
Hadoop案例(十)WordCount
WordCount案例
需求1:统计一堆文件中单词出现的个数(WordCount案例)
0)需求:在一堆给定的文本文件中统计输出每一个单词出现的总次数
1)数据准备:Hello.txt
hello world
dog fish
hadoop
spark
hello world
dog fish
hadoop
spark
hello world
dog fish
hadoop
spark
2)分析
按照mapreduce编程规范,分别编写Mapper,Reducer,Driver。

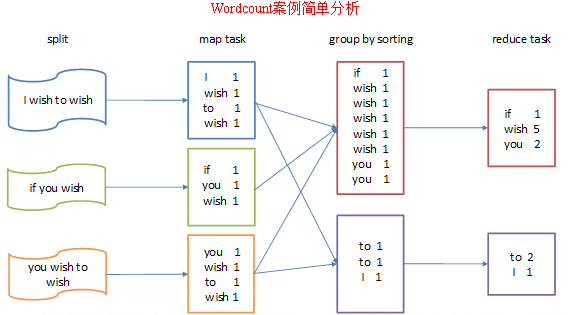
3)编写程序
(1)定义一个mapper类
package com.xyg.wordcount; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; /** * KEYIN:默认情况下,是mr框架所读到的一行文本的起始偏移量,Long; * 在hadoop中有自己的更精简的序列化接口,所以不直接用Long,而是用LongWritable * VALUEIN:默认情况下,是mr框架所读到的一行文本内容,String;此处用Text * KEYOUT:是用户自定义逻辑处理完成之后输出数据中的key,在此处是单词,String;此处用Text * VALUEOUT,是用户自定义逻辑处理完成之后输出数据中的value,在此处是单词次数,Integer,此处用IntWritable * @author Administrator */ public class WordcountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{ /** * map阶段的业务逻辑就写在自定义的map()方法中 * maptask会对每一行输入数据调用一次我们自定义的map()方法 */ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 将maptask传给我们的文本内容先转换成String String line = value.toString(); // 2 根据空格将这一行切分成单词 String[] words = line.split(" "); // 3 将单词输出为<单词,1> for(String word:words){ // 将单词作为key,将次数1作为value,以便于后续的数据分发,可以根据单词分发,以便于相同单词会到相同的reducetask中 context.write(new Text(word), new IntWritable(1)); } } }
(2)定义一个reducer类
package com.xyg.wordcount; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; /** * KEYIN , VALUEIN 对应mapper输出的KEYOUT, VALUEOUT类型 * KEYOUT,VALUEOUT 对应自定义reduce逻辑处理结果的输出数据类型 KEYOUT是单词 VALUEOUT是总次数 */ public class WordcountReducer extends Reducer<Text, IntWritable, Text, IntWritable> { /** * key,是一组相同单词kv对的key */ @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int count = 0; // 1 汇总各个key的个数 for(IntWritable value:values){ count +=value.get(); } // 2输出该key的总次数 context.write(key, new IntWritable(count)); } }
(3)定义一个主类,用来描述job并提交job
package com.xyg.wordcount; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /** * 相当于一个yarn集群的客户端, * 需要在此封装我们的mr程序相关运行参数,指定jar包 * 最后提交给yarn * @author Administrator */ public class WordcountDriver { public static void main(String[] args) throws Exception { // 1 获取配置信息,或者job对象实例 Configuration configuration = new Configuration(); // 8 配置提交到yarn上运行,windows和Linux变量不一致 // configuration.set("mapreduce.framework.name", "yarn"); // configuration.set("yarn.resourcemanager.hostname", "node22"); Job job = Job.getInstance(configuration); // 6 指定本程序的jar包所在的本地路径 // job.setJar("/home/admin/wc.jar"); job.setJarByClass(WordcountDriver.class); // 2 指定本业务job要使用的mapper/Reducer业务类 job.setMapperClass(WordcountMapper.class); job.setReducerClass(WordcountReducer.class); // 3 指定mapper输出数据的kv类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); // 4 指定最终输出的数据的kv类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); // 5 指定job的输入原始文件所在目录 FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // 7 将job中配置的相关参数,以及job所用的java类所在的jar包, 提交给yarn去运行 // job.submit(); boolean result = job.waitForCompletion(true); System.exit(result?0:1); } }
4)集群上测试
(1)将程序打成jar包,然后拷贝到hadoop集群中。
(2)启动hadoop集群
(3)执行wordcount程序
[admin@node21 module]$ hadoop jar wc.jar com.xyg.wordcount.WordcountDriver /user/admin/input /user/admin/output
5)本地测试
(1)在windows环境上配置HADOOP_HOME环境变量。
(2)在eclipse上运行程序
(3)注意:如果eclipse打印不出日志,在控制台上只显示
1.log4j:WARN No appenders could be found for logger (org.apache.hadoop.util.Shell).
2.log4j:WARN Please initialize the log4j system properly.
3.log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
需要在项目的src目录下,新建一个文件,命名为“log4j.properties”,在文件中填入
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
需求2:把单词按照ASCII码奇偶分区(Partitioner)
0)分析

1)自定义分区
package com.xyg.mapreduce.wordcount; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Partitioner; public class WordCountPartitioner extends Partitioner<Text, IntWritable>{ @Override public int getPartition(Text key, IntWritable value, int numPartitions) { // 1 获取单词key String firWord = key.toString().substring(0, 1); char[] charArray = firWord.toCharArray(); int result = charArray[0]; // int result = key.toString().charAt(0); // 2 根据奇数偶数分区 if (result % 2 == 0) { return 0; }else { return 1; } } }
2)在驱动中配置加载分区,设置reducetask个数
job.setPartitionerClass(WordCountPartitioner.class);
job.setNumReduceTasks(2);
需求3:对每一个maptask的输出局部汇总(Combiner)
0)需求:统计过程中对每一个maptask的输出进行局部汇总,以减小网络传输量即采用Combiner功能。

1)数据准备:hello,txt
方案一
1)增加一个WordcountCombiner类继承Reducer
package com.xyg.mr.combiner; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class WordcountCombiner extends Reducer<Text, IntWritable, Text, IntWritable>{ @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int count = 0; for(IntWritable v :values){ count += v.get(); } context.write(key, new IntWritable(count)); } }
2)在WordcountDriver驱动类中指定combiner
//9 指定需要使用combiner,以及用哪个类作为combiner的逻辑 job.setCombinerClass(WordcountCombiner.class);
方案二
1)将WordcountReducer作为combiner在WordcountDriver驱动类中指定
//9 指定需要使用combiner,以及用哪个类作为combiner的逻辑 job.setCombinerClass(WordcountReducer.class);
运行程序

需求4:大量小文件的切片优化(CombineTextInputFormat)
0)需求:将输入的大量小文件合并成一个切片统一处理。
1)输入数据:准备5个小文件
2)实现过程
(1)不做任何处理,运行需求1中的wordcount程序,观察切片个数为5

(2)在WordcountDriver中增加如下代码,运行程序,并观察运行的切片个数为1
// 如果不设置InputFormat,它默认用的是TextInputFormat.class
job.setInputFormatClass(CombineTextInputFormat.class);
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);// 4m
CombineTextInputFormat.setMinInputSplitSize(job, 2097152);// 2m


 浙公网安备 33010602011771号
浙公网安备 33010602011771号