Hystrix - 断路器 Circuit Breaker + 滑动窗口
一、断路器 Circuit Breaker
1.1 断路器的三个状态
断路器是Hystrix最核心的状态机,有三个状态:
- CLOSED关闭状态:允许流量通过。
- OPEN打开状态:不允许流量通过,即处于降级状态,走降级逻辑。
- HALF_OPEN半开状态:允许某些流量通过,并关注这些流量的结果,如果出现超时、异常等情况,将进入OPEN状态,如果成功,那么将进入CLOSED状态。
1.2 断路器配置
//滑动窗口的大小,默认为20 circuitBreaker.requestVolumeThreshold //过多长时间,熔断器再次检测是否开启,默认为5000,即5s钟 circuitBreaker.sleepWindowInMilliseconds //错误率,默认50% circuitBreaker.errorThresholdPercentage
1.3 三个状态的转换逻辑
CLOSED -> OPEN :
时间窗口内(默认10秒)请求量大于请求量阈值(即circuitBreaker.RequestVolumeThreshold,默认值是20),并且该时间窗口内错误率大于错误率阈值(即circuitBreaker.ErrorThresholdPercentage,默认值为50,表示50%),那么断路器的状态将由默认的CLOSED状态变为OPEN状态。
OPEN ->HALF_OPEN:
当熔断器状态为open状态时候,所有 [服务调用方] 调用该服务方法时候都是执行本地降级方法,那么什么时候才会恢复到远程调用呢?Hystrix提供了一种测试策略,也就是设置了一个时间窗口(circuitBreaker.sleepWindowInMilliseconds,默认是5秒),从熔断器状态变为open状态开始的一个时间窗口内,调用该服务接口时候都委托服务降级方法进行执行。如果时间超过了时间窗口,则把熔断状态从open->half-open...
HALF_OPEN ->CLOSED :
变为half-open半开状态后,会放第一笔请求去执行,并跟踪它的执行结果,如果是成功,那么将由HALF_OPEN状态变成CLOSED状态
HALF_OPEN ->OPEN :
变为half-open半开状态时,如果第一笔被放去执行的请求执行失败(资源获取失败、异常、超时等),就会由HALP_OPEN状态再变为OPEN状态。还会重新记录时间窗口的开始时间(circuitBreaker.sleepWindowInMilliseconds,默认是5秒)。

1.4 断路器状态转换,如何保证线程安全
为了能做到状态能按照指定的顺序来流转,并且是线程安全的,断路器的实现类HystrixCircuitBreakerImpl使用了AtomicReference。断路器在状态变化时,使用了AtomicReference.compareAndSet()来确保当条件满足时,只有一笔请求能成功改变状态。
enum Status { CLOSED, OPEN, HALF_OPEN; } // 断路器初始状态肯定是关闭状态 private final AtomicReference<Status> status = new AtomicReference<Status>(Status.CLOSED);
二、滑动窗口
2.1 总结
上面提到的断路器需要的时间窗口请求量和错误率这两个统计数据,都是指固定时间长度内的统计数据,断路器的目标,就是根据这些统计数据来预判并决定系统下一步的行为,Hystrix通过滑动窗口来对数据进行“平滑”统计,默认情况下,一个滑动窗口包含10个桶(Bucket),每个桶时间宽度是1秒,负责1秒的数据统计。滑动窗口包含的总时间以及其中的桶数量都是可以配置的,来张官方的截图认识下滑动窗口:

上图的每个小矩形代表一个桶,可以看到,每个桶都记录着1秒内的四个指标数据:成功量、失败量、超时量和拒绝量,这里的拒绝量指的就是上面流程图中【信号量/线程池资源检查】中被拒绝的流量。10个桶合起来是一个完整的滑动窗口,所以计算一个滑动窗口的总数据需要将10个桶的数据加起来。
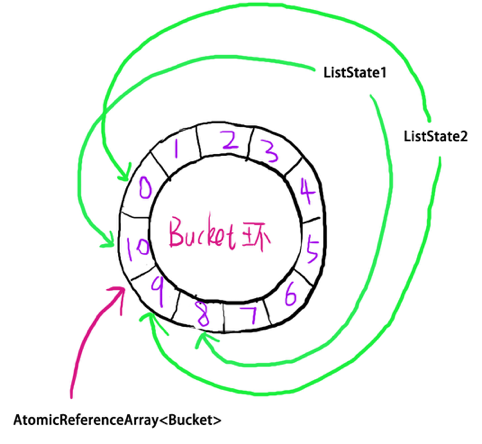
滑动窗口由多个桶组成,业界一般的做法是将数组做成环,Hystrix中也类似,多个桶是放在AtomicReferenceArray<Bucket>来维护的。我们可以看到,由于默认一个滑动窗口包含10个桶,所以AtomicReferenceArray<Bucket>的size得达到10+1=11才能“滑动/滚动”起来,在确定的某一秒内,只有一个桶被更新,其他的桶数据都没有变化。
2.2 详细说明
我们现在来具体看看滑动窗口和桶的设计,如果将滑动窗口设计成对一个长度为10的整形数组的操作,第一个想到的应该是AtomicLongArray,AtomicLongArray中每个位置的数据都能线程安全的操作,提供了譬如incrementAndGet、getAndSet、compareAndSet等常用方法。但由于一个桶需要维护四个指标,如果用四个AtomicLongArray来实现,做法不够高级,于是我们想到了AtomicReferenceArray<Bucket>,Bucket对象内部可以用AtomicLong来维护着这四个指标。滑动窗口和桶的设计特别讲究技巧,需要尽可能做到性能、数据准确性两方面的极致,我们来看Hystrix是如何做到的。
桶的数据统计简单来说可以分为两类,一类是简单自增计数器,比如请求量、错误量等,另一类是并发最大值,比如一段时间内的最大并发量(或者说线程池的最大任务数),下面是桶类Bucket的定义:
class Bucket { // 标识是哪一秒的桶数据 final long windowStart; // 如果是简单自增统计数据,那么将使用adderForCounterType final LongAdder[] adderForCounterType; // 如果是最大并发类的统计数据,那么将使用updaterForCounterType final LongMaxUpdater[] updaterForCounterType; Bucket(long startTime) { this.windowStart = startTime; // 预分配内存,提高效率,不同事件对应不同的数组index adderForCounterType = new LongAdder[HystrixRollingNumberEvent.values().length]; for (HystrixRollingNumberEvent type : HystrixRollingNumberEvent.values()) { if (type.isCounter()) { adderForCounterType[type.ordinal()] = new LongAdder(); } } // 预分配内存,提高效率,不同事件对应不同的数组index updaterForCounterType = new LongMaxUpdater[HystrixRollingNumberEvent.values().length]; for (HystrixRollingNumberEvent type : HystrixRollingNumberEvent.values()) { if (type.isMaxUpdater()) { updaterForCounterType[type.ordinal()] = new LongMaxUpdater(); // initialize to 0 otherwise it is Long.MIN_VALUE updaterForCounterType[type.ordinal()].update(0); } } } ...略... }
我们可以看到,并没有用所谓的AtomicLong,为了方便的管理各种事件(参见com.netflix.hystrix.HystrixEventType)的数据统计,Hystrix对不同的事件使用不同的数组index(即枚举的顺序),这样对于某个桶(即某一秒)的指定类型的数据,总能从数组中找到对应的LongAdder(用于统计前面说的简单自增)或LongMaxUpdater(用于统计前面说的最大并发值)对象来进行自增或更新操作。对于性能有要求的中间件或库类都避不开要CPUCache优化的问题,比如cache line,以及cache line带来的false sharing问题。Bucket的内部并没有使用AtomicLong,而是使用了JDK8新提供的LongAdder,在高并发的单调自增场景,LongAdder提供了比AtomicLong更好的性能,至于LongAdder的设计思想,本文不展开,感兴趣的朋友可以去拜读Doug Lea大神的代码(有意思的是Hystrix没有直接使用JDK中的LongAdder,而是copy过来改了改)。LongMaxUpdater也是类似的,它和LongAddr一样都派生于Striped64,这里不再展开。
滑动窗口由多个桶组成,业界一般的做法是将数组做成环,Hystrix中也类似,多个桶是放在AtomicReferenceArray<Bucket>来维护的,为了将其做成环,需要保存头尾的引用,于是有了ListState类:
class ListState { /* * 这里的data之所以用AtomicReferenceArray而不是普通数组,是因为data需要 * 在不同的ListState对象中跨线程来引用,需要可见性和并发性的保证。 */ private final AtomicReferenceArray<Bucket> data; private final int size; private final int tail; private final int head; private ListState(AtomicReferenceArray<Bucket> data, int head, int tail) { this.head = head; this.tail = tail; if (head == 0 && tail == 0) { size = 0; } else { this.size = (tail + dataLength - head) % dataLength; } this.data = data; } ...略... }
我们可以发现,真正的数据是data,而ListState只是一个时间段的数据快照而已,所以tail和head都是final,这样做的好处是我们不需要去为head、tail的原子操作而苦恼,转而变成对ListState的持有操作,所以滑动窗口看起来如下:
我们可以看到,由于默认一个滑动窗口包含10个桶,所以AtomicReferenceArray<Bucket>的size得达到10+1=11才能“滑动/滚动”起来,在确定的某一秒内,只有一个桶被更新,其他的桶数据都没有变化。既然通过ListState可以拿到所有的数据,那么我们只需要持有最新的ListState对象即可,为了能做到可见性和原子操作,于是有了环形桶类BucketCircularArray:
class BucketCircularArray implements Iterable<Bucket> { // 持有最新的ListState private final AtomicReference<ListState> state; ...略... }
我们注意到BucketCircularArray实现了迭代器接口,这是因为我们输出给断路器的数据需要计算滑动窗口中的所有桶,于是你可以看到真正的滑动窗口类HystrixRollingNumber有如下属性和方法:
public class HystrixRollingNumber { // 环形桶数组 final BucketCircularArray buckets; // 获取该事件类型当前滑动窗口的统计值 public long getRollingSum(HystrixRollingNumberEvent type) { Bucket lastBucket = getCurrentBucket(); if (lastBucket == null) return 0; long sum = 0; // BucketCircularArray实现了迭代器接口环形桶数组 for (Bucket b : buckets) { sum += b.getAdder(type).sum(); } return sum; } ...略... }
断路器就是通过监控来从HystrixRollingNumber的getRollingSum方法来获取统计值的。
到这里断路器和滑动窗口的核心部分已经分析完了,当然里面还有不少细节没有提到,感兴趣的朋友可以去看一下源码。Hystrix中通过RxJava来实现了事件的发布和订阅,所以如果想深入了解Hystrix,需要熟悉RxJava,而RxJava在服务端的应用没有像客户端那么广,一个原因是场景的限制,还一个原因是大多数开发者认为RxJava设计的过于复杂,加上响应式编程模型,有一定的入门门槛。
参考文献
————————————————
版权声明:本文为CSDN博主「飞向札幌的班机」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/manzhizhen/article/details/80296655

 浙公网安备 33010602011771号
浙公网安备 33010602011771号