
面向多人共用场景建立LXD容器化GPU服务器
服务器数量有限,而为最大化使用服务器资源,不可避免的会让多人共同使用一台服务器。但在共享服务器时,如果所有用户都对服务器拥有完全控制权较为危险,可能会误操作损毁他人环境、数据,还会由于各种原因,整台服务器资源直接耗尽,最后所有进程一起崩溃,不得不重启整台服务器的情况也时有发生。为解决这些问题,最直观的方法就是为每一个同学开启一个虚拟机,但完整的虚拟化方案(ESXi、KVM等)资源浪费较高,且目前显卡只能直通到虚拟机中,造成独占,想要切换设备极其麻烦。本文采用在宿主机上创建多个LXD容器的虚拟化方法,使得资源能够更好的利用。
基于上述背景提出以下需求:
- 不同用户之间通过容器机制进行隔离,且可以同时使用;
- 用户在容器内拥有所有的权限;
- 用户不能直接操作宿主机;
- 用户可以使用宿主机的所有资源,同时管理员应当能够对其使用的资源进行动态调整和限制;
- 用户可以使用SSH方便地访问自己的“服务器”;
- 用户在容器内不慎占满内存等资源时崩溃后,不会影响其他用户容器中正在运行的服务。
经过综合调研,发现基于LXC/LXD的容器隔离机制较为成熟且方便,管理员除了在前期准备合适的容器模板这一步的工作量较大,日常的维护和管理都会比较轻松。(还可以借助自动化工具和脚本辅助运行)
用户在自己的容器内拥有完整的权限,可以自己安装所需的各种软件,不会影响到其他用户。(用户直接把内核搞炸了除外)
总体方案概括:
- 每人开启容器,共享宿主机资源,计算、存储资源可控可调整,可共享文件,不能直接操作宿主机及其他人的环境。
- 访问容器通过端口转发的方式进行,从宿主机的某端口转发到容器内。
- ~/workspace作为私人工作目录保存到宿主机中,/shared_common作为公共只读数据,/network_share和/host_share作为可读写的共享数据,容器内其余数据均放置在LXD公共的zfs存储池中。
- 安装cuda、cudnn等通过从公共只读数据拷贝的方式进行,其余软件安装可任意使用方法,conda环境独立,不再担心破坏他人环境。
建立一个ZFS分区
ZFS分区用于LXC的存储池建立,最好用一块独立的分区/硬盘做,如果没有也可以在初始化LXD部分创建一个块设备,缺点是性能会降低。
安装ZFS组件
sudo apt install zfsutils-linux
创建ZFS分区
本次以/dev/sda的剩余空间创建一个zfs分区
sudo fidks /dev/sda
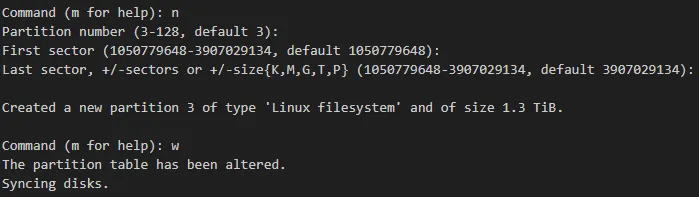
在刚创建的/dev/sda3上创建一个名为tank的zfs存储池
sudo zpool create tank /dev/sda3
sudo zpool list

安装NVIDIA驱动
安装依赖库并卸载原有驱动
# 安装依赖库
sudo apt install git gcc g++ make cmake build-essential curl -y
# 卸载原有驱动
sudo apt-get remove --purge nvidia* -y
禁用nouveau
编辑文件
sudo vi /etc/modprobe.d/blacklist-nouveau.conf
在其中加入以下内容
blacklist nouveau
options nouveau modeset=0
保存退出,更新内核并重新启动机器
sudo update-initramfs -u
sudo reboot now
安装驱动
# 下载并安装驱动
chmod a+x NVIDIA-Linux-x86_64-560.35.03.run
sudo sh NVIDIA-Linux-x86_64-560.35.03.run --no-opengl-files
# 检查安装情况
nvidia-smi

切换到持久模式
注意:一定注意显卡要么开启持久模式(无论是下文介绍的Daemon,或是自己写命令用nvidia-smi),要么在LXC容器运行之前首先调用一下显卡(nvidia-smi之类的,或是简单用cuda算一下),否则LXC容器开机无法自动启动!(REF:等我找找)
# 本次切换到持久模式,重启消失
sudo nvidia-persistenced --persistence-mode
# 检查是否安装daemon, 没安装的话下面安装, 安装了的话直接跳到修改步骤
sudo systemctl status nvidia-persistenced
# 安装持久模式Daemon(部分系统不可用)
# 拷贝init脚本安装包
cp /usr/share/doc/NVIDIA_GLX-1.0/samples/nvidia-persistenced-init.tar.bz2 ~/nvidia-persistenced-init.tar.bz2
# 解压
bzip2 -d nvidia-persistenced-init.tar.bz2
tar xvf nvidia-persistenced-init.tar
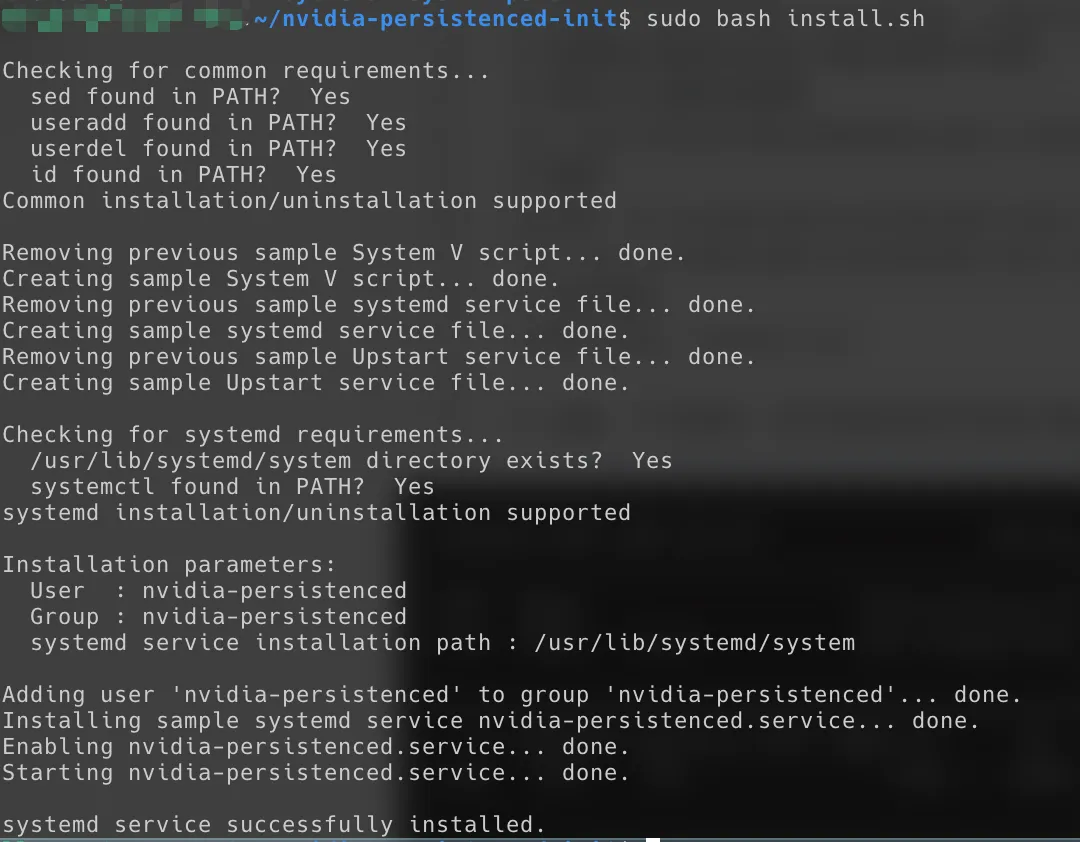
# 运行脚本
sudo bash install.sh
# 修改持久模式开机自启动
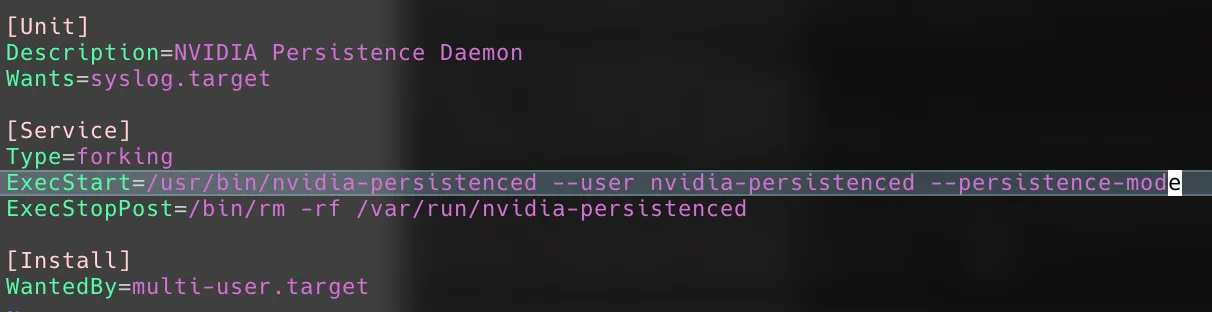
vi /lib/systemd/system/nvidia-persistenced.service
# 对照下面,一定是--persistence-mode,而不是--no-persistence-mode
# 注意:一定注意显卡要么按照要求开启持久模式,要么在LXC容器运行之前首先调用一下显卡,否则LXC容器开机无法自动启动!
(成功开启是这样的,注意--persistence-mode)
安装NVIDIA容器化组件
REF: Installing the NVIDIA Container Toolkit — NVIDIA Container Toolkit 1.16.0 documentation
# 添加APT源
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt update
# 安装, 官方提示第一句, 但我装的是第二句
# sudo apt-get install -y nvidia-container-toolkit
sudo apt install libnvidia-container-dev libnvidia-container-tools nvidia-container-runtime
准备运行时环境
CUDA与CUDNN
为了简化容器中安装 CUDA 的工作,这里在宿主机安装大部分版本的 CUDA ,完成后将文件汇总后作为公共资源挂载到容器中。容器中需要安装时只需复制文件并配置相关的环境变量即可使用,无需重新安装。若使用 ZFS 等 Copy-On-Write 存储后端,所有用户的 CUDA 文件只占用一份空间。这里传入 --silent --toolkit 参数保证安装过程中只安装 cuda-toolkit 而不安装驱动和示例文件,传入 --override 参数则忽略对 gcc 版本等的检查,保证文件能正常生成。
(REF: 通过LXD搭建实验室共享GPU服务器 | 杨钦翔的博客 (yqxpro.com))
# 安装依赖
sudo apt install -y perl
# 下载cuda安装包文件并执行安装(注意不要安装其中的驱动)
# Note: 若空间不足可将目录移动至其他分区中,在原来的位置放置软链接
sudo sh cuda_11.4.2_470.57.02_linux.run --silent --toolkit --override
sudo sh cuda_11.3.1_465.19.01_linux.run --silent --toolkit --override
sudo sh cuda_11.2.2_460.32.03_linux.run --silent --toolkit --override
sudo sh cuda_11.1.1_455.32.00_linux.run --silent --toolkit --override
sudo sh cuda_11.0.3_450.51.06_linux.run --silent --toolkit --override
sudo sh cuda_10.2.89_440.33.01_linux.run --silent --toolkit --override
sudo sh cuda_10.1.105_418.39_linux.run --silent --toolkit --override
sudo sh cuda_10.0.130_410.48_linux --silent --toolkit --override
sudo sh cuda_9.2.148_396.37_linux --silent --toolkit --override
sudo sh cuda_9.1.85_387.26_linux --silent --toolkit --override
sudo sh cuda_9.0.176_384.81_linux-run --silent --toolkit --override
sudo sh cuda_8.0.61_375.26_linux-run --silent --toolkit --override
# 宿主机如果有闲心也可以配置一个默认的CUDA版本, 注意不要忘了添加环境变量
#sudo rm /usr/local/cuda
#sudo ln -s /usr/local/cuda-10.0 /usr/local/cuda
CUDNN也是同样,下载特定的版本然后解压备用就可以了,有需要时直接复制到安装好的CUDA目录里即可。
gcc/g++环境(宿主机可选)
安装各版本 gcc 供编译 CUDA 程序时使用,下面的方法中将各版本优先级设为版本号,因此默认使用版本号的 gcc-9 和 g++-9
注意,此处可选。不一定都要安装,按照需求选择常用即可。下文为确保最大通用性,选择安装了gcc6。
# 通过update-alternatives可以快速切换gcc版本
# 选择需要的即可, 无需全部安装
sudo apt install -y gcc-5 g++-5 gcc-6 g++-6 gcc-7 g++-7 gcc-8 g++-8 gcc-9 g++-9
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-5 5
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-6 6
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-7 7
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-8 8
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-9 9
sudo update-alternatives --display gcc
sudo update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-5 5
sudo update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-6 6
sudo update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-7 7
sudo update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-8 8
sudo update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-9 9
sudo update-alternatives --display g++
如果有进一步在宿主机使用的需求,还可以将不同版本的gcc/g++直接链接到cuda环境中,避免切换默认版本。如不链接,使用update-alternatives程序也可切换。
# 下文的容器使用 Ubuntu 18.04 作为基础,其软件仓库中有5到8版本的 gcc 和 g++
# 因此需要使用 gcc-4 的 cuda-8.0 内容已注释
# CUDA 11.4 等可以使用更高版本 gcc 的也只链接到 gcc-8
sudo ln -s /usr/bin/gcc-8 /usr/local/cuda-11.4/bin/gcc
sudo ln -s /usr/bin/gcc-8 /usr/local/cuda-11.3/bin/gcc
sudo ln -s /usr/bin/gcc-8 /usr/local/cuda-11.2/bin/gcc
sudo ln -s /usr/bin/gcc-8 /usr/local/cuda-11.1/bin/gcc
sudo ln -s /usr/bin/gcc-8 /usr/local/cuda-11.0/bin/gcc
sudo ln -s /usr/bin/gcc-8 /usr/local/cuda-10.2/bin/gcc
sudo ln -s /usr/bin/gcc-8 /usr/local/cuda-10.1/bin/gcc
sudo ln -s /usr/bin/gcc-7 /usr/local/cuda-10.0/bin/gcc
sudo ln -s /usr/bin/gcc-7 /usr/local/cuda-9.2/bin/gcc
sudo ln -s /usr/bin/gcc-6 /usr/local/cuda-9.1/bin/gcc
sudo ln -s /usr/bin/gcc-6 /usr/local/cuda-9.0/bin/gcc
#sudo ln -s /usr/bin/gcc-4 /usr/local/cuda-8.0/bin/gcc
sudo ln -s /usr/bin/g++-8 /usr/local/cuda-11.4/bin/g++
sudo ln -s /usr/bin/g++-8 /usr/local/cuda-11.3/bin/g++
sudo ln -s /usr/bin/g++-8 /usr/local/cuda-11.2/bin/g++
sudo ln -s /usr/bin/g++-8 /usr/local/cuda-11.1/bin/g++
sudo ln -s /usr/bin/g++-8 /usr/local/cuda-11.0/bin/g++
sudo ln -s /usr/bin/g++-8 /usr/local/cuda-10.2/bin/g++
sudo ln -s /usr/bin/g++-8 /usr/local/cuda-10.1/bin/g++
sudo ln -s /usr/bin/g++-7 /usr/local/cuda-10.0/bin/g++
sudo ln -s /usr/bin/g++-7 /usr/local/cuda-9.2/bin/g++
sudo ln -s /usr/bin/g++-6 /usr/local/cuda-9.1/bin/g++
sudo ln -s /usr/bin/g++-6 /usr/local/cuda-9.0/bin/g++
#sudo ln -s /usr/bin/g++-4 /usr/local/cuda-8.0/bin/g++
安装LXD
sudo apt install lxd lxd-client
拉取远端Ubuntu18.04镜像到本地
设置LXC代理
sudo lxc config set core.proxy_http http://<ProxyIP>:<ProxyPort>/
sudo lxc config set core.proxy_https http://<ProxyIP>:<ProxyPort>/
拉取镜像
lxc image copy ubuntu:18.04 local: --alias ubuntu/18.04 --copy-aliases --public
从ubuntu源拉取18.04版本,并放到本地ubuntu/18.04中
以后要用的话这么用:local:ubuntu/18.04
LXD容器配置
创建默认的lxd容器配置
lxd init
# 是否需要集群
Would you like to use LXD clustering? (yes/no) [default=no]:
# 是否要在lxd里面挂一个新的存储池?
Do you want to configure a new storage pool? (yes/no) [default=yes]:
# 存储池名字
Name of the new storage pool [default=default]:
# 后端用的究竟是什么,这里选zfs
Name of the storage backend to use (btrfs, dir, lvm, zfs, ceph) [default=zfs]:
# 需要创建一个新的zfs池吗?刚刚已经创建过了,选no
Create a new ZFS pool? (yes/no) [default=yes]: no
# 填写刚刚创建的池名称,tank
Name of the existing ZFS pool or dataset: tank
Would you like to connect to a MAAS server? (yes/no) [default=no]: no
# 这里桥接网络
Would you like to create a new local network bridge? (yes/no) [default=yes]:
What should the new bridge be called? [default=lxdbr0]:
What IPv4 address should be used? (CIDR subnet notation, “auto” or “none”) [default=auto]:
What IPv6 address should be used? (CIDR subnet notation, “auto” or “none”) [default=auto]:
Would you like the LXD server to be available over the network? (yes/no) [default=no]:
Would you like stale cached images to be updated automatically? (yes/no) [default=yes]
Would you like a YAML "lxd init" preseed to be printed? (yes/no) [default=no]:
至此,lxd的默认配置default就创建完毕。下面将直接在默认配置文件default中做修改,如果想要新建的话也可以新建一个配置文件后再修改。
修改宿主机系统UID GID范围
sudo vi /etc/subuid
修改内容为:
lxd:1000:1000
root:1000:1000
lxd:100000:10000000
root:100000:10000000
sudo vi /etc/subgid
修改内容为:
lxd:1000:1000
root:1000:1000
lxd:100000:10000000
root:100000:10000000
另外,我们还要配置 idmap,首先查看 /etc/subuid 和 /etc/subgid 这两个文件的内容,两个文件内容应该是一样的,默认为:
lxd:100000:65536
root:100000:65536
这表示将允许用户 root 使用宿主机中的 uid/gid,从 100000 开始的 65536 个 id,用于容器内的分配.lxd 中一行按照文档的说法是用于在卸载 LXD 是应该删掉哪些行而已,因此应该与 root 那行保持一致.这样子的话,容器内的 root 用户(uid/gid 均为 0)在宿主机看来他的 uid/gid 就是 100000,容器内的其他用户 uid/gid 也相应的递增映射.也就是说,容器内的 root 用户与容器外的 root 用户并不等价,而是映射到了一个不存在的用户的 uid/gid,规避了安全问题.这是 LXD 的默认运行方式,即在非特权模式下运行.容器内的用户无法逃逸到宿主机,对宿主机造成破坏.但是呢,我们想要让宿主机里的用户 tom 和容器中的 ubuntu 用户相互映射,从而实现宿主机和容器的文件共享,并保证宿主机中的文件权限不会混乱.此时就可以使用 LXD 的 raw.id 配置了.为此,将 /etc/subuid 和 /etc/subgid 文件中的 lxd 和 root 两行都删掉,重新添加以下四行:
lxd:1000:1000
root:1000:1000
lxd:100000:10000000
root:100000:10000000
这里我们把原来允许使用的 id 数量增加了,这是为了嵌套使用容器而设置的,POSIX 要求可用的 id 至少有 65536 个.然后,我们还设置允许用户 root 使用 uid/gid 从 1000 开始的 1000 个 id.这是正好我们在宿主机创建的 uid/gid 默认是从 1000 开始递增的.修改 /etc/subuid 和 /etc/subgid 需要重启 lxd 服务才能生效:systemctl restart lxd.
TIPS:这里的 idmap 的设置是为了方便管理,管理员也可以考虑跳过.只需要给不同的容器在宿主机上分配不同的目录挂载进去给用户使用,不要允许用户访问宿主机,问题也不大.不过好像这样子管理员在宿主机上也看不出来到底是哪个用户在占用显存了.在宿主机上用 nvidia-smi 命令查到进程的 pid,再根据 pid 去查看对应的用户的 uid 应该就都是一样的.为了管理方便,还是多做点吧.
REF: 面向深度学习训练的LXD GPU 服务器搭建、管理与使用 (butui.me)
非特权GPU容器default配置
其中default均为配置名,配置(profile)配合镜像,可以快速地启动一个容器,简单来说,配置(profile)可以认为是告诉lxc如何决定其下附属的容器的各种资源限制、硬盘挂载等信息,而镜像提供操作系统有关的资源。
# 添加nvidia runtime, 主机的驱动直接传递到容器中
# !!注意此选项与特权容器的security.privileged=true冲突!!
lxc profile set default nvidia.runtime true
lxc profile set default security.privileged=false
# 添加GPU设备
lxc profile device add default gpu gpu
# 开机自启动容器
lxc profile set default boot.autostart true
# 限制CPU
lxc profile set default limits.cpu 24
# 限制内存用量, 注意64GiB
lxc profile set default limits.memory 64GiB
# 添加硬盘与挂载点
# 修改根目录默认大小(root是lxc profile show default看来的)
lxc profile device set default root size 200GB
# 添加一个只读的挂载点
lxc profile device add default shared_common disk source=/shared_common path=/shared_common readonly=true
# 添加一个读写的挂载点
lxc profile device add default host_share disk source=/host_share path=/host_share
# 添加banner文件以实现用户登录时输出引导信息(如果不注释的话)
#lxc profile device add default lxd-banner disk source=<banner-file> path=/etc/motd readonly=true
# Ubuntu用这个
lxc profile device add default motd disk source=/99-container-tip path=/etc/update-motd.d/99-container-tip readonly=true
# 确认default Profile内容
lxc profile show default
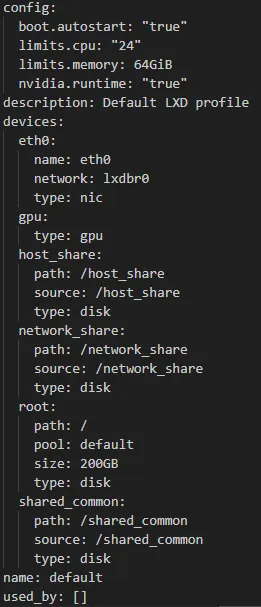
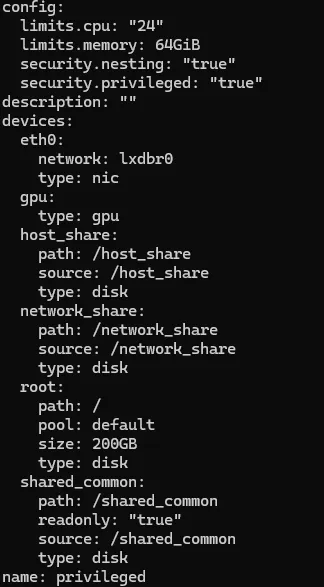
特权容器配置
该配置不是必须,具体特权容器和非特权容器有什么区别(REF: 无特权容器vs特权容器——PVE下创建LXC容器基础流程_网络存储_什么值得买 (smzdm.com))
# 创建一个新的profile用于特权容器配置, 名字设置为privileged
lxc profile create privileged
# 添加GPU
lxc profile device add privileged gpu gpu
# 特权容器
# !!注意, 不能与nvidia.runtime=true混用, 会冲突!!
lxc profile set privileged security.privileged=true
lxc profile set nvidia.runtime=false
# 允许在其中创建嵌套容器(docker等)
lxc profile set privileged security.nesting=true
# 添加网卡, 注意网桥名称是刚刚init里面创建的
lxc profile device add privileged eth0 nic network=lxdbr0
# 添加根目录
lxc profile device add privileged root disk pool=default path=/ size=200GB
# 添加其他挂载
lxc profile device add privileged host_share disk source=/host_share path=/host_share
lxc profile device add privileged network_share disk source=/shared_common path=/shared_common readonly=true
# 添加CPU, 内存等资源限制
lxc profile set privileged limits.cpu 24
lxc profile set privileged limits.memory 64GiB
# 添加banner文件以实现用户登录时输出引导信息(如果不注释的话)
#lxc profile device add privileged lxd-banner disk source=<banner-file> path=/etc/motd readonly=true
# 检查配置
lxc profile show privileged
LXD初始镜像配置与发布
以default配置为例,启动第一个容器,进行一些配置,最后保存为镜像模板(template)。
启动第一个容器并配置
# 创建容器demo-1804-default, 基础镜像为刚刚拉取的ubuntu 18.04
lxc launch local:ubuntu/18.04 demo-1804-default
# 进入容器bash
lxc exec demo-1804-default bash
进入容器bash后,就可以进行一些配置了。如修改时区、换源、安装一些必要软件、修改ssh密码登录、设置gcc/g++编译器的优先顺序等,还可根据需要安装桌面(REF:GitHub - shenuiuin/LXD_GPU_SERVER: 实验室GPU服务器的LXD虚拟化, 面向深度学习训练的LXD GPU 服务器搭建、管理与使用 (butui.me))。
# 安装相关软件包, 这里考虑到兼容性和体积平衡只装了gcc6, 至少支持cuda9-12
apt install -y zip perl gcc-6 g++-6 build-essential
# 别忘了使用update-alternatives, 具体参见本文gcc/g++环境(宿主机可选)配置
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-6 80
sudo update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-6 80
sudo update-alternatives --display gcc
sudo update-alternatives --display g++
# 修改时区
timedatectl set-timezone Asia/Shanghai
# 修改SSH密码登录
vi /etc/ssh/sshd_config
# 在Ubuntu 20.04镜像中, 多了一个/etc/ssh/sshd_config.d/60-cloudimg-settings.conf
# 会覆盖默认的sshd_config设置, 可以直接删除文件, 也可以修改内容
# 注意, 采用ubuntu官方lxd镜像时, 换源需要在/etc/cloud/templates/sources.list.ubuntu.tmpl中更改
# 否则会失效
# 在这个文件中写入原本应在sources.list的内容
vi /etc/cloud/templates/sources.list.ubuntu.tmpl
# 清除apt缓存
rm -rfv /var/lib/apt/lists/*
# 清除痕迹
>/var/log/wtmp
>/var/log/btmp
>/var/log/lastlog
>~/.bash_history
history -c
# 等等...
退出前也别忘了删除APT缓存、删除代理、APT代理、登录与命令记录等等。
特权容器在使用时,容器内需要安装与宿主机同样版本的NVIDIA驱动,同时不可安装内核模块,具体命令如下:
(非特权容器不要在容器内安装驱动,否则会导致驱动和CUDA环境异常)
宿主机中NVIDIA驱动版本不要升级
# 注意不要安装内核模块, --no-kernel-module参数
sudo sh NVIDIA-Linux-x86_64-560.35.03.run --no-kernel-module --no-opengl-files
保存容器为镜像模板
# 退出并停止容器
exit
lxc stop demo-1804-default
# 记得关闭自动启动,否则该模板每次开机都会自启
lxc config set demo-1804-default boot.autostart="false"
# 保存容器为镜像模板, 名字为template-ubuntu-1804-default
lxc publish demo-1804-default --alias template-ubuntu-1804-default
# 可以查看当前镜像模板, alias同名时以最新的为准, 还可以管理不需要的镜像等
lxc images list
这里我们将容器保存为镜像模板,并且设置该镜像的别名为 template-ubuntu-1804-default。以后,只需从该模板创建容器给用户使用即可。
真正的开启第一个用户镜像
上面,我们创建了一个镜像模板。可以用该模板来快速的创建一个容器。如果要使用刚刚创建的模板给用户user创建一个名字为user-container的容器,只需要使用命令:
lxc launch template-ubuntu-1804-default user-container
创建容器后,如何管理也就成了个难题。从方便管理的角度考虑,我们在宿主机也创建用户user,但是不设置密码,同时将其SHELL设置为nologin,user用户就无法登录到宿主机。
同时我们把宿主机user用户的home目录挂载到容器内,并设置好权限,使得宿主机中的用户user与容器内的用户ubuntu映射起来,从而实现容器内的用户ubuntu可以读写挂载进来的user用户的home目录。
这样即可以保证容器内的用户可以将数据持久化存储到宿主机挂载进来的目录,而在宿主机这边管理员也可以很好的管理和区分不同用户的文件。
# 在宿主机创建用户 user
useradd -m -s $(which nologin) user
# 将宿主机中用户 user 的 home 目录挂载到容器内的 /home/ubuntu/user 目录去
# 如果你是在宿主机安装的 Anaconda/Miniconda,可以直接将 user 目录挂载到 /home/ubuntu 目录去
# 这样子用户的所有数据都会保存到宿主机上的 /hom/user 目录,容器出错直接删除即可,数据也不会丢失.
lxc config device add user-container home disk source=/home/user path=/home/ubuntu/user
# 设置该容器的 idmap,让宿主机的 user 用户可以映射到容器内的 ubuntu 用户
printf "uid $(id user -u) 1000\ngid $(id user -g) 1000" | lxc config set user-container raw.idmap -
# 检查 raw.idmap 的设置
lxc config get user-container raw.idmap
# 应该得到类似这样的输出:
uid 1003 1000
gid 1003 1000
# 这说明,宿主机的 user 用户的 uid 和 gid 都分别映射到容器内的 ubuntu 用户的 uid 和 gid 了
# 也就是说,容器内 ubuntu 用户的权限等价与宿主机里 user 用户的权限,从而可以读写挂载进容器的
# user 用户的 home 目录
# 最后请注意,raw.idmap的设置需要重启容器后才生效!
(REF:面向深度学习训练的LXD GPU 服务器搭建、管理与使用 (butui.me))
甚至更高级一点的做法是采用自动化脚本(不嫌麻烦手打也可以),每次新容器创建后,删除原有的ubuntu用户,再在容器内新建一个与用户user同名的账户,创建对应的UID、GID映射,做到更加舒适的使用容器环境。(同样,修改raw.idmap设置后需要重启容器才可生效!)
# $CONTAINER_NAME容器名称
# $USERNAME 用户名
echo "[+] Deleting default user ubuntu and adding new user $USERNAME"
lxc exec $CONTAINER_NAME -- bash -c "deluser --remove-home ubuntu"
lxc exec $CONTAINER_NAME -- bash -c "groupdel ubuntu"
lxc exec $CONTAINER_NAME -- bash -c "useradd -m $USERNAME -s /bin/bash"
lxc exec $CONTAINER_NAME -- bash -c "echo '$USERNAME ALL=(ALL) ALL' >> /etc/sudoers"
CONTAINER_UID=$(lxc exec $CONTAINER_NAME -- bash -c "id $USERNAME -u")
CONTAINER_GID=$(lxc exec $CONTAINER_NAME -- bash -c "id $USERNAME -g")
echo "Container New Username: $USERNAME, New UID:$CONTAINER_UID, New GID:$CONTAINER_GID"
# 读取宿主机上该用户名UID和GID
PHYSICAL_UID=$(id $USERNAME -u)
PHYSICAL_GID=$(id $USERNAME -g)
echo "[+] Physical Server User UID: $PHYSICAL_UID, GID: $PHYSICAL_GID"
# 修改raw.idmap设置, 建立容器到宿主机的UID和GID映射
echo "[+] Modifying raw.idmap to align container user ubuntu to outside user $USERNAME..."
printf "uid %s %s\ngid %s %s" "$PHYSICAL_UID" "$CONTAINER_UID" "$PHYSICAL_GID" "$CONTAINER_GID" | lxc config set "$CONTAINER_NAME" raw.idmap -
if [ $? -eq 0 ]; then
echo "[+] Successfully updated raw.idmap for container $CONTAINER_NAME."
else
echo "[+] Failed to update raw.idmap for container $CONTAINER_NAME."
fi
echo "[+] Confirm raw.idmap setting..."
lxc config get "$CONTAINER_NAME" raw.idmap
# 重启容器后才可生效
echo "[+] Restarting Container..."
lxc restart "$CONTAINER_NAME"
由于采用了NAT,无法直接被外部所连接,还需要建立一个转发,将宿主机上的端口转发到容器中。以将名字为user-container的容器的22端口转发到宿主机的30000端口为例,执行以下命令添加转发。
lxc config device add user-container proxy0 proxy listen=tcp:0.0.0.0:30000 connect=tcp:127.0.0.1:22 bind=host
还可以直接重置容器内用户的密码,以user-container为容器名,user为用户名,user123为密码,并强制该用户下次登录时修改密码。
lxc exec user-container -- bash -c "echo 'user:user123' | chpasswd"
lxc exec user-container -- bash -c "passwd -e user"
还记得刚刚设置的特权容器吗?要是想用特权的配置来启动刚刚做好的镜像模板怎么办?只需使用以下命令。
# TEMPLATE_NAME为模板名, 这里可以填写刚刚配置好的template-ubuntu-1804-default
# PROFILE_NAME为配置, 这里可以填写刚刚创建的privileged配置
# CONTAINER_NAME为容器名, 容器创建后要叫什么名字
lxc launch TEMPLATE_NAME -p PROFILE_NAME CONTAINER_NAME
# 甚至还可以增加多个profile来创建一个镜像!
lxc launch TEMPLATE_NAME -p PROFILE1 -p PROFILE2 CONTAINER_NAME
为了确保CUDA和NVIDIA驱动能够正常在容器内使用,正式上线使用前将宿主机系统重启,并创建虚拟机进行测试确保CUDA可用。(似乎显卡确实需要开启持久模式才能正常使用)
如何针对单个容器调整相关限制?
# 调整内存限制到32GiB
lxc config set CONTAINER_NAME limits.memory 32GiB
到此,基本上的流程已经结束了。随后就是对容器的自定义发挥、安装组件以及运行计算程序了,本文以Ubuntu 18.04为例,事实上后续也创建了不同的系统版本供使用。后续也可以编写自动化脚本来减轻工作量,方便维护管理。还有一个方向就是组成LXD集群,容器可以自由地在其中转移、复制、执行任务,需要较大的工作量。
经过测试,容器化的服务器能够实现较好的数据与环境隔离,容器内的进程在超出内存限制后也会被强制Kill,在宿主机内存未被占满之前,不会影响到宿主机和其他容器内的进程运行。
NVIDIA显卡在训练时,多人同时使用一张卡的行为也是允许的,但可能由于切换时间的因素影响,整体的训练速度会更慢。
一些注意事项
- 经过观察,宿主机重启之后需要先使用一下显卡,如nvidia-smi等操作后,才能正常启动挂载了GPU的容器,否则容器无法正常启动。具体原因未知,其它教程中也都提到了这一点。
- 同时,如果宿主机重启之后会出现挂在了GPU的容器正常启动,但是容器内无法正常使用CUDA的情况,一个典型的报错是这样的:
>>> torch.cuda.is_available()
/home/xxx/miniconda3/envs/xxx/lib/python3.6/site-packages/torch/cuda/__init__.py:80: UserWarning: CUDA initialization: CUDA unknown error - this may be due to an incorrectly set up environment, e.g. changing env variable CUDA_VISIBLE_DEVICES after program start. Setting the available devices to be zero. (Triggered internally at ../c10/cuda/CUDAFunctions.cpp:112.)
return torch._C._cuda_getDeviceCount() > 0
False
这时候,只需要在宿主机内使用一下显卡,如nvidia-smi等操作,再重启容器,即可在容器内正常使用。

3. 修改镜像后,有时候启动的容器会无法生成初始的SSH链接密钥,导致用户无法连接容器。只需要在容器刚建立好时,重新配置SSH服务即可。
lxc exec CONTAINER_NAME -- bash -c "dpkg-reconfigure openssh-server"
附录
安装CUDA和CUDNN参考流程
# 安装CUDA和CUDNN参考流程
# 拷贝CUDA到本地(10.2版本为例)
sudo cp -r /shared_common/cuda/cuda-10.2 /usr/local/cuda-10.2
# 建立软连接(10.2版本为例)
sudo rm -rf /usr/local/cuda
sudo ln -s /usr/local/cuda-10.2 /usr/local/cuda
#下面内容写入到~/.bashrc(如有同样内容请不要重复添加)
# CUDA enviroment variable
export PATH=$PATH:/usr/local/cuda/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib64
export CUDA_HOME=$CUDA_HOME:/usr/local/cuda
#执行命令更新
source ~/.bashrc
# 验证安装
nvcc -V
# 安装CUDNN(不需要安装的不用看,cuda10.2版本为例)
sudo cp /shared_common/cudnn/cudnn7.6.5-cuda10.2/cuda/include/cudnn*.h /usr/local/cuda/include
sudo cp /shared_common/cudnn/cudnn7.6.5-cuda10.2/cuda/lib64/libcudnn* /usr/local/cuda/lib64
sudo chmod a+r /usr/local/cuda/include/cudnn*.h /usr/local/cuda/lib64/libcudnn*
# 检查是否安装成功
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2
如果输出下面内容,代表安装成功:
#define CUDNN_MAJOR 7
#define CUDNN_MINOR 6
#define CUDNN_PATCHLEVEL 5
--
#define CUDNN_VERSION (CUDNN_MAJOR * 1000 + CUDNN_MINOR * 100 + CUDNN_PATCHLEVEL)
#include "driver_types.h"

