
Hive(五)数据类型与库表操作以及中文乱码
一、数据类型
1、基本数据类型
Hive 支持关系型数据中大多数基本数据类型
| 类型 | 描述 | 示例 |
|---|---|---|
| boolean | true/false | TRUE |
| tinyint | 1字节的有符号整数 | -128~127 1Y |
| smallint | 2个字节的有符号整数,-32768~32767 | 1S |
| int | 4个字节的带符号整数 | 1 |
| bigint | 8字节带符号整数 | 1L |
| float | 4字节单精度浮点数 | 1.0 |
| double | 8字节双精度浮点数 | 1.0 |
| deicimal | 任意精度的带符号小数 | 1.0 |
| String | 字符串,变长 | “a”,’b’ |
| varchar | 变长字符串 | “a”,’b’ |
| char | 固定长度字符串 | “a”,’b’ |
| binary | 字节数组 | 无法表示 |
| timestamp | 时间戳,纳秒精度 | 122327493795 |
| date | 日期 | ‘2018-04-07’ |
和其他的SQL语言一样,这些都是保留字。需要注意的是所有的这些数据类型都是对Java中接口的实现,因此这些类型的具体行为细节和Java中对应的类型是完全一致的。例如,string类型实现的是Java中的String,float实现的是Java中的float,等等。
2、复杂类型
| 类型 | 描述 | 示例 |
|---|---|---|
| array | 有序的的同类型的集合 | array(1,2) |
| map | key-value,key必须为原始类型,value可以任意类型 | map(‘a’,1,’b’,2) |
| struct | 字段集合,类型可以不同 | struct(‘1’,1,1.0), named_stract(‘col1’,’1’,’col2’,1,’clo3’,1.0) |
案例实操
1)假设某表有如下一行,我们用JSON格式来表示其数据结构。在Hive下访问的格式为
|
{ "name": "songsong", "friends": ["bingbing" , "lili"] , //列表Array, "children": { //键值Map, "xiao song": 18 , "xiaoxiao song": 19 } "address": { //结构Struct, "street": "hui long guan" , "city": "beijing" } } |
2)基于上述数据结构,我们在Hive里创建对应的表,并导入数据。
创建本地测试文件test.txt
|
songsong,bingbing_lili,xiao song:18_xiaoxiao song:19,hui long guan_beijing yangyang,caicai_susu,xiao yang:18_xiaoxiao yang:19,chao yang_beijing |
注意,MAP,STRUCT和ARRAY里的元素间关系都可以用同一个字符表示,这里用“_”。
3)Hive上创建测试表test
|
create table test( name string, friends array<string>, children map<string, int>, address struct<street:string, city:string> ) row format delimited fields terminated by ',' collection items terminated by '_' map keys terminated by ':' lines terminated by '\n'; |
字段解释:
row format delimited fields terminated by ',' -- 列分隔符
collection items terminated by '_' --MAP STRUCT 和 ARRAY 的分隔符(数据分割符号)
map keys terminated by ':' -- MAP中的key与value的分隔符
lines terminated by '\n'; -- 行分隔符
4)导入文本数据到测试表
|
hive (default)> load data local inpath '/opt/module/datas/test.txt' into table test; |
5)访问三种集合列里的数据,以下分别是ARRAY,MAP,STRUCT的访问方式
|
hive (default)> select friends[1],children['xiao song'],address.city from test where name="songsong"; OK _c0 _c1 city lili 18 beijing Time taken: 0.076 seconds, Fetched: 1 row(s) |
3、类型转化
Hive的原子数据类型是可以进行隐式转换的,类似于Java的类型转换,例如某表达式使用INT类型,TINYINT会自动转换为INT类型,但是Hive不会进行反向转化,例如,某表达式使用TINYINT类型,INT不会自动转换为TINYINT类型,它会返回错误,除非使用CAST 操作。
1)隐式类型转换规则如下。
(1)任何整数类型都可以隐式地转换为一个范围更广的类型,如TINYINT可以转换成INT,INT可以转换成BIGINT。
(2)所有整数类型、FLOAT和STRING类型都可以隐式地转换成DOUBLE。
(3)TINYINT、SMALLINT、INT都可以转换为FLOAT。
(4)BOOLEAN类型不可以转换为任何其它的类型。
2)可以使用CAST操作显示进行数据类型转换,例如CAST('1' AS INT)将把字符串'1' 转换成整数1;如果强制类型转换失败,如执行CAST('X' AS INT),表达式返回空值 NULL。
二、存储格式
Hive会为每个创建的数据库在HDFS上创建一个目录,该数据库的表会以子目录形式存储,表中的数据会以表目录下的文件形式存储。对于default数据库,默认的缺省数据库没有自己的目录,default数据库下的表默认存放在/user/hive/warehouse目录下。
(1)textfile
textfile为默认格式,存储方式为行存储。数据不做压缩,磁盘开销大,数据解析开销大。
(2)SequenceFile
SequenceFile是Hadoop API提供的一种二进制文件支持,其具有使用方便、可分割、可压缩的特点。
SequenceFile支持三种压缩选择:NONE, RECORD, BLOCK。 Record压缩率低,一般建议使用BLOCK压缩。
(3)RCFile
一种行列存储相结合的存储方式。
(4)ORCFile
数据按照行分块,每个块按照列存储,其中每个块都存储有一个索引。hive给出的新格式,属于RCFILE的升级版,性能有大幅度提升,而且数据可以压缩存储,压缩快 快速列存取。
(5)Parquet
Parquet也是一种行式存储,同时具有很好的压缩性能;同时可以减少大量的表扫描和反序列化的时间。
三、数据格式
当数据存储在文本文件中,必须按照一定格式区别行和列,并且在Hive中指明这些区分符。Hive默认使用了几个平时很少出现的字符,这些字符一般不会作为内容出现在记录中。
Hive默认的行和列分隔符如下表所示。
| 分隔符 | 描述 |
|---|---|
| \n | 对于文本文件来说,每行是一条记录,所以\n 来分割记录 |
| ^A (Ctrl+A) | 分割字段,也可以用\001 来表示 |
| ^B (Ctrl+B) | 用于分割 Arrary 或者 Struct 中的元素,或者用于 map 中键值之间的分割,也可以用\002 分割。 |
| ^C | 用于 map 中键和值自己分割,也可以用\003 表示。 |
四、DDL语句的定义
1、创建库
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name
[COMMENT database_comment] //关于数据块的描述
[LOCATION hdfs_path] //指定数据库在HDFS上的存储位置
[WITH DBPROPERTIES (property_name=property_value, ...)]; //指定数据块属性
默认地址:/user/hive/warehouse/db_name.db/table_name/partition_name/…
创建库的方式
(1)创建普通的数据库
0: jdbc:hive2://hadoop3:10000> create database t1; No rows affected (0.308 seconds) 0: jdbc:hive2://hadoop3:10000> show databases; +----------------+ | database_name | +----------------+ | default | | myhive | | t1 | +----------------+ 3 rows selected (0.393 seconds) 0: jdbc:hive2://hadoop3:10000>
(2)创建库的时候检查存与否
0: jdbc:hive2://hadoop3:10000> create database if not exists t1; No rows affected (0.176 seconds) 0: jdbc:hive2://hadoop3:10000>
(3)创建库的时候带注释
0: jdbc:hive2://hadoop3:10000> create database if not exists t2 comment 'learning hive';
No rows affected (0.217 seconds)
0: jdbc:hive2://hadoop3:10000>

(4)创建带属性的库
0: jdbc:hive2://hadoop3:10000> create database if not exists t3 with dbproperties('creator'='hadoop','date'='2018-04-05');
No rows affected (0.255 seconds)
0: jdbc:hive2://hadoop3:10000>
2、查看库
(1)查看有哪些数据库
0: jdbc:hive2://hadoop3:10000> show databases;
+----------------+
| database_name |
+----------------+
| default |
| myhive |
| t1 |
| t2 |
| t3 |
+----------------+
5 rows selected (0.164 seconds)
0: jdbc:hive2://hadoop3:10000>
(2)显示数据库的详细属性信息
desc database [extended] dbname;
示例
0: jdbc:hive2://hadoop3:10000> desc database extended t3;
+----------+----------+------------------------------------------+-------------+-------------+------------------------------------+
| db_name | comment | location | owner_name | owner_type | parameters |
+----------+----------+------------------------------------------+-------------+-------------+------------------------------------+
| t3 | | hdfs://myha01/user/hive/warehouse/t3.db | hadoop | USER | {date=2018-04-05, creator=hadoop} |
+----------+----------+------------------------------------------+-------------+-------------+------------------------------------+
1 row selected (0.11 seconds)
0: jdbc:hive2://hadoop3:10000>
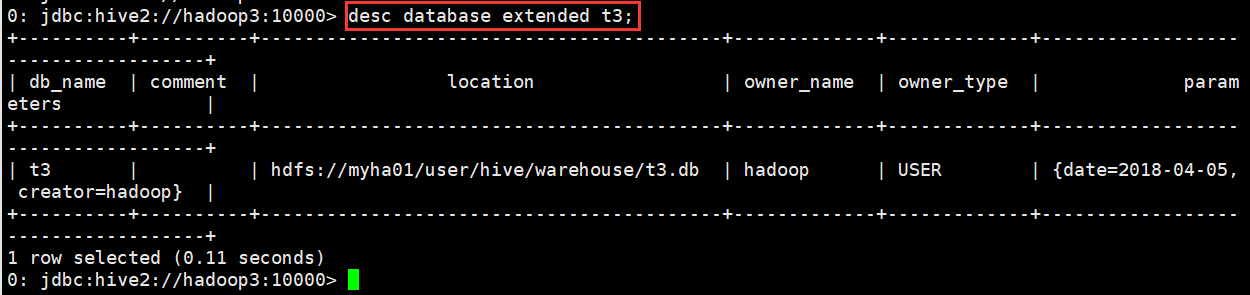
(3)查看正在使用哪个库
0: jdbc:hive2://hadoop3:10000> select current_database(); +----------+ | _c0 | +----------+ | default | +----------+ 1 row selected (1.36 seconds) 0: jdbc:hive2://hadoop3:10000>
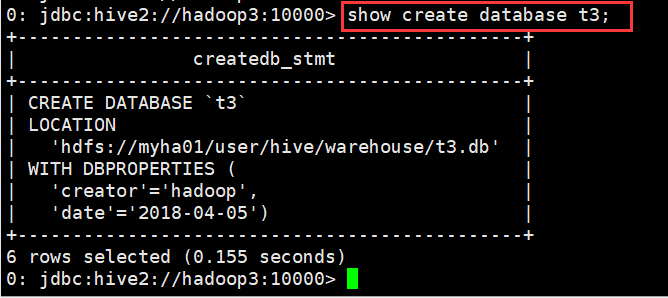
(4)查看创建库的详细语句
0: jdbc:hive2://hadoop3:10000> show create database t3; +----------------------------------------------+ | createdb_stmt | +----------------------------------------------+ | CREATE DATABASE `t3` | | LOCATION | | 'hdfs://myha01/user/hive/warehouse/t3.db' | | WITH DBPROPERTIES ( | | 'creator'='hadoop', | | 'date'='2018-04-05') | +----------------------------------------------+ 6 rows selected (0.155 seconds) 0: jdbc:hive2://hadoop3:10000>
3、删除库
删除库操作
drop database dbname; drop database if exists dbname;
默认情况下,hive 不允许删除包含表的数据库,有两种解决办法:
1、 手动删除库下所有表,然后删除库
2、 使用 cascade 关键字
drop database if exists dbname cascade;
默认情况下就是 restrict drop database if exists myhive ==== drop database if exists myhive restrict
示例
(1)删除不含表的数据库
0: jdbc:hive2://hadoop3:10000> show tables in t1; +-----------+ | tab_name | +-----------+ +-----------+ No rows selected (0.147 seconds) 0: jdbc:hive2://hadoop3:10000> drop database t1; No rows affected (0.178 seconds) 0: jdbc:hive2://hadoop3:10000> show databases; +----------------+ | database_name | +----------------+ | default | | myhive | | t2 | | t3 | +----------------+ 4 rows selected (0.124 seconds) 0: jdbc:hive2://hadoop3:10000>
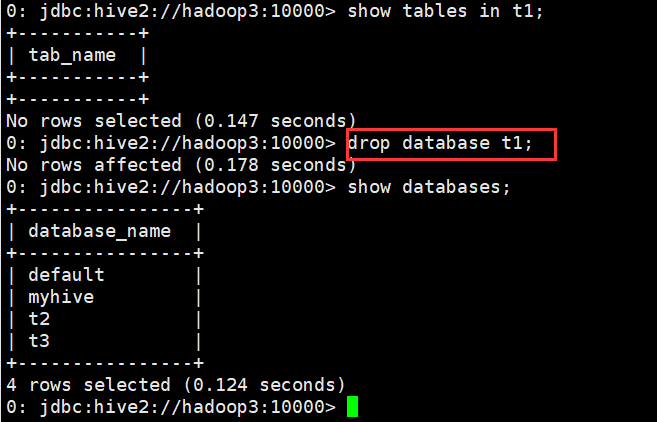
(2)删除含有表的数据库
0: jdbc:hive2://hadoop3:10000> drop database if exists t3 cascade; No rows affected (1.56 seconds) 0: jdbc:hive2://hadoop3:10000>
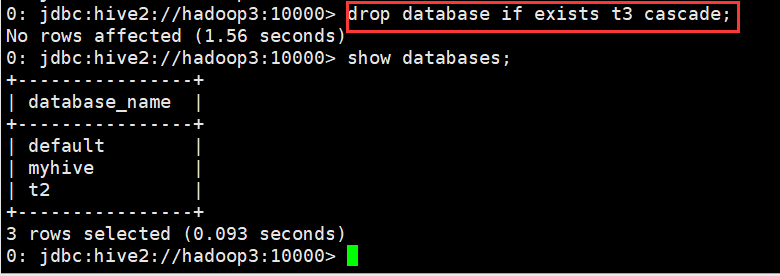
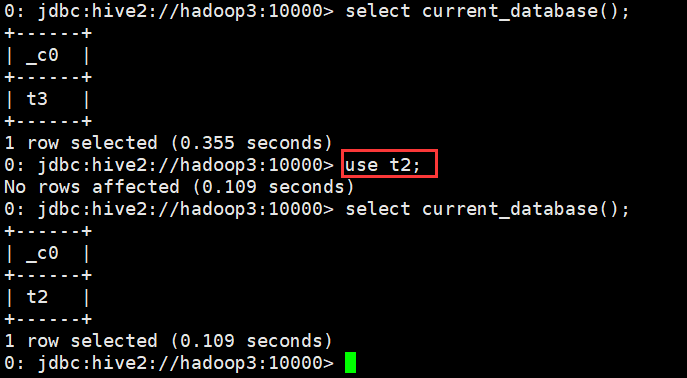
4、切换库
use database_name
示例
0: jdbc:hive2://hadoop3:10000> use t2; No rows affected (0.109 seconds) 0: jdbc:hive2://hadoop3:10000>
5、修改库
用户可以使用ALTER DATABASE命令为某个数据库的DBPROPERTIES设置键-值对属性值,来描述这个数据库的属性信息。数据库的其他元数据信息都是不可更改的,包括数据库名和数据库所在的目录位置。
hive (default)> alter database db_hive set dbproperties('createtime'='20170830');
在mysql中查看修改结果
hive> desc database extended db_hive;
db_name comment location owner_name owner_type parameters
db_hive hdfs://hadoop102:8020/user/hive/warehouse/db_hive.db admin USER {createtime=20170830}
6、创建表
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
详情请参见: https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualD DL-CreateTable
•CREATE TABLE 创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常;用户可以用 IF NOT EXIST 选项来忽略这个异常 •EXTERNAL 关键字可以让用户创建一个外部表,在建表的同时指定一个指向实际数据的路径(LOCATION) •LIKE 允许用户复制现有的表结构,但是不复制数据 •COMMENT可以为表与字段增加描述
•PARTITIONED BY 指定分区
•ROW FORMAT
DELIMITED [FIELDS TERMINATED BY char] [COLLECTION ITEMS TERMINATED BY char]
MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
| SERDE serde_name [WITH SERDEPROPERTIES
(property_name=property_value, property_name=property_value, ...)]
用户在建表的时候可以自定义 SerDe 或者使用自带的 SerDe。如果没有指定 ROW FORMAT 或者 ROW FORMAT DELIMITED,将会使用自带的 SerDe。在建表的时候,
用户还需要为表指定列,用户在指定表的列的同时也会指定自定义的 SerDe,Hive 通过 SerDe 确定表的具体的列的数据。
•STORED AS
SEQUENCEFILE //序列化文件
| TEXTFILE //普通的文本文件格式
| RCFILE //行列存储相结合的文件
| INPUTFORMAT input_format_classname OUTPUTFORMAT output_format_classname //自定义文件格式
如果文件数据是纯文本,可以使用 STORED AS TEXTFILE。如果数据需要压缩,使用 STORED AS SEQUENCE 。
•LOCATION指定表在HDFS的存储路径
最佳实践:
如果一份数据已经存储在HDFS上,并且要被多个用户或者客户端使用,最好创建外部表
反之,最好创建内部表。
如果不指定,就按照默认的规则存储在默认的仓库路径中。
示例
使用t2数据库进行操作
(1)创建默认的内部表
0: jdbc:hive2://hadoop3:10000> create table student(id int, name string, sex string, age int,department string) row format delimited fields terminated by ","; No rows affected (0.222 seconds) 0: jdbc:hive2://hadoop3:10000> desc student; +-------------+------------+----------+ | col_name | data_type | comment | +-------------+------------+----------+ | id | int | | | name | string | | | sex | string | | | age | int | | | department | string | | +-------------+------------+----------+ 5 rows selected (0.168 seconds) 0: jdbc:hive2://hadoop3:10000>

(2)外部表
0: jdbc:hive2://hadoop3:10000> create external table student_ext
(id int, name string, sex string, age int,department string) row format delimited fields terminated by "," location "/hive/student"; No rows affected (0.248 seconds) 0: jdbc:hive2://hadoop3:10000>
(3)分区表
0: jdbc:hive2://hadoop3:10000> create external table student_ptn(id int, name string, sex string, age int,department string) . . . . . . . . . . . . . . .> partitioned by (city string) . . . . . . . . . . . . . . .> row format delimited fields terminated by "," . . . . . . . . . . . . . . .> location "/hive/student_ptn"; No rows affected (0.24 seconds) 0: jdbc:hive2://hadoop3:10000>
添加分区
0: jdbc:hive2://hadoop3:10000> alter table student_ptn add partition(city="beijing"); No rows affected (0.269 seconds) 0: jdbc:hive2://hadoop3:10000> alter table student_ptn add partition(city="shenzhen"); No rows affected (0.236 seconds) 0: jdbc:hive2://hadoop3:10000>
如果某张表是分区表。那么每个分区的定义,其实就表现为了这张表的数据存储目录下的一个子目录
如果是分区表。那么数据文件一定要存储在某个分区中,而不能直接存储在表中。
(4)分桶表
0: jdbc:hive2://hadoop3:10000> create external table student_bck(id int, name string, sex string, age int,department string) . . . . . . . . . . . . . . .> clustered by (id) sorted by (id asc, name desc) into 4 buckets . . . . . . . . . . . . . . .> row format delimited fields terminated by "," . . . . . . . . . . . . . . .> location "/hive/student_bck"; No rows affected (0.216 seconds) 0: jdbc:hive2://hadoop3:10000>
(5)使用CTAS创建表
作用: 就是从一个查询SQL的结果来创建一个表进行存储
现象student表中导入数据
0: jdbc:hive2://hadoop3:10000> load data local inpath "/home/hadoop/student.txt" into table student; No rows affected (0.715 seconds) 0: jdbc:hive2://hadoop3:10000> select * from student; +-------------+---------------+--------------+--------------+---------------------+ | student.id | student.name | student.sex | student.age | student.department | +-------------+---------------+--------------+--------------+---------------------+ | 95002 | 刘晨 | 女 | 19 | IS | | 95017 | 王风娟 | 女 | 18 | IS | | 95018 | 王一 | 女 | 19 | IS | | 95013 | 冯伟 | 男 | 21 | CS | | 95014 | 王小丽 | 女 | 19 | CS | | 95019 | 邢小丽 | 女 | 19 | IS | | 95020 | 赵钱 | 男 | 21 | IS | | 95003 | 王敏 | 女 | 22 | MA | | 95004 | 张立 | 男 | 19 | IS | | 95012 | 孙花 | 女 | 20 | CS | | 95010 | 孔小涛 | 男 | 19 | CS | | 95005 | 刘刚 | 男 | 18 | MA | | 95006 | 孙庆 | 男 | 23 | CS | | 95007 | 易思玲 | 女 | 19 | MA | | 95008 | 李娜 | 女 | 18 | CS | | 95021 | 周二 | 男 | 17 | MA | | 95022 | 郑明 | 男 | 20 | MA | | 95001 | 李勇 | 男 | 20 | CS | | 95011 | 包小柏 | 男 | 18 | MA | | 95009 | 梦圆圆 | 女 | 18 | MA | | 95015 | 王君 | 男 | 18 | MA | +-------------+---------------+--------------+--------------+---------------------+ 21 rows selected (0.342 seconds) 0: jdbc:hive2://hadoop3:10000>
使用CTAS创建表
0: jdbc:hive2://hadoop3:10000> create table student_ctas as select * from student where id < 95012; WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution
engine (i.e. spark, tez) or using Hive 1.X releases. No rows affected (34.514 seconds) 0: jdbc:hive2://hadoop3:10000> select * from student_ctas . . . . . . . . . . . . . . .> ; +------------------+--------------------+-------------------+-------------------+--------------------------+ | student_ctas.id | student_ctas.name | student_ctas.sex | student_ctas.age | student_ctas.department | +------------------+--------------------+-------------------+-------------------+--------------------------+ | 95002 | 刘晨 | 女 | 19 | IS | | 95003 | 王敏 | 女 | 22 | MA | | 95004 | 张立 | 男 | 19 | IS | | 95010 | 孔小涛 | 男 | 19 | CS | | 95005 | 刘刚 | 男 | 18 | MA | | 95006 | 孙庆 | 男 | 23 | CS | | 95007 | 易思玲 | 女 | 19 | MA | | 95008 | 李娜 | 女 | 18 | CS | | 95001 | 李勇 | 男 | 20 | CS | | 95011 | 包小柏 | 男 | 18 | MA | | 95009 | 梦圆圆 | 女 | 18 | MA | +------------------+--------------------+-------------------+-------------------+--------------------------+ 11 rows selected (0.445 seconds) 0: jdbc:hive2://hadoop3:10000>
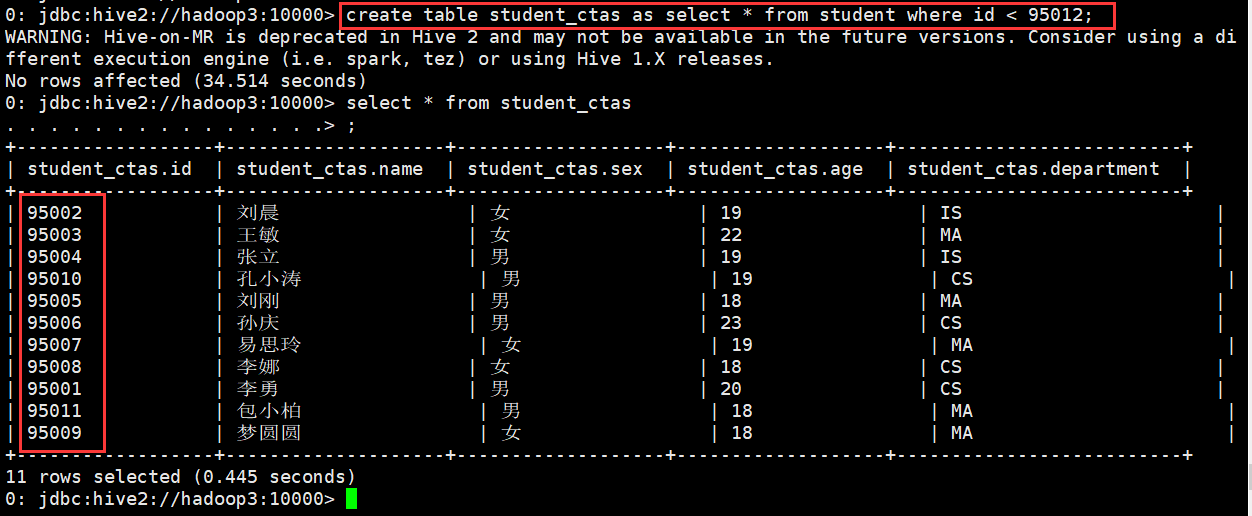
(6)复制表结构
0: jdbc:hive2://hadoop3:10000> create table student_copy like student; No rows affected (0.217 seconds) 0: jdbc:hive2://hadoop3:10000>
注意:
如果在table的前面没有加external关键字,那么复制出来的新表。无论如何都是内部表
如果在table的前面有加external关键字,那么复制出来的新表。无论如何都是外部表

7、查看表
(1)查看表列表
查看当前使用的数据库中有哪些表
0: jdbc:hive2://hadoop3:10000> show tables; +---------------+ | tab_name | +---------------+ | student | | student_bck | | student_copy | | student_ctas | | student_ext | | student_ptn | +---------------+ 6 rows selected (0.163 seconds) 0: jdbc:hive2://hadoop3:10000>
查看非当前使用的数据库中有哪些表
0: jdbc:hive2://hadoop3:10000> show tables in myhive; +-----------+ | tab_name | +-----------+ | student | +-----------+ 1 row selected (0.144 seconds) 0: jdbc:hive2://hadoop3:10000>
查看数据库中以xxx开头的表
0: jdbc:hive2://hadoop3:10000> show tables like 'student_c*'; +---------------+ | tab_name | +---------------+ | student_copy | | student_ctas | +---------------+ 2 rows selected (0.13 seconds) 0: jdbc:hive2://hadoop3:10000>
(2)查看表的详细信息
查看表的信息
0: jdbc:hive2://hadoop3:10000> desc student; +-------------+------------+----------+ | col_name | data_type | comment | +-------------+------------+----------+ | id | int | | | name | string | | | sex | string | | | age | int | | | department | string | | +-------------+------------+----------+ 5 rows selected (0.149 seconds) 0: jdbc:hive2://hadoop3:10000>
查看表的详细信息(格式不友好)
0: jdbc:hive2://hadoop3:10000> desc extended student;
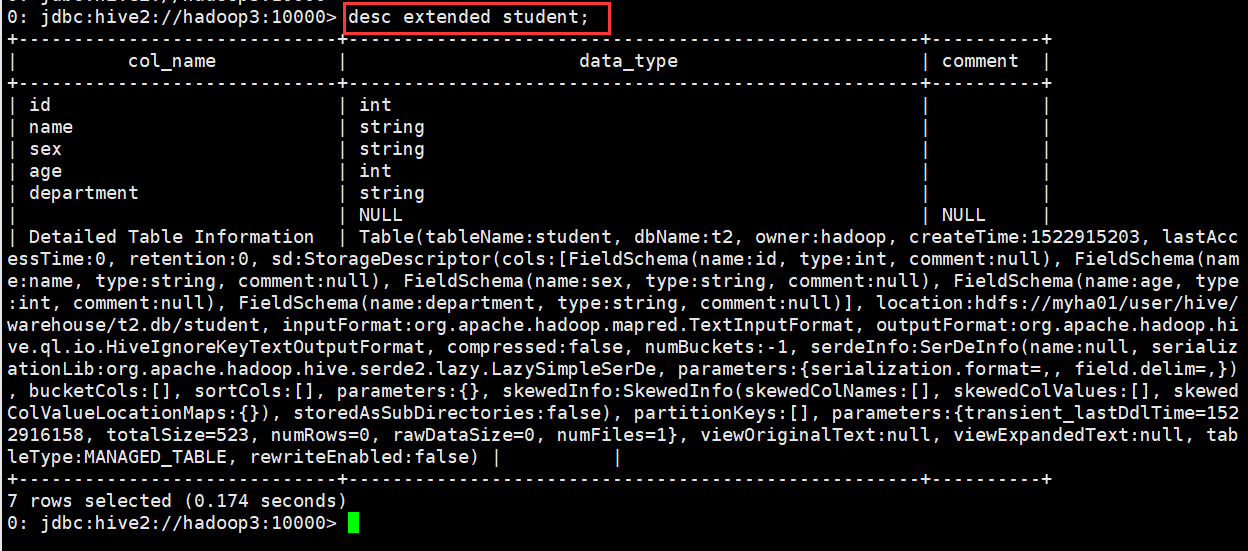
查看表的详细信息(格式友好)
0: jdbc:hive2://hadoop3:10000> desc formatted student;
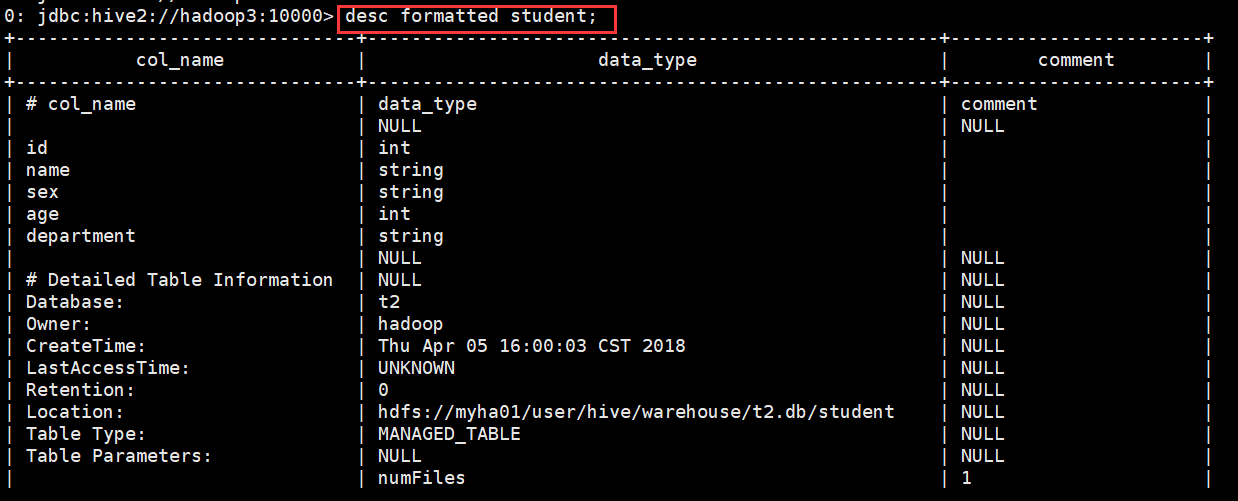
查看分区信息
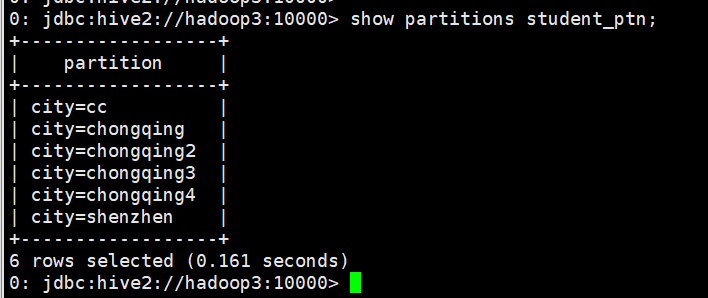
0: jdbc:hive2://hadoop3:10000> show partitions student_ptn;
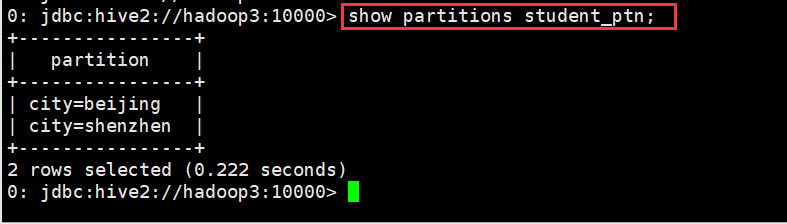
(3)查看表的详细建表语句
0: jdbc:hive2://hadoop3:10000> show create table student_ptn;
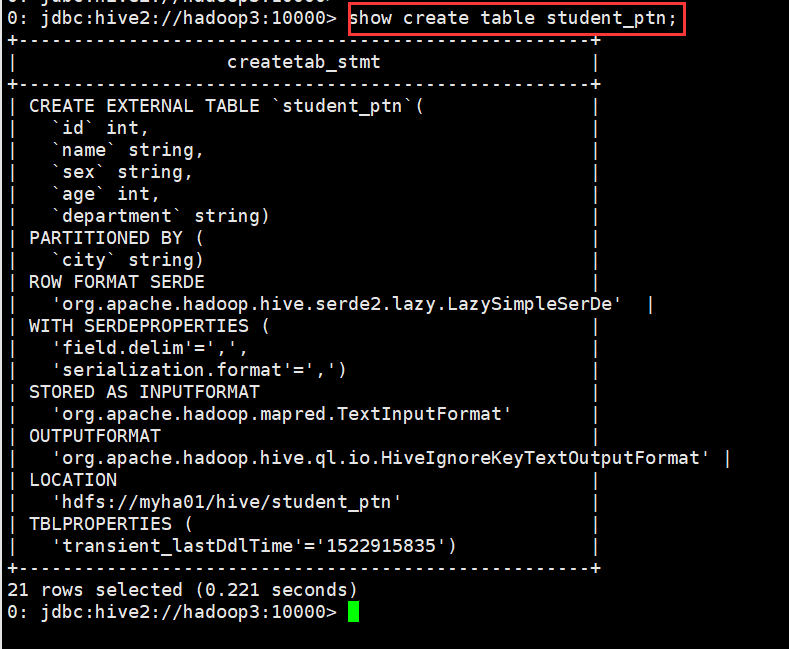
8、修改表
(1)修改表名
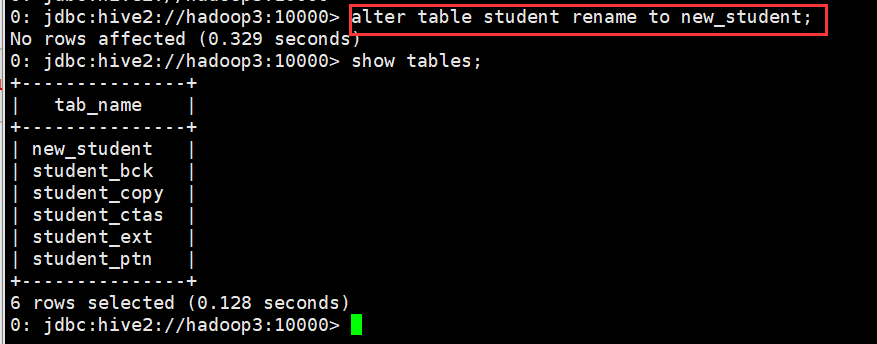
0: jdbc:hive2://hadoop3:10000> alter table student rename to new_student;
(2)修改字段定义
A. 增加一个字段
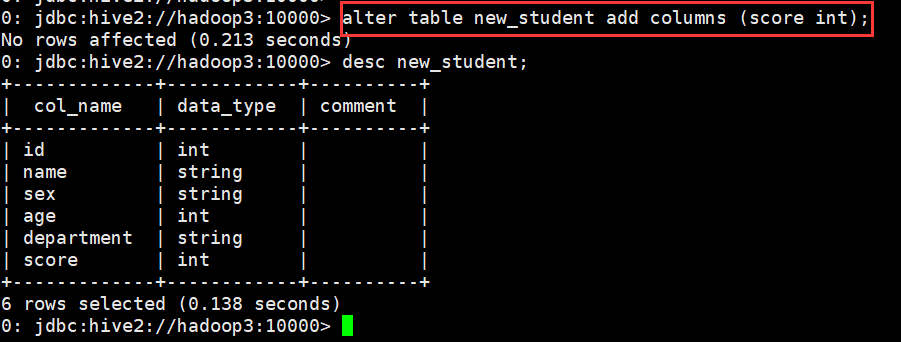
0: jdbc:hive2://hadoop3:10000> alter table new_student add columns (score int);
B. 修改一个字段的定义
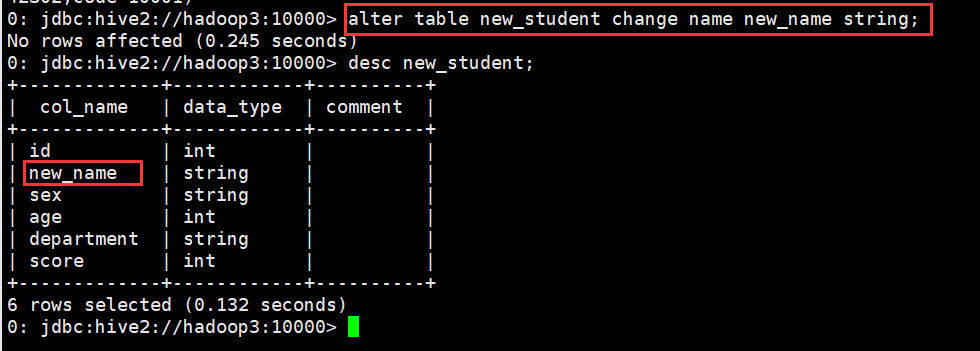
0: jdbc:hive2://hadoop3:10000> alter table new_student change name new_name string;
C. 删除一个字段
不支持
D. 替换所有字段
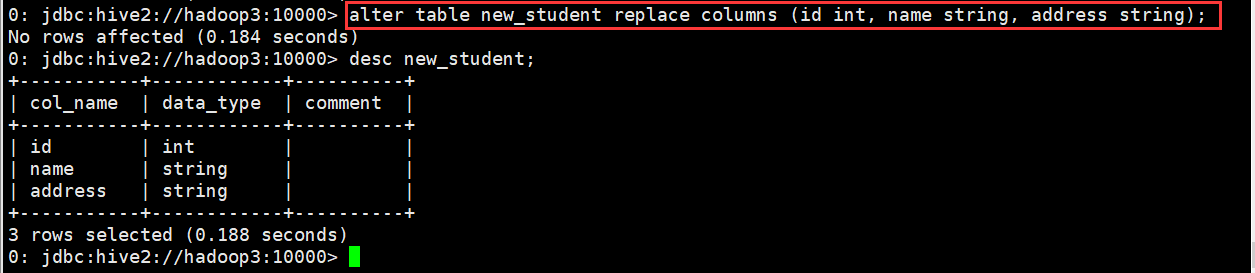
0: jdbc:hive2://hadoop3:10000> alter table new_student replace columns (id int, name string, address string);
(3)修改分区信息
A. 添加分区
静态分区
添加一个
0: jdbc:hive2://hadoop3:10000> alter table student_ptn add partition(city="chongqing");
添加多个
0: jdbc:hive2://hadoop3:10000> alter table student_ptn add partition(city="chongqing2") partition(city="chongqing3") partition(city="chongqing4");
动态分区
先向student_ptn表中插入数据,数据格式如下图
0: jdbc:hive2://hadoop3:10000> load data local inpath "/home/hadoop/student.txt" into table student_ptn partition(city="beijing");
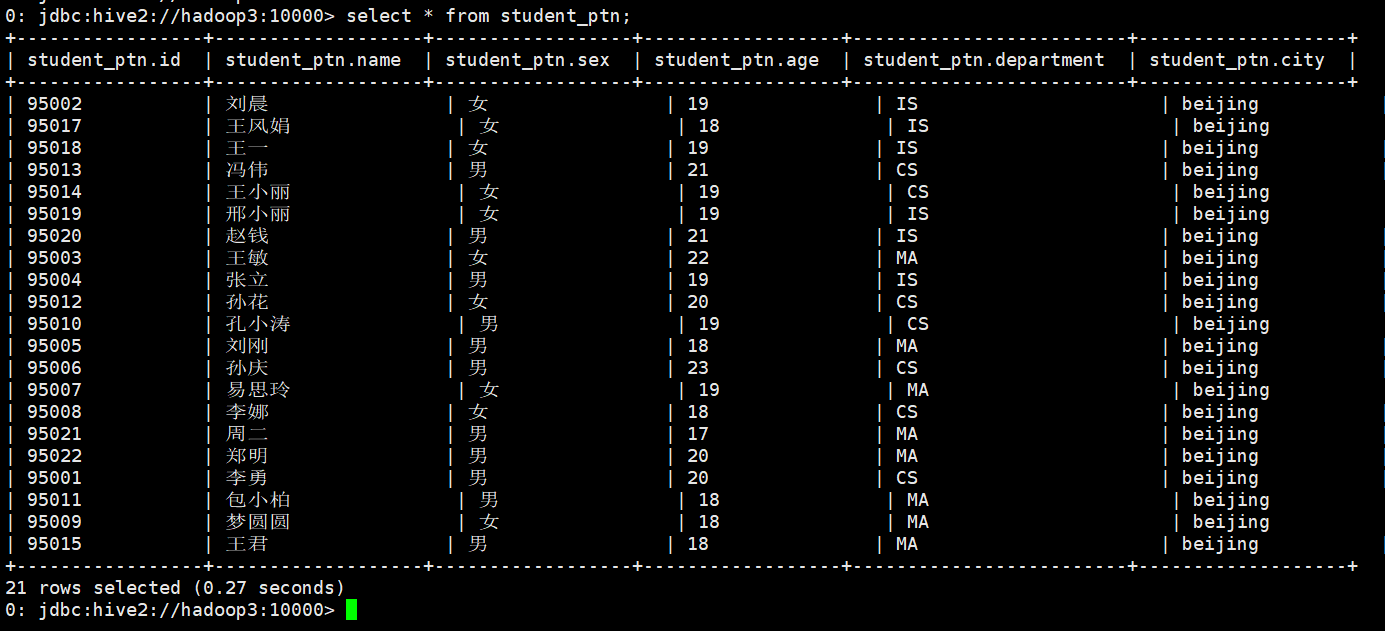
现在我把这张表的内容直接插入到另一张表student_ptn_age中,并实现sex为动态分区(不指定到底是哪中性别,让系统自己分配决定)
首先创建student_ptn_age并指定分区为age
0: jdbc:hive2://hadoop3:10000> create table student_ptn_age(id int,name string,sex string,department string) partitioned by (age int);
从student_ptn表中查询数据并插入student_ptn_age表中
0: jdbc:hive2://hadoop3:10000> insert overwrite table student_ptn_age partition(age) . . . . . . . . . . . . . . .> select id,name,sex,department,age from student_ptn; WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases. No rows affected (27.905 seconds) 0: jdbc:hive2://hadoop3:10000>
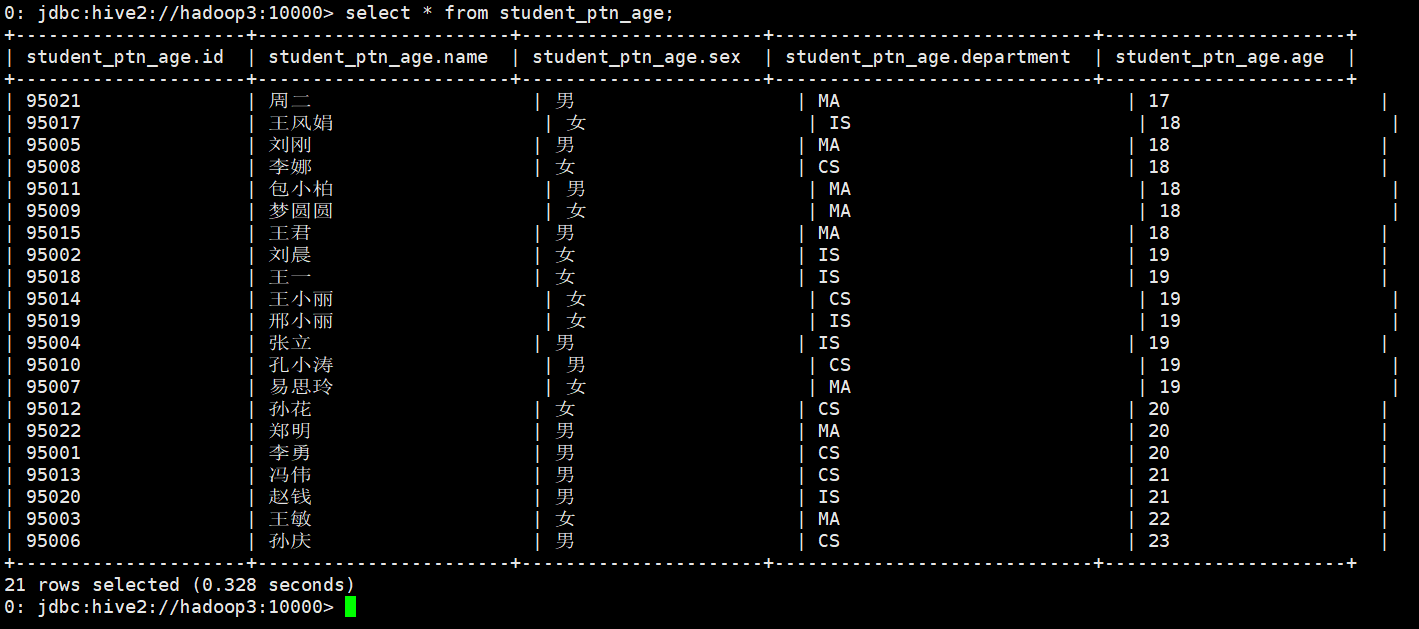
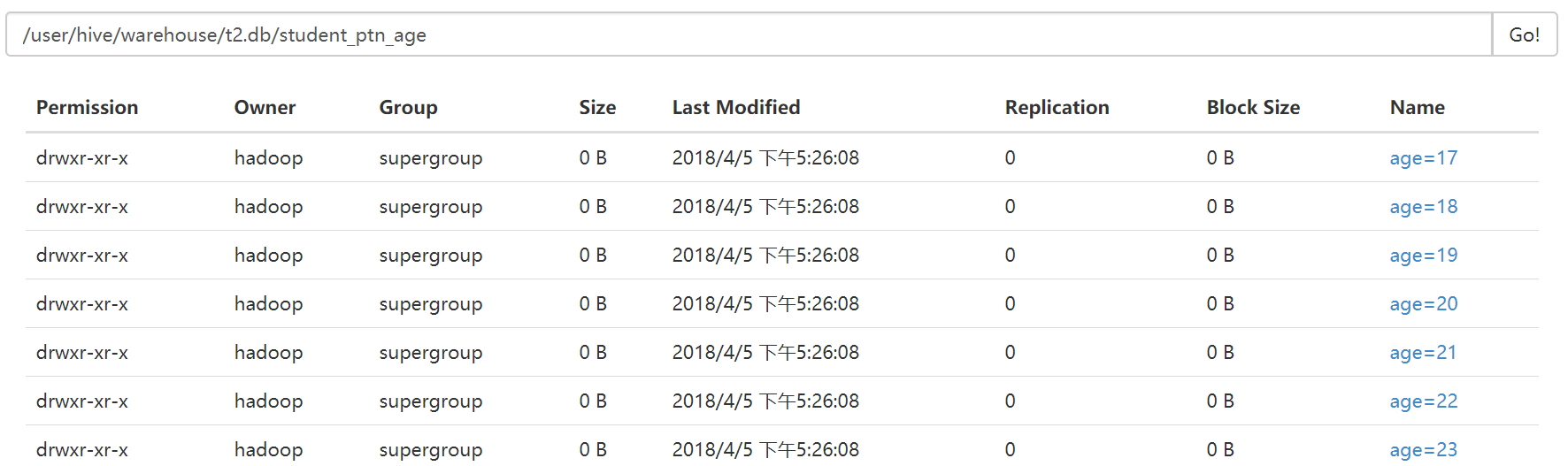
B. 修改分区
修改分区,一般来说,都是指修改分区的数据存储目录
在添加分区的时候,直接指定当前分区的数据存储目录
0: jdbc:hive2://hadoop3:10000> alter table student_ptn add if not exists partition(city='beijing') . . . . . . . . . . . . . . .> location '/student_ptn_beijing' partition(city='cc') location '/student_cc'; No rows affected (0.306 seconds) 0: jdbc:hive2://hadoop3:10000>
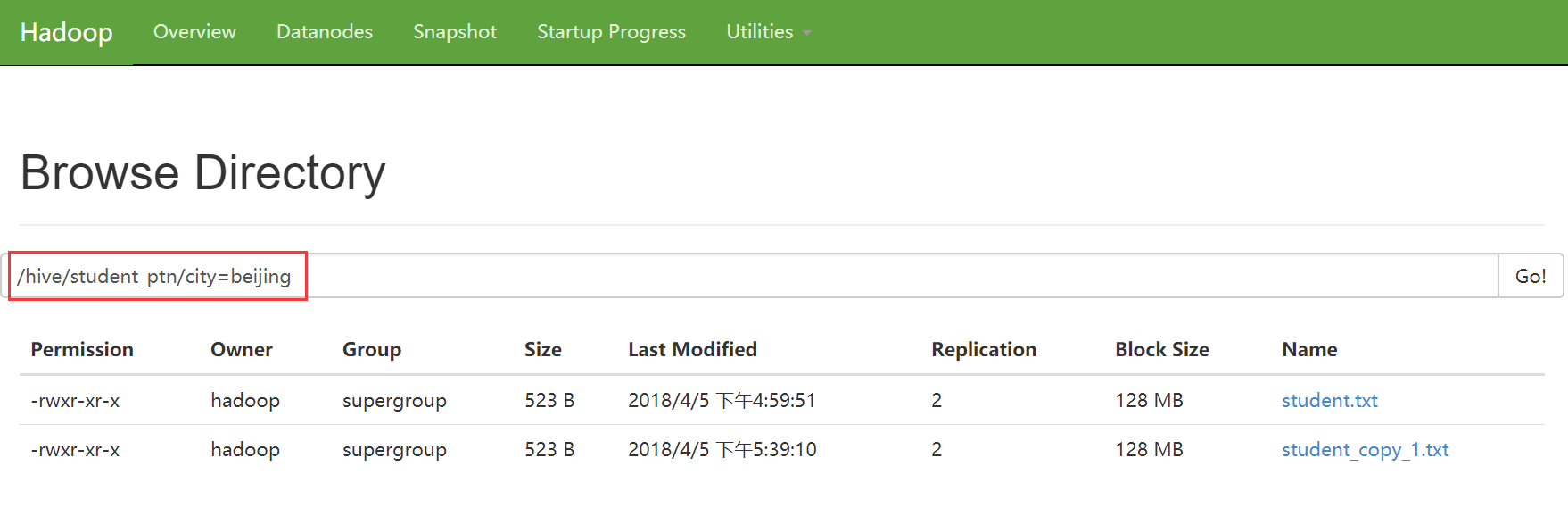
修改已经指定好的分区的数据存储目录
0: jdbc:hive2://hadoop3:10000> alter table student_ptn partition (city='beijing') set location '/student_ptn_beijing';
此时原先的分区文件夹仍存在,但是在往分区添加数据时,只会添加到新的分区目录
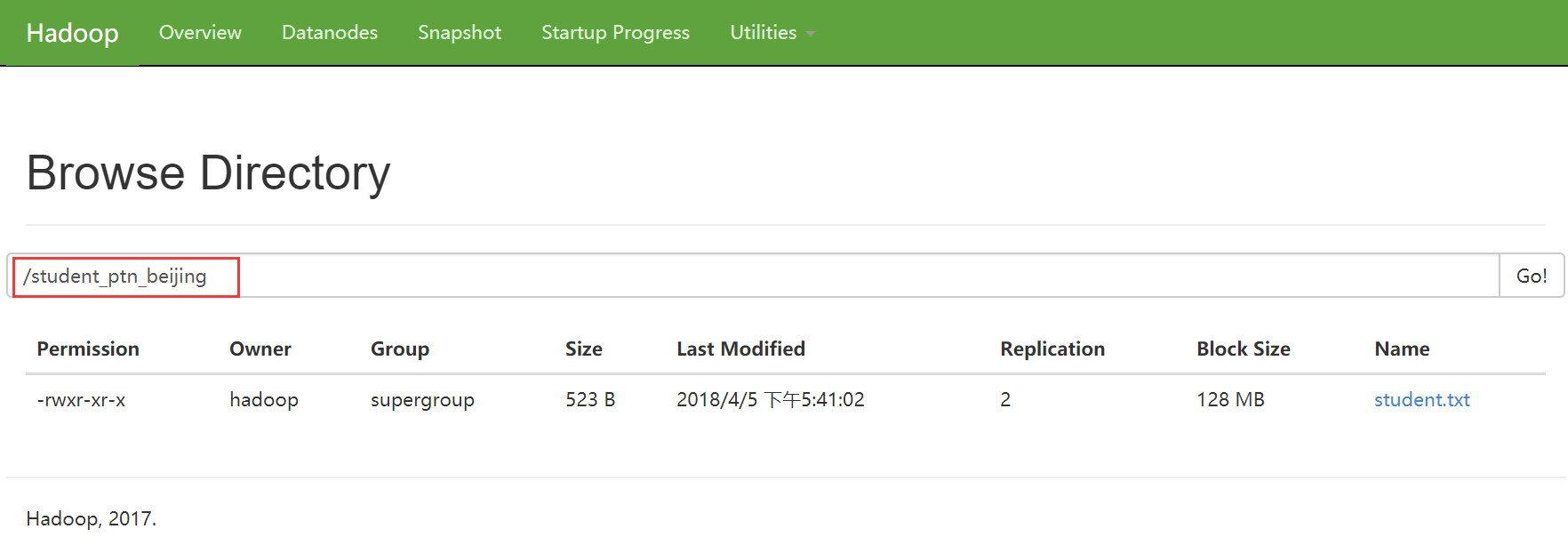
C. 删除分区
0: jdbc:hive2://hadoop3:10000> alter table student_ptn drop partition (city='beijing');
9、删除表
0: jdbc:hive2://hadoop3:10000> drop table new_student;
10、清空表
0: jdbc:hive2://hadoop3:10000> truncate table student_ptn;
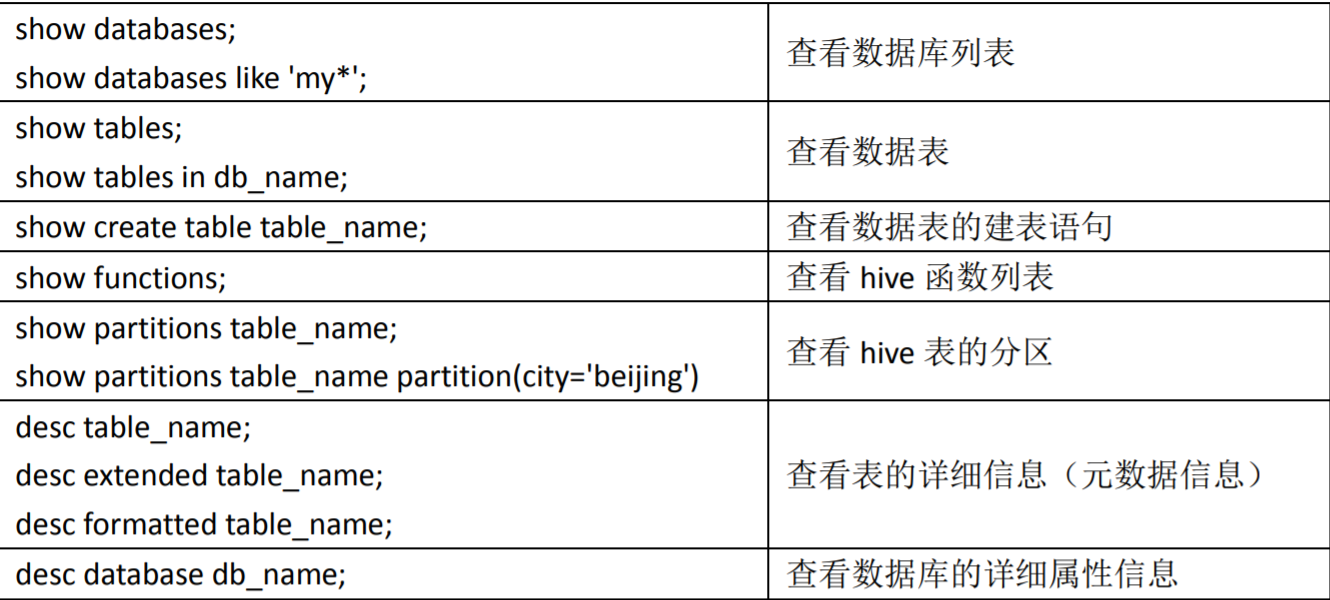
其他辅助命令

五、DML数据操作
1、数据导入
向表中装载数据(Load)
1)语法
hive>load data [local] inpath '/opt/module/datas/student.txt' [overwrite] into table student [partition (partcol1=val1,…)];
(1)load data:表示加载数据
(2)local:表示从本地加载数据到hive表;否则从HDFS加载数据到hive表
(3)inpath:表示加载数据的路径
(4)into table:表示加载到哪张表
(5)student:表示具体的表
(6)overwrite:表示覆盖表中已有数据,否则表示追加
(7)partition:表示上传到指定分区
2)实操案例
(0)创建一张表
hive (default)> create table student(id string, name string) row format delimited fields terminated by '\t';
(1)加载本地文件到hive
hive (default)> load data local inpath '/opt/module/datas/student.txt' into table default.student;
(2)加载HDFS文件到hive中
上传文件到HDFS
hive (default)> dfs -put /opt/module/datas/student.txt /user/atguigu/hive;
加载HDFS上数据
hive (default)>load data inpath '/user/atguigu/hive/student.txt' into table default.student;
(3)加载数据覆盖表中已有的数据
上传文件到HDFS
hive (default)> dfs -put /opt/module/datas/student.txt /user/atguigu/hive;
加载数据覆盖表中已有的数据
hive (default)>load data inpath '/user/atguigu/hive/student.txt' overwrite into table default.student;
通过查询语句向表中插入数据(Insert)
1)创建一张分区表
hive (default)> create table student(id string, name string) partitioned by (month string) row format delimited fields terminated by '\t';
2)基本插入数据
hive (default)> insert into table student partition(month='201709') values('1004','wangwu');
3)基本模式插入(根据单张表查询结果)
hive (default)> insert overwrite table student partition(month='201708')
select id, name from student where month='201709';
4)多插入模式(根据多张表查询结果)
hive (default)> from student
insert overwrite table student partition(month='201707')
select id, name where month='201709'
insert overwrite table student partition(month='201706')
select id, name where month='201709';
查询语句中创建表并加载数据(As Select)
根据查询结果创建表(查询的结果会添加到新创建的表中)
create table if not exists student3
as select id, name from student;
创建表时通过Location指定加载数据路径
1)创建表,并指定在hdfs上的位置
hive (default)> create table if not exists student5(
id int, name string
)
row format delimited fields terminated by '\t'
location '/user/hive/warehouse/student5';
2)上传数据到hdfs上
hive (default)> dfs -put /opt/module/datas/student.txt /user/hive/warehouse/student5;
3)查询数据
hive (default)> select * from student5;
3.1.5 Import数据到指定Hive表中
先用export导出后,再将数据导入。
hive (default)> import table student2 partition(month='201709') from '/user/hive/warehouse/export/student';
2、数据导出
Insert导出
1)将查询的结果导出到本地
hive (default)> insert overwrite local directory '/opt/module/datas/export/student'
select * from student;
2)将查询的结果格式化导出到本地
hive (default)> insert overwrite local directory '/opt/module/datas/export/student1'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' COLLECTION ITEMS TERMINATED BY '\n'
select * from student;
3)将查询的结果导出到HDFS上(没有local)
hive (default)> insert overwrite directory '/user/atguigu/hive/warehouse/student2'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' COLLECTION ITEMS TERMINATED BY '\n'
select * from student;
Hadoop命令导出到本地
hive (default)> dfs -get /user/hive/warehouse/student/month=201709/000000_0 /opt/module/datas/export/student3.txt;
Hive Shell 命令导出
bin/hive -e 'select * from default.student;' > /opt/module/datas/export/student4.txt;
Export导出到HDFS上
hive (default)> export table default.student to '/user/hive/warehouse/export/student';
Sqoop导出
3、清除表中数据(Truncate)
hive (default)> truncate table student;
注意:Truncate只能删除管理表,不能删除外部表中数据
六、Hive注释中文乱码
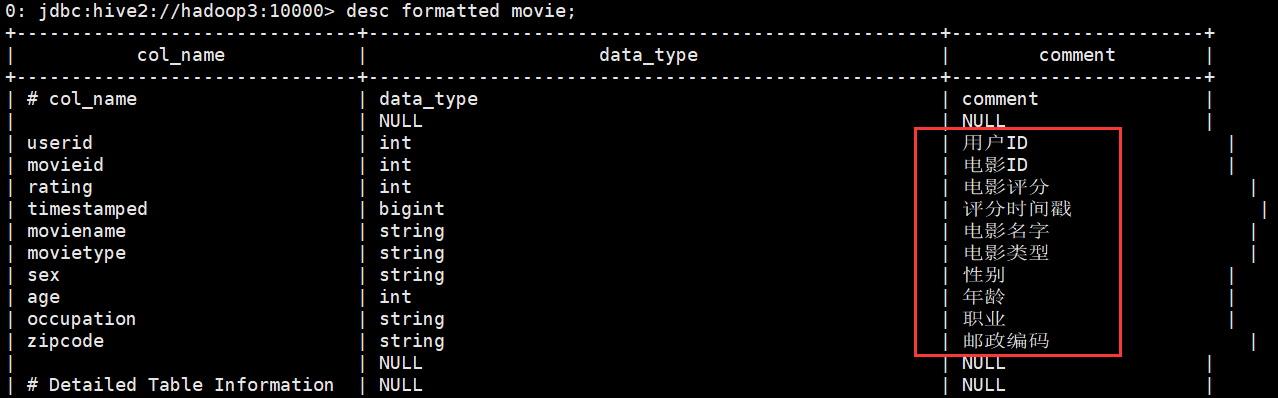
创建表的时候,comment说明字段包含中文,表成功创建成功之后,中文说明显示乱码
create external table movie( userID int comment '用户ID', movieID int comment '电影ID', rating int comment '电影评分', timestamped bigint comment '评分时间戳', movieName string comment '电影名字', movieType string comment '电影类型', sex string comment '性别', age int comment '年龄', occupation string comment '职业', zipcode string comment '邮政编码' ) comment '影评三表合一' row format delimited fields terminated by "," location '/hive/movie';

这是因为在MySQL中的元数据出现乱码
针对元数据库metastore中的表,分区,视图的编码设置
因为我们知道 metastore 支持数据库级别,表级别的字符集是 latin1
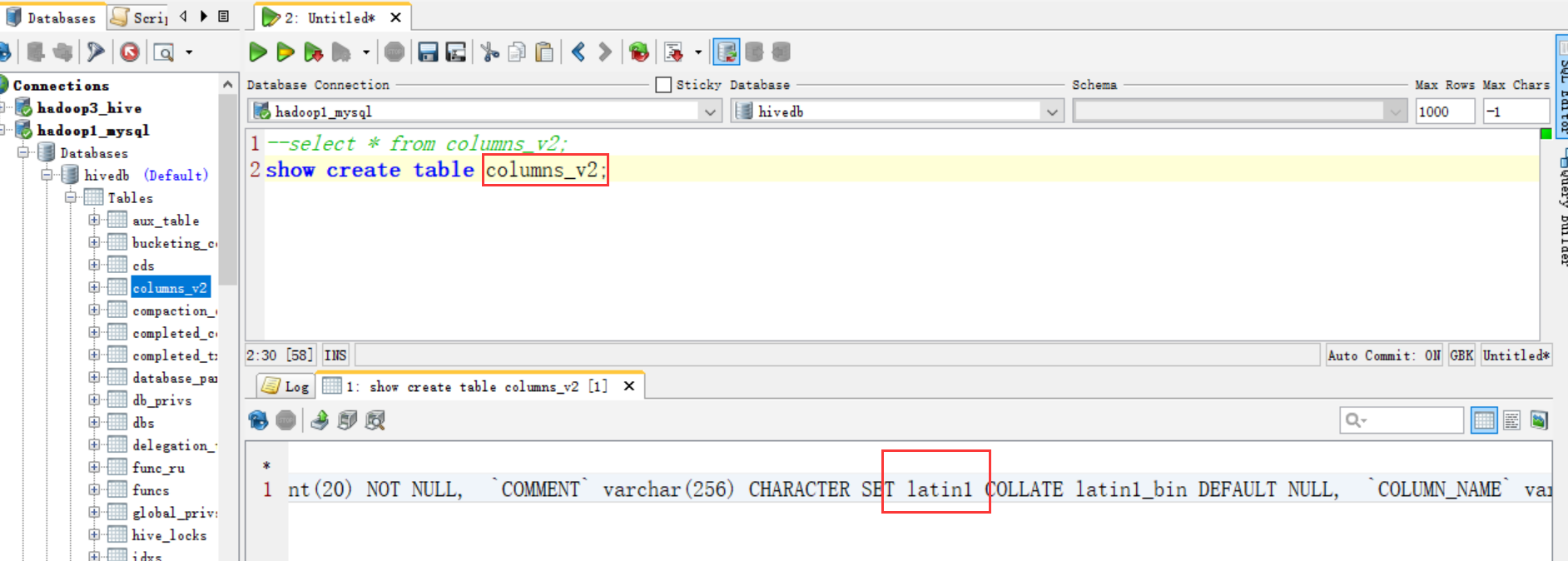
那么我们只需要把相应注释的地方的字符集由 latin1 改成 utf-8,就可以了。用到注释的就三个地方,表、分区、视图。如下修改分为两个步骤:
1、进入数据库 Metastore 中执行以下 5 条 SQL 语句
(1)修改表字段注解和表注解
alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8; alter table TABLE_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
(2)修改分区字段注解
alter table PARTITION_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8 ; alter table PARTITION_KEYS modify column PKEY_COMMENT varchar(4000) character set utf8;
(3)修改索引注解
alter table INDEX_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
2、修改 metastore 的连接 URL
修改hive-site.xml配置文件
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://IP:3306/db_name?createDatabaseIfNotExist=true&useUnicode=true&characterEncoding=UTF-8</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
验证
做完可以解决乱码问题

 浙公网安备 33010602011771号
浙公网安备 33010602011771号