
数据分析系列_1
通常,我们进行数据分析的步骤都是经过从数据的识别、数据的获取、数据的清洗、数据的持久化、数据建模、数据可视化...这一系列的过程。而这里面的每一步,都包含了大量的内容。数据科学技术属于交叉学科,不仅仅需要学习数据科学的系列课程,同时也要对所分析的学科有一些数据的概念和行业的了解。
案例1、(汽车之家数据爬取)
①、数据的识别
打开汽车之家网站,二手车的页面,我们可以看到里面的车辆信息,(品牌、年份、型号、公里数、上牌时间、上牌属地、汽车之家会员会龄、现价、新车指导价、上架属性、过户次数)这些都是作为购买二手车的最基本的一些重要信息。我们需要获取这些数据作为后续的用途。
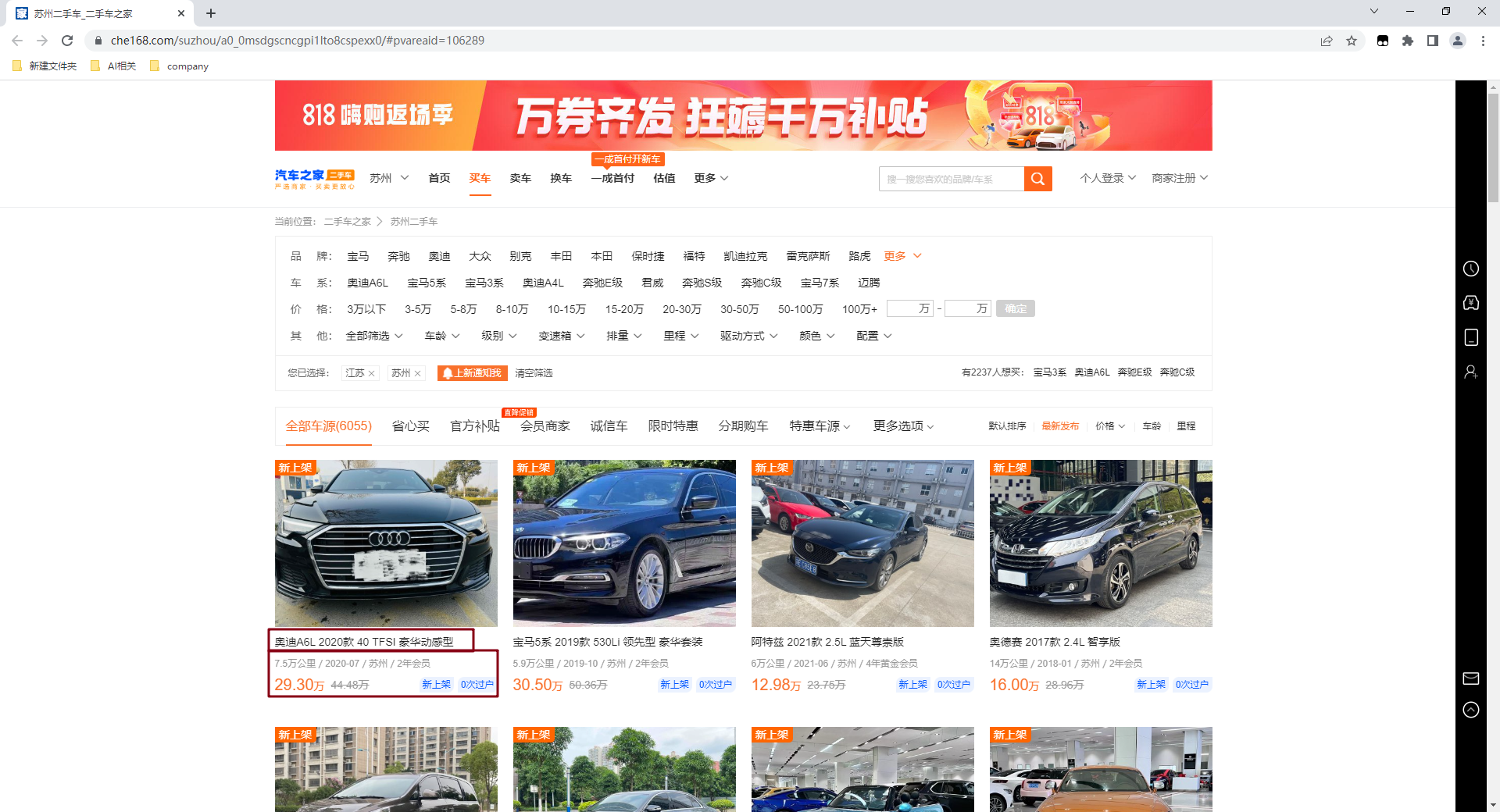
②、数据的获取
此时就需要写一个爬虫代码对数据进行爬取,那我们应该怎样进行爬取呢?
首先,分析网页的链接,我们打开第一页,发现链接是这样的。

打开第二页,对比第一页的链接有哪些变化呢?
https://www.che168.com/suzhou/a0_0msdgscncgpi1lto8csp2exx0/?pvareaid=102179#currengpostion

再打开后面的页面,比如这里我打开第98页,跟第一页和第二页有什么区别呢?
细心的你肯定就发现了,除了 csp后面的数字跟随页数发生变化,其他的都是保持一致的,那我们再次实施第一页,把数字改为1能不能跟第一页一致呢?再次打开,发现还是一致的。所以这个数字的这个位置我们就可以设置为一个变量,用于递增爬取每个页面。
https://www.che168.com/suzhou/a0_0msdgscncgpi1lto8csp98exx0/?pvareaid=102179#currengpostion

然后我们F12打开网页,复制这些信息。
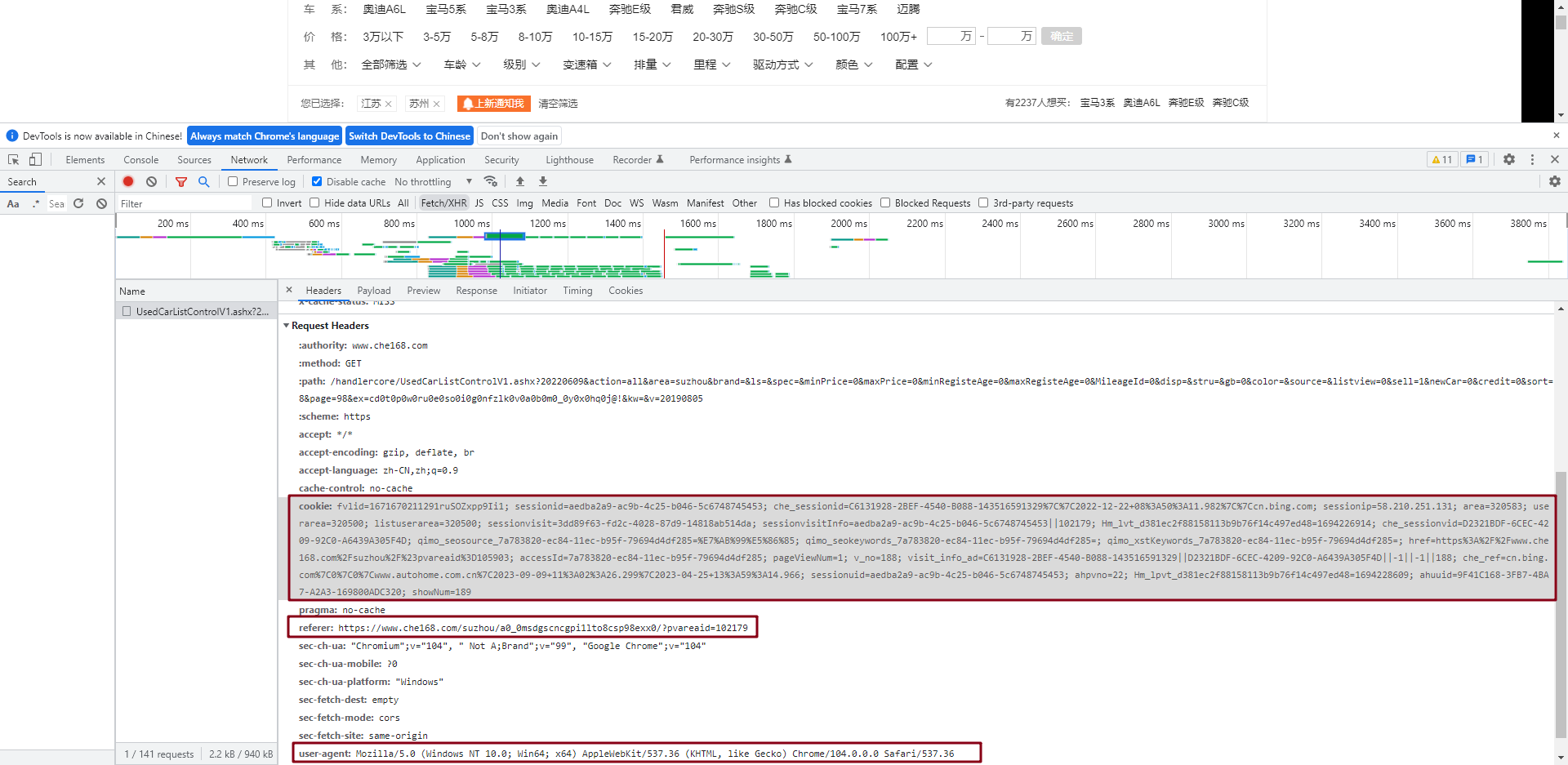
此时,运行这个程序,证明我们的访问是成功的,没有拦截。
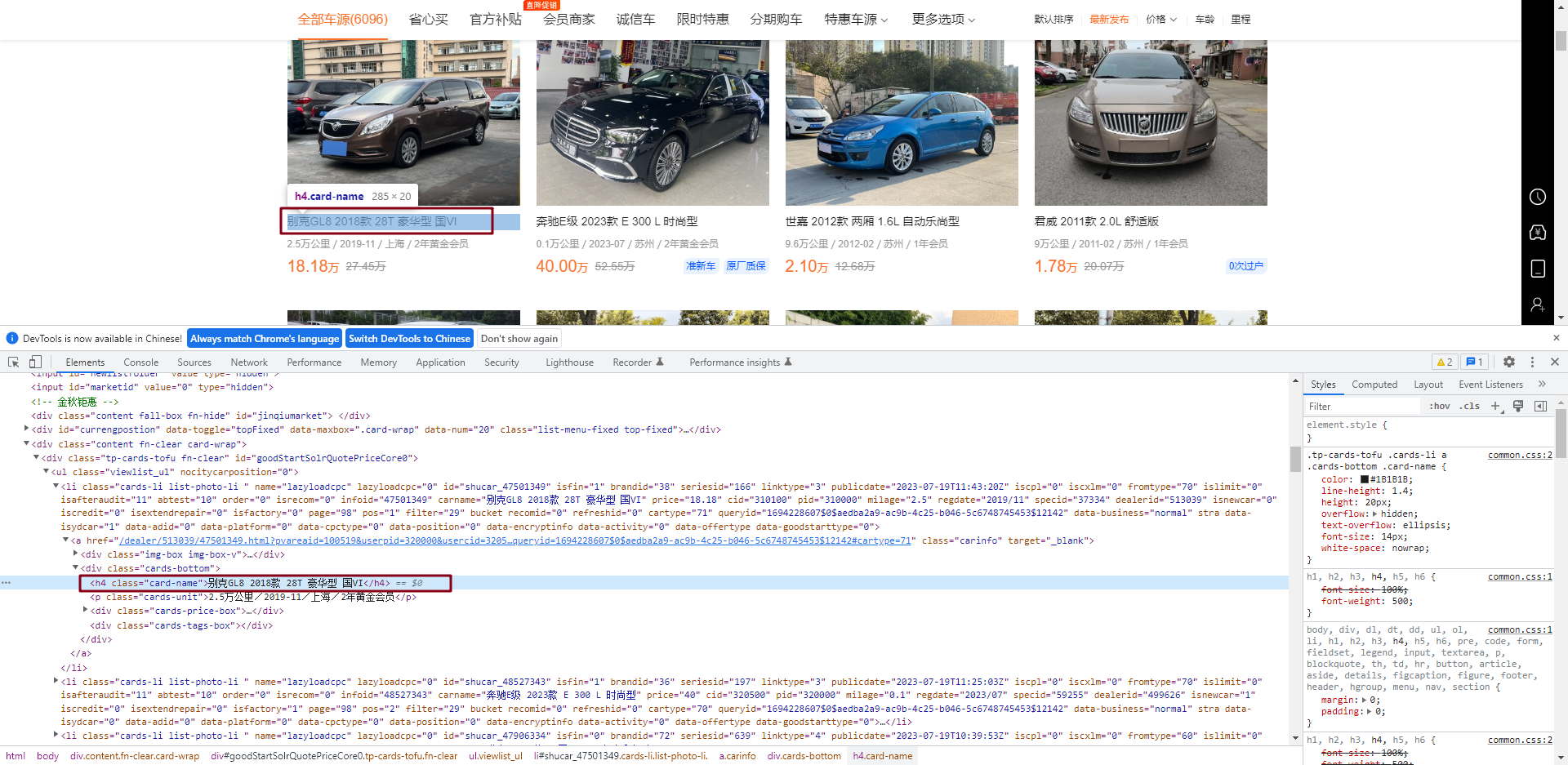
打开 F12 网页调试工具,我们发现,每一辆车的信息都包含在了 viewlist_ul 这个下面。就是<ul>标签下面包含<li>的这种结构
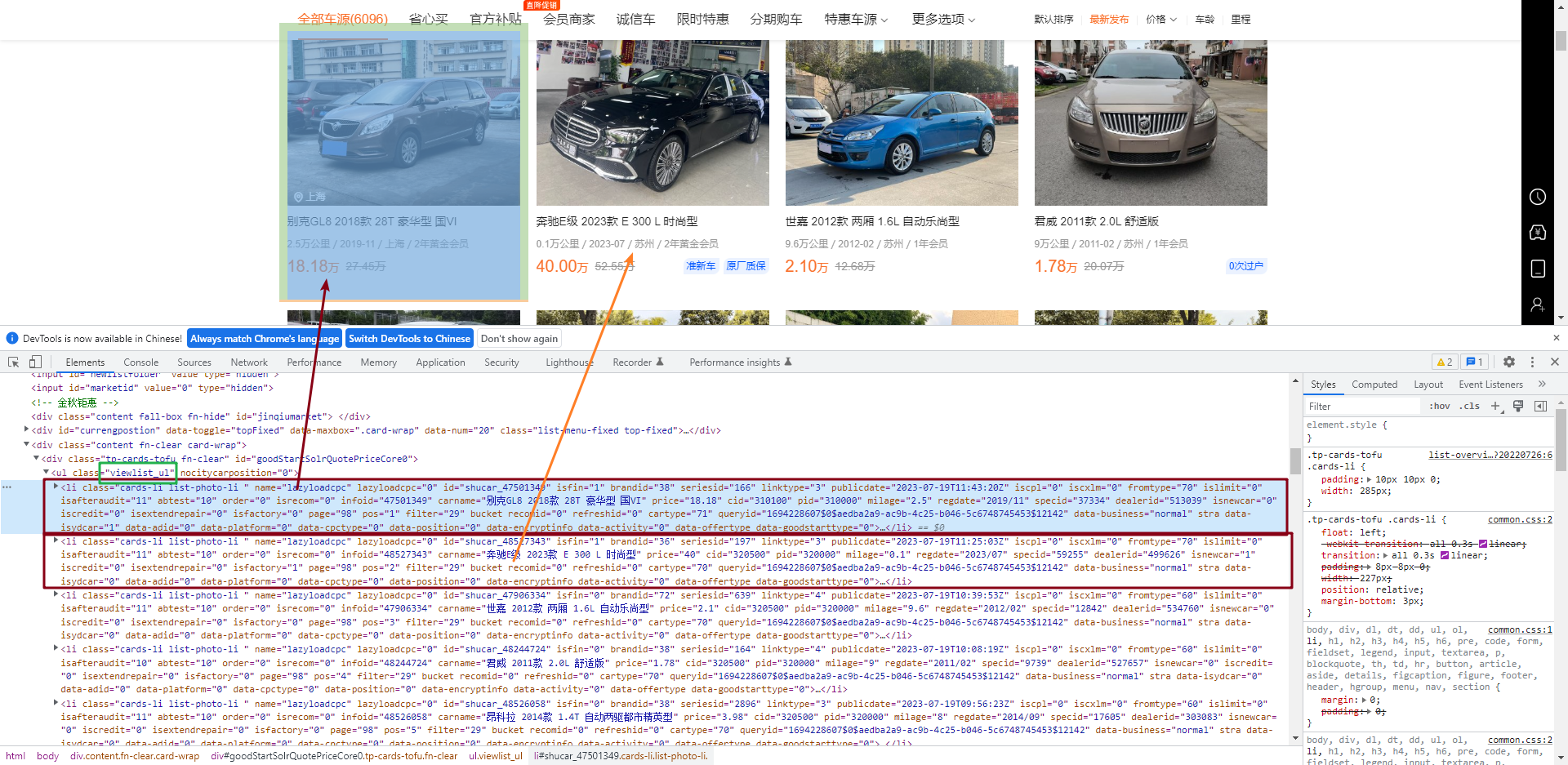
然后,我们可以看到标题 “别克GLB 2018款 28T 豪华型 国Ⅵ ” 包含在了<h4>标签下面,名称为.card-name。
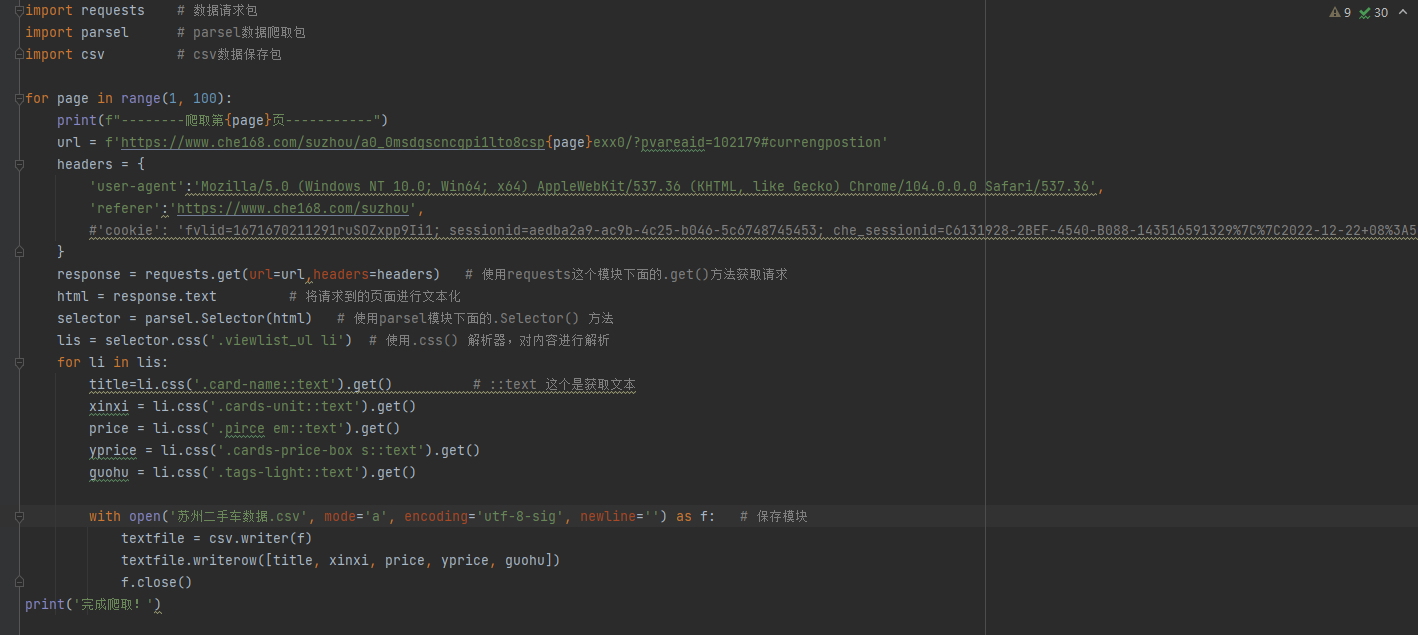
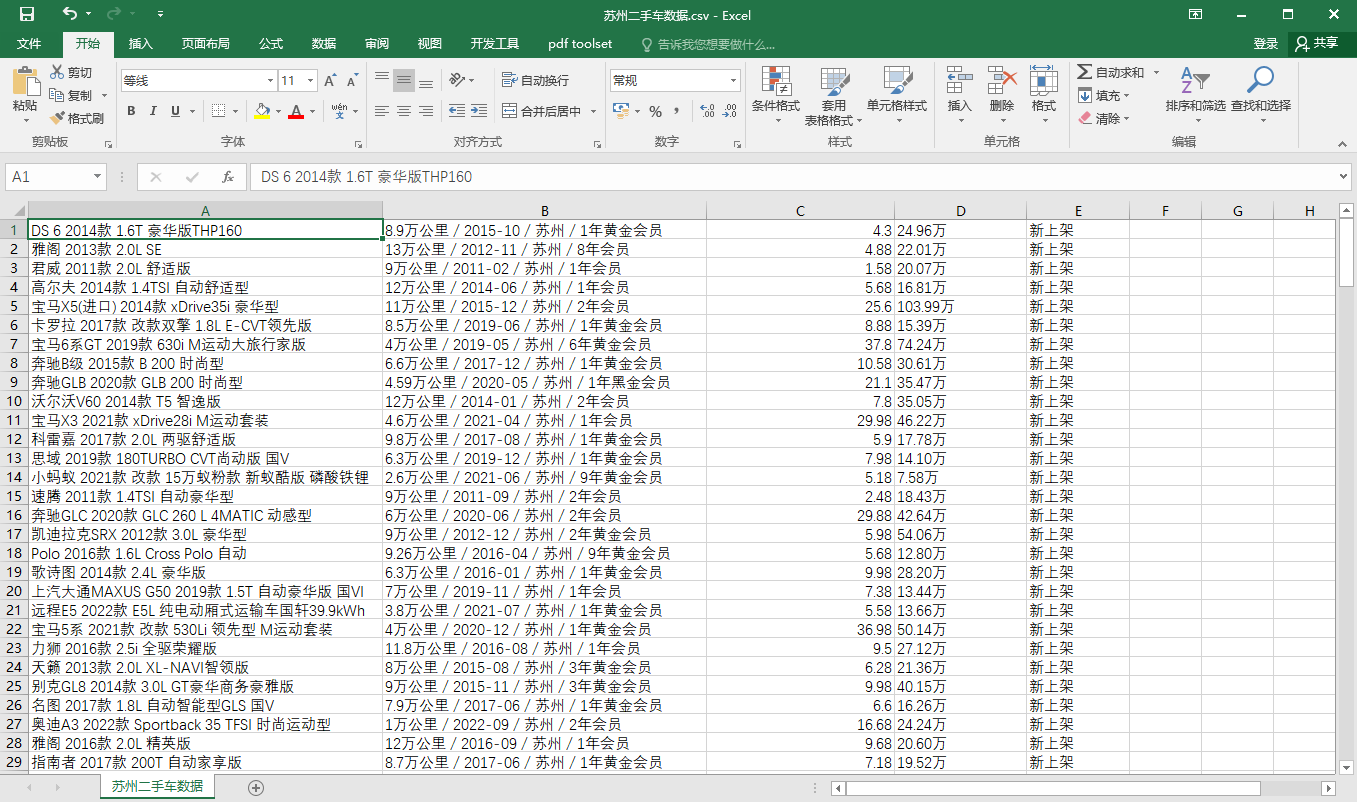
此时,我们已经将数据爬取保存到了我们本地,但是还需要使用 Excel 的分栏功能,对数据进行分栏处理。
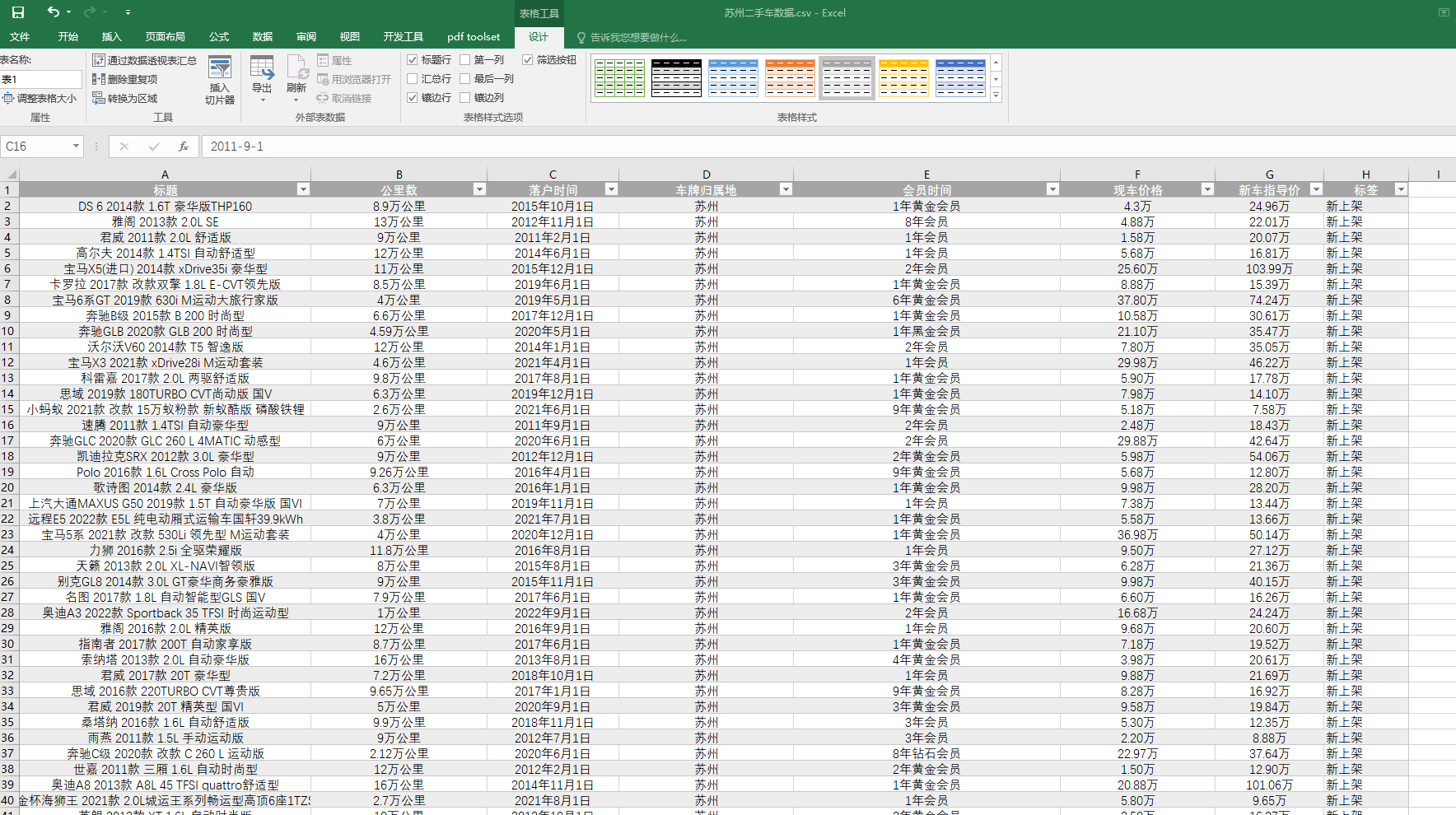
经过了简单的处理,我们可以看到现在的数据看起来舒服多了。
③、
数据分析 ....待续
④、

 浙公网安备 33010602011771号
浙公网安备 33010602011771号