YOLOv5快速入门和使用
一、配置虚拟环境(不止是YOLO如果使用其余的需要隔离环境也可以这样操作)
为了防止影响我们电脑上已有的Python环境,我们可以使用Anaconda配置虚拟环境,如果没有请先找教学安装一下。
(一)、创建虚拟环境
使用 Anaconda 自带的cmd命令行,不知道在哪里?直接使用电脑搜索框搜一下:Anaconda Prompt 这个就是了
提示:(一)到(七)均是在Anaconda的cmd中运行哦
conda create -n yolov5 python=3.8 # 创建一个名为 yolov5 的虚拟环境,使用的是python3.8
(二)、激活虚拟环境
conda activate yolov5
(三)、查看已经安装好的包
pip list
(四)、配置国内源
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
(五)、运行环境安装
1、先切换到指定路径下:
# 切换盘符,你的yolov5源码所在的盘符 F: # 到达指定路径 cd 这里是你从github上拉取的yolov5的源码文件根目录
2、根据自己的NVIDIA的控制面板选择合适(比自己的NVIDIA CUDA低的就行)的PyTorch(https://pytorch.org/get-started/previous-versions/)版本:

比如选择一下这个版本安装(可以将pip3 换为 pip):

3、安装其他环境(安装前先参考一下我的配置文件):
# 安装其他的依赖,如果你的目录下没有这个文件,说明你还没有到项目根目录下,或者你拉取的代码有误 pip install -r requirements.txt ################ 参考文件,修改了其中的numpy版本为等于 ################ # YOLOv5 requirements # Usage: pip install -r requirements.txt # Base ------------------------------------------------------------------------ gitpython>=3.1.30 matplotlib>=3.3 numpy==1.20.3 opencv-python>=4.1.1 Pillow>=9.4.0 psutil # system resources PyYAML>=5.3.1 requests>=2.23.0 scipy>=1.4.1 thop>=0.1.1 # FLOPs computation torch>=1.8.0 # see https://pytorch.org/get-started/locally (recommended) torchvision>=0.9.0 tqdm>=4.64.0 ultralytics>=8.0.232 # protobuf<=3.20.1 # https://github.com/ultralytics/yolov5/issues/8012 # Logging --------------------------------------------------------------------- # tensorboard>=2.4.1 # clearml>=1.2.0 # comet # Plotting -------------------------------------------------------------------- pandas>=1.1.4 seaborn>=0.11.0 # Export ---------------------------------------------------------------------- # coremltools>=6.0 # CoreML export # onnx>=1.10.0 # ONNX export # onnx-simplifier>=0.4.1 # ONNX simplifier # nvidia-pyindex # TensorRT export # nvidia-tensorrt # TensorRT export # scikit-learn<=1.1.2 # CoreML quantization # tensorflow>=2.4.0,<=2.13.1 # TF exports (-cpu, -aarch64, -macos) # tensorflowjs>=3.9.0 # TF.js export # openvino-dev>=2023.0 # OpenVINO export # Deploy ---------------------------------------------------------------------- setuptools>=65.5.1 # Snyk vulnerability fix # tritonclient[all]~=2.24.0 # Extras ---------------------------------------------------------------------- # ipython # interactive notebook # mss # screenshots # albumentations>=1.0.3 # pycocotools>=2.0.6 # COCO mAP wheel>=0.38.0 # not directly required, pinned by Snyk to avoid a vulnerability
(六)、查看和删除对应的虚拟环境(一点补充)
# 查看所有的虚拟环境 conda env list # 删除指定的虚拟环境 conda env remove --name yolov5
(七)、如果遇到换源的地址没有对应版本(没遇到就不管):
# 如阿里云没有的环境就需要单独安装,这里只是一个例子 pip install torch==1.8.2 torchvision==0.9.2 torchaudio==0.8.2 --extra-index-url https://download.pytorch.org/whl/lts/1.8/cu102
(八)、在PyCharm中设置虚拟环境
在此处找到我们设置的虚拟环境地址并选择其中的.exe文件即可:

查看是否成功(使用终端打开,看到命名行前面又这个环境即可):

确定安装好了:
可以使用默认的训练文件看看能不能检测,这里推荐使用本机摄像头,可以正常运行识别就表示你的环境好了,就算失败也是虚拟环境不怕,根据问题去网上找答案吧,大概率没有配置好。
python detect.py --weights yolov5s.pt --source 0 # webcam 本机摄像头 img.jpg # image vid.mpp4 # video screen # screenshot path/ # directory list.txt # list of images list.streams # list of streams 'path/*.jpg' # glob
二、训练自己的模型(使用PyCharm)
友情提示: 为了防止 labelimg打标签 闪退和辛勤付出打水漂,推荐使用在线的打标网站打标,而且有些网站还可以团队合作和选择更多形状的框框出特征:https://www.makesense.ai/ 这样的网站很多,如果有好的也可以推荐给我,可以先找好并会用了再开始。——工欲善其事,必先利其器
(一)、数据准备:
首先准备好原始图片数据,可以使用下面程序通过旋转生成更多图片:
from math import * import cv2 import os import glob import imutils import numpy as np # 如果这里导入依赖有问题,可以直接使用pip 在已经配置号python环境的基础上 # 通过旋转角度来快速获取大量图片 def rotate_img(img, angle): ''' img --image angle --rotation angle return--rotated img ''' h, w = img.shape[:2] rotate_center = (w / 2, h / 2) # 获取旋转矩阵 # 参数1为旋转中心点; # 参数2为旋转角度,正值-逆时针旋转;负值-顺时针旋转 # 参数3为各向同性的比例因子,1.0原图,2.0变成原来的2倍,0.5变成原来的0.5倍 M = cv2.getRotationMatrix2D(rotate_center, angle, 1.0) # 计算图像新边界 new_w = int(h * np.abs(M[0, 1]) + w * np.abs(M[0, 0])) new_h = int(h * np.abs(M[0, 0]) + w * np.abs(M[0, 1])) # 调整旋转矩阵以考虑平移 M[0, 2] += (new_w - w) / 2 M[1, 2] += (new_h - h) / 2 rotated_img = cv2.warpAffine(img, M, (new_w, new_h)) return rotated_img if __name__ == '__main__': output_dir = "train-image" # 生成到的文件夹 image_names = glob.glob("images/b-zu.png") # 对应图片 for image_name in image_names: image = cv2.imread(image_name, -1) for i in range(1, 361): # 1 —— 360左闭右开 rotated_img1 = rotate_img(image, i) basename = os.path.basename(image_name) tag, _ = os.path.splitext(basename) cv2.imwrite(os.path.join(output_dir, 'b-zu-%d.jpg' % i), rotated_img1)
(二)、安装对应的标记软件——labelimg(为防闪退一标到底,随意切换恨意满满)
1、安装
pip install labelimg -i https://pypi.tuna.tsinghua.edu.cn/simple
2、打开 pycharm 控制台
labelimg
3、使用
先设置:


创建两个文件用于存放训练的图片和标签:

保存标签文件的地址:

选择需要标记的图片:

操作(标记和下一张):
按下 W 键即可出现一个十字架,按下鼠标左键就可以圈定范围,然后可以给这个访问标记一个名字
注意:标记名不要使用中文,同时标记特征尽可能不要涵盖其他特征

按下d进入下一张图片,可以这样依次打完
(三)、准备对应的GPU环境(你也可以使用自己的电脑训练只是有点久,但是这个将代码上传的速度也吃网速)
这里如果自己电脑配置不好可以去租用云GPU来进行模型训练,例如矩池云地址:https://www.matpool.com/
1、先冲值一定金额,在网盘中准备好需要使用的文件
2、然后租用一个GPU选择对应的镜像配置(这里有现成的YOLOv5环境)
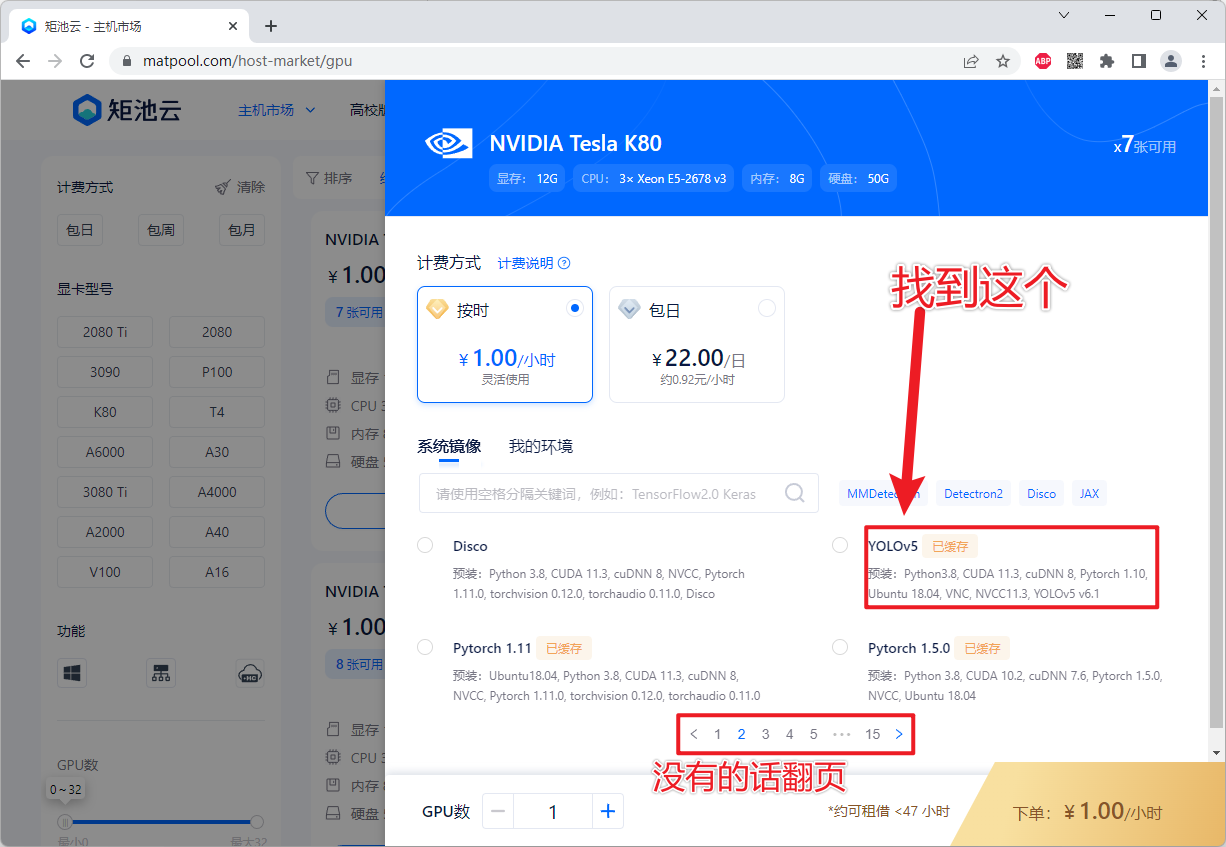
3、租用成功后 鼠标右击win键然后选择Windows PowerShell 进行连接
注意:对应运行好的实例有对应连接地址和密码复制后鼠标右键粘贴即可,密码复制右键就粘贴上了
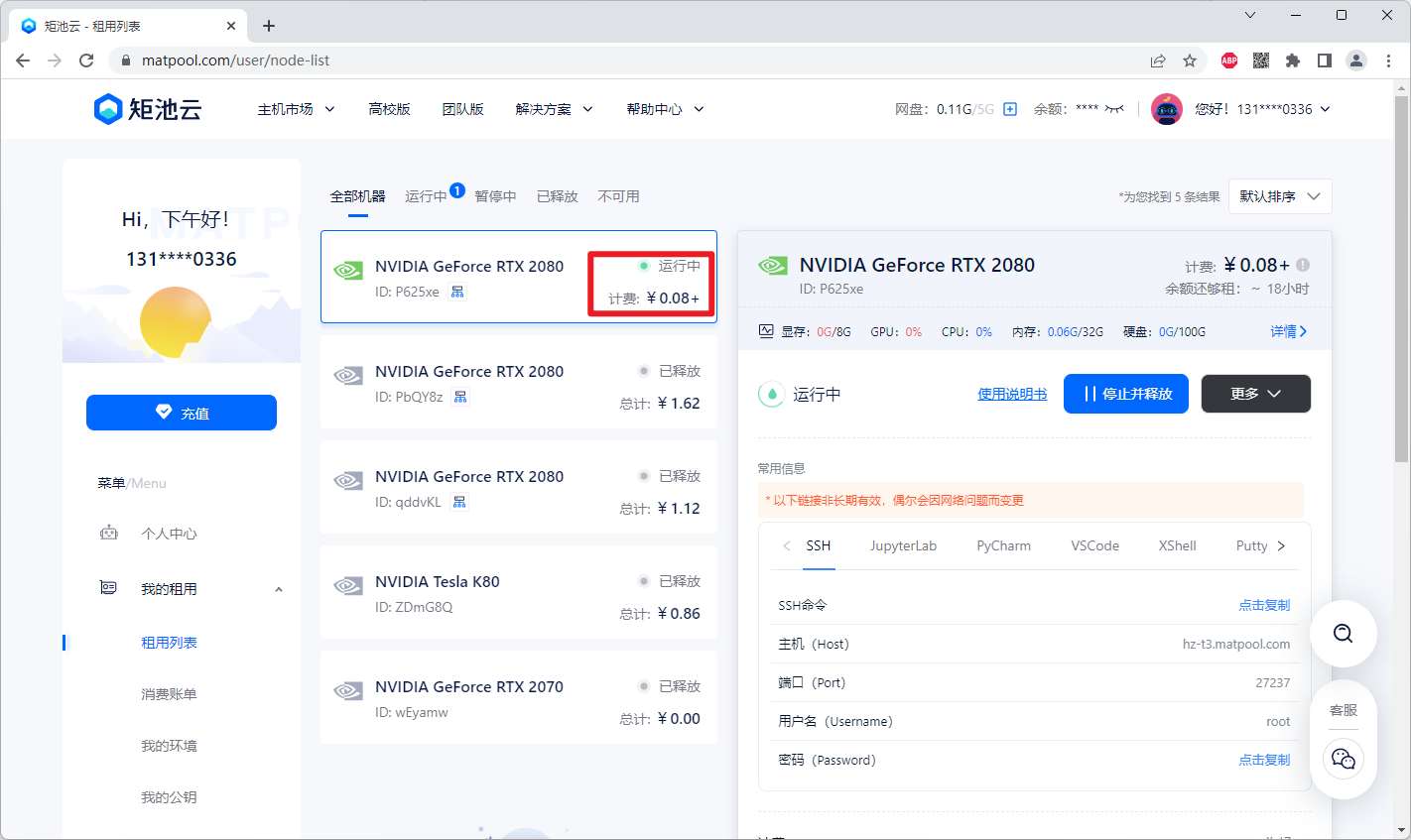
连接好后:
# 在这个目录下看看能不能找到自己上传到云盘上的YOLOv5 cd /mnt
(四)、训练运行(特别注意,这里是使用了矩池云的云盘后的默认根路径:/mnt)
在此之前请确定好对应的图片和标签的对应位置以及配置文件信息:
参考配置文件:
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..] path: /mnt/yolov5-master/data/ChineseChess # dataset root dir train: images/train # train images (relative to 'path') val: images/val # val images (relative to 'path') test: # test images (optional) # Classes nc: 2 # number of classes names: ['no-arse', 'no-bosom'] # class names
图片标签配置文件放置(这里是一个放置参考,主要注意看看路径)

训练配置文件分析
数据集相关信息: 数据集根目录:/mnt/yolov5-master/data/ChineseChess 训练集图片目录:images/train(相对于数据集根目录) 验证集图片目录:images/val(相对于数据集根目录) 测试集图片目录:如果需要指定测试集图片目录,可以在test字段中填写相应的路径。在这个配置中,测试集图片目录是可选的。 类别信息: # 这是标签的分类数量和名称: 类别数量:2(nc: 2) 类别名称:['r-bing', 'b-zu'],表示有两个类别,分别是'r-bing'和'b-zu' # ---------------------- 训练集(Train set):训练集包含用于模型训练的图像数据。模型通过观察训练集中的图像和相应的标注来学习目标物体的特征和位置信息。 验证集(Validation set):验证集用于在训练过程中对模型进行验证和调参。通常会从训练集中分割一部分数据作为验证集,用于评估模型在未见过的数据上的表现。这有助于监控模型的泛化能力,并避免过拟合。 测试集(Test set):测试集包含模型从未见过的图像数据,用于最终评估模型的性能和泛化能力。测试集的设计目的是模拟模型在实际应用中遇到的新数据,以便评估模型的真实表现。
训练(如果你使用的是自己的配置高的电脑,注意改对应的地址)
# 参考指令: # data/ChineseChess/ChineseChess.yaml 对应你的配置文件地址 python3 train.py --weights yolov5s.pt --data data/ChineseChess/ChineseChess.yaml --workers 4 --batch-size 20 --epochs 100
结果的权重文件就在:runs/train/exp/weights/ 下 这里多次训练exp文件名会依次增加 exp exp2...
图片识别测试结果 Validating runs/train/exp/weights/best.pt... Fusing layers... Model summary: 157 layers, 7015519 parameters, 0 gradients Class Images Instances P R mAP50 mAP50-95: 100%|██████████| 1/1 [00:00<00:00, 6.54it/s] all 20 56 0.766 0.474 0.53 0.225 no-arse 20 30 0.658 0.333 0.383 0.126 no-bosom 20 26 0.874 0.615 0.676 0.324
三、运行
(一)、将训练好的模型文件下载并放在yolov5源码更目录下的自定一目录下
# 比如你放在: C:\Users\YAN\Desktop\yolov5\myModel\xxx.pt # 注意,那你的运行指令的对应模型文件地址就要变哦,不是直接放在根路径下
(二)、在PyCharm中的控制台上运行
detect.py 这里是关键代码,Python好的可以自行学习修改,也可以通过Flask接口使其可以通过Http接口访问,当然写好了可以分享给我康康啊
python detect.py --weights best.pt【即你训练的模型文件】 --source 0 # webcam 本机摄像头 img.jpg # image vid.mpp4 # video screen # screenshot path/ # directory list.txt # list of images list.streams # list of streams 'path/*.jpg' # glob
四、参考视频和总结展望
(一)、B站参考视频:
1、在这里你可以学到YOLOv5的使用,对于环境没有配置好的和想进一步了解的看这个(感谢作者的教学):
2、在这里你可以学到YOLOV5于树莓派结合,对于矩池云那里有问题和没看清楚的看这个(感谢作者的教学):
3、一篇外网作者文章(使用 Flask 进行视频流传输,脑洞大的你可以猜想,看懂就机器翻译,哈哈哈): https://blog.miguelgrinberg.com/post/video-streaming-with-flask
(二)、总结展望:
作为一个Java菜鸟程序员,目前并对YOLO了解不太多。但是我们可以看到其在图像和实时流的识别上可以做很多事情,比如我们可以通过YOLO做图片的检测,再通过Flask或者Python后端提供对应的Http接口服务供Java或者直接供前端使用,这点Python后端程序员比我熟。
然后我们也可以看到还能用YOLOv5检测实时流(文中只是提及了摄像头,但是如果是流媒体的实时流也是可以的所以可以尝试作为直播场景下的违规检测),那么其实可以做一些监控设备或者是实时流的检测,这里比如:车库往来车辆检测提取车票获取司机信息扣费或者是高速路检测超速,当然可能也不一定会用YOLOv5类似的专业人士比我熟。
当然也可以和硬件结合起来,以YOLO为眼,然后要不就是自动根据其控制一些硬件操作,或者就是可以识别报警,人工进行控制。至于可视化怎么做那就看你的脑洞了。
本文作者:如此而已~~~
本文链接:https://www.cnblogs.com/fragmentary/p/18262591
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· 单线程的Redis速度为什么快?
· 展开说说关于C#中ORM框架的用法!
· Pantheons:用 TypeScript 打造主流大模型对话的一站式集成库