winform网站资源抓取及下载设计方案和理念
设计方案
根据之前项目需求,抓取网站资源并下载,整理出两套设计方案:
1)采用HtmlAgilityPack.HtmlDocument(),当前网Html进行解析,再使用XPath路径表达式获取节点集合;
2)分析网页资源脚本和页面,若当前加载资源内容部分为异步操作,必定会存在异步调用操作的JS,获取JS存在AJAX请求的的相关参数作为模拟客户端请求的方式;
以下将对两种设计方案进行详细说明:
HtmlAgilityPack.HtmlDocument解析
winform的界面设计
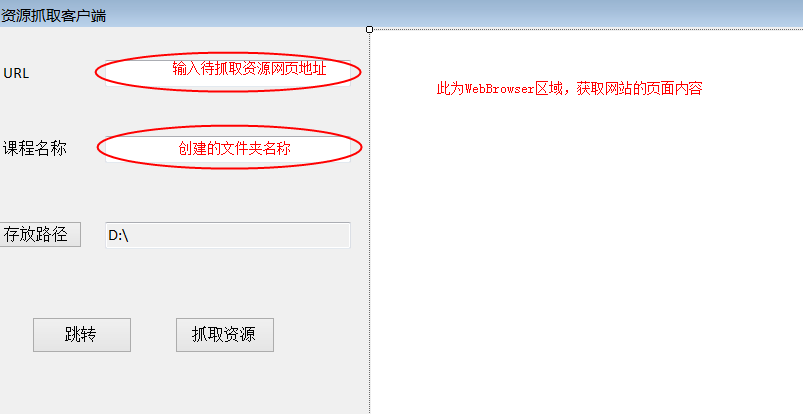
此方式希望一次性加载所有资源目录并通过异步线程实现资源下载。
资源抓取程序
1 private void button1_Click(object sender, EventArgs e) 2 { 3 if (string.IsNullOrEmpty(chaperName.Text)) 4 { 5 MessageBox.Show("请输入课程名称"); 6 return; 7 } 8 if (string.IsNullOrEmpty(directory.Text)) 9 { 10 MessageBox.Show("请选择存放路径"); 11 return; 12 } 13 var root = directory.Text+@"\"+chaperName.Text; 14 if (!Directory.Exists(root)) 15 { 16 Directory.CreateDirectory(root); 17 } 18 List<JumonyZ> list = new List<JumonyZ>(); 19 string htmlstr = ""; 20 htmlstr = broswer.Document.GetElementById("horizontal_container").InnerHtml; 21 HtmlAgilityPack.HtmlDocument doc = new HtmlAgilityPack.HtmlDocument(); 22 doc.LoadHtml(htmlstr); 23 //XPath路径表达式,这里表示选取所有span节点中的font最后一个子节点,其中span节点的class属性值为num 24 //根据网页的内容设置XPath路径表达式 25 HtmlNode rootnode = doc.DocumentNode; 26 var xpathString= "//div[@class='course-catalog students-catalog']/ol/li"; 27 HtmlNodeCollection chapters= rootnode.SelectNodes(xpathString); 28 if (chapters != null) 29 { 30 foreach (var li in chapters) 31 { 32 var spanText = li.SelectSingleNode("//span").InnerText; 33 var chapterDir = !string.IsNullOrEmpty(spanText)?root + @"\" + spanText: root; 34 if (!Directory.Exists(chapterDir)) 35 { 36 Directory.CreateDirectory(chapterDir); 37 } 38 var sections = li.SelectNodes("//ol/li[@data-hid]"); 39 if (sections!=null) 40 { 41 foreach (var sect in sections) 42 { 43 var sectionNode = sect.SelectSingleNode("//div[@class='catalog-row clefix']"); 44 var sectFolderName = sectionNode.SelectSingleNode("//div[@class='catalog-left']/div[@class='catalog-name']/a/span").InnerText; 45 var sectionDir = !string.IsNullOrEmpty(sectFolderName) ? chapterDir + @"\" + sectFolderName : chapterDir; 46 if (!Directory.Exists(sectionDir)) 47 { 48 Directory.CreateDirectory(sectionDir); 49 } 50 var sectionResNode = sectionNode.SelectNodes("//div[@class='catalog-right h_cells']/a"); 51 if (sectionResNode!=null) 52 { 53 foreach (var resource in sectionResNode) 54 { 55 var res_Name = resource.GetAttributeValue("title", ""); 56 var res_Url = resource.GetAttributeValue("href", ""); 57 Action<string, string, string> w_downloadRes = LoadingResource; 58 w_downloadRes.BeginInvoke(res_Name, res_Url, sectionDir,null,null); 59 } 60 } 61 var itemNodes = sect.SelectNodes("//li"); 62 if (itemNodes!=null) 63 { 64 foreach (var item in itemNodes) 65 { 66 var itemNode = item.SelectSingleNode("//div[@class='catalog-row clefix']"); 67 var itemFolderName = itemNode.SelectSingleNode("//div[@class='catalog-left']/div[@class='catalog-name']/a/span").InnerText; 68 var itemDir = !string.IsNullOrEmpty(sectFolderName) ? sectionDir + @"\" + itemFolderName : sectionDir; 69 if (!Directory.Exists(itemDir)) 70 { 71 Directory.CreateDirectory(itemDir); 72 } 73 var itemResNode = sectionNode.SelectNodes("//div[@class='catalog-right h_cells']/a"); 74 if (itemResNode != null) 75 { 76 foreach (var resource in itemResNode) 77 { 78 var res_Name = resource.GetAttributeValue("title", ""); 79 var res_Url = resource.GetAttributeValue("href", ""); 80 Action<string, string, string> w_downloadRes = LoadingResource; 81 w_downloadRes.BeginInvoke(res_Name, res_Url, sectionDir, null, null); 82 } 83 } 84 } 85 } 86 } 87 } 88 } 89 } 90 else 91 { 92 MessageBox.Show("暂无资源"); 93 return; 94 } 95 }
执行异步线程实现下载部分代码如下:
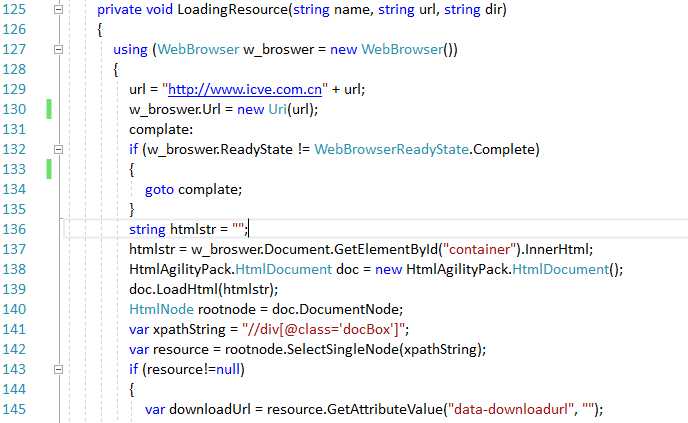
下面设计的代码就是根据当前downloadUrl采用Webclient模拟客户端请求下载资源通过filestream文件流的方式输出下载的文件;很可惜,这里没有得到想要的结果,因为winform采用[STAThread]单线程操作,导致在异步请求启用WebBrowser时提示单线程无法执行,从而终止此设计方案;
Webclient模拟数据接口,反序列化数据对象
抓取设计理念及程序
首先需要分析当前页面站点发送请求的方式,针对资源部分若是异步请求,你用谷歌浏览器F12查看JS异步请求参数,采用WebClient模拟异步请求,程序如下:

注意若被抓取的服务器需要验证Session,那么就需要事先加载WebBrowser并登录获取当前用户Cookie,并将Cookie添加到Webclient中再发送请求;然后将返回的对象字符串进行反序列化:
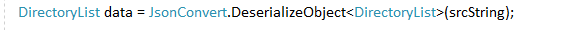
可以先用在线解析序列化网站,对指定的返回的数据结构的解析,并生成Model,现在解析网站:https://www.bejson.com/jsonviewernew/
最后对解析的数据进行处理,详情内容不做具体赘述,程序如下:

资源下载主要程序
1 WebClient client = new WebClient(); 2 // 第一种 3 string url="http://zy2.icve.com.cn:80/doc/b@18D4B8F3E4FB002A638E59549C034E38.pdf/download?&filename=01案例欣赏《AniRoschier动画场景设计欣赏》"; 4 Stream str = client.OpenRead(url); 5 StreamReader reader = new StreamReader(str); 6 byte[] mbyte = new byte[1000000]; 7 int allmybyte = (int)mbyte.Length; 8 int startmbyte = 0; 9 while (allmybyte > 0) 10 { 11 int m = str.Read(mbyte, startmbyte, allmybyte); 12 if (m == 0) 13 break; 14 startmbyte += m; 15 allmybyte -= m; 16 } 17 18 reader.Dispose(); 19 str.Dispose(); 20 string path = "E:\\" + System.IO.Path.GetFileName(url); 21 22 23 FileStream fstr = new FileStream(path, FileMode.OpenOrCreate, FileAccess.Write); 24 fstr.Write(mbyte, 0, startmbyte); 25 fstr.Flush(); 26 fstr.Close();
以上内容为项目总结,若有不足支出,请多多建议。
本文来自博客园,作者:念冬的叶子,转载请注明原文链接:https://www.cnblogs.com/fqzhong2007/p/7997989.html
