http/1.x、http/2与https的区别、以及http3
面试的时候被问到http与https的区别、以及http/1.x与http/2的区别,之前偶尔有了解,但是没有系统的学习,所以答的就比较模棱两可,结果不大如人意,于是狠下心来。。。学呗
一、首先说http与https的区别

(一)、了解http与https之前先要知道一下几个概念:
1、什么是http与https?
2、什么是ssl与tls
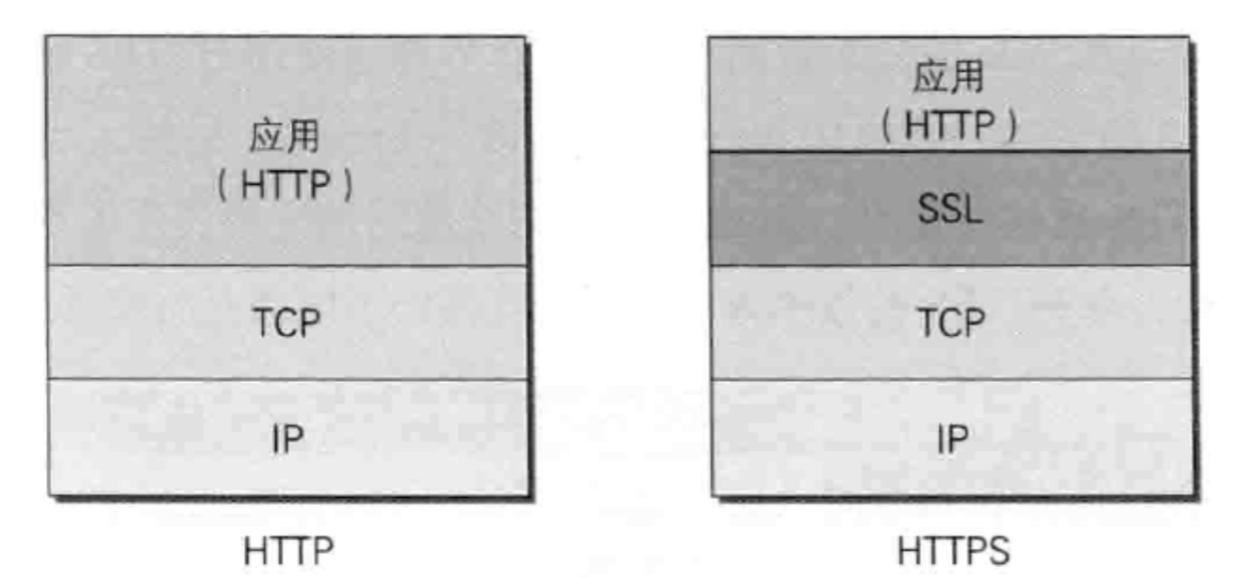
1、http(HyperText Transfer Protocol)超文本传输协议,https(Hypertext Transfer Protocol Secure)超文本传输安全协议,就是http的安全版本。http与https都属于应用层协议,下一层是TCP(传输层协议),https没有对http作任何修改,https是由http进行通信,但利用SSL/TLS来加密数据包,https是在http与tcp之间加了一个ssl/tls协议。http + 加密 + 认证 + 完整性保护 = https,可以说https是披着ssl/tls外衣的http。那么什么是ssl/tls?
2、ssl/tls:SSL/TLS是HTTP和TCP之间的中转协议,也是一个应用层协议。我们可以把ssl/tls理解为一个黑盒子,我们把数据丢给http,http把数据丢给ssl/tls,ssl/tls把数据加密后丢给tcp,这就是https。
(二)、http与https的特点
1、http是明文传输,所以如果报文被劫持,劫持者完全可以读懂报文或修改报文,易被监听、伪装、篡改,是一种不安全的协议。而https是密文传输,它是由http+SSL的结合体,由之前http到tcp,改为了http到SSL到tcp。报文是经过加密的,所以更加安全。
2、https使用需要CA证书,大部分都是付费使用的
3、http默认使用80端口,https默认使用443端口
4、https因为多了一层ssl/tls加密,以及数字证书的握手,数据的加密/解密,以及密钥的交换与确认,消耗更多的CPU和内存资源,加密范围也比较有限,黑客攻击、拒绝服务攻击、服务器劫持方面几乎起不到什么作用。最关键的,SSL证书信用链体系并不安全,特别是在某些国家可以控制CA根证书的情况下,中间攻击一样可行。
二、再说http/1.x与http/2的区别

Web 性能的终极目标是减少到用户端的延迟,让用户能够尽快的打开前端网页并进行相关交互。尽可能发送少的数据给服务器,从服务端下载尽可能少的数据,尽可能减少往返 (Round Trips) ,客户端与服务器无论是哪一边,额外的数据流都会带来额外的延迟开销,与此同时也更容易出现拥塞和丢包问题,这无疑严重影响了性能。 多余的 Round Trip 同样会增加延迟,尤其是在移动网络下(100ms 是让用户感觉到系统立即做出响应的时间上限)。
而HTTP/2试图解决HTTP/1.1的许多缺点和不灵活之处,对比demo在这里。
(一)、HTTP/1.x
Http1.x
缺陷:线程阻塞,在同一时间,同一域名的请求有一定数量限制,超过限制数目的请求会被阻塞。

http1.0
缺陷:浏览器与服务器只保持短暂的连接,浏览器的每次请求都需要与服务器建立一个 TCP 连接(TCP 连接的新建成本很高,因为需要客户端和服务器三次握手),服务器完成请求处理后立即断开 TCP 连接,服务器不跟踪每个客户也不记录过去的请求;
解决方案:添加头信息——非标准的 Connection 字段 Connection: keep-alive
http1.1
改进点:
1、持久连接
引入了持久连接,即 TCP 连接默认不关闭,可以被多个请求复用,不用声明 Connection: keep-alive(对于同一个域名,大多数浏览器允许同时建立 6 个持久连接)
2、管道机制
即在同一个 TCP 连接里面,客户端可以同时发送多个请求。
3、分块传输编码
即服务端没产生一块数据,就发送一块,采用”流模式”而取代”缓存模式”。
4、新增请求方式
PUT:请求服务器存储一个资源;
DELETE:请求服务器删除标识的资源;
OPTIONS:请求查询服务器的性能,或者查询与资源相关的选项和需求;
TRACE:请求服务器回送收到的请求信息,主要用于测试或诊断;
CONNECT:保留将来使用
缺点:
虽然允许复用 TCP 连接,但是同一个 TCP 连接里面,所有的数据通信是按次序进行的。服务器只有处理完一个请求,才会接着处理下一个请求。如果前面的处理特别慢,后面就会有许多请求排队等着。这将导致“队头堵塞”
避免方式:一是减少请求数(代码合并、图片精灵),二是同时多开持久连接(静态资源分布到不同的域下)。
(二)、HTTP/2.0
特点
采用二进制格式而非文本格式;完全多路复用,而非有序并阻塞的、只需一个连接即可实现并行;使用报头压缩,降低开销服务器推送
1. 二进制协议
HTTP/1.1 版的头信息肯定是文本(ASCII 编码),数据体可以是文本,也可以是二进制。HTTP/2 则是一个彻底的二进制协议,头信息和数据体都是二进制,并且统称为”帧”:头信息帧和数据帧。二进制协议解析起来更高效、“线上”更紧凑,更重要的是错误更少。
2. 完全多路复用(多路复用的单一长连接)
(1)、单一长链接
在HTTP/2中,客户端向某个域名的服务器请求页面的过程中,只会创建一条TCP连接,即使这页面可能包含上百个资源。而之前的HTTP/1.x一般会创建6-8条TCP连接来请求这100多个资源。单一的连接应该是HTTP2的主要优势,单一的连接能减少TCP握手带来的时延(如果是建立在SSL/TLS上面,HTTP2能减少很多不必要的SSL握手,大家都知道SSL握手很慢吧)。
另外我们知道,TCP协议有个滑动窗口,有慢启动这回事,就是说每次建立新连接后,数据先是慢慢地传,然后滑动窗口慢慢变大,才能较高速度地传,这下倒好,这条连接的滑动窗口刚刚变大,http1.x就创个新连接传数据(这就好比人家HTTP2一直在高速上一直开着,你HTTP1.x是一辆公交车走走停停)。由于这种原因,让原本就具有突发性和短时性的 HTTP 连接变的十分低效。
所以咯,HTTP2中用一条单一的长连接,避免了创建多个TCP连接带来的网络开销,提高了吞吐量。
(2)、多路复用
HTTP2把要传输的信息分割成一个个二进制帧,首部信息会被封装到HEADER Frame,相应的request body就放到DATA Frame,一个帧你可以看成路上的一辆车,只要给这些车编号,让1号车都走1号门出,2号车都走2号门出,就把不同的http请求或者响应区分开来了。但是,这里要求同一个请求或者响应的帧必须是有有序的,要保证FIFO的,但是不同的请求或者响应帧可以互相穿插。这就是HTTP2的多路复用,是不是充分利用了网络带宽,是不是提高了并发度?
更进一步,http2还能对这些流(车道)指定优先级,优先级能动态的被改变,例如把CSS和JavaScript文件设置得比图片的优先级要高,这样代码文件能更快的下载下来并得到执行。
3. 报头压缩
HTTP 协议是没有状态,导致每次请求都必须附上所有信息。所以,请求的很多头字段都是重复的,比如 Cookie,一样的内容每次请求都必须附带,这会浪费很多带宽,也影响速度。对于相同的头部,不必再通过请求发送,只需发送一次;HTTP/2 对这一点做了优化,引入了头信息压缩机制;一方面,头信息使用 gzip 或 compress 压缩后再发送;另一方面,客户端和服务器同时维护一张头信息表(分静态部分和动态部分),所有字段都会存入这个表,产生一个索引号,之后就不发送同样字段了,只需发送索引号。
4. 服务器推送
HTTP/2 允许服务器未经请求,主动向客户端发送资源;通过推送那些服务器任务客户端将会需要的内容到客户端的缓存中,避免往返的延迟
服务端可以主动推送,客户端也有权利选择是否接收。如果服务端推送的资源已经被浏览器缓存过,浏览器可以通过发送RST_STREAM帧来拒收。主动推送也遵守同源策略,换句话说,服务器不能随便将第三方资源推送给客户端,而必须是经过双方确认才行。
上文提到 HTTP/2 使用了多路复用,一般来说同一域名下只需要使用一个 TCP 连接。但当这个连接中出现了丢包的情况,那就会导致 HTTP/2 的表现情况反倒不如 HTTP/1 了。
因为在出现丢包的情况下,整个 TCP 都要开始等待重传,也就导致了后面的所有数据都被阻塞了。但是对于 HTTP/1.1 来说,可以开启多个 TCP 连接,出现这种情况反到只会影响其中一个连接,剩余的 TCP 连接还可以正常传输数据。
1、0RTT
传输层0RTT建立连接
加密层0RTT建立连接
2、真正的多路复用
虽然 HTTP/2 支持了多路复用,但是 TCP 协议终究是没有这个功能的。QUIC 原生就实现了这个功能,并且传输的单个数据流可以保证有序交付且不会影响其他的数据流,这样的技术就解决了之前 TCP 存在的问题。
同HTTP2.0一样,同一条 QUIC连接上可以创建多个stream,来发送多个HTTP请求,但是,QUIC是基于UDP的,一个连接上的多个stream之间没有依赖。比如下图中stream2丢了一个UDP包,不会影响后面跟着 Stream3 和 Stream4,不存在 TCP 队头阻塞。虽然stream2的那个包需要重新传,但是stream3、stream4的包无需等待,就可以发给用户。
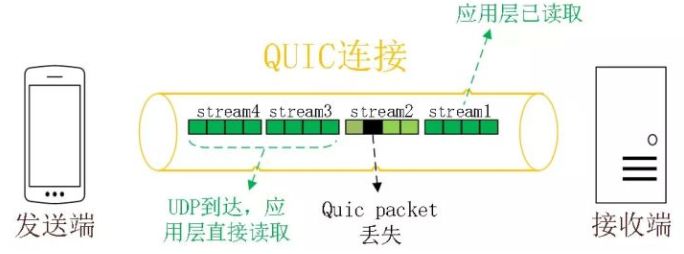
另外QUIC 在移动端的表现也会比 TCP 好。因为 TCP 是基于 IP 和端口去识别连接的,这种方式在多变的移动端网络环境下是很脆弱的。但是 QUIC 是通过 ID 的方式去识别一个连接,不管你网络环境如何变化,只要 ID 不变,就能迅速重连上。
3、加密认证的报文
TCP 协议头部没有经过任何加密和认证,所以在传输过程中很容易被中间网络设备篡改,注入和窃听。比如修改序列号、滑动窗口。这些行为有可能是出于性能优化,也有可能是主动攻击。
但是 QUIC 的 packet 可以说是武装到了牙齿。除了个别报文比如 PUBLIC_RESET 和 CHLO,所有报文头部都是经过认证的,报文 Body 都是经过加密的。
这样只要对 QUIC 报文任何修改,接收端都能够及时发现,有效地降低了安全风险。
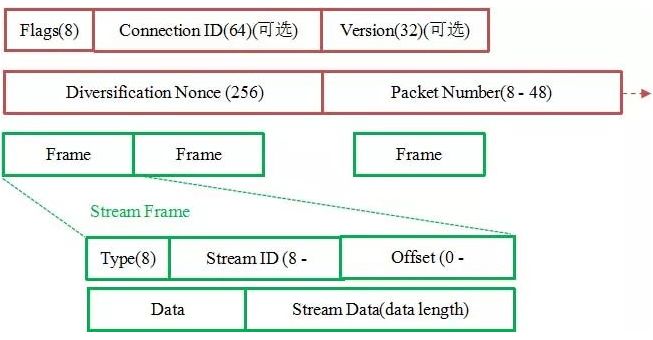
如上图所示,红色部分是 Stream Frame 的报文头部,有认证。绿色部分是报文内容,全部经过加密。
4、向前纠错机制
QUIC协议有一个非常独特的特性,称为向前纠错 (Forward Error Correction,FEC),每个数据包除了它本身的内容之外,还包括了部分其他数据包的数据,因此少量的丢包可以通过其他包的冗余数据直接组装而无需重传。向前纠错牺牲了每个数据包可以发送数据的上限,但是减少了因为丢包导致的数据重传,因为数据重传将会消耗更多的时间(包括确认数据包丢失、请求重传、等待新数据包等步骤的时间消耗)。
假如说这次我要发送三个包,那么协议会算出这三个包的异或值并单独发出一个校验包,也就是总共发出了四个包。当出现其中的非校验包丢包的情况时,可以通过另外三个包计算出丢失的数据包的内容。当然这种技术只能使用在丢失一个包的情况下,如果出现丢失多个包就不能使用纠错机制了,只能使用重传的方式了。
参考文献:
HTTP/2 对现在的网页访问,有什么大的优化呢?体现在什么地方?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号