

ajax爬取今日头条街拍图片——data出现none的解决
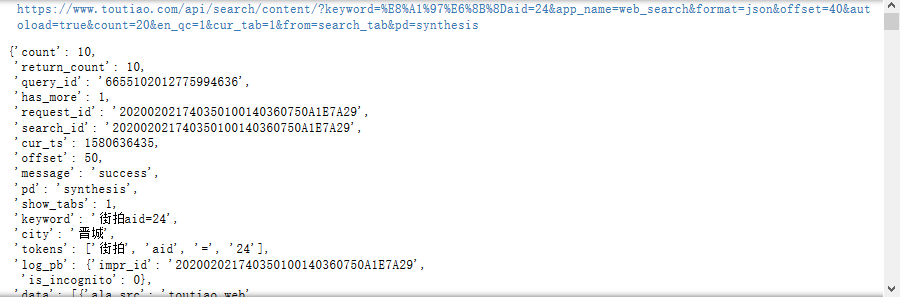
- 之前爬取总是出现如图的结果:手动打开url显示的是想要的结果,但是爬取的时候data为空

- 尝试了多种方法,偶然得到了想要的结果:
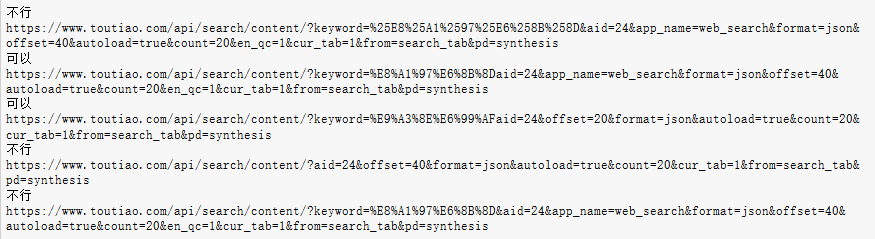 这是多次实验中成功与不成功结果中构造的url
这是多次实验中成功与不成功结果中构造的url- 发现
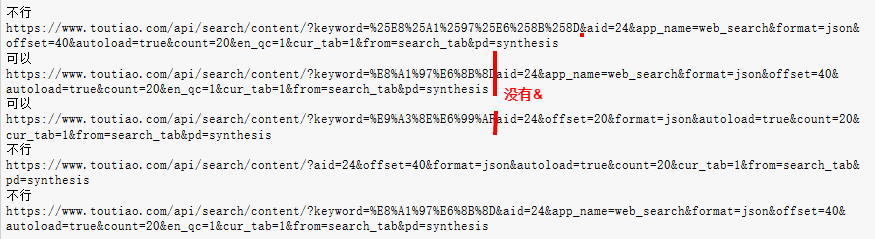
1)得到想要结果,所构造的url中keyword=******与下一参数间没有&链接
2)同样的keyword=%E8%A1%97%E6%8B%8D,参用不同的方式:‘https://www.toutiao.com/api/search/content/?keyword=%E8%A1%97%E6%8B%8D’+urlencode(params)
requests.get(‘https://www.toutiao.com/api/search/content/?’,params=params)
得到的url结果是不一样的,前一个的keyword不变,还是%E8%A1%97%E6%8B%8D,后一种方式得到的keyword变成了%25E8%25A1%2597%25E6%258B%258D
- 因为不是科班专业,仅仅根据自己所学的比较浅薄的知识连蒙带猜得出来的结果,还希望有专业人士解释一下,嘻嘻。
- 附上部分代码
import requests from urllib.parse import urlencode def get_page(offset): params={ 'aid':24, 'app_name':'web_search', 'format':'json', 'offset':offset, 'autoload':'true', 'count':20, 'en_qc':1, 'cur_tab':1, 'from':'search_tab', 'pd':'synthesis' } headers={ 'X-Requested-With':'XMLHttpRequest', 'Cookies':'tt_webid=6788393831844185614; WEATHER_CITY=%E5%8C%97%E4%BA%AC; tt_webid=6788393831844185614; csrftoken=0fd39b0f026752a8f38a902ab9226d44; s_v_web_id=k64mh7pe_9IueD6zl_X1iG_4smt_8Dkd_SMrb5NXXMR8G; __tasessionId=naf9b8ylp1580623604878', 'Host':'www.toutiao.com', 'Referer':'https://www.toutiao.com/search/?keyword=%E8%A1%97%E6%8B%8D', 'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36' } try: url='https://www.toutiao.com/api/search/content/?keyword=%E8%A1%97%E6%8B%8D'+urlencode(params) response=requests.get(url,headers=headers) response.raise_for_status response.encoding=response.apparent_encoding print(response.url) return response.json() except: print('爬取出错')


