
Hive(九)Hive 执行过程实例分析
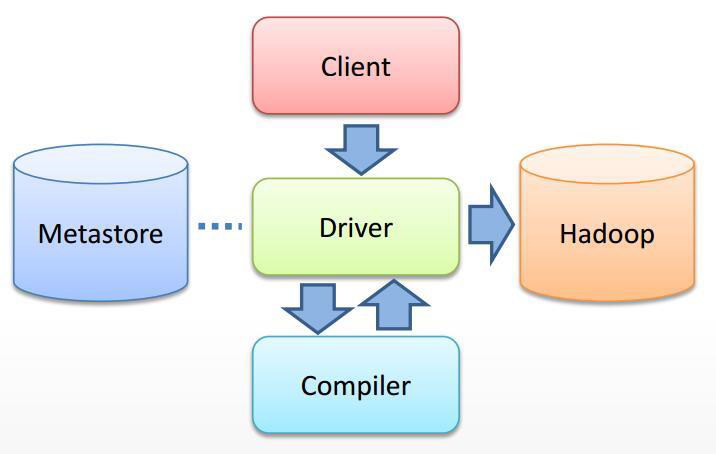
一、Hive 执行过程概述
1、概述
(1) Hive 将 HQL 转换成一组操作符(Operator),比如 GroupByOperator, JoinOperator 等
(2)操作符 Operator 是 Hive 的最小处理单元
(3)每个操作符代表一个 HDFS 操作或者 MapReduce 作业
(4)Hive 通过 ExecMapper 和 ExecReducer 执行 MapReduce 程序,执行模式有本地模式和分 布式两种模式
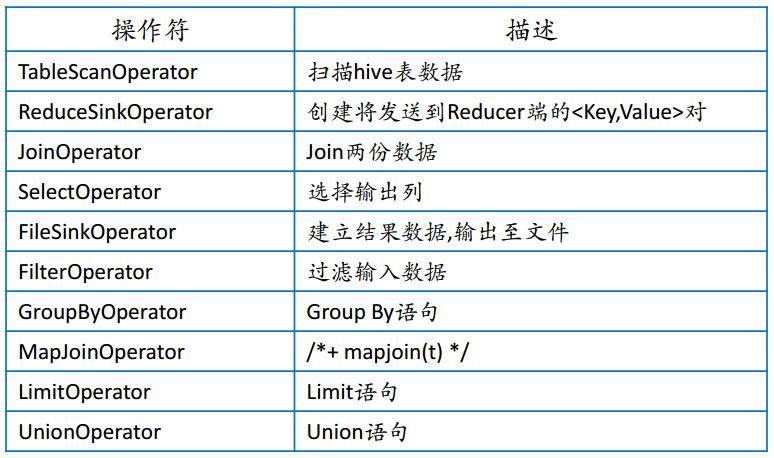
2、Hive 操作符列表
3、Hive 编译器的工作职责
(1)Parser:将 HQL 语句转换成抽象语法树(AST:Abstract Syntax Tree)
(2)Semantic Analyzer:将抽象语法树转换成查询块
(3)Logic Plan Generator:将查询块转换成逻辑查询计划
(4)Logic Optimizer:重写逻辑查询计划,优化逻辑执行计划
(5)Physical Plan Gernerator:将逻辑计划转化成物理计划(MapReduce Jobs)
(6)Physical Optimizer:选择最佳的 Join 策略,优化物理执行计划
4、优化器类型
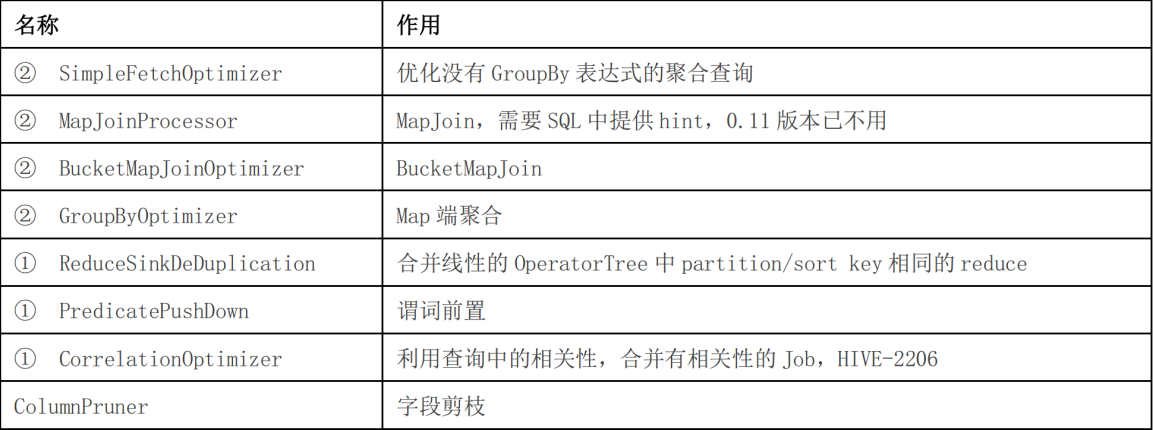
上表中带①符号的,优化目的都是尽量将任务合并到一个 Job 中,以减少 Job 数量,带②的 优化目的是尽量减少 shuffle 数据量
二、join
1、对于 join 操作
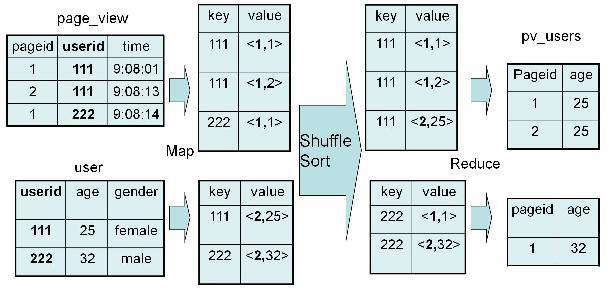
SELECT pv.pageid, u.age FROM page_view pv JOIN user u ON pv.userid = u.userid;
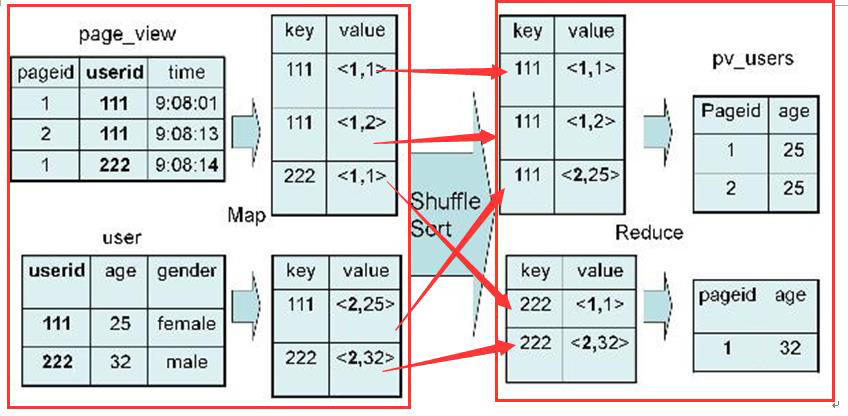
2、实现过程
Map:
1、以 JOIN ON 条件中的列作为 Key,如果有多个列,则 Key 是这些列的组合
2、以 JOIN 之后所关心的列作为 Value,当有多个列时,Value 是这些列的组合。在 Value 中还会包含表的 Tag 信息,用于标明此 Value 对应于哪个表
3、按照 Key 进行排序
Shuffle:
1、根据 Key 的值进行 Hash,并将 Key/Value 对按照 Hash 值推至不同对 Reduce 中
Reduce:
1、 Reducer 根据 Key 值进行 Join 操作,并且通过 Tag 来识别不同的表中的数据
3、具体实现过程
三、Group By
1、对于 group by操作
SELECT pageid, age, count(1) FROM pv_users GROUP BY pageid, age;
2、实现过程
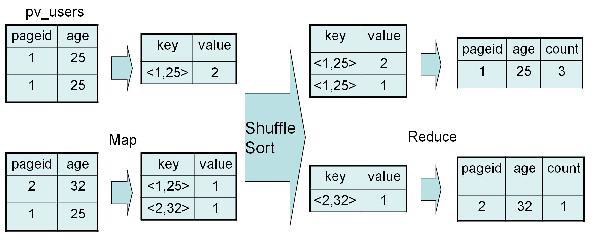
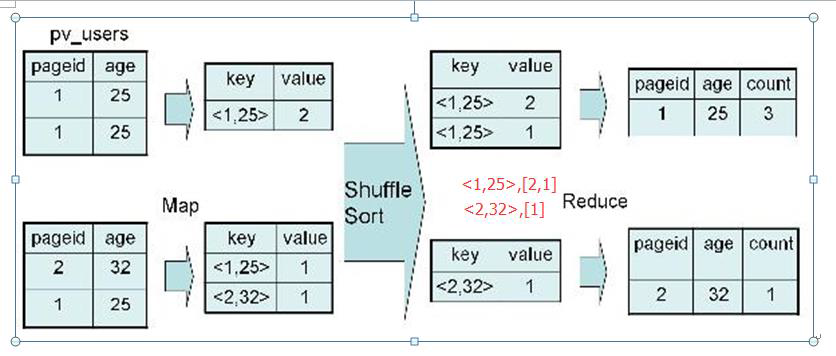
四、Distinct
1、对于 distinct的操作
按照 age 分组,然后统计每个分组里面的不重复的 pageid 有多少个
SELECT age, count(distinct pageid) FROM pv_users GROUP BY age;
2、实现过程
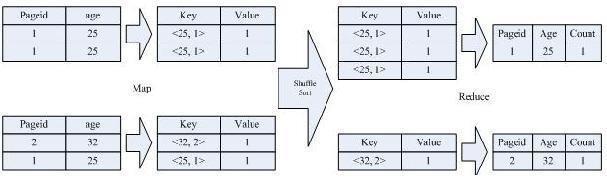
3、详细过程解释
该 SQL 语句会按照 age 和 pageid 预先分组,进行 distinct 操作。然后会再按 照 age 进行分组,再进行一次 distinct 操作

 浙公网安备 33010602011771号
浙公网安备 33010602011771号