python基础语法(版本python3.65)
1.注释
单行:#
多行:三个'单引号'或三个"双引号"
'''
print("hello world")
'''
或
"""
print("hello world")
"""
2.编码
python2 = assic = 不支持中文
文件中有中文,不管是否为注释,python2执行报错。
解决:程序首行加 #coding=utf-8 或 #*-* coding:utf-8 *-*
python3 = unicode = 默认支持中文
3.模块:
在计算机程序的开发过程中,随着程序代码越写越多,在一个文件里代码就会越来越长,越来越不容易维护。
为了编写可维护的代码,我们把很多函数分组,分别放到不同的文件里,这样,每个文件包含的代码就相对较少,很多编程语言都采用这种组织代码的方式。在Python中,一个.py文件就称之为一个模块(Module)。
使用模块有什么好处?
最大的好处是大大提高了代码的可维护性。其次,编写代码不必从零开始。当一个模块编写完毕,就可以被其他地方引用。我们在编写程序的时候,也经常引用其他模块,包括Python内置的模块和来自第三方的模块。
使用模块还可以避免函数名和变量名冲突。相同名字的函数和变量完全可以分别存在不同的模块中,因此,我们自己在编写模块时,不必考虑名字会与其他模块冲突。但是也要注意,尽量不要与内置函数名字冲突。点这里查看Python的所有内置函数。
你也许还想到,如果不同的人编写的模块名相同怎么办?为了避免模块名冲突,Python又引入了按目录来组织模块的方法,称为包(Package)。
举个例子,一个abc.py的文件就是一个名字叫abc的模块,一个xyz.py的文件就是一个名字叫xyz的模块。
现在,假设我们的abc和xyz这两个模块名字与其他模块冲突了,于是我们可以通过包来组织模块,避免冲突。方法是选择一个顶层包名,比如mycompany,按照如下目录存放:
mycompany
├─ __init__.py
├─ abc.py
└─ xyz.py引入了包以后,只要顶层的包名不与别人冲突,那所有模块都不会与别人冲突。现在,abc.py模块的名字就变成了mycompany.abc,类似的,xyz.py的模块名变成了mycompany.xyz。
请注意,每一个包目录下面都会有一个__init__.py的文件,这个文件是必须存在的,否则,Python就把这个目录当成普通目录,而不是一个包。__init__.py可以是空文件,也可以有Python代码,因为__init__.py本身就是一个模块,而它的模块名就是mycompany。
类似的,可以有多级目录,组成多级层次的包结构。比如如下的目录结构:
mycompany
├─ web
│ ├─ __init__.py
│ ├─ utils.py
│ └─ www.py
├─ __init__.py
├─ abc.py
└─ xyz.py文件www.py的模块名就是mycompany.web.www,两个文件utils.py的模块名分别是mycompany.utils和mycompany.web.utils。
注意:自己创建模块时要注意命名,不能和Python自带的模块名称冲突。例如,系统自带了sys模块,自己的模块就不可命名为sys.py,否则将无法导入系统自带的sys模块。
导入模块:
import package
from Package import specific_submodule
Import 模块名
From 模块名 import 子模块1,子模块2,......
总结:
模块是一组Python代码的集合,可以使用其他模块,也可以被其他模块使用。
创建自己的模块时,要注意:
- 模块名要遵循Python变量命名规范,不要使用中文、特殊字符;
- 模块名不要和系统模块名冲突,最好先查看系统是否已存在该模块,检查方法是在Python交互环境执行
import abc,若成功则说明系统存在此模块。
4.输入
name = input("请输入名字:")
5.输出
print("name is %s"%name)
print("name:%s, age:%d"%(name,age))
print("name:{0}, age:{1}".format(name,age)) #(标号可不写,为默认顺序)
print("name:{name}, age:{age}".format(name = "你的名字",age = 60))
import math
print('常量 PI 的值近似为 {0:.3f}。'.format(math.pi)) #常量 PI 的值近似为 3.142。
table = {'tbl_a': 1, 'tbl_b': 2, 'tbl_c': 3}
print('tbl_b: {0[tbl_b]:d}; tbl_a: {0[tbl_a]:d}; tbl_c: {0[tbl_c]:d}'.format(table))
#tbl_b: 2; tbl_a: 1; tbl_c: 3
table = {'tbl_a': 1, 'tbl_b': 2, 'tbl_c': 3}
print('tbl_b: {tbl_b:d}; tbl_a: {tbl_a:d}; tbl_c: {tbl_c:d}'.format(**table))
#tbl_b: 2; tbl_a: 1; tbl_c: 3
6.类型转换
a = int("100") # 转换为数字
a = str("100“) # 转换为字符串
7.python2与python3
python2中input的内容当做执行的内容,python3当做字符串。如a = input(“”). python2中的raw_input相当于python3中的inpout。
python2 中支持 <> 是不等于的意思,python3不支持,应该用 != 表示
8.运算符
一、算述运算符:
1 + 1 = 2 (加法)
4 - 10 = -6 #(减法 - 得到负数或是一个数减去另一个数)
"a" * 5 = "aaaaa" #(乘法 - 两个数相乘或是返回一个被重复若干次的字符串)
2 ** 3 = 8 #(幂 - 返回2的3次幂)
5 / 2 = 2.5 #(除法)
5 // 2 = 2 #(取商 - 返回商的整数部分)
5 % 2 = 1 #(取余 - 返回除法的余数)
二、赋值运算符:
i += 1 等价于 i = i + 1
i -= 1 等价于 i = i - 1
i *= 2 等价于 i = i * 2
i /= 2 等价于 i = i / 2
i //= 2 等价于 i = i // 2
i %= 2 等价于 i = i % 2
i **= 2 等价于 i = i ** 2
9.逻辑运算符
not , and , or
优先级(短路原则):
and:条件1 and 条件2 ,如果条件1为假,那么这个and前后两个条件组成的表达式的计算结果就一定为假,就不判断条件2了
or:条件1 or 条件2,如果前面的第一个条件为真,那么这个or前后两个条件组成的表达式的计算结果就一定为真,就不判断条件2了
10.流程
表达式及操作运算符、常量及变量:
(1)表达式:由操作数和运算符组成的一句代码或语句,表达式可以求值,可以放在" = "的右边,用来给变量赋值。
(2)操作运算符:
< 小于
<= 小于或等于
> 大于
>= 大于或等于
== 等于,比较对象是否相等(注意区分 = ,= 是赋值,==是比较)
!= 不等于
(3)常量:固定不变的量,字母大写
(4)变量: 存储信息,以后被调用
命名规则:
-
- 1.字母数字下划线组成
- 2.不能以数字开头,不能含有特殊字符和空格
- 3.不能以保留字命名
- 4.不能以汉字命名
- 5.定义的变量名应该有意义
- 6.驼峰式命名、下划线分割单词
- 7.变量名区分大小写
(if...elif...else)
if 条件(如果):
elif 条件(或如果):
else否则:
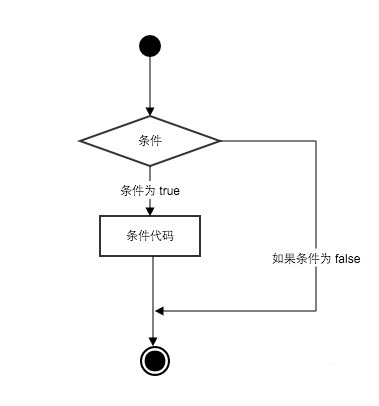
注意:
- 1、每个条件后面要使用冒号 :,表示接下来是满足条件后要执行的语句块。
- 2、使用缩进来划分语句块,相同缩进数的语句在一起组成一个语句块。
- 3、在Python中没有switch – case语句。
例:
# 该实例演示了数字猜谜游戏
number = 7
guess = 0
print("数字猜谜游戏!")
while guess != number:
guess = int(input("请输入你猜的数字:"))
if guess == number:
print("恭喜,你猜对了!")
elif guess < number:
print("猜的数字小了...")
elif guess > number:
print("猜的数字大了...")
# 执行结果:
数字猜谜游戏!
请输入你猜的数字:5
猜的数字小了...
请输入你猜的数字:6
猜的数字小了...
请输入你猜的数字:8
猜的数字大了...
请输入你猜的数字:9
猜的数字大了...
请输入你猜的数字:7
恭喜,你猜对了!
if 嵌套:在嵌套 if 语句中,可以把 if...elif...else 结构放在另外一个 if...elif...else 结构中。
if 表达式1:
语句
if 表达式2:
语句
elif 表达式3:
语句
else:
语句
elif 表达式4:
语句
else:
语句
例:
num=int(input("输入一个数字:"))
if num%2==0:
if num%3==0:
print ("你输入的数字可以整除 2 和 3")
else:
print ("你输入的数字可以整除 2,但不能整除 3")
else:
if num%3==0:
print ("你输入的数字可以整除 3,但不能整除 2")
else:
print ("你输入的数字不能整除 2 和 3")
# 执行结果:
输入一个数字:5
你输入的数字不能整除 2 和 3
输入一个数字:6
你输入的数字可以整除 2 和 3
(while)
while 判断条件: #(while:当...的时候)
语句
一、需要注意冒号和缩进。另外,在Python中没有do...while循环。
例:while 循环使用 else 语句
i = 0
while i < 5:
print (i, " 小于 5")
i += 1 # 变量自增
else:
print (i, " 等于 5")
# 输出结果:
0 小于 5
1 小于 5
2 小于 5
3 小于 5
4 小于 5
5 等于 5
二、以下实例使用了 while 来计算 1 到 100 的总和:
i = 100
sum = 0
counter = 1
while counter <= i:
sum = sum + counter
counter += 1
print("1 到 %d 之和为: %d" % (i,sum))
# 输出结果:
1 到 100 之和为: 5050
(for)
一、for循环可以遍历任何序列的项目,如一个列表或者一个字符串。
例:
languages = ["C", "C++", "Perl", "Python"]
for x in languages:
print (x)
# 输出结果:
C
C++
Perl
Python
二、以下 for 实例中使用了 break 语句,break 语句用于跳出当前循环体。
例:
sites = ["Baidu", "Google","frank-me","Taobao"]
for site in sites:
if site == "frank-me":
print("我的网址")
break
print("循环数据 " + site)
else:
print("到此为止!")
print("结束!")
# 输出结果:
循环数据 Baidu
循环数据 Google
我的网址
结束!
注意: i++,++i 在python中不允许使用。
(range函数)
一、如果你需要遍历数字序列,可以使用内置range()函数,它会生成数列。
例:
for i in range(5):
print(i)
# 输出结果:
0
1
2
3
4
二、也可以使用range指定区间的值。
例:
for i in range(5,9) :
print(i)
# 输出结果:
5
6
7
8
三、也可以使range以指定数字开始并指定不同的增量(甚至可以是负数,有时这也叫做'步长')。
例:
for i in range(0, 10, 3) :
print(i)
# 输出结果:
0
3
6
9
四、您可以结合range()和len()函数以遍历一个序列的索引
例:
>>> a = ['Google', 'Baidu', 'frank-me', 'Taobao', 'QQ']
>>> for i in range(len(a)):
>>> print(i, a[i])
# 输出结果:
0 Google
1 Baidu
2 frank-me
3 Taobao
4 QQ
五、可以使用range()函数来创建一个列表,用for直接历遍
>>> for i in list(range(5)):
... print( i )
# 输出结果:
0
1
2
3
4
break和continue语句及循环中的else子句
一、break 语句可以跳出 for 和 while 的循环体。如果你从 for 或 while 循环中终止,任何对应的循环 else 块将不执行。
例:
for letter in 'frank-me': # 第一个实例
if letter == '-': # 当符号为“-”时,跳出
break
print ('当前字符为 :', letter)
var = 10 # 第二个实例
while var > 0:
print ('当期变量值为 :', var)
var = var -1
if var == 5: # 到数字5(包含5)时不往下执行
break
print ("See you!")
# 输出结果:
当前字符为 : f
当前字符为 : r
当前字符为 : a
当前字符为 : n
当前字符为 : k
当期变量值为 : 10
当期变量值为 : 9
当期变量值为 : 8
当期变量值为 : 7
当期变量值为 : 6
See you!
二、continue语句被用来告诉Python跳过当前循环块中的剩余语句,然后继续进行下一轮循环。
例:
for letter in 'frank-me': # 第一个实例
if letter == '-': # 字符为 "-" 时跳过输出,继续往下执行
continue
print ('当前字符 :', letter)
var = 10 # 第二个实例
while var > 0:
var = var -1
if var == 5: # 变量为 5 时跳过输出,继续往下执行
continue
print ('当前变量值 :', var)
print ("See you!")
# 输出结果:
当前字符 : f
当前字符 : r
当前字符 : a
当前字符 : n
当前字符 : k
当前字符 : m
当前字符 : e
当前变量值 : 9
当前变量值 : 8
当前变量值 : 7
当前变量值 : 6
当前变量值 : 4
当前变量值 : 3
当前变量值 : 2
当前变量值 : 1
当前变量值 : 0
See you!
三、循环语句可以有 else 子句,它在穷尽列表(以for循环)或条件变为 false (以while循环)导致循环终止时被执行,但循环被break终止时不执行。
例:
for i in range(2, 10):
for x in range(2, i):
if i % x == 0:
print(i, '=', x, '*', i//x)
break
else:
# 循环中没有找到元素
print(i, '是质数')
# 输出结果:
2 是质数
3 是质数
4 = 2 * 2
5 是质数
6 = 2 * 3
7 是质数
8 = 2 * 4
9 = 3 * 3
for-else
for中没有break,则else一定会执行
for temp in strs:
print(temp)
else:
print("")
const 修改变量为不可变。
(pass语句)
pass是空语句,是为了保持程序结构的完整性。
pass 不做任何事情,一般用做占位语句。
while True:
pass # 等待键盘中断 (Ctrl+C)
最小的类:
class EmptyClass:
pass
例:
for letter in 'frank-me':
if letter == '-':
pass
print ('- 执行 pass')
print ('当前字符 :', letter)
print ("See you!")
# 输出结果:
当前字符 : f
当前字符 : r
当前字符 : a
当前字符 : n
当前字符 : k
- 执行 pass
当前字符 : -
当前字符 : m
当前字符 : e
See you!
11.字符串(不可变)
一、创建
‘ str ’,“ str ”单引号或双引号包裹起来的内容
顺序,序列
-- 偏移量,索引,直标
长度
--len()返回一个序列的长度
** 单个字符,即长度为1的字符串
二、索引
test_str[0]
** 特别的:最后一元素的索引“-1”,“-2”代表倒数第二,依此类推
切片
-- test_str[strat:end]
-- start:起始索引(包含这个元素)
-- end:结束索引(不包含这个元素)
-- start < end
不可变
-- 不能修改
切片例:
str = "dasfaf"
str[2:4] #(取得2到3的),
str[2:] #(到最后),
str[2:-1:2] #(步长2,隔一个取一个)
逆序:
str = "abcdefABCDEF"
str[0:] # out:"abcdefABCDEF" (顺序)
str[-1:] # out:"F" (倒数第一个)
str[-1:0] # out:""
str[-1:0:-1] # out:"FEDCBAfedcb" (逆序,不含第一个)
str[-1::-1], str[::-1] # out:"FEDCBAfedcba"(逆序)
三、字符串连接:
a = b + c #或者
a = "===%s==="%(b+c) #或者
a = "==={}===".format(b+c)
四、常见操作
find: str.find("abc") # 从左向右有返回第一个匹配字符串的起始下标,没有返回-1。rfind():从右向左。
str.index("abc") #找到返回起始下标,没有抛出异常。 存在rindex().
str.count("abc") #匹配的个数。
str.replace("abc", "def") #同java,把左边的替换成右边的 。
str.replace("abc", "def",1) #第三个参数是从左到右替换个数。
str.split(" ") #同java ,通过指定分隔符(包括空格、换行(\n)、制表符(\t)等)对字符串进行切片,如果参数 num 有指定
值,则仅分隔 num 个子字符串。
str.capitalize() #字符串的第一个字母大写。
str.title() #字符串的每个单词的首字母大写。
str.startswith("abc"), str.endswith("abc") #同java,用于检查字符串是否是以指定子字符串开头,如果是则返回 True,
否则返回 False。如果参数 beg 和 end 指定值,则在指定范围内检查。
str.lower() str.uper() #所有的字母小写和大写。
str.center(50) #居中显示,行总长50 " abc "
str.ljust(50), str.rjust(50) #左(右)对齐
str.lstrip() #删除左边空格
str.rstrip() #右边空格
str.strip() #删除两端空格.
12.列表 (类似数组,可变,针对自身的变化)
运算符
|
表达式 |
结果 |
描述 |
|
len([1, 2, 3]) |
3 |
计算元素个数 |
|
[1, 2, 3] + [4, 5, 6] |
[1, 2, 3, 4, 5, 6] |
连接 |
|
[‘Hi!’] * 4 |
[‘Hi!’, ‘Hi!’, ‘Hi!’, ‘Hi!’] |
复制 |
|
3 in [1, 2, 3] |
True |
元素是否存在 |
|
for x in [1, 2, 3]: print(x, end=” “) |
1 2 3 |
迭代 |
创建
序列
list1 = [1,2,3,4,5,6]
例:
["zhangsan","lisi"]
#定义
names = ["zhangsan", "lisi", 3.14] #列表中的数据可以是不同的数据类型。 可以下标,和切片。
增删改查
增
-- 1.list.append(item)向尾部添加
-- 2.list.insert(index,item) 向指定的地方插入
例:#增
names.append("abc") #-->插入到最后;
names.insert(0, "bcc") #-->插入指定位置。
names = names1 + names2 #两个列表用连接符
names1.extend(names2) #扩充
#注意:append添加的元素;extend连接的列表
删
-- list.pop(index) #-->index 默认-1 (最后一个)
例:#删
names.pop() #-->删除最后一个;
names.remove("lisi") #-->根据内容删除;
del names[0] #-->下标删除
改
-- 直接复制
例:#改
names[0] = "abc"
查
索引
操作同字符串
例:#查
name[1:] # "lisi"
in, not in #是否存在 (if "zhangsan" in names:)
#可以for... in 循环遍历
len(names) #元素个数
13.字典(可变)
a = {"name":"yy", "age": 12}
增
a["name"] = "yy" #直接写key-value
删
del a["name"]
改
a["name"] = "zz" #相同key的值覆盖。
查
a["name"], a.get("name")
例:
>>> params = {"server":"mpilgrim", "database":"master", "uid":"sa", "pwd":"secret"}
>>> params
{'server': 'mpilgrim', 'database': 'master', 'uid': 'sa', 'pwd': 'secret'}
>>> ["%s=%s" % (k, v) for k, v in params.items()]
['server=mpilgrim', 'database=master', 'uid=sa', 'pwd=secret']
>>> ";".join(["%s=%s" % (k, v) for k, v in params.items()])
'server=mpilgrim;database=master;uid=sa;pwd=secret'
字典常见操作
len(params) #键值对的个数
params.keys() 或 dict.keys(params) #返回key的列表
if "uid" in params.keys(): #判断是否存在某个key
print("yes")
params.values() #返回value的列表
14.元组(类似列表,不可变)
列表可以增删改,元组不能改
tup1 = (); #空元组
例:
>>> tup1 = (50)
>>> type(tup1) # 不加逗号,类型为整型
# 执行结果:
<class 'int'>
>>> tup1 = (50,)
>>> type(tup1) # 加上逗号,类型为元组
# 执行结果:
<class 'tuple'>
访问:
例:
tup1 = ('Google', 'Baidu', 1997, 2000)
tup2 = (1, 2, 3, 4, 5, 6, 7 )
print ("tup1[0]: ",tup1[0])
# 执行结果:
tup1[0]: Google
print ("tup2[1:5]: ", tup2[1:5])
# 执行结果:
tup2[1:5]: (2, 3, 4, 5)
修改:
例:
tup1 = (12, 34.56);
tup2 = ('abc', 'xyz')
# 以下修改元组元素操作是非法的。
# tup1[0] = 100
# 创建一个新的元组
tup3 = tup1 + tup2;
print (tup3) #(12, 34.56, 'abc', 'xyz')
删除
tup = ('Google', 'Baidu', 1997, 2000)
print (tup)
del tup;
类似拆包
a = (11,12)
b = a
b #out (11,12)
c,d = a #类似拆包
c #out 11
d #out 12
例:
info = {"name":"ysw", "age":24}
for temp in info:
print(temp)
# 执行结果:
name
age
for temp in info.items():
print("key=%s,value=%s"%(temp[0],temp[1]))
#or(或者)
for a,b in info.items():
print("key=%s,value=%s"%(a,b))
# 执行结果
key=name,value=ysw
key=age,value=24
遍历技巧:
一、在字典中遍历时,关键字和对应的值可以使用 items() 方法同时解读出来
knights = {'gallahad': 'the pure', 'robin': 'the brave'}
for k, v in knights.items():
print(k, v)
# 执行结果:
gallahad the pure
robin the brave
二、在序列中遍历时,索引位置和对应值可以使用 enumerate() 函数同时得到
>>> for i, v in enumerate(['tic', 'tac', 'toe']):
... print(i, v)
# 执行结果:
0 tic
1 tac
2 toe
三、同时遍历两个或更多的序列,可以使用 zip() 组合
>>> questions = ['name', 'quest', 'favorite color']
>>> answers = ['lancelot', 'the holy grail', 'blue']
>>> for q, a in zip(questions, answers):
... print('What is your {0}? It is {1}.'.format(q, a))
...
# 执行结果:
What is your name? It is lancelot.
What is your quest? It is the holy grail.
What is your favorite color? It is blue.
四、要反向遍历一个序列,首先指定这个序列,然后调用 reversed() 函数
>>> for i in reversed(range(1, 10, 2)):
... print(i)
...
# 执行结果:
9
7
5
3
1
五、要按顺序遍历一个序列,使用 sorted() 函数返回一个已排序的序列,并不修改原值
>>> basket = ['apple', 'orange', 'apple', 'pear', 'orange', 'banana']
>>> for f in sorted(set(basket)):
... print(f)
...
# 执行结果:
apple
banana
orange
pear
15.函数
def abc():
print("")
abc()
#注意: 函数的定义需要在函数的调用之前,否则报错。
可更改与不可更改对象:
在python中,strings,tuples和numbers是不可更改对象,list.dict等则是可更改对象。
- 不可变类型:变量赋值 a=5后在赋值a=10,生成了新的对象,原对象丢弃。
- 可变类型:变量赋值 la=[1,2,3,4] 后再赋值 la[2]=5 则是将 list la 的第三个元素值更改,本身la没有动,只是其内部的一部分值被修改了。
python 函数的参数传递:
- 不可变类型:类似 c++ 的值传递,如 整数、字符串、元组。如fun(a),传递的只是a的值,没有影响a对象本身。比如在 fun(a)内部修改 a 的值,只是修改另一个复制的对象,不会影响 a 本身
- 可变类型:类似 c++ 的引用传递,如 列表,字典。如 fun(la),则是将 la 真正的传过去,修改后fun外部的la也会受影响
一、默认函数参数
def printinfo( name, age = 35 ):
"打印任何传入的字符串"
print ("名字: ", name);
print ("年龄: ", age);
return;
printinfo( age=50, name="baidu" );
print ("------------------------")
printinfo( name="baidu" );
# 执行结果:
名字: baidu
年龄: 50
------------------------
名字: baidu
年龄: 35
二、可变参数
例:
def printinfo( *vartuple ):
"打印任何传入的参数"
print ("输出: ")
for var in vartuple:
print (var)
return;
printinfo(10,32,22)
#匿名函数(lambda创建匿名函数)
sum = lambda arg1, arg2: arg1 + arg2;
print ("相加后的值为 : ", sum( 10, 20 ))
print ("相加后的值为 : ", sum( 20, 20 ))
# 执行结果:
输出:
10
32
22
相加后的值为 : 30
相加后的值为 : 40
三、global关键字修改外部作用域变量
例:
num = 1
def fun1():
global num # 需要使用 global 关键字声明
print(num)
num = 123
print(num)
fun1()
# 执行结果:
1
123
四、nonlocal 修改嵌套作用域变量
例:
def outer():
num = 10
def inner():
nonlocal num # nonlocal关键字声明
num = 100
print(num)
inner()
print(num)
outer()
# 执行结果:
100
100
16.迭代器和生成器
一、字符串,列表和元组对象都可用于创建迭代器。
例:
list = [1,2,3,4]
it = iter(list)
print(next(it))
print(next(it))
#执行结果
1
2
for x in it: #遍历
print(x, end = "")
#执行结果:
1 2 3 4
例:
import sys
list = [1,2,3,4]
it = iter(list)
while True:
try:
print(next(it))
except StopIteration:
sys.exit()
# 执行结果:
1
2
3
4
二、生成器(TODO)
yield 的函数,生成器是返回迭代器的函数,只能用于迭代操作。
例:
import sys
def fibonacci(n): # 生成器函数 - 斐波那契
a, b, counter = 0, 1, 0
while True:
if (counter > n):
return
yield a # 相当于generator的print(a)
a, b = b, a + b # 注意,赋值语句相当于:t = (b,a+b), t 是一个tuple,a = t[0] , b = t[1]
counter += 1
f = fibonacci(10) # f 是一个迭代器,由生成器返回生成
while True:
try:
print (next(f), end=" ")
except StopIteration:
sys.exit()
#执行结果:
0 1 1 2 3 5 8 13 21 34 55
17.模块
Python 提供了一个办法,把某些定义存放在文件中,为一些脚本或者交互式的解释器实例使用,这个文件被称为模块。
- import语句,想使用 Python 源文件,只需在另一个源文件里执行 import 语句。
例:
#!/usr/bin/python3
# Filename: support.py
def print_func( par ):
print ("Hello : ", par)
return
#!/usr/bin/python3
# Filename: test.py
import support #导入模块,即文件名
# 现在可以调用模块里包含的函数了
support.print_func()
from…import语句,从模块中导入一个指定的部分到当前命名空间中。
#导入模块 fibo 的 fib 函数
from fibo import fib, fib2
>>> fib(500)
- From…import* 语句,把一个模块的所有内容全都导入到当前的命名空间。
- 模块除了方法定义,还可以包括可执行的代码。这些代码一般用来初始化这个模块。这些代码只有在第一次被导入时才会被执行。
- name属性,一个模块被另一个程序第一次引入时,其主程序将运行。如果我们想在模块被引入时,模块中的某一程序块不执行,可以用name属性。
例:
#!/usr/bin/python3
# Filename: using_name.py
if __name__ == '__main__':
print('程序自身在运行')
else:
print('我来自另一模块')
#执行结果:
程序自身在运行
- Python 会根据 sys.path 中的目录来寻找这个包中包含的子目录。
- 目录只有包含一个叫做 init.py 的文件才会被认作是一个包,主要是为了避免一些滥俗的名字(比如叫做 string)不小心的影响搜索路径中的有效模块。
- 推荐:from Package import specific_submodule
18.文件
open()方法返回文件,第二个参数为文件打开方式。默认只读r / 写w,a追加…
f = open("/tmp/test.txt","w")
f.write("人生苦短,我用python!")
f.close()
- f.read(size) 读取文件内容,size为空或负数则全部返回。
- f.readline() 会从文件中读取单独的一行。换行符为 ‘\n’。f.readline() 如果返回一个空字符串, 说明已经已经读取到最后一行。
- f.readlines() 读取文件所有行,并以列表返回。
- f.write(string) 将 string 写入到文件中, 然后返回写入的字符数。如果要写入一些不是字符串的东西, 那么将需要先进行转换。
19.类
类方法
例:
class MyClass:
i = 12345
#类方法必须有一个额外的第一个参数,惯例是self,不固定;代表的的类的实例而非类
def f(self):
return "hello world"
x = MyClass()
print("MyClass 类的属性 i 为:", x.i)
print("MyClass 类的方法 f 输出为:", x.f())
#执行结果:
MyClass 类的属性 i 为: 12345
MyClass 类的方法 f 输出为: hello world
构造方法
例:
class Complex:
#构造方法
def __init__(self, realpart, imagpart):
self.r = realpart
self.i = imagpart
x = Complex(3.0, -4.5)
print(x.r, x.i)
# 执行结果:
3.0 -4.5
例:
类定义
class people:
#定义基本属性
name = ''
age = 0
#定义私有属性,私有属性在类外部无法直接进行访问
__weight = 0
#定义构造方法
def __init__(self,n,a,w):
self.name = n
self.age = a
self.__weight = w
def speak(self):
print("%s 说: 我 %d 岁。" %(self.name,self.age))
# 实例化类
p = people('baidu',10,30)
p.speak()
# 执行结果:
baidu 说: 我 10 岁。
继承
例:
类定义
class people:
#定义基本属性
name = ''
age = 0
#定义私有属性,私有属性在类外部无法直接进行访问
__weight = 0
#定义构造方法
def __init__(self,n,a,w):
self.name = n
self.age = a
self.__weight = w
def speak(self):
print("%s 说: 我 %d 岁。" %(self.name,self.age))
#单继承示例
class student(people):
grade = ''
def __init__(self,n,a,w,g):
#调用父类的构函
people.__init__(self,n,a,w)
self.grade = g
#覆写父类的方法
def speak(self):
print("%s 说: 我 %d 岁了,我在读 %d 年级"%(self.name,self.age,self.grade))
#另一个类,多重继承之前的准备
class speaker():
topic = ''
name = ''
def __init__(self,n,t):
self.name = n
self.topic = t
def speak(self):
print("我叫 %s,我是一个演说家,我演讲的主题是 %s"%(self.name,self.topic))
#多重继承
class sample(speaker,student):
a =''
def __init__(self,n,a,w,g,t):
student.__init__(self,n,a,w,g)
speaker.__init__(self,n,t)
test = sample("frank",25,80,4,"Python")
test.speak() #方法名同,默认调用的是在括号中排前地父类的方法
# 执行结果:
我叫 frank,我是一个演说家,我演讲的主题是 Python
20.正则表达式
re.match与re.search的区别
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配。
例:
import re
line = "Cats are smarter than dogs";
matchObj = re.match( r'dogs', line, re.M|re.I)
if matchObj:
print ("match --> matchObj.group() : ", matchObj.group())
else:
print ("No match!!")
#执行结果
No match!!
例:
import re
line = "Cats are smarter than dogs";
matchObj = re.search( r'dogs', line, re.M|re.I)
if matchObj:
print ("search --> matchObj.group() : ", matchObj.group())
else:
print ("No match!!")
#执行结果
search --> matchObj.group() : dogs
检索和替换
例:
import re
phone = "2018-666-666 # 这是一个电话号码"
num = re.sub(r'#.*$', "", phone) # 删除“#”后面的注释内容
print ("电话号码 : ", num)
#执行结果
电话号码 : 2018-666-666
例:
import re
phone = "2018-666-666 # 这是一个电话号码"
num = re.sub(r'\D', "", phone) # 移除非数字的内容
print ("电话号码 : ", num)
#执行结果
电话号码 : 2018666666
最后用一张图来概括:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号