


Big Data Tech and Analytics --- MapReduce and Frequent Itemsets
1. Standard Architecture to solve the problem of big data computation
- Cluster of commodity Linux nodes
-
Commodity network (ethernet) to connect them
2. Issue and idea
- Issue: Copying data over a network takes time
-
Idea:
Bring computation close to the data
Store files multiple times for reliability
3. HDFS
3.1 Function: Distributed File System, Provides global file namespace, Replica to ensure data recovery
3.2 Data Characteristics:
- Streaming data access
- Large data sets and files: gigabytes to terabytes size
- High aggregate data bandwidth
- Scale to hundreds of nodes in a cluster
- Tens of millions of files in a single instance
- Batch processing rather than interactive user access
- Write-once-read-many
- This assumption simplifies coherency of concurrent accesses
3.3 Architecture
Master: manage the file system namespace and regulates access to files by clients.
Details:
- The HDFS namespace is stored by NameNode. NameNode uses a transaction log called the "EditLog" to record every change that occurs to the filesystem meta data.
- Entire filesystem namespace including mapping of blocks to files and file system properties is stored in a file "FsImage". Stored in Namenode’s local filesystem. NameNode keeps image of entire file system namespace.
- When the Namenode starts up
- Gets the FsImage and Editlog.
- Update FsImage with EditLog information.
- Stores a copy of the FsImage as a checkpoint.
- In case of crash, last checkpoint is recovered.
Slaves: manage storage attached to the nodes that they run on. Serves read, write requests, performs block creation, deletion, and replication upon instruction from NameNode.
Details:
- A DataNode stores data in files in its local file system. Each block of HDFS is a separate file. These files are placed in different directories. Creation of new directory is determined by heuristics.
- When the filesystem starts up: Generates Blockreport. Sends this report to NameNode.
- DataNode has no knowledge about HDFS filesystem. DataNode does not create all files in the same directory.
3.4 Data Replication
- Each file is a sequence of blocks. Blocks are replicated for fault tolerance. All blocks in the file except the last are of the same size. Block size and replicas are configurable per file.
- The NameNode receives a Heartbeat and a BlockReport from each DataNode in the cluster. BlockReport contains all the blocks on a DataNode.
- Replica selection for read operation: HDFS tries to minimize the bandwidth consumption and latency. If there is a replica on the Reader node then that is preferred. HDFS cluster may span multiple data centers: replica in the local data center is preferred over the remote one
3.5 Safemode Startup
3.5.1 Each DataNode checks in with Heartbeat and BlockReport.
3.5.2 NameNode verifies that each block has acceptable number of replicas.
3.5.3 After a configurable percentage of safely replicated blocks check in with the NameNode, NameNode exits Safemode.
3.5.4 It then makes the list of blocks that need to be replicated.
3.5.6 NameNode then proceeds to replicate these blocks to other DataNodes.
Hint: On startup NameNode enters Safemode. Replication of data blocks do not occur in Safemode.
4. MapReduce
4.1 Data Flow
Input and final output are stored on a distributed file system (FS): Scheduler tries to schedule map tasks “close” to physical storage location of input data. Intermediate results are stored on local FS of Map and Reduce workers.
4.2 Coordination
Master node takes care of coordination:
Task status: (idle, in-progress, completed)
Idle tasks get scheduled as workers become available
When a map task completes, it sends the master the location and sizes of its R intermediate files, one for each reducer
Master pushes this info to reducers
Master pings workers periodically to detect failures
4.3 Dealing with Failure
4.3.1 Map worker failure
Map tasks completed or in-progress at worker are reset to idle
Reduce workers are notified when task is rescheduled on another worker
4.3.2 Reduce worker failure
Only in-progress tasks are reset to idle
Reduce task is restarted
4.3.3 Master failure
MapReduce task is aborted and client is notified.
4.4 Number of Map and Reduce Jobs
Suppose: M map tasks, R reduce tasks
Rule of a thumb:
Make M much larger than the number of nodes in the cluster
One chunk per map is common
Improves dynamic load balancing and speeds up recovery from worker failures
Usually R is smaller than M
Output is spread across R files
4.5 Combiners
Function: Can save network time by pre-aggregating values in the mapper:
Combine(k, list(v)) -> v2
Combiner is usually the same as the reduce function
Works only if reduce function is commutative and associative
4.6 Partition Function
- Want to control how keys get partitioned
- Inputs to map tasks are created by contiguous splits of input file
- Reduce needs to ensure that records with the same intermediate key end up at the same worker
- System uses a default partition function: ------ Hash(key) mod R
- Sometimes useful to override the hash function:
- E.g., hash(hostname(URL)) mod R ensures URLs from a host end up in the same output file
4.6 Cost Measures for Algorithms
In MapReduce we quantify the cost of an algorithm using
4.6.1 Communication cost: total I/O of all processes
Communication cost = input file size + 2 × (sum of the sizes of all files passed from Map processes to Reduce processes) + the sum of the output sizes of the Reduce processes
4.6.2 Elapsed communication cost: Max of I/O along any path
Elapsed communication cost is the sum of the largest input + output for any map process, plus the same for any reduce process
4.6.3 (Elapsed) computation cost: running time of processes
Note that here the big-O notation is not the most useful (adding more machines is always an option)
4.6.4 Example: Cost of MapReduce Join
Total communication cost: O(|R| + |S| + |R×S|)
Elapsed communication cost = O(s), where s is the I/O limit
We’re going to pick k and the number of Map processes so that the I/O limit s is respected
We put a limit s on the amount of input or output that any one process can have
s could be:
What fits in main memory
What fits on local disk
With proper indexes, computation cost is linear in the input + output size
So computation cost is like communication cost
5 Hadoop
5.1 Function
handles the task split, task distribution, task monitoring and failure recovery
5.2 Architecturse
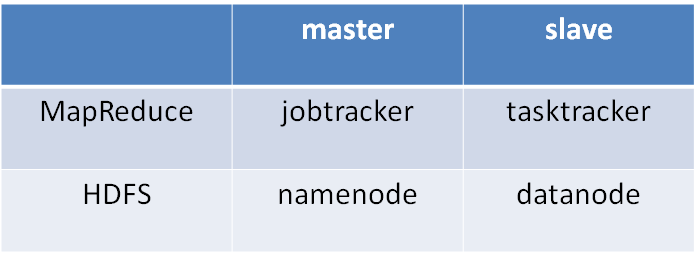
5.3 Hadoop Streaming
Allows you to start writing MapReduce application that can be readily deployed without having to learn Hadoop class structure and data types
Speed up development
Utilize rich features and handy libraries from other languages (Python, Ruby)
Efficiency critical application can be implemented in efficient language (C, C++)
6. Problems Suited for MapReduce
- Host Size, Link analysis and graph processing, ML algorithms
- MapReduce Join
- Use a hash function ℎ from B-values to 1⋯𝑘
- A Map process turns:
- Each input tuple 𝑅(𝑎,𝑏) into key-value pair (𝑏, (𝑎,𝑅))
- Each input tuple 𝑆(𝑏,𝑐) into (𝑏, (𝑐, 𝑆))
- Map processes send each key-value pair with key 𝑏 to Reduce process ℎ(𝑏)
- Hadoop does this automatically; just tell it what 𝑘 is
- Each Reduce process matches all the pairs (𝑏, (𝑎, 𝑅)) with all (𝑏,(𝑐,𝑆)) and outputs (𝑎,𝑏,𝑐).
7. TensorFlow
- Express a numeric computation as a graph
- Graph nodes are operations which have any number of inputs and outputs
- Graph edges are tensors which flow between nodes
- Portability: deploy computation to one or more CPUs or GPUs in a desktop, server, or mobile device with a single API
8. A-Priori Algorithm: Finding Frequent Items
8.1 Key idea: monotonicity
If a set of items I appears at least s times, so does every subset J of I.
Contrapositive for pairs:
If item i does not appear in s baskets, then no pair including i can appear in s baskets
8.2 Algorithm:
Pass 1: Read baskets and count in main memory the occurrences of each individual item
Requires only memory proportional to #items
Items that appear at least s times are the frequent items
Pass 2: Read baskets again and count in main memory only those pairs where both elements are frequent (from Pass 1)
Requires memory proportional to square of frequent items only (for counts)
Plus a list of the frequent items (so you know what must be counted)
8.3 MapReduce Implementation:
8.3.1 Divide the file in which we want to find frequent itemsets into equal chunks randomly.
8.3.2 Solve the frequent itemsets problem for the smaller chunk at each node. (Pretend the chunk is the entire dataset)
Given:
Each chunk is fraction 𝑝 of the whole input file (total 1/𝑝 chunks)
𝑠 is the support threshold for the algorithm
𝑝×𝑠 or 𝑝𝑠 is the threshold as we process a chunk
8.3.3 At each node, we can use A-Priori algorithm to solve the smaller problem
8.3.4 Take the group of all the itemsets that have been found frequent for one or more chunks.
Every itemset that is frequent in the whole file is frequent in at least one chunk
All the true frequent itemsets are among the candidates
8.3.5 Conclusion:
We can arrange the aforementioned algorithm in a two-pass Map-Reduce framework
First Map-Reduce cycle to produce the candidate itemsets
Second Map-Reduce cycle to calculate the true frequent itemsets.



