API做翻页的两种思路
转自:https://www.cnblogs.com/cgzl/p/10706881.html
在开发API的时候,有时候数据太多了,就需要分页读取。
基于偏移量的分页(Offset-based)
这种方式就是会提供一个每页笔数(page size)来定义返回条目的最大数,提供一个页数(page number)来表示从哪里开始读取数据。
例如:
|
1
|
SELECT * FROM "CampusResumes" ORDER BY "Name" DESC LIMIT 5 OFFSET 10; |
这句话的意思就是从该表中读取数据,按照Name字段降序排序,从第10笔数据后开始读取,一共读取5笔(可能不足5笔)。
这就相当于page size = 5,page number = 3的分页读取。
Offset-based分页方式实现起来非常的简单,对用户来说体验也比较好。但是还有有一些劣势的:
- 对于大规模的数据集,效率不够高。因为数据库需要进行count和skip操作。
- 如果数据经常发生变化,那么结果不可信。在查询的时候如果插入或删除了数据,那么某条数据可能会出现两次或者翻页的时候越界了。
- 在分布式系统中实现起来略麻烦。这种情况下,你可能需要扫描不同的数据碎片,然后才能得到想要的数据。
总体来说,当允许结果出现误差的时候,Offset-based分页还是很好用的。
基于游标的分页(Cursor-based)
为了解决Offset-based分页的那些问题,可以采用Cursor-based分页。
这种方式是这样的:客户端首先发送请求,请求里提供所需数据的数量。然后服务器响应请求,返回这些数量的数据(如果有这么多数据的话),同时还会返回一个游标(Cursor)。在下一次请求中,客户端除了发送请求数据的数量之外,还把这个cursor也传送过去,这个cursor就表示这次所要读取的数据的开始位置。
这看起来和Offset-based分页差别不大,但是却更有效率。数据库里面的数据可以根据cursor值来获取。
例如:
|
1
|
SELECT * FROM "CampusResumes" WHERE "Id" > 15 ORDER BY "Id" LIMIT 5; |
这个例子里,上次请求返回的cursor(Id字段)值为15,这次要获取Id比15大的连续的5条数据。
这里的Id字段本身就是一个索引,所以查询起来非常快。
在这次请求的响应里,可以把本次结果的最后一条的Id作为cursor再返回去:
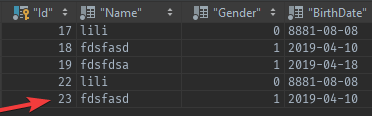
所以返回的cursor值为23,以供下次读取。
Cursor-based翻页的优点是:
- 性能好。因为cursor字段通常都是索引列,查起来很快。
- 一致性。添加和删除数据并不影响返回的结果,翻页时同一笔数据也只会被返回一次。
Cursor-based翻页通常适用于大量和动态的数据集,但是它也有一些缺点:
- 无法跳转到指定的页。Cursor-based翻页只能一页一页遍历结果。
- 结果必须基于一个唯一并且顺序的字段。不可以让添加记录到任意位置。
- 实现起来比Offset-based复杂一点,尤其对客户端来说。
对于Cursor字段的选择:
- Id,顺序的主键。
- 时间戳。
- 加密字符串。它们看起来像随机字符串,但实际上通常是Cursor里加入了额外的信息。
总体来说Cursor-based翻页还是更适合于高吞吐的应用,这种情况下客户端通常需要扫描整个数据集。
翻页的最佳实践
- 设定每页的最大笔数限制。
- 针对大数据集,尽量不要使用Offset-based分页。
- 分页的默认排序,通常会把新的数据先返回,旧的数据往后翻。
- 没分页的API尽量去实现分页。
- 分页的时候,最好把下一页的链接一同返回,并鼓励客户端使用这个链接,参考HATEOAS。这样以后你改变翻页策略的时候,客户端不会爆掉。
- 不要在Cursor里加入敏感信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号