
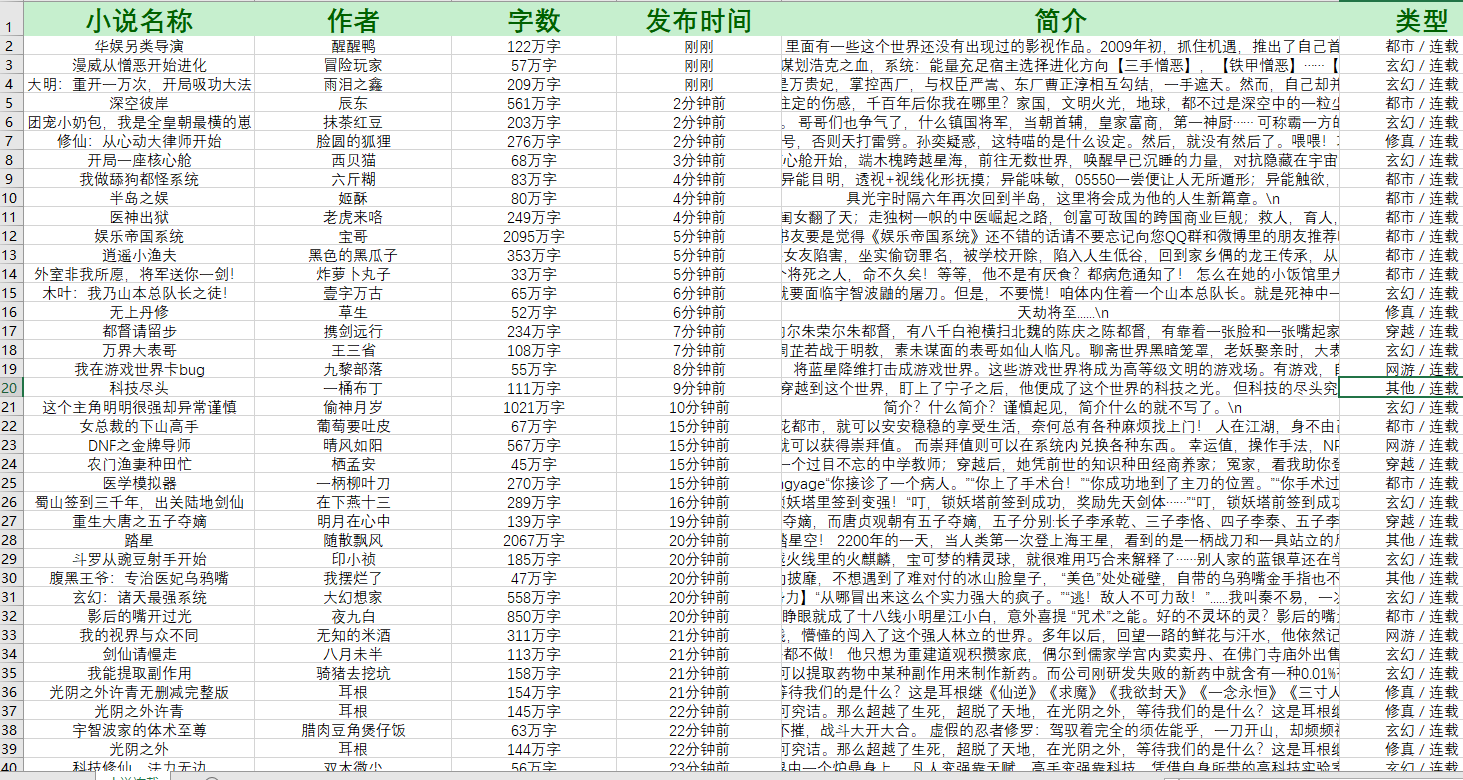
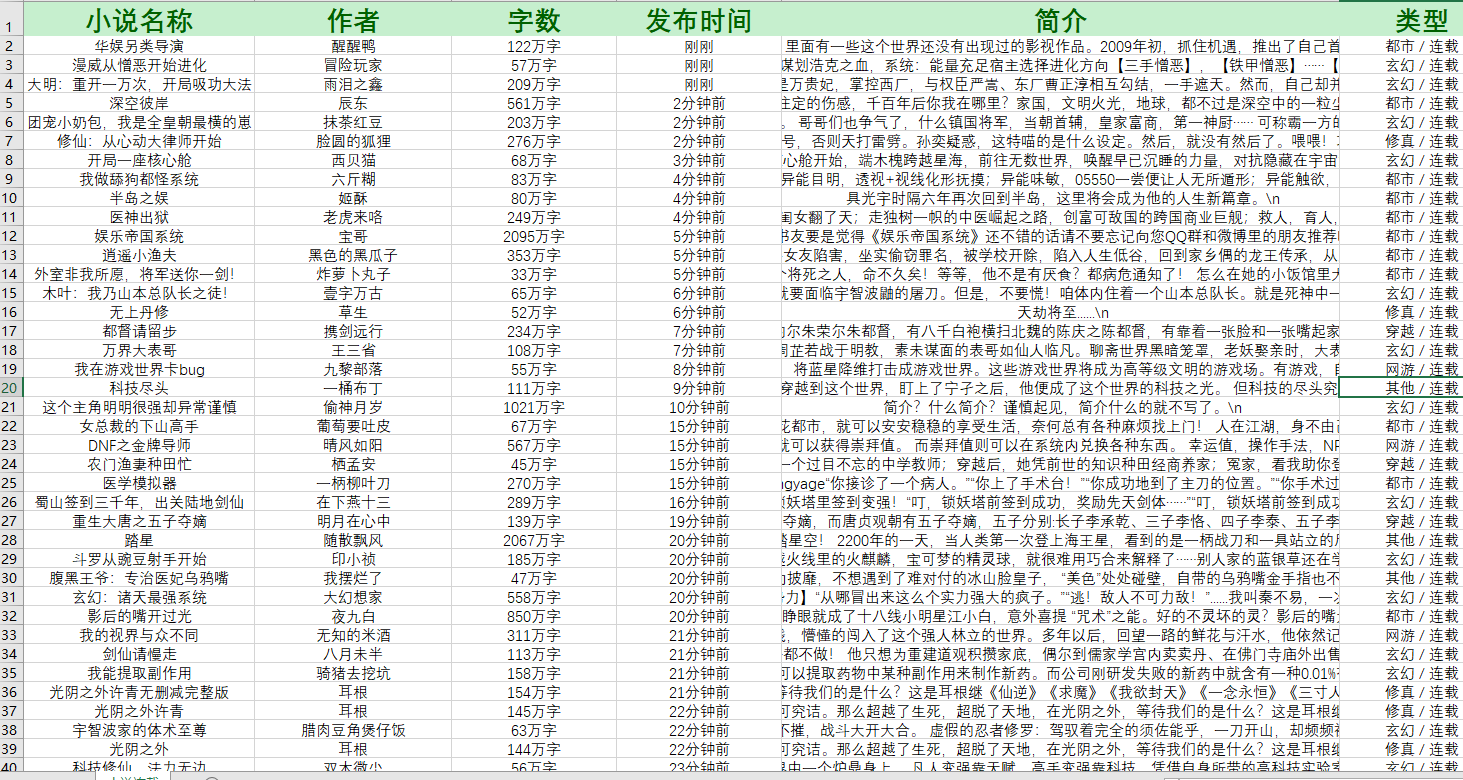
爬虫实战-爬取小说信息
import requests
import parsel
import csv
for i in range(1,5):
print(f"--------爬取第{i}页-----------")
url = f'https://www.slyqw.com/sort/{i}'
header = {
'User-Agent': 'Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 107.0.0.0Safari / 537.36',
'Cookie': 'zh_choose = s;Hm_lvt_c4eec4b108dac241786b4218f0d27642 = 1669790844;Hm_lpvt_c4eec4b108dac241786b4218f0d27642 = 1669791342',
'Referer': 'https: // www.slyqw.com / whole.html'
}
# 通过requests 模拟发送请求
r = requests.get(url=url,headers=header)
response = r.text
# 引入pansel模块
response = parsel.Selector(response)
lis = response.css('.flex li')
for li in lis:
leibie = li.css('.img_span span::text').getall()
title = li.css('.w100 a h2::text').getall()
zuozhe = li.css('.w100 div i::text').getall()
zishu = li.css('.w100 div .orange::text').getall()
shijian = li.css('.w100 div .blue::text').getall()
jieshao = li.css('.w100 p::text').getall()
link = li.css('.w100 a::attr(href)')[0].getall()
print(link)
with open('小说连载.csv',mode='a',encoding='utf-8-sig',newline='') as f:
writefile = csv.writer(f)
writefile.writerow([title,zuozhe,zishu,shijian,leibie,jieshao,link])
print("完成!")
以上信息是爬取 5 页小说的信息。当然爬取信息之后需要在excel里面转换替换一下不要的字符,这里也可以在代码里面直接写 .replace()方法替换,我是直接用的excel的 ctrl+H 进行替换的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号