
机器学习 作业1
1. 机器学习概述
本周任务:
1.python基础的准备
本课程拟采用Python做为机器算法应用的实现语言,所以请确保:
1)安装好Python开发环境, PyCharm 或 Anaconda等都可以,按个人习惯喜好。
2)基本库的安装,如numpy、pandas、scipy、matplotlib
3)具备一定的Python编程技能,如果不熟悉,可选择一个教程进行学习,Python简单好上手,资源也很丰富。
菜鸟教程 Python 3 教程 http://www.runoob.com/python3/python3-tutorial.html
廖雪峰的官方网站 Python3 https://www.liaoxuefeng.com/wiki/1016959663602400
学习视频
2.本周视频学习内容:https://www.bilibili.com/video/BV1Tb411H7uC?p=1
1)P4 Python基础
2)P1 机器学习概论
机器学习是一门多领域交叉学科,涉及较多的数学知识,我们不做太多理论上的要求,如果有听不懂的地方,不要放弃,看一遍就有个印象。通过观看视频,大家对课程有个总体的认识。
建议大家边看边做笔记,记录要点及所在时间点,以便有必要的时候回看。学习笔记也是作业的一部分。
3.作业要求:
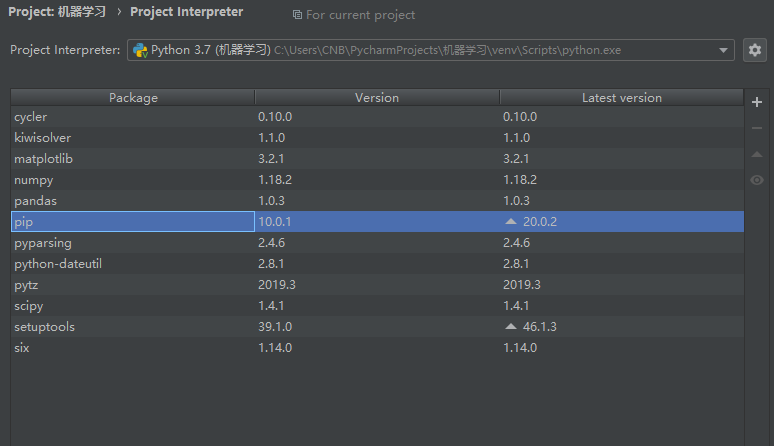
1)贴上Python环境及pip list截图,了解一下大家的准备情况。暂不具备开发条件的请说明原因及打算。
python环境

pip list
使用国内镜像,使相关包的下载更快,其中优选豆瓣pip源镜像
2)贴上视频学习笔记,要求真实,不要抄袭,可以手写拍照。
1.Python基础
02:52Python有各种各样的安装包,安装Python包推荐工具Pip: https://pypi.python.org/pypi/pip
06:33Numpy:为Python提供快速的多维数组处理能力
06:57Pandas更多的是处理可视化相关的,在Numpy基础上提供了更多的数据读写工具
07:25Scipy在Numpy基础上添加了众多科学计算工具包
09:54Python相较于C,Java,可以用更简单的代码输出矩阵
10:36验证中心极限定理
10:51正态分布的概率密度函数
11:45Poisson分布的概率质量函数
12:23机器学习中的损失函数
13:13各种2D曲线
13:283D
13:49类/继承类
15:16重心插值,样条插值
16:55Taylor展式
17:21Taylor展式应用
18:15计算圆周率
19:02数值计算
25:38负二项分布
34:13 本福特定律
39:33 import导包方式介绍
47:17 array创建数组
48:16 shape查看数组大小
reshape创建改变了尺寸的新数组,原数组shape不变
(数组a和b共享内存,修改其一将影响另一个)
52:36 dtype用于数组的元素类型获取或设置
54:33 astype转换元素类型
56:15 使用函数创建数组arange
59:04 linspace指定起始值、终止值和元素个数创建数组
60:20 logspace创建等比数列
63:40 数组元素存取
65:20 切片
71:10 np.random.rand()生成随机数
80:39 numpy与python数学库的时间比较
84:53 元素去重,库函数np.unique():利用转换为虚数split;利用set
98:25 绘图,绘制正态分布密度函数
104:57 损失函数:Logistic损失(-1,1)/SVM Hinge损失/ 0/1损失
112:43 xx绘图
114:34 胸型线
116:07 心形线
117:05 渐开线
118:00 sin曲线
118:34 概率分布:均匀分布,验证中心极限定理,其他分布的中心极限定理,poisson分布
131:00 直方图的使用
132:26 插值
133:44 绘制三维图像
2.机器学习概论
01:31 机器学习与数学分析主要内容介绍,数学分析,概率论基础
02:25 什么是机器学习
机器学习是人工智能的一个分支。我们使用计算机设计一个系统,使它能够根据提供的训练数据按照一定的方式来学习;随着训练次数的增加,该系统可以在性能上不断学习和改进;通过参数优化的学习模型,能够用于预测相关问题的输出。
05:04 无人驾驶汽车
09:38 人类的学习
18:40 机器学习的内涵与外延
21:48 人们对于机器学习的图文印象
24:11 机器学习房屋价格例子
35:19 建模
36:03 预测
37:26 机器学习的一般流程
数据收集—数据清洗—特征工程—数据建模
39:35 机器学习方法
42:03 机器如何发现新词
42:50 Python Code示例
45:38 机器学习示例
线性回归、rate、Loss;EM Code,EM算法;GMM与图像;图像的卷积;去均值ICA分离;带噪声的信号分离;SVM:高斯合函数的影响;Crawler爬取数据;HMM分词:MLE;LDA;舆情;石油例检结果;
55:04 其他内容
最大熵模型:自然语言处理解决标记问题
聚类:K-means/K-Mediods/密度聚类/谱聚类
降维:PCA/SVD/ICA
SVM:与核技术相结合
主题模型pLSA/LDA:与聚类、标签传递算法相结合
条件随机场:无向图模型,链式条件随机场解决标记问题
变分推导Variation Inference:与EM、贝叶斯相结合,参数、隐变量的学习
深度学习:大规模人工神经网络
55:30 本课程参考文献(部分)
62:30 对数函数的上升速度
67:41 导数
69:51 常用函数的导数
71:23 应用1:已知f(x)=xx,x>0,求f(x)最小值
75:28 求解xx
76:46 积分应用2: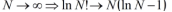
83:11 Taylor公式-Maclaurin公式
85:15 Taylor公式的应用1:初等函数值的计算,计算e^x。
94:51 Taylor公式的应用2:Gini系数的图像、熵、分类误差率之间的关系
97:14 方向导数
102:46 梯度
107:22
114:46 凸函数
119:06 一阶可微,二阶可微
125:40 凸函数
128:31 概率论,古典概型,生日悖论,装箱问题,与组合数的关系
138:42 组合数背后的秘密:熵
3)什么是机器学习,有哪些分类?结合案例,写出你的理解。
答:机器学习是人工智能的一个分支。我们使用计算机设计一个系统,使它能够根据提供的训练数据按照一定的方式来学习;随着训练次数的增加,该系统可以在性能上不断学习和改进;通过参数优化的学习模型,能够用于预测相关问题的输出。
机器学习通常可以分为四种:
①监督学习:利用已标记的有限训练数据集,通过某种学习策略/方法建立一个模型,实现对新数据/实例的标记(分类)/映射。如回归分析和统计分类。
②无监督学习:利用无标记的有限数据描述隐藏在未标记数据中的结构/规律。如聚类。
③半监督学习:介于监督学习与无监督学习之间,其主要解决的问题是利用少量的标注样本和大量的未标注样本进行训练和分类,从而达到减少标注代价、提高学习能力的目的。如拉普拉斯支持向量机。
④强化学习:智能系统从环境到行为映射的学习,以使强化信号函数值最大。由于外部环境提供的信息很少,强化学习系统必须靠自身的经历进行学习。如无人驾驶。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号