
CentOS7.5安装MongoDB4.0与CRUD基本操作
一 MongoDB简介
- MongoDB 是一个基于分布式文件存储的数据库。由 C++ 语言编写。旨在为 WEB 应用提供可扩展的高性能数据存储解决方案。
- MongoDB 是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。
- MongoDB中的记录是一个文档,它是由字段和值对组成的数据结构。MongoDB文档类似于JSON对象。字段的值可以包括其他文档,数组和文档数组。
二 MongoDB下载安装
2.1 下载地址:
https://www.mongodb.com/download-center?jmp=nav#community
- MongoDB的版本偶数版本为稳定版,奇数版本为开发版。
- MongoDB对于32位系统支持不佳,所以3.2版本以后没有再对32位系统的支持。
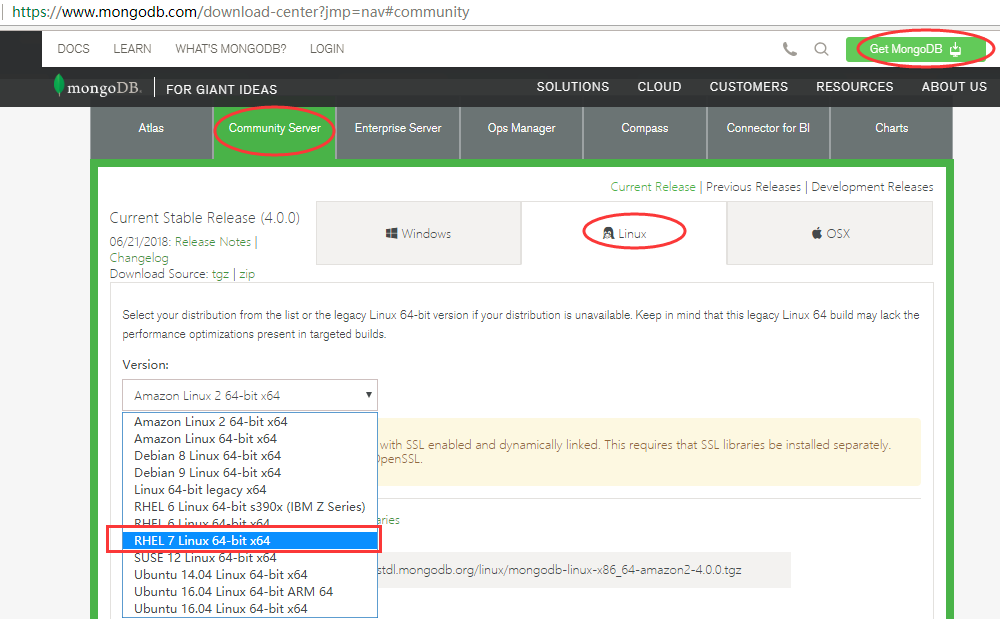
2.2 下载安装
下载完安装包,并解压 tgz(以下演示的是 64 位 Linux上的安装) 。
curl -O https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-rhel70-4.0.0.tgz # 下载 tar -zxvf mongodb-linux-x86_64-rhel70-4.0.0.tgz # 解压 mv mongodb-linux-x86_64-rhel70-4.0.0 /usr/local/mongodb # 将解压包拷贝到指定目录
MongoDB 的可执行文件位于 bin 目录下,所以可以将其添加到 PATH 路径中:
export PATH=<mongodb-install-directory>/bin:$PATH
<mongodb-install-directory> 为你 MongoDB 的安装路径。如本文的 /usr/local/mongodb 。
2.3 bin目录结构
bsondump: binary-json,二进制文件,选择性导出bson文件
mongo: 客户端
mongod: 服务端
mongodump: 整体导出数据库(二进制)
mongoexport:导出易识别的json文档
mongoimport:导入json文档
mongorestore:数据库整体导入
mongos: 路由器(分片)
2.4 创建数据库目录
MongoDB的数据存储在data目录的db目录下,但是这个目录在安装过程不会自动创建,所以你需要手动创建data目录,并在data目录中创建db目录。
以下实例中我们将data目录创建于MongoDB安装目录下。
注意:/data/db 是 MongoDB 默认的启动的数据库路径(--dbpath)。
[root@node21 mongodb]$ mkdir -p data
[root@node21 mongodb]$ mkdir -p log/mongodb.log
2.5 运行 MongoDB 服务
你可以再命令行中执行mongo安装目录中的bin目录执行mongod命令来启动mongdb服务。 注意:如果你的数据库目录不是/data/db,可以通过 --dbpath 来指定。
[root@node21 mongodb]$ ./bin/mongod --dbpath ./data/ --logpath ./log/mongodb.log --port 27017 --fork
参数解释: dbpath 数据存储目录 logpath 日志存储文件 port 运行端口(默认27017) fork 后台静默运行
查看MongoDB运行进程
[root@node21 mongodb]# ps aux |grep mongod
2.6 后台管理 Shell
如果你需要进入MongoDB后台管理,你需要先打开mongodb装目录的下的bin目录,然后执行mongo命令文件。MongoDB Shell是MongoDB自带的交互式Javascript shell,用来对MongoDB进行操作和管理的交互式环境。当你进入mongoDB后台后,它默认会链接到 test 文档(数据库): $ cd /usr/local/mongodb
[root@node21 mongodb]# ./bin/mongo MongoDB shell version v4.0.0 connecting to: mongodb://127.0.0.1:27017 MongoDB server version: 4.0.0 Welcome to the MongoDB shell.
...
2.7 基本概念解释
|
MongoDB术语/概念 |
解释/说明 |
|
database |
数据库 |
|
collection |
数据库表/集合 |
|
document |
数据记录行/文档 |
|
field |
数据字段/域 |
|
index |
索引 |
|
primary key |
主键,MongoDB自动将_id字段设置为主键 |
2.8 Shell help 帮助解释
|
参数 |
说明 |
|
--help –h |
返回基本帮助和用法文本 |
|
--version |
返回MongoDB的版本 |
|
--config<文件名> -f<文件名> |
指定包含运行时配置的配置文件 |
|
--verbose -v |
增加发送到控制台日志的数量 |
|
--quiet |
减少发送到控制台日志的数量 |
|
--port<端口> |
指定mongod的端口,默认27017 |
|
--bind_ip<端口> |
指定id地址 |
|
--maxConns<编号> |
指定链接的最大数 |
|
--logpath<路径> |
指定日志文件的路径 |
|
--auth |
启用远程主机的身份验证 |
|
--dbpath<路径> |
指定数据库实例的路径 |
|
--nohttpinterface |
禁用HTTP接口 |
|
--nojournal |
禁用日志 |
|
--noprealloc |
禁止预分配数据文件 |
|
--repair |
在所有数据库上运行修复程序 |
2.9 MongoDB 数据类型
下表为MongoDB中常用的几种数据类型。
| 数据类型 | 描述 |
|---|---|
| String | 字符串。存储数据常用的数据类型。在 MongoDB 中,UTF-8 编码的字符串才是合法的。 |
| Integer | 整型数值。用于存储数值。根据你所采用的服务器,可分为 32 位或 64 位。 |
| Boolean | 布尔值。用于存储布尔值(真/假)。 |
| Double | 双精度浮点值。用于存储浮点值。 |
| Min/Max keys | 将一个值与 BSON(二进制的 JSON)元素的最低值和最高值相对比。 |
| Array | 用于将数组或列表或多个值存储为一个键。 |
| Timestamp | 时间戳。记录文档修改或添加的具体时间。 |
| Object | 用于内嵌文档。 |
| Null | 用于创建空值。 |
| Symbol | 符号。该数据类型基本上等同于字符串类型,但不同的是,它一般用于采用特殊符号类型的语言。 |
| Date | 日期时间。用 UNIX 时间格式来存储当前日期或时间。你可以指定自己的日期时间:创建 Date 对象,传入年月日信息。 |
| Object ID | 对象 ID。用于创建文档的 ID。 |
| Binary Data | 二进制数据。用于存储二进制数据。 |
| Code | 代码类型。用于在文档中存储 JavaScript 代码。 |
| Regular expression | 正则表达式类型。用于存储正则表达式。 |
ObjectId 类似唯一主键,可以很快的去生成和排序,包含 12 bytes,含义是:
- 前 4 个字节表示创建 unix时间戳,格林尼治时间 UTC 时间,比北京时间早了 8 个小时
- 接下来的 3 个字节是机器标识码
- 紧接的两个字节由进程 id 组成 PID
- 最后三个字节是随机数

MongoDB 中存储的文档必须有一个 _id 键。这个键的值可以是任何类型的,默认是个 ObjectId 对象
由于 ObjectId 中保存了创建的时间戳,所以你不需要为你的文档保存时间戳字段,你可以通过 getTimestamp 函数来获取文档的创建时间:
> var newObject = ObjectId()
> newObject.getTimestamp()
ISODate("2018-07-05T07:21:10Z")
ObjectId 转为字符串
> newObject.str
5a1919e63df83ce79df8b38f
三 Mongodb入门命令
3.1 基本查看命令
show dbs 查看当前的数据库
use databaseName 选库
show tables/collections 查看当前库下的collection
3.2 库和集合的操作
db 查看当前所处的数据库,在mongodb中,库是隐式创建,你可以use 一个不存在的库, 然后在该库下创建collection,即可创建库
db.dropDatabase(); 删除database,把当前所用的库给删除了, 即使里面有数据也会删除
db.createCollection(‘collectionName’), 创建collection,collection也是允许隐式创建的
db.collectionName.insert(document); 在集合(表)中插入具体数据的时候会自动创建
db.collectionName.drop() , 删除collection
测试隐式创建:往不存在的students表中插入数据
> show dbs admin 0.000GB config 0.000GB local 0.000GB > use admin switched to db admin > db.students.insert({name:'zhangsan',age:'20'}) WriteResult({ "nInserted" : 1 }) > show tables students
删除当前库里的students表
> db. students. drop()
true
四 Mongodb基本增删改查
4.1 增加数据
mongodb存储的是文档,文档是json格式的对象,我们向数据库存储数据的时候可以使用insert方法,数据格式要以js对象格式进行存储:
语法:db.collectionName.insert(document);
db.students.insert({name:'zhangsan',age:'20'}) 向当前students表里插入数据
我们可以以多种方法对文档进行存储:
4.1.2 增加单篇文档
语法:db.collectionName.insert({title:"nice day"});
4.1.3 增加单个文档,并且指定_id
语法:db.collectionName.insert({_id:8,age:78,name:"lisi"});
_id 是我们在插入数据的时候,mongodb自动给文档添加的一个属性,如果我们不需要系统分配_id ,可以在添加数据的时候手动设置,覆盖原有_id ,虽然_id 的类型可以自由指定,但是在同一个集合当中必须唯一,如果插入重复的值,系统会抛出异常.
这个_id 的名称是固定的,它可以是Mongodb支持的任何数据类型,默认是ObjectId,在关系型数据库中,主键通常是数值型的,并且可以设置自增,而Mongodb的主键,原生不支持自增主键.
4.1.4 增加多个文档
db.students.insert( [{time:'friday',value:'mongodb'},{_id:1,gender:'male',name:'QQ'}])
可以以数组的方式,一次性向集合插入多个数据; 同时应该注意的是,由于mongodb采用的是JavaScript Shell,所以我们可以根据js特性,将文档作为值赋给变量然后进行操作:
j = {name : 'isi'};
t = {name : 'wangwu’};
db.students.insert([j,t]);
4.1.5 save和insert的区别
save和insert都可以进行数据的插入和增加,但是也有一些异同:
对于已存在数据{ _id:1, "name":"n1" },再次进行插入操作时,insert({_id : 1, "name" :"n2"}) 会报主键重复的错误提示 save({ _id:1, " name ":"n2"}) 会把n1修改为n2。
相同点:若新增的数据中没有主键时,会增加一条记录。
不同点:主键冲突时:insert 会报错,save会自增_i d 主键插入
4.2 查询操作
4.2.1 find()
无条件的普通查询方式很简单,可以直接使用
db.collectionName.find();一次可以查出指定集合中的所有数据
for(var i = 1;1<5;i++) { db.students.save({x:i,y:i+1}) } db.students.find();
如果出现显示不全的现象,可以使用"it"命令,继续显示下面的数据. 当然,我们还可以按照条件进行查询操作
语法: db.collection.find(查询表达式,查询的列);
例1: db.students.find({},{gendre:1})
查询所有文档,的gender属性 (_id属性默认总是查出来)
例2: db.students.find({},{gender:1, _id:0})
查询所有文档的gender属性,且不查询_id属性
此处的0表示的是false,不查询
例3: db.students.find({gender:’male’},{name:1,_id:0});
查询所有gender属性值为male的文档中的name属性
4.2.2 findOne()
findOne()和find()函数一样,只是findOne()返回的是查询结果中的第一条数据,或者返回null.
4.3 删除操作
语法: db.collectionName.remove(查询表达式, 选项);
选项是指 {justOne:true/false},是否只删一行, 默认为false 注意
1: 查询表达式依然是个json对象
2: 查询表达式匹配的行,将被删掉.
3: 如果查询表达式为空对象{},collections中的所有文档将被删掉.
例1: db.students.remove({sn:'001'});
删除stu表中sn属性值为'001'的文档
例2: db.students.remove({gender:'m'},true);
删除stu表中gender属性为m的文档,只删除1行.
4.4 修改操作
语法: db.collection.update(查询表达式,新值,选项);
*改哪几行? --- 查询表达式 *改成什么样? -- 新值 或 赋值表达式 *操作选项 ----- 可选参数 upsert:如果要更新的那条记录没有找到,是否插入一条新纪录,默认为false
multi :是否更新满足条件的多条的记录,默认为false
multi :是否更新满足条件的多条的记录,false:只更新第一条,true:更新多条,默认为false
例:db.news.update({name:'QQ'},{name:'MSN'});
是指选中news表中,name值为QQ的文档,并把其文档值改为{name:"MSN"},
结果: 文档中的其他列也不见了,改后只有_id和name列了.即是新文档直接覆盖了旧文档,而不是修改.
4.4.1 修改操作中的关键字
如果是想修改文档的某列,可以用$set关键字
例:db.collectionName.update(query,{$set:{name:’QQ’}})
修改时的赋值表达式
- $set 修改某列的值
- $unset 删除某个列
- $inc 增长某个列
- $rename 重新命名某列
- $setOnInsert 当upsert为true时,并且发生了insert操作时,可以补充的字段.
$inc实例
按照指定的步长增长某个列;
> db.students.insert({"uid":"201203","type":"1",size:10})
> db.students.find()
{ "_id" : ObjectId("5003b6135af21ff428dafbe6"), "uid" : "201203", "type" : "1", "size" : 10 }
> db.students.update({"uid" : "201203"},{"$inc":{"size" : 2}})
> db.stdentsu.find()
{ "_id" : ObjectId("5003b6135af21ff428dafbe6"), "uid" : "201203", "type" : "1", "size" : 12 }
$unset实例
>db.students.find({_id:3})
{"_id" : 3 , "age" : 18}
> db.students.update({_id:3},{$unset:{age:'sss'}})
WriteResult({ "nMatched" : 0, "nUpserted" : 0, "nModified" : 0 })
> db.students.update({_id:3},{$unset:{age:'sss'}})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
> db.students.find({_id:3})
{ "_id" : 3 }
$rename实例
->db.students.insert({name:'lisi',age:12,sex:'male',height:123,area:'haidian'});
->db.students.update({name:'lisi'},{$set:{area:'chaoyang'},$unset:{height:1},$inc:{age:1},$rename:{sex:'gender'}});
4.4.2 Option选项的作用
语法: {upsert:true/false,multi:true/false}
upsert:是指没有匹配的行,则直接插入该行
例:db.stu.update({name:'wuyong'},{$set:{name:'junshiwuyong'}},{upsert:true});
如果有name='wuyong'的文档,将被修改,如果没有,将添加此新文档
例:db.news.update({_id:99},{x:123,y:234},{upsert:true});
没有_id=99的文档被修改,因此直接插入该文档
multi: 是指修改多行(即使查询表达式命中多行,默认也只改1行,如果想改多行,可以用此选项)
例:db.news.update({age:21},{$set:{age:22}},{multi:true});
则把news中所有age=21的文档,都修改
4.5 查询表达式
我们无论在修改删除还是查询的过程中,都需要传入查询表达式对目标数据进行查询,表达式有很多种
1: 最简单的查询表达式 {filed:value} ,是指查询field列的值为value的文档 2: $ne:!= {field:{$ne:value}} db.stu.find({age:{$ne:16}}) 作用--查age列的值 不等于16的文档 3:$gt:大于 $lt:小于 $gte:大于或等于 $lte:小于或等于 4: $in:[] 查询某列的值在范围内的文档 db.goods.find({cat_id:{$in:[2,8]}} 5: $nin:not in 查询某列不在范围内的文档 $nin:[2,3,5] 6: $exists 语法: {field:{$exists:1}} 作用: 查询出含有field字段的文档 7:用正则表达式查询 以”诺基亚”开头的商品 例:db.goods.find({goods_name:/诺基亚.*/},{goods_name:1});
五 游标操作
通俗的说,游标不是查询结果,而是查询的返回资源,或者接口,通过这个接口,你可以逐条对数据进行读取;
声明游标:
var cursor = db.collectioName.find(query,projection);
cursor.hasNext() //判断游标是否已经取到尽头
cursor.next() //取出游标的下1个单元
用while来循环游标
> var mycursor = db.bar.find({_id:{$lte:5}}) > while(mycursor.hasNext()) { printjson(mycursor.next());}
游标还有一个迭代函数,允许我们自定义回调函数来逐个处理每个单元.
cursor.forEach(回调函数); > var gettitle = function(obj) {print(obj.goods_name)} > var cursor = db.goods.find(); > cursor.forEach(gettitle);
游标在分页中的应用
比如查到10000行,跳过100页,取10行,一般地,我们假设每页N行, 当前是page页,就需要跳过前 (page-1)*N 行, 再取N行.
在mongo中,分页是用skip(), limit()函数来实现的
//查询结果中,跳过前9995行 var mycursor = db.bar.find().skip(9995); //查询第901页,每页10条 则是 var mytcursor = db.bar.find().skip(9000).limit(10);
六 group分组
mongodb支持聚合运算;
在goods表中插入数据
db.goods.insert([ {'_id':3,'cat_id':6,'price':29}, {'_id':4,'cat_id':7,'price':30}, {'_id':5,'cat_id':6,'price':31}, {'_id':6,'cat_id':7,'price':32}, {'_id':7,'cat_id':7,'price':28}, ])
如果我们所处的是mysql数据库,我们可以这样查询每个类下面的商品平均价格
select avg(price) from goods group by cat_id;
但如果在mongodb下,我们如何查询分组内的平均值呢? 我们需要使用mongodb的聚合运算 https://docs.mongodb.com/manual/aggregation/
db.goods.aggregate([ {$match:{}}, {$group:{_id:"$cat_id",avg:{$avg:'$price'}}} ]);
其中,$match表示匹配的条件,$group表示分组的条件,$avg表示求平均值. 当然,指令还有很多,我们还可以使用limit,sort等操作
db.goods.aggregate([ {$match:{}}, {$group:{_id:"$cat_id",avg:{$avg:'$price'}}}, {$limit:1} ]); db.goods.aggregate([ {$match:{}}, {$sort:{price:-1}} ]);
七 MapReduce
7.1 MapReduce原理
随着大数据兴起,MapReduce的概念也越来越火,通常的概念是用于大规模数据集(1TB)的并行运算,实际上就是传统关系型数据库的group概念的延伸.
MapReduce之所以能够流行,是因为数据的大,当数据过大的时候,单个服务器无法承载,facebook,微软等等的数据中心都是分布在世界各地的,我们所需 要的数据很可能分布在不同的服务器甚至世界各地.在这时候,我们就无法使用group操作了.
MapReduce通俗的讲,最大的优点就是可以支持分布式的group
而MapReduce的操作即分为map和reduce两步;
map ---> 映 射
reduce ---> 减少,规约,回归
7.2 MapReduce统计价格
//按照cat_id 分配 price,把price数据映射到一个数组上 var map = function(){ emit(this.cat_id , this.price) } //将映射好的数组进行操作 var reduce = function(cat_id,number){ return Array.avg(number) } //将统计的数据映射到res表当中db.goods.mapReduce(map,reduce,{out:'res'})
接下来我们使用mapReduce功能实现地震数据的统计
7.3 下载并导入地震信息
在国家地震科学数据共享中心下载过去一年的地震数据 http://data.earthquake.cn/sjfw/index.html?PAGEID=datasourcelist&dt=40280d0453e414e40153e44861dd0003
将数据保存为csv格式,导入到mongodb数据库中,使用mongoimport
-d : 指明导入文件存放在哪个数据库
-c : 指明导入文件存放在哪个集合
--type:指明要导入的文件格式。
--headerline:指明不导入第一行,csv格式的文件第一行为列名。
--file:指明要导入的文件路径。
./bin/mongoimport -d test -c dz --type csv --file /usr/local/src/dz.csv --headerline
7.4 按照经纬度统计数据
我们规约的时候按照经纬度的5*5方格进行分组,如果在此方格内存在地震,则地震+1
var map = function(){ var jd = parseInt(this.jd/5)*5; var wd = parseInt(this.wd/5)*5; var area = jd + ':' + wd; emit(area,1);//如果该区域有地震,则统计为1 } var reduce = function(area,nums){ return Array.sum(nums); } db.dz.mapReduce(map,reduce,{out:'dzrs'});
成功获取区间范围内的地震次数,此时我们要将数据导出为json,做成热力图;
7.5 热力图
使用百度地图开放平台的热力图api http://lbsyun.baidu.com/index.php?title=jspopular
填入密钥,生成热力图
7.6 展示地震数据
转化地震数据为规定的json格式
var course = db.dzrs.find();
var row;
course.forEach(function(obj){ row = obj._id.split(':');
db.reli.insert({lng:parseInt(row[1])+2.5,lat:parseInt(row[0])+2.5,count:obj.value}) })
导出json
./bin/mongoexport -d test -c reli -o /usr/local/src/reli.json
将json数据放入热力图当中并配置热力图相关选项.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号