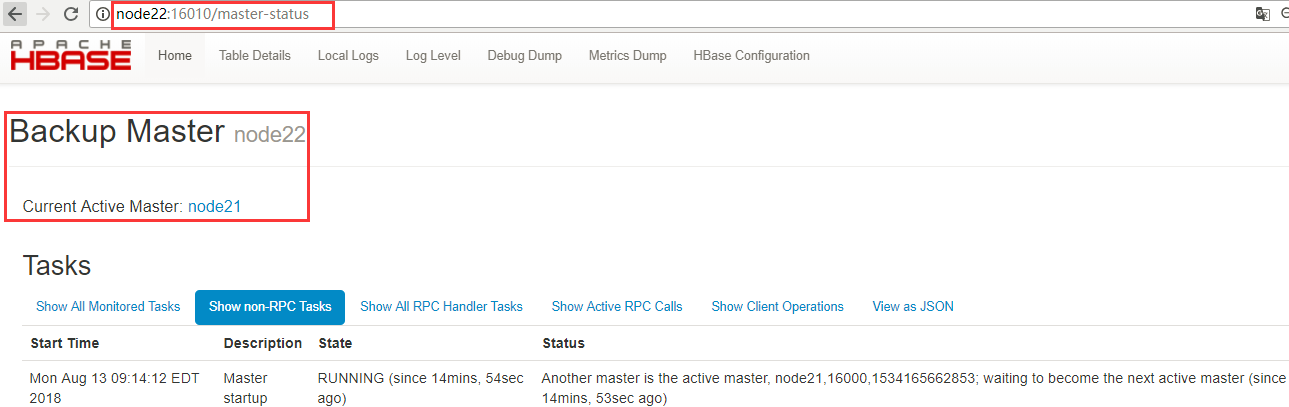
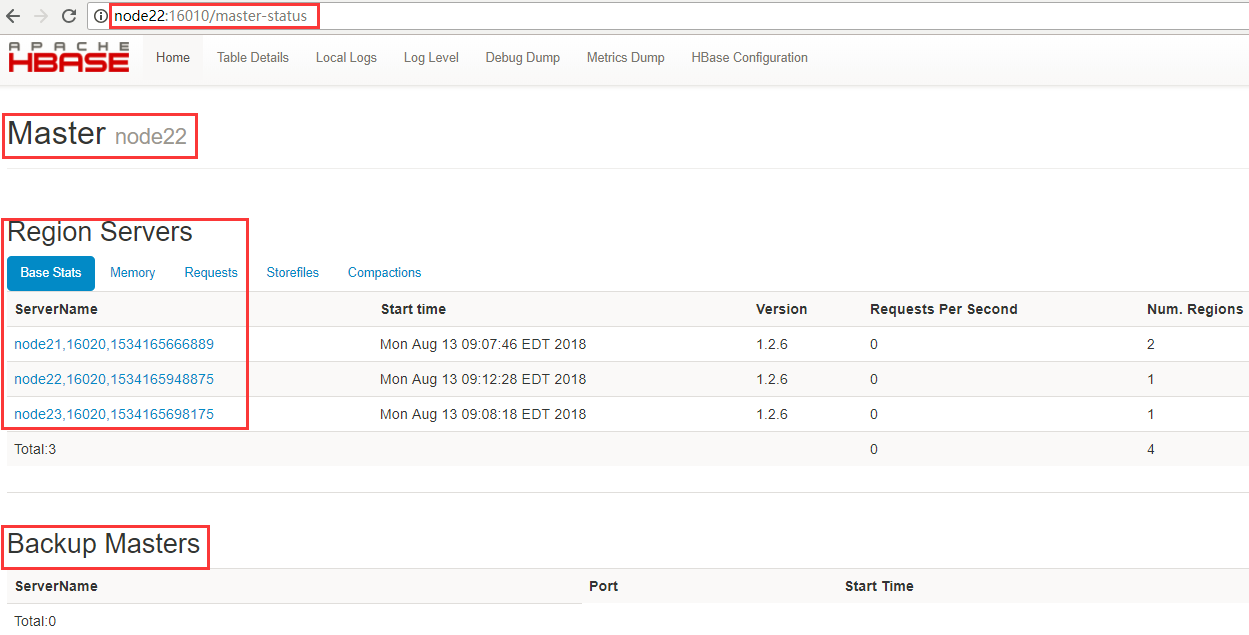
3、验证高可用
干掉node21上的hbase进程,观察备用节点是否启用
[admin@node21 ~]$ kill -9 3414
node21界面访问失败,node22变成主节点
4、手动启动进程
启动HMaster进程,当node21节点上的HMaster进程起来后又会成为备用Master,状态可通过webUI查看。
[admin@node21 ~]$ jps 3650 HRegionServer 2677 NodeManager 2394 DFSZKFailoverController 4442 Jps 1852 DataNode 2156 JournalNode 1405 QuorumPeerMain [admin@node21 ~]$ hbase-daemon.sh start master starting master, logging to /opt/module/hbase-1.2.6/logs/hbase-admin-master-node21.out [admin@node21 ~]$ jps 3650 HRegionServer 2677 NodeManager 4485 HMaster 4630 Jps 2394 DFSZKFailoverController 1852 DataNode 2156 JournalNode 1405 QuorumPeerMain
启动HRegionServer进程
$ hbase-daemon.sh start regionserver

 浙公网安备 33010602011771号
浙公网安备 33010602011771号