

查看windows操作系统的默认编码
查看windows操作系统的默认编码
转自:http://blog.csdn.net/java_belucky/article/details/18311225
转自:http://blog.csdn.net/yelbosh/article/details/7518484
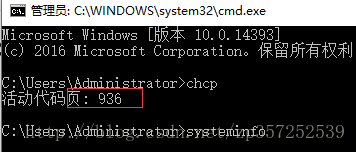
在Windows平台下,进入DOS窗口,输入:chcp
可以得到操作系统的代码页信息,你可以从控制面板的语言选项中查看代码页对应的详细的字符集信息。
例如:
我的活动代码页为:936,它对于的编码格式为GBK。
代码页是字符集编码的别名,也有人称"内码表"。早期,代码页是IBM称呼电脑BIOS本身支持的字符集编码的名称。当时通用的操作系统都是命令行界面系统,这些操作系统直接使用BIOS供应的VGA功能来显示字符,操作系统的编码支持也就依靠BIOS的编码。现在这BIOS代码页被称为OEM代码页。图形操作系统解决了此问题,图形操作系统使用自己字符呈现引擎可以支持很多不同的字符集编码。
早期IBM和微软内部使用特别数字来标记这些编码,其实大多的这些编码已经有自己的名称了。虽然图形操作系统可以支持很多编码,很多微软程序还使用这些数字来点名某编码。
各种编码依次产生简介:
ANSII码:英文码+英文常用图形,一个字符占用一个字节。
GB2312(1980年,中国大陆,最早国标码):即中文ANSII码,中文码占用了0x80~0xFF,收录汉字6763个,汉字图形682个。ASII有94个区,每个区94位,每个区位放一个字符。一个字节只能表示256个字符,不够用,因此要用两个字节,最多能表示65536个字符。
GBK(1995年,中国大陆,国标扩展码,基于GB2312):占用8140 ~FEFE。因为GB2312缺少生僻,增补汉字8160个字。
GB18030(基于GBK的扩展码):本来觉得GBK已经够了,不知道哪个货拿出了《康熙字典》,悲剧,又不够了,继续扩展。
台湾有BIG5码,日韩也跟着添乱。中日韩台港文字出现在一起时,没招了……
终于,Unicode编码出来了,把地球上所有的语言的符号,都用统一的字符集来表示,一个编码真正做到了唯一。
但是Windows又出来裹乱,在UTF-8码上又加了BOM,导致Linux下不能识别。但是Python可以做兼容。
BOM:Byte Order Mark,字节顺序标记。会在文件开始的地方插入三个不可见的字符(0xEF 0xBB 0xBF,即BOM)。
Unicode里有几种方式:
UTF-16BE/LE:UTF-16 LE就是Windows模式的编码模式,用2个字节表示任意字符,注意:英文字符也占2个字节(变态不?),这种编码可以表示65536个字符,至于LE和BE,就是一个数值在内存/磁盘上的保存方式,比如一个编码0x8182,在磁盘上应该是0x81 0x82呢?还是0x82 0x81呢?就是高位是最先保存还是最后保存的问题,前者为BE(大端),后者为LE(小端)。
UTF-8:UTF-8则是网页比较流行的一种格式,用一个字节表示英文字符,用3个字节表示汉字,准确的说,UTF-8是用二进制编码的前缀,如果某个UTF-8的编码的第一个字节的最高二进制位是0,则这个编码占1字节,如果是110,则占2字节,如果是1110,则占3字节……
关于字符集(character set)和编码(encoding),比较容易有些混淆。
对于 ASCII、GB 2312、Big5、GBK、GB 18030 之类的遗留方案来说,基本上一个字符集方案只使用一种编码方案。
比如 ASCII 这部标准本身就直接规定了字符和字符编码的方式,所以既是字符集又是编码方案;而 GB 2312 只是一个区位码形式的字符集标准,不过实际上基本都用 EUC-CN 来编码,所以提及「GB 2312」时也说的是一个字符集和编码连锁的方案;GBK 和 GB 18030 等向后兼容于 GB 2312 的方案也类似。
在不同语言的系统中编码不同,这一部分在微软的术语中叫 code page。比如所谓 GBK 编码,实际上更多地被叫做 CP936。
[1] Windows 里说的「ANSI」其实是 Windows code pages,这个模式根据当前 locale 选定具体的编码,比如简中 locale 下是 GBK。把自己这些 code page 称作「ANSI」是 Windows 的臭毛病。在 ASCII 范围内它们应该是和 ASCII 一致的。
[2] 把带有 BOM 的小端序 UTF-16 称作「Unicode」也是 Windows 的臭毛病。Windows 从 Windows 2000 开始就已经支持 surrogate pair 了,所以已经是 UTF-16 了,「UCS-2」这个说法已经不合适了。UCS-2 只能编码 BMP 范围内的字符,从 1996 年起就在 Unicode/ISO 标准中被 UTF-16 取代了(UTF-16 通过蛋疼的 surrogate pair 来编码超出 BMP 的字符)。都十多年了,求求大家别再误称了……
[3] 把带 BOM 的 UTF-8 称作「UTF-8」又是 Windows 的臭毛病。如果忽略 BOM,那么在 ASCII 范围内与 ASCII 一致。另请参见:「带 BOM 的 UTF-8」和「无 BOM 的 UTF-8」有什么区别? http://www.zhihu.com/question/20167122
————————————————
版权声明:本文为CSDN博主「xuejianhui0911」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/xuejianhui/article/details/81214422

