
== 其他基础一 ==
文章引用:
https://www.cnblogs.com/654321cc/p/7419124.html
http://www.cnblogs.com/alex3714/articles/5465198.html
如有侵权,请联系删除
1.bytes类型:
python3中,字符串是unicode格式,字节包括utf-8,gbk等等,网络传输,硬盘保存是以字节格式保存的。
str和bytes格式的区别:
str:
表现形式:a='hello,world'
内部原理:00000000 00000000 00000000 01101000 ‘h’
。。。
。。。
bytes:
表现形式:a=b'hello,world'
内部原理:
01101000 utf-8
。。。
。。。
00000000 01101000 gbk
。。。
。。。
Bytes 对象是由单个字节作为基本元素(8位,取值范围 0-255)组成的序列,为不可变对象。
Bytes 对象只负责以二进制字节序列的形式记录所需记录的对象,至于该对象到底表示什么(比如到底是什么字符)则由相应的编码格式解码所决定。我们可以通过调用 bytes() 类(没错,它是类,不是函数)生成 bytes 实例,其值形式为 b'xxxxx',其中 'xxxxx' 为一至多个转义的十六进制字符串(单个 x 的形式为:\xHH,其中 \x 为小写的十六进制转义字符,HH 为二位十六进制数)组成的序列,每两个十六进制数即每个‘x’代表一个字节(八位二进制数,取值范围 0-255),对于同一个字符串如果采用不同的编码方式生成 bytes 对象,就会形成不同的值。
Python 3最重要的新特性大概要算是对文本和二进制数据作了更为清晰的区分。文本总是Unicode,由str类型表示,二进制数据则由bytes类型表示。Python 3不会以任意隐式的方式混用str和bytes,正是这使得两者的区分特别清晰。你不能拼接字符串和字节包,也无法在字节包里搜索字符串(反之亦然),也不能将字符串传入参数为字节包的函数(反之亦然 )。
例如:


1 a = '你好' 2 a_b = a.encode('utf-8') 3 print(a,b) 4 for i in a_b: 5 print(i) 6 for i in a_b: 7 print(bin(i))
输出:
1 b'\xe4\xbd\xa0\xe5\xa5\xbd' #原来如此,\xe4 长得这么丑,实际是十六进制的数字。和128,12,没什么本质的区别。自然就可以bin()变为二进制数字了。 2 228 3 189 4 160 5 229 6 165 7 189 8 0b11100100 9 0b10111101 10 0b10100000 11 0b11100101 12 0b10100101 13 0b10111101
回到bytes和str的身上。bytes是一种比特流,它的存在形式是01010001110这种。我们无论是在写代码,还是阅读文章的过程中,肯定不会有人直接阅读这种比特流,它必须有一个编码方式,使得它变成有意义的比特流,而不是一堆晦涩难懂的01组合。因为编码方式的不同,对这个比特流的解读也会不同,对实际使用造成了很大的困扰。下面让我们看看Python是如何处理这一系列编码问题的:
1 >>> s = "中文" 2 >>> s 3 '中文' 4 >>> type(s) 5 <class 'str'> 6 >>> b = bytes(s, encoding='utf-8') 7 >>> b 8 b'\xe4\xb8\xad\xe6\x96\x87' 9 >>> type(b) 10 <class 'bytes'>
从例子可以看出,s是个字符串类型。Python有个内置函数bytes()可以将字符串str类型转换成bytes类型,b实际上是一串01的组合,但为了在ide环境中让我们相对直观的观察,它被表现成了b'\xe4\xb8\xad\xe6\x96\x87'这种形式,开头的b表示这是一个bytes类型。\xe4是十六进制的表示方式,它占用1个字节的长度,因此”中文“被编码成utf-8后,我们可以数得出一共用了6个字节,每个汉字占用3个,这印证了上面的论述。在使用内置函数bytes()的时候,必须明确encoding的参数,不可省略。
我们都知道,字符串类str里有一个encode()方法,它是从字符串向比特流的编码过程。而bytes类型恰好有个decode()方法,它是从比特流向字符串解码的过程。除此之外,我们查看Python源码会发现bytes和str拥有几乎一模一样的方法列表,最大的区别就是encode和decode。
从实质上来说,字符串在磁盘上的保存形式也是01的组合,也需要编码解码。
如果,上面的阐述还不能让你搞清楚两者的区别,那么记住下面两几句话:
-
在将字符串存入磁盘和从磁盘读取字符串的过程中,Python自动地帮你完成了编码和解码的工作,你不需要关心它的过程。
-
使用
bytes类型,实质上是告诉Python,不需要它帮你自动地完成编码和解码的工作,而是用户自己手动进行,并指定编码格式。 -
Python已经严格区分了
bytes和str两种数据类型,你不能在需要bytes类型参数的时候使用str参数,反之亦然。这点在读写磁盘文件时容易碰到。
2.三元运算:
1 result = a if 条件 else b
如果条件为真,result = a
如果条件为假,result = b
3.进制:
- 二进制,01
- 八进制,01234567
- 十进制,0123456789
- 十六进制,0123456789ABCDEF 二进制到16进制转换http://jingyan.baidu.com/album/47a29f24292608c0142399cb.html?picindex=1
计算机内存地址和为什么用16进制?
为什么用16进制1、计算机硬件是0101二进制的,16进制刚好是2的倍数,更容易表达一个命令或者数据。十六进制更简短,因为换算的时候一位16进制数可以顶4位2进制数,也就是一个字节(8位进制可以用两个16进制表示)2、最早规定ASCII字符集采用的就是8bit(后期扩展了,但是基础单位还是8bit),8bit用2个16进制直接就能表达出来,不管阅读还是存储都比其他进制要方便
3、计算机中CPU运算也是遵照ASCII字符集,以16、32、64的这样的方式在发展,因此数据交换的时候16进制也显得更好
4、为了统一规范,CPU、内存、硬盘我们看到都是采用的16进制计算
16进制用在哪里
1、网络编程,数据交换的时候需要对字节进行解析都是一个byte一个byte的处理,1个byte可以用0xFF两个16进制来表达。通过网络抓包,可以看到数据是通过16进制传输的。
2、数据存储,存储到硬件中是0101的方式,存储到系统中的表达方式都是byte方式3、一些常用值的定义,比如:我们经常用到的html中color表达,就是用的16进制方式,4个16进制位可以表达好几百万的颜色信息。
4.Python中一切皆对象:
对象是基于类创建的
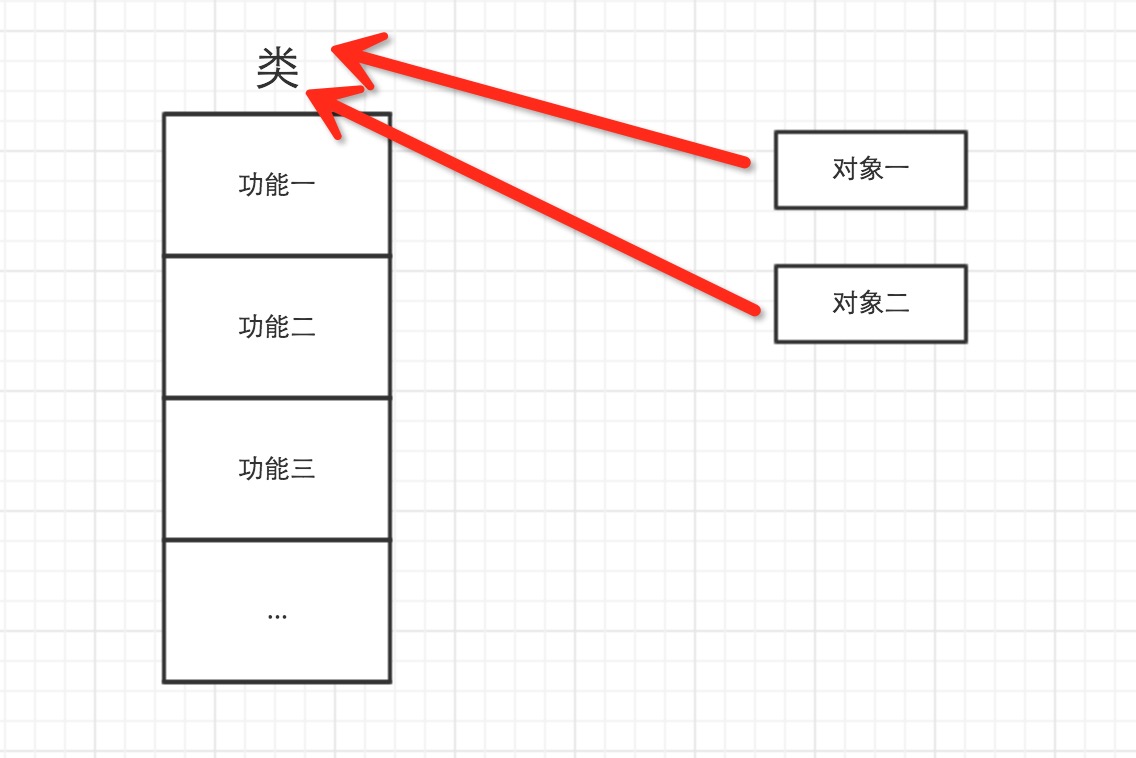
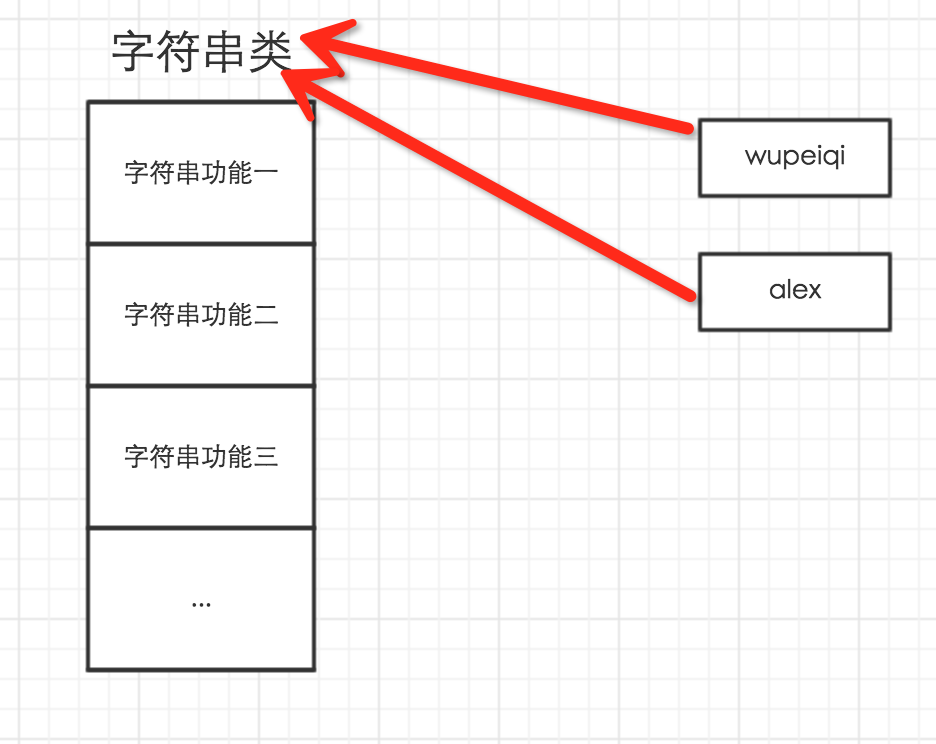
所以,以下这些值都是对象: "wupeiqi"、38、['北京', '上海', '深圳'],并且是根据不同的类生成的对象。




 浙公网安备 33010602011771号
浙公网安备 33010602011771号