
线程安全之可见性(三)
一:final的处理
1.1 经final修饰的变量或者对象,在其构造函数中初始化之后,其他线程一定可以获得正确的构造版本,即可以获得变量或者对象字段的最新值。
看下面的代码:
上述代码,定义了一个final修饰的i,和一个没用final修饰的j,在构造函数中赋值后,i在其他线程中一定可以获得正确的构造版本,即i=2,而j不一定可以获得正确的构造版本,可能获得j的默认值0。
1.2 经final修饰的变量或者对象,在其构造函数中初始化之后,其他线程一定可以获得正确的构造版本,而且字段若重新赋值与final修饰的字段,那么该字段也一定可以获得正确的构造版本。
public class ThreadFinal2 { public final int i; public int j; public ThreadFinal1 final1; public ThreadFinal2() { this.i = 2; //一定可以得到正确的构造版本 this.j = this.i; //也一定可以得到正确的构造版本 } public void write() { final1 = new ThreadFinal1(); } public void reader() { if (final1 != null) { System.out.println(final1.i); System.out.println(final1.j); } } }
上述代码中,j赋值为i,i是final修饰的字段,那么j在其他线程中也一定可以获得正确的构造版本,即j=2。
二:字节分裂(word tearing)
在有些处理器中,不能对单个的字节进行修改,这样就会造成一些问题;如字节数组,多个线程想要去修改它,只能通过把该字节数组copy过来修改,然后再把主内存中的字节数组覆盖掉,这样会造成只能有一个线程是修改成功的。

![]()
在上图中,线程1和线程2去修改字节数组,分别修改不同位置的值,这样就会造成最后只有一个线程修改成功。所以,在多线程编程中,尽量不要去对byte[]数组修改。
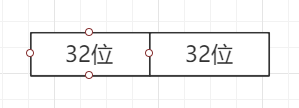
三:double和long的特殊处理
double和long都是64位字节,他们的特殊在于,要去修改值,是分成两部分进行的,即分成两个32位字节的,这样就会导致,出现脏数据,如一个线程修改了值,另一个线程读取,可能读到的是只修改一部分的值。
![]()
所以在多线程编程中,可以用volidate字段去修饰double和long,并不是说volidate修饰的字段是原子性的,只是在double和long中,用volidate修改,可以保证其原子性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号