
nifi-大数据基础02——基本使用介绍
1、主页面概况
界面主体是一个画布的面板系统,最上面的是公共导航栏,左侧的Navigate没什么用,就是一个全局视角的查看,下面的Operate是一个组件控制面板,可以进行单个组件的控制,也可以选中一片组件进行统一的启动和停止等操作。
2、面板介绍
![]() 导航栏中的这个菜单,我们可以理解为处理器(Processor)商城,用鼠标单击拖出到画布上,便会出现处理器(Processor)菜单
导航栏中的这个菜单,我们可以理解为处理器(Processor)商城,用鼠标单击拖出到画布上,便会出现处理器(Processor)菜单
![]() 导航栏中这个菜单,我叫它为组,什么叫组呢,当你拉了很多处理器(Processor),形成了一个完整的流程的时候,我们可以单独把这块划分成一个整体了,这时候就要用组把它包裹起来。
导航栏中这个菜单,我叫它为组,什么叫组呢,当你拉了很多处理器(Processor),形成了一个完整的流程的时候,我们可以单独把这块划分成一个整体了,这时候就要用组把它包裹起来。
![]() 有了组以后,组和组之间可能也需要联通、通信,这时候就可以用入口和出口,把它们放在组内
有了组以后,组和组之间可能也需要联通、通信,这时候就可以用入口和出口,把它们放在组内
![]() 这个组件需要配合 Operate 中的 上传使用,主要是用来迁移模板的,这块后续会专门抽章节讲一下
这个组件需要配合 Operate 中的 上传使用,主要是用来迁移模板的,这块后续会专门抽章节讲一下
![]() 这一组件,是集群Nifi进行数据通信的时候用的
这一组件,是集群Nifi进行数据通信的时候用的
![]() 这一组件,就是个便签,用来写个备注呀啥的
这一组件,就是个便签,用来写个备注呀啥的
 这一组件就是个漏斗,主要作用就是把四散的数据可以汇集在一起。
这一组件就是个漏斗,主要作用就是把四散的数据可以汇集在一起。
3、Nifi的工作方式
Nifi其实就是一个数据接入、处理、清洗、分发的系统,它的工作方式就是将数据看作水管中的水,它是顺着某个流程管道流动,在这中间,可以在任意节点处堵截这个“水流”,并对它进行改造,然后放回管道继续向下流去。
Processor:这里的节点,其实就是Nifi的Processor,你叫它处理器也可以,叫他组件也好,它就是一个黑盒小模块,不同的模块有不同的功能
Relationship:节点和节点直接的通道,在Nifi里叫Relationship,我把它称之为管道,就像水管一样,它本身的意义就是充当水管,把上节点处理完的水传下去。
基本流程就是 : 选则一个处理器——>配置该组件至可运行状态——>关联下一组件建立管道
4、选择处理器
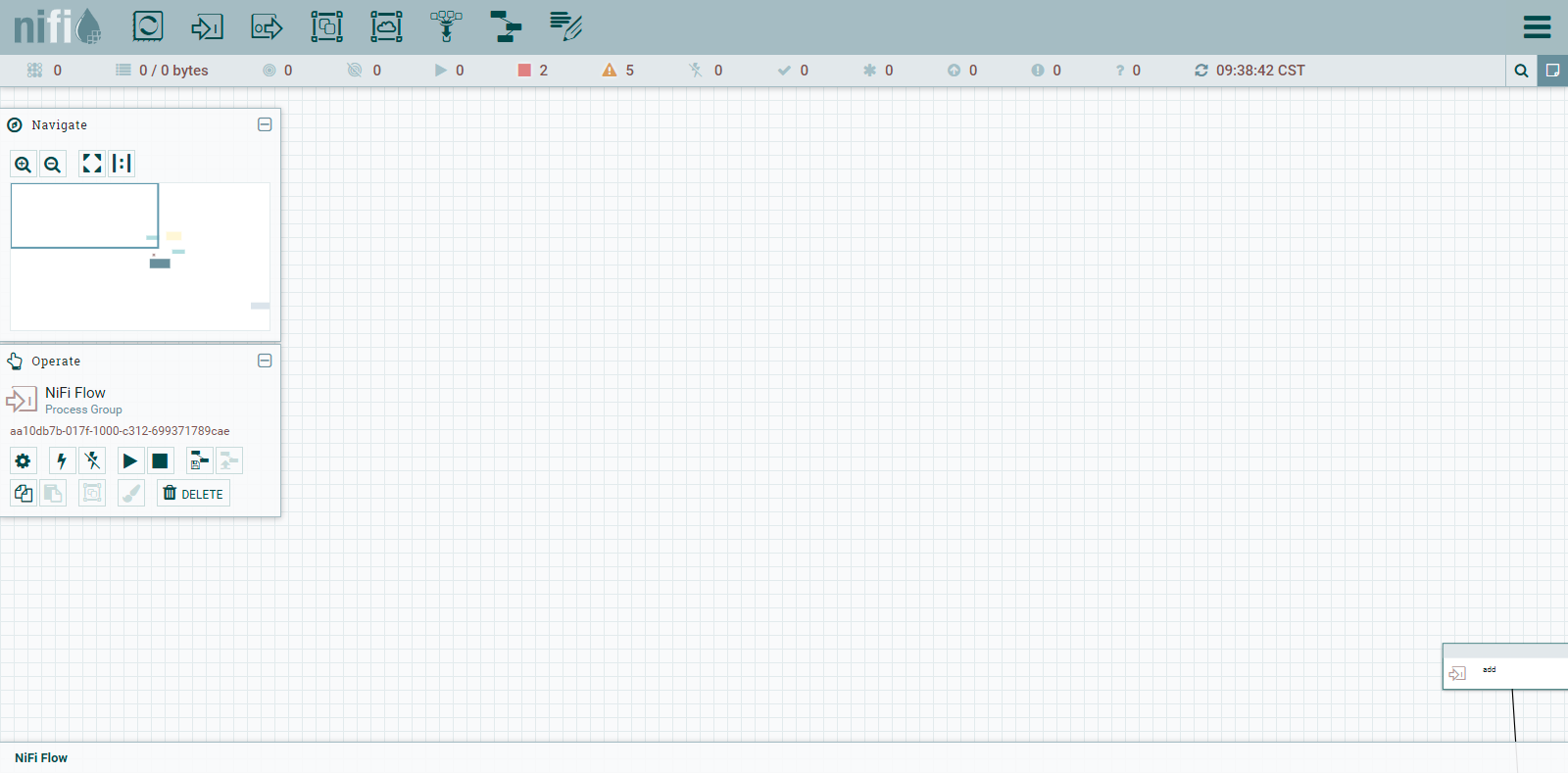
![]() 通过“组件商城” 图标进行处理器的选择, 处理器是最常用的组件,因为它负责数据的流入,流出,路由和操作。
通过“组件商城” 图标进行处理器的选择, 处理器是最常用的组件,因为它负责数据的流入,流出,路由和操作。
这里可以通过处理器的包、处理器的属性、处理器的名称等维度进行组件的筛选、选择。选中后,双击则可拖拉至画布中。
5、组件状态
-
状态:显示处理器的当前状态。以下指标是可能的:
-
![]() 正在运行:处理器当前正在运行。
正在运行:处理器当前正在运行。 -
![]() 已停止:处理器有效并已启用但未运行。
已停止:处理器有效并已启用但未运行。 -
![]() 无效:处理器已启用但当前无效且无法启动。将鼠标悬停在此图标上将提供工具提示,指示处理器无效的原因。一般情况下是需要我们完成必须的配置
无效:处理器已启用但当前无效且无法启动。将鼠标悬停在此图标上将提供工具提示,指示处理器无效的原因。一般情况下是需要我们完成必须的配置 -
![]() 已禁用:处理器未运行,在启用之前无法启动。此状态不表示处理器是否有效。
已禁用:处理器未运行,在启用之前无法启动。此状态不表示处理器是否有效。
-



-
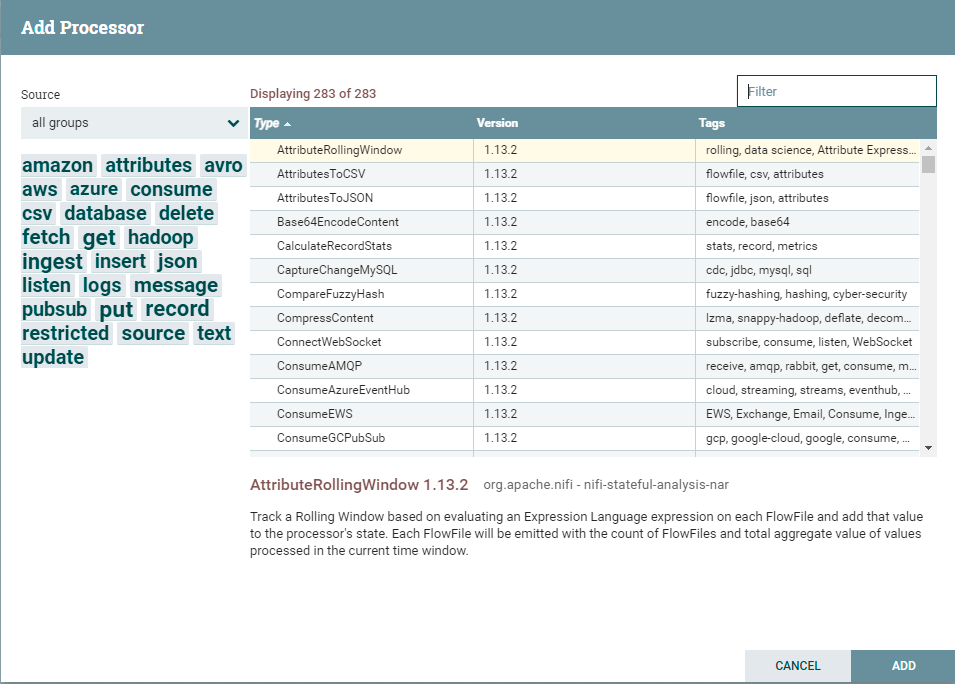
名称:这是处理器的用户定义名称。默认情况下组件的名称与它的Type相同。在示例中,此值为"ExecuteGroovyScript",是一个专门用于执行Groovy脚本的组件。
-
任务:此处理器当前正在执行的任务数。此数字受处理器配置对话框的计划选项卡中的并发任务设置的约束。在这里,我们可以看到处理器当前正在执行一项任务。如果NiFi实例是集群的,则此值表示当前正在集群中的所有节点上执行的任务数。
- 实时日志:这里是用于监控当前处理器状态的,当处理器内部出现问题,一般会在此处显示错误日志
- 数据流入流出看板:这里主要是展示处理数据过程中数据的流入流出情况,Nifi默认是5分钟更新一次页面上的看板情况,当然用户也可以在画布空白处,鼠标右键选择刷新,以达到实时查看的效果。
-
-
In:处理器从其传入处理器的队列中提取的数据量。此值表示为count size,其中count是从队列中提取的FlowFiles的数量,size是这些FlowFiles内容的总大小
-
Read/Write:处理器从磁盘读取并写入磁盘的FlowFile内容的总大小。这提供了有关此处理器所需的I/O性能的有用信息。某些处理器可能只读取数据而不写入任何内容,而某些处理器不会读取数据但只会写入数据。其他可能既不会读取也不会写入数据,而某些处理器会读取和写入数据。
-
Out:处理器已传输到其出站连接的数据量。这不包括处理器自行删除的FlowFiles,也不包括路由到自动终止的连接的FlowFiles。与上面的"In"指标一样,此值表示为count size,其中count是已转移到出站Connections的FlowFiles的数量,size是这些FlowFiles内容的总大小。
-
Tasks/Time:此处理器在过去5分钟内被触发运行的次数,以及执行这些任务所花费的时间。时间格式为hour:minute:second。请注意,所花费的时间可能超过五分钟,因为许多任务可以并行执行。例如,如果处理器计划运行60个并发任务,并且每个任务都需要一秒钟才能完成,则所有60个任务可能会在一秒钟内完成。但是,在这种情况下,我们会看到时间指标显示它需要60秒,而不是1秒。
-
6、组件
SETTINGS(通用配置)
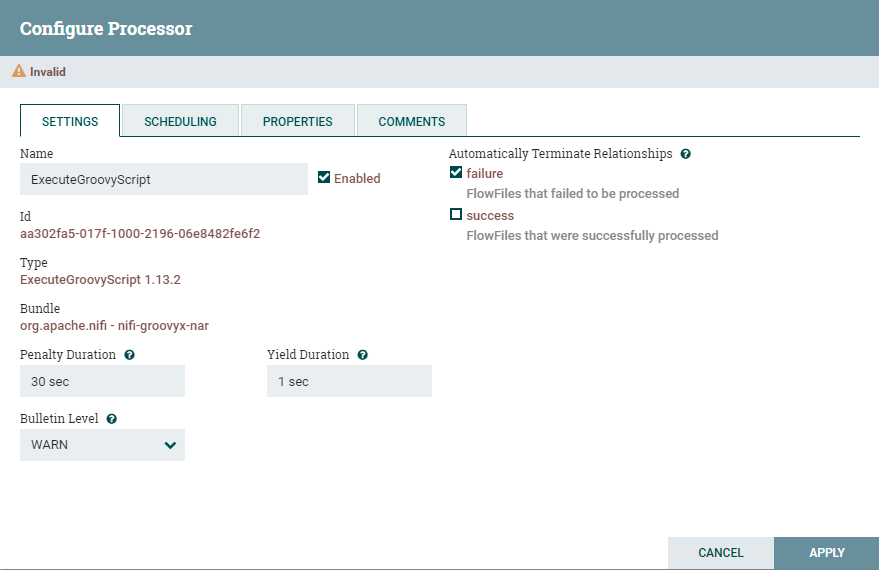
基本的Name这里就不说了,就是用户自定义的名称,Id、Type、Bundle这三个是这个处理器组件所属的代码包等基本信息,这里也不过多介绍,Enable这个选项,就是控制组件由启用到禁用 状态的切换。
状态的切换。
最右边包含自动终止关系(Automatically Terminate Relationships)部分。此处列出了处理器定义的每个关系及其描述。为了使处理器被视为有效且能够运行,处理器定义的每个关系必须连接到下游组件或自动终止。我们可以通过选中它,例如图中选中Failure一样,来表示我们弃用这个输出,也就是不需要它指向下一个组件,这样这个处理器就变成只有一个对外输出数据的Relationship了。
接下来是两个用于配置Penalty Duration和Yield Duration的对话框。在处理一条数据(FlowFile)的正常过程中,可能发生事件,该事件指示处理器此时不能处理数据但是数据可以在稍后进行处理。在发生这种情况时,处理器可以选择Penalize FlowFile。这将阻止FlowFile在一段时间内被处理。例如,如果处理器要将数据推送到远程服务,但远程服务已经有一个与处理器指定的文件名同名的文件,则处理器可能会惩罚FlowFile。Penalty Duration允许DFM指定FlowFile应该受到多长时间的惩罚。默认值为30 seconds。(简单理解为推后一段时间再处理),类似的处理器可以确定存在某种情况,处理器没法进行处理数据。例如,如果处理器要将数据推送到远程服务并且该服务没有响应。这样的话处理器应该Yield,这将阻止处理器运行一段时间。通过设置Yield Duration来指定该时间段。默认值为1 second。
最下方Bulletin Level可以简单的理解为组件的日志输出等级的选择,有选择地进行日志等级输出
SCHEDULING(处理器调度)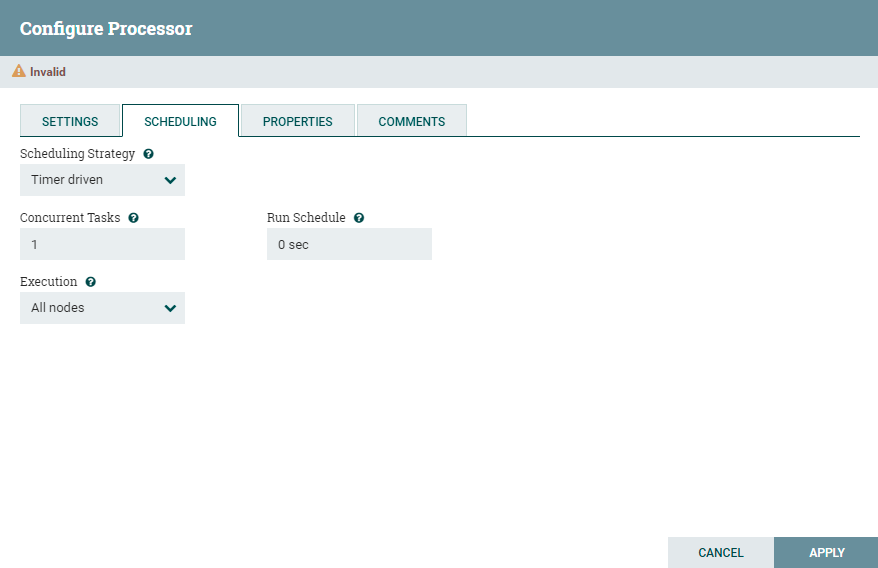
这一标签页,代表的就是如何驱动处理器,或者说处理器的运作方式:
第一个配置选项是调度策略(Scheduling Strategy)。调度有三种可能的选项:
- Timer driven:这是默认模式。处理器将定期运行。即多久运行一次,运行处理器的时间间隔由Run Schedule选项定义(当Run Schedule为0时,则代表瞬时执行)。
- Event driven:选择此模式时,将由一个事件触发处理器运行,当FlowFiles进入连接此处理器的Connections时,将产生这个事件。此模式目前被认为是实验性的,并非所有处理器都支持。选择此模式时,Run Schedule选项不可配置。此外,只有此模式下Concurrent Tasks选项可以设置为0。这种情况,线程数仅受管理员配置的事件驱动线程池的大小限制。
- CRON驱动:这是定时执行模式,即通过cron表达式,进行定时运行的控制。
下面的配置就是线程的分配(Concurrent Tasks):这可以控制处理器将使用的线程数。换句话说,它控制此处理器应同时处理多少个FlowFiles。增加此值通常会使处理器在相同的时间内处理更多数据。但是,它是通过使用其他处理器无法使用的系统资源来实现此目的。这基本上提供了处理器的相对权重 - 应该将多少系统资源分配给此处理器而不是其他处理器。该字段适用于大多数处理器。但是,某些类型的处理器只能使用单个任务进行调度。
关于Execution,执行设置用于确定处理器将被调度执行的节点。选择"All Nodes"将导致在集群中的每个节点上调度此处理器。选择"Primary Node"将导致此处理器仅在主节点上进行调度。一般单节点的情况下,我们都使用Primary Node
"Run Duration"选项卡的右侧包含一个用于选择运行持续时间的滑块。这可以控制处理器每次触发时应安排运行的时间。在滑块的左侧,标记为"Lower latency(较低延迟)",而右侧标记为"Higher throughput(较高吞吐量)"。处理器完成运行后,必须更新存储库才能将FlowFiles传输到下一个Connection。更新存储库的成本很高,因此在更新存储库之前可以立即完成的工作量越多,处理器可以处理的工作量就越多(吞吐量越高)。这意味着在上一批数据处理更新此存储库之前,Processor是无法开始处理接下来的FlowFiles。结果是,延迟时间会更长(从开始到结束处理FlowFile所需的时间会更长)。因此,滑块提供了一个频谱,DFM可以从中选择支持较低延迟或较高吞吐量。
COMMENTS(备注区)
为用户提供一个区域,以包含适用于此组件的任何注释。
PROPERITIES(属性区)
这一标签页差别较大,一般不同的组件所需要的配置各不相同,具体可以参考http://nifi.apache.org/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号