自注意力的秘密.
跟着别人学转换器
参考地址
1,超参数文件
2,源汇词汇文件,预处理,就是词汇+次数的统计文件
3,加载数据,批量化数据文件,词与id建立一一对应关系.(一批一批的处理数据)
4,(实现编码器和解码器的)模型文件(重点)
5,训练代码(模型,损失函数)
6,评估.
1,超参数:批大小,学习速率,最大词长度,最小词数,隐藏节点数(或许就是神经单元数吧),块数(加解码块数)
4,模型.
1,先归一化,
2,词嵌入.估计就是将词=>映射为词的数字表示.这个其实还是映射.
3,重点.这个就是注意力了.
为什么要关注这个注意力模型?,有个人说得好.这个玩意儿最能够提取特征!!!,重中之重!!!
注意力模型(Attention Model)被广泛使用在自然语言处理、图像识别及语音识别等各种不同类型的深度学习任务中,是深度学习技术中最值得关注与深入了解的核心技术之一。
参考注意力模型
注意力模型,就是找的词与词间的关系,这个词与谁谁谁关系最好.对输出每一个词时.注意力的值是不同的.关键是如何找出注意力关系矩阵呢?如何学会呢?
公式:yi=f1(Ci,y[0…i)),这里的Ci是关系权重.
Ci=g(关系向量*词嵌入向量),所谓的g,基本上都是加个权,或者就是1.
所以.实质上很简单的表示,这些人搞得复杂得很.
看见没有,仔细看注意力矩阵的权重,最后是根据上个输出的词与前面的每个词的相似度来得到的.即越相似,权重越大.这就是词嵌入的威力,可以判断词与词之间的相似度.
什么是对齐?对齐就是相似度判定余弦函数的问题.
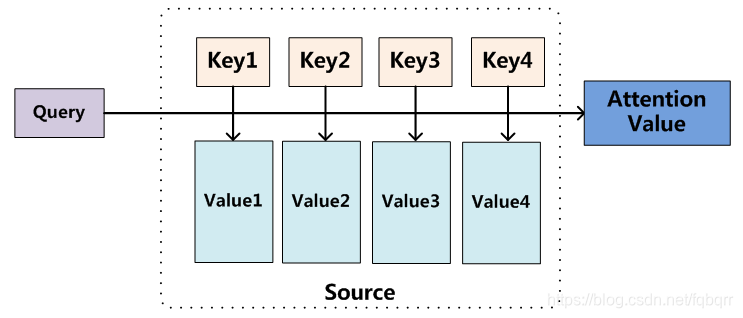
仔细看.人人都可以搞懂注意力.这里的键值对.查询是什么意思?
查询是目标词的词向量即词嵌入.键是什么意思?键就是源词的词向量.值呢?值就是每个源词与目标词的相似度.所以,注意力的秘密暴露了.就是相似度.所以,词嵌入的发展会更一步加强.然后就是bert,=>xlnet!相似度就是秘密.秘密就是相似度.
所以,所谓的三元素查询,键,值,妈妈再也不担心我不知道这是什么鬼东西了.
相似度,就是可替换性.词与词之间的可替换性.然后再把结构搞定..
如果是常规的Target不等于Source情形下的注意力计算,其物理含义正如上文所讲,比如对于机器翻译来说,本质上是目标语单词和源语单词之间的一种单词对齐机制。那么如果是Self Attention机制,一个很自然的问题是:通过Self Attention到底学到了哪些规律或者抽取出了哪些特征呢?
上面是人家写的.仔细看.
自注意力.自注意力有啥用?
对齐,也就是找相似,找注意力的过程!!!图片对齐,狗与狗的图片对应.


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 25岁的心里话
· 按钮权限的设计及实现