
爬虫实战(安居客二手房和租房信息爬取)
不说废话,直接上代码!
import requests import csv import parsel # 解析数据 # 安居客二手房信息 # 网页源代码解析 # json数据解析 for page in range(1,51): print(f"正在爬取第-----{page}------页数据信息!") url=f'https://anjuke.com/sale/p{page}/' header = { 'cookie': 'sessid=E8557945-A48A-DECA-D8A1-102112E95525; aQQ_ajkguid=6005B887-989E-9E1E-EB74-C01BBCE2362D; twe=2; ajk-appVersion=; fzq_h=3cdd8dc4ff49c08b22268609df890299_1670208027764_406af778a32a4516a91f70fef3d1409d_986905475; id58=CrIclWONWihf8mLgZefRAg==; ctid=231; lps=https%3A%2F%2Fyx.zu.anjuke.com%2F%7Chttps%3A%2F%2Fyuxi.anjuke.com%2F; cmctid=2040; wmda_uuid=48c23ab83834bd513b73a85f47e86a23; wmda_new_uuid=1; wmda_session_id_6289197098934=1670208078386-18df4190-2941-5746; wmda_visited_projects=%3B6289197098934; obtain_by=1; xxzl_cid=df78ca61c6fa40b680bd980d2ff3bd01; xxzl_deviceid=out+sEolHB8HXmPxXFzGJuGNceTZiUsWOVAr25QoCxZqXuiGQDtGyv3aQwmOHRGV', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36', 'referer': 'https://yx.zu.anjuke.com/fangyuan/' } response = requests.get(url=url,headers=header) html_data = response.text # print(response) selectors = parsel.Selector(html_data) lis = selectors.css('.property-content') for li in lis: 标题 = li.css('.property-content-title-name::text').get() 户型 = li.css('.property-content-info:nth-child(1) .property-content-info-text:nth-child(1) span::text').getall() 面积 = li.css('.property-content-info:nth-child(1) .property-content-info-text:nth-child(2)::text').getall() 朝向 = li.css('.property-content-info:nth-child(1) .property-content-info-text:nth-child(3)::text').get() 楼层 = li.css('.property-content-info:nth-child(1) .property-content-info-text:nth-child(4)::text').get() 建造时间 = li.css('.property-content-info:nth-child(1) .property-content-info-text:nth-child(5)::text').get() 小区名称 = li.css('.property-content-info:nth-child(2) .property-content-info-comm-name::text').getall() 小区地址 = li.css('.property-content-info:nth-child(2) .property-content-info-comm-address span::text').getall() 总价 = li.css('.property-price .property-price-total .property-price-total-num::text').getall() 单价 = li.css('.property-price .property-price-average::text').getall() print(标题) with open('./txt/玉溪安居客二手房.csv',mode='a+',encoding='utf-8-sig',newline='') as f: csv_text = csv.writer(f) csv_text.writerow((标题,户型,面积,朝向,楼层,建造时间,小区名称,小区地址,总价,单价)) print("爬取完成!")
这是爬取下来的格式,当然里面的标点符号我替换掉了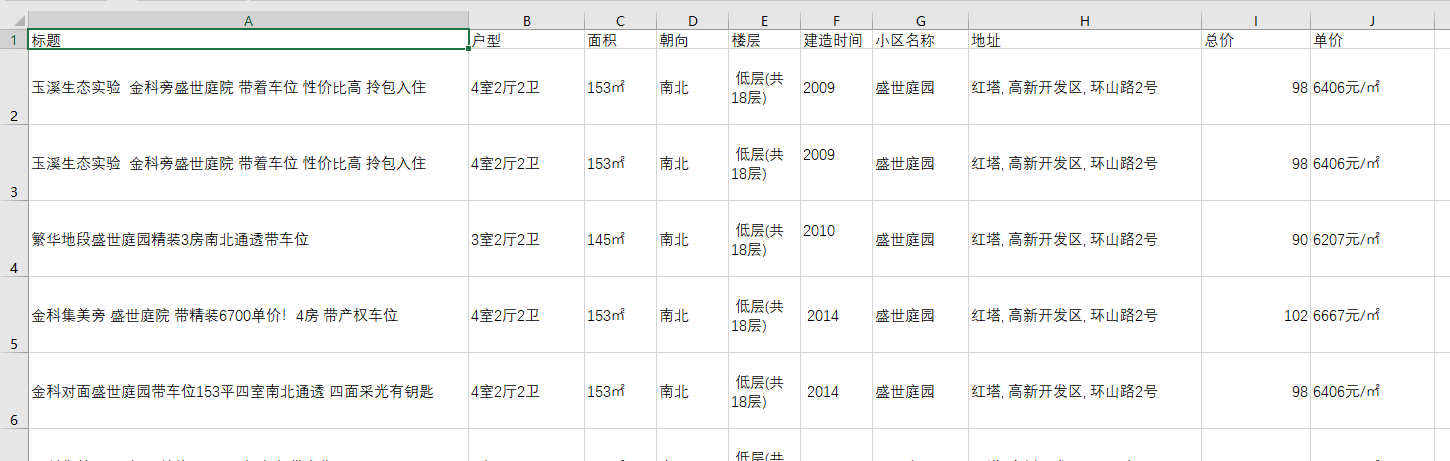
租房信息:
import requests import csv import parsel # 解析数据 # 安居客租房信息 # 网页源代码解析 # json数据解析 for page in range(1,34): print(f"正在爬取第-----{page}------页数据信息!") url=f'https://yx.zu.anjuke.com/fangyuan/p{page}/' header = { 'cookie': 'sessid=E8557945-A48A-DECA-D8A1-102112E95525; aQQ_ajkguid=6005B887-989E-9E1E-EB74-C01BBCE2362D; twe=2; ajk-appVersion=; fzq_h=3cdd8dc4ff49c08b22268609df890299_1670208027764_406af778a32a4516a91f70fef3d1409d_986905475; id58=CrIclWONWihf8mLgZefRAg==; ctid=231; lps=https%3A%2F%2Fyx.zu.anjuke.com%2F%7Chttps%3A%2F%2Fyuxi.anjuke.com%2F; cmctid=2040; wmda_uuid=48c23ab83834bd513b73a85f47e86a23; wmda_new_uuid=1; wmda_session_id_6289197098934=1670208078386-18df4190-2941-5746; wmda_visited_projects=%3B6289197098934; obtain_by=1; xxzl_cid=df78ca61c6fa40b680bd980d2ff3bd01; xxzl_deviceid=out+sEolHB8HXmPxXFzGJuGNceTZiUsWOVAr25QoCxZqXuiGQDtGyv3aQwmOHRGV', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36', 'referer': 'https://yx.zu.anjuke.com/fangyuan/' } response = requests.get(url=url,headers=header) html_data = response.text # print(response) selectors = parsel.Selector(html_data) lis = selectors.css('.zu-itemmod') for li in lis: 标题 = li.css('.zu-info .strongbox::text').get() 户型 = li.css('.zu-info .strongbox::text').getall()[1]+'室'+li.css('.strongbox::text').getall()[2]+'厅' 面积 = li.css('.zu-info .strongbox::text').getall()[3]+'㎡' 价格 = li.css('.zu-side .strongbox::text').getall() 出租类型 = li.css('.zu-info .cls-1::text').getall() 朝向 = li.css('.zu-info .cls-2::text').getall() 电梯 = li.css('.zu-info .cls-3::text').getall() 位置 = li.css('.zu-info .details-item::text').getall()[8] 小区 = li.css('.zu-info a::text').getall() 楼层 = li.css('.zu-info p::text').getall()[4] 联系人 = li.css('.zu-info p::text').getall()[5] print(位置) with open('./txt/玉溪安居客租房.csv',mode='a+',encoding='utf-8-sig',newline='') as f: csv_text = csv.writer(f) csv_text.writerow((标题,户型,面积,价格,出租类型,朝向,电梯,位置,小区,楼层,联系人)) print("爬取完成!")
这是爬取后修改为.xlsx格式的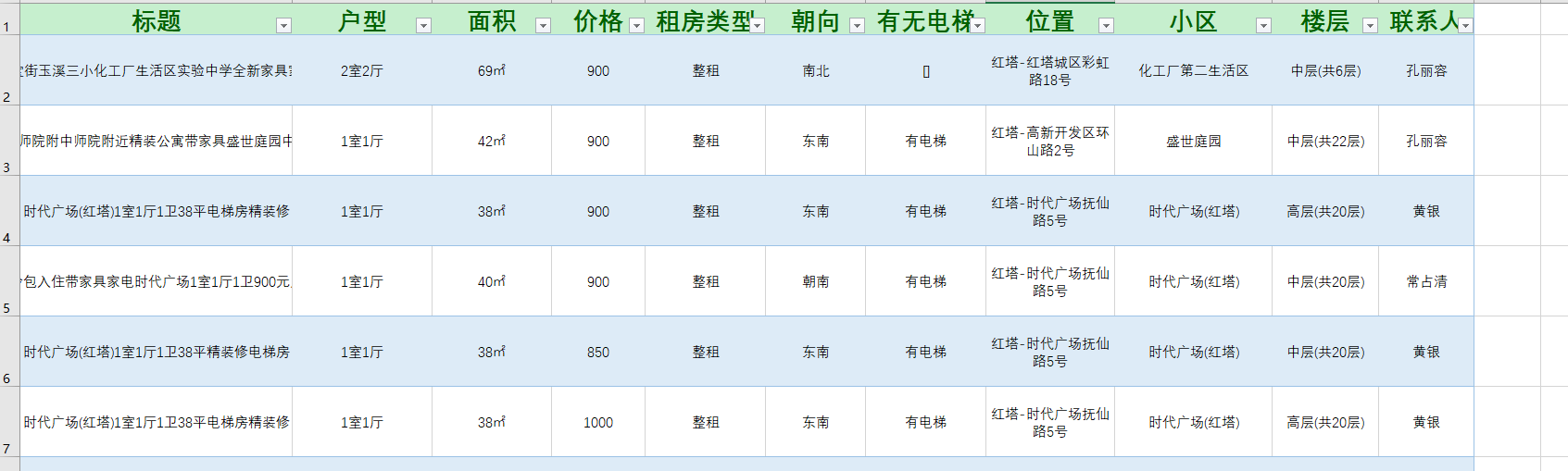
懂得都懂。现在爬取数据,后续更新对于数据的处理的内容文章!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号