论文阅读笔记十七:RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation(CVPR2017)

论文源址:https://arxiv.org/abs/1611.06612
tensorflow代码:https://github.com/eragonruan/refinenet-image-segmentation
摘要
RefineNet是一种生成式的多路径增强网络,在进行高分辨率的预测时,借助远距离的残差连接,尽可能多的利用下采样过程中的所有信息。这样,通过前期卷积操作得到的细粒度特征可以增强能够获得图像更高层次信息更深的网络。RefineNet的组件基于残差连接,可以进行端到端的训练。该文还引入了链式残差池化操作,进而以一种高效的方式捕捉更加丰富的背景上下文信息。
介绍
分割问题可以被看做是一种密集的分类任务,VGG,ResNet等在分类任务上取得不俗的成绩,但对于像密集深度,或者普通的评估,语义分割等密集预测时就会显得力不从心。原因在于在下采样过程中预测的图片会缩为原图大小的几分之一,此过程会丢失大量的图像结构信息。 解决方法是利用反卷积进行上采样 ,但上采样无法恢复在网络前向过程中下采样丢失的可视化的底层信息,因此,无法生成准确率较高分辨率的预测结果。然而,底层的可视化信息对于边界细节信息的预测发挥着重大的作用。Deeplab在不缩减图片尺寸的基础上利用空洞卷积扩大感受野的范围。但空洞卷积的做法存在两个限制条件:(1)需要在大量高维度的空洞feature map上运行卷积操作,这需要大量的计算资源。此外,大量高维度和高分辨率的feature map在训练阶段需要更多的GPU内存资源,这通常限制了高分辨率feature map预测时的计算,通常输出的尺寸为原图的八分之一。(2)空洞卷积生成比较粗糙的下采样feature map,造成重要细节信息的损失。
直观上中间层的网络包含着目标物体中层次的信息,同时其包含的位置信息也是丰富的。 中间层的信息虽然保留了一定的前端网络得到的像边,点,等细节信息,同时也包含着高层编码层的语义信息。但仍缺少足够多的位置信息。
该文主要是利用所有层的特征信息,较高的网络层利于图片区域的类别识别,低层网络提取的可视化的特征利于高分辨率的更多细节信息的生成。主要贡献如下:
(1)提出了多路增强网络,从而利用多个层次网络层的特征提取用于高分辨率的抽象信息。该网络利用递归的方式增强低分辨率(粗糙)的语义特征来产生高分辨率的分割特征图。
(2)该级联网络可以进行端到端的训练,可以用于更好的预测。此外,RefineNet的所有组件都由残差连接,梯度在训练过程中可以通过长短距离的残差连接进行高效的端到端的传播。
(3)该文提出了一种新的网络组建-链式残差池化,可以从图片中较大区域捕捉背景上下文信息。该模块中不同大小的窗口得到的池化特征通过残差连接和可学习的权重进行融合。
(4)该网络刷新了7个数据集的分数。
说明
该文基于ResNet进行改进,在ResNet的前向过程中,由于卷积与池化操作,图片的尺寸逐渐减少,而特征的深度(通道数)逐渐增加。ResNet的层可以根据输出feature map的大小分为4个不同的block。一系列的下采样操作有如下好处:(1)在更深层的网络中的感受野增大,从而捕捉更多的全局文本信息用于后续更准确的分类。
(2)由于每一层的网络包含大量的卷积核,进而输出的feature map中含有大量的通道数造成对训练的效率上有一定的要求,因此,最终需要在feature map上的大小与通道数之间做一个权衡,一般情况下,最后一层输出的feature map的大小在空间维度上是原图的32分之一,然而却包含1000多个通道。
低分辨率的feature map会丢失由前层网络得到的可视化信息,生成一个粗略的分割map,这是基于深度卷积网络的一个通病。一种替换方案是利用空洞卷积,在不降低分辨率的情况下保留较大的感受野。此方法中的下采样操作被移除。在ResNet第一个block之后的所有卷积层被替换为空洞卷积,空洞卷积可以在不增加训练参数的基础上扩大感受野的范围。即使这样,也会占用大量的内存,不同于下采样方法,空洞卷积在较高分辨率上保留大量的feature map(在网络的后层,通道数量剧增)。实际发现,在应用空洞卷积下,输出的feature map的尺寸最大不超过原图的八分之一,而不是四分之一。

方法
该网络基于通用的ResNet组建进行构建,通过不同分辨率及潜在的长距离的连接辅助等操作提供多通路的信息。
多通路增强
该文通过远距离的残差连接来获得不同尺寸的feature map用于高分辨率的预测。RefineNet提供一种通用的方式将粗糙的高级别的分割特征与细粒度低级别特征进行融合进而产生高分辨率的分割特征图。该网络结构的一个重要关键点是确保可以通过不同长距离的残差连接将梯度在反向传播时可以传递到较低层的网络层中,从而可以保证整个网络可以进行端到端的训练。
该网络将在ImageNet上预训练的ResNe根据feature map的尺寸的大小分为4个block,外加一个带有4个RefineNet单元的4级联结构,每一个RefineNet单元与对应的block进行直接相连,同时四个RefineNet单元进行级联。同时,这种结构可以进行多种变换,一个单元可以接受所有block作为输入。每个RefeineNet单元的结构相同,但之间的参数并不相关,因此,每一个单元可以针对对应层次的细节进行调整。
根据上图c,从下网上,从ResNet的block4开始,将RefineNet4与ResNet对用的block4进行直接连接。RefineNet4只有一个输入,RefineNet4后接一系列的卷积层用于调整与训练的ResNet权重,下一阶段,RefineNet4的输出与ResNet3的输出作为RefineNet3的2通路输入。RefineNet3的作用时利用从ResNet block3中的较高分辨率的feature map增强RefienNet4输出的低分辨率的feature map。如此重复。最终生成的高分辨率的feature map送入一个密集的soft-max分类层。产生用于预测的score map。得到的score map通过基于双线性插值进行上采样得到与原图大小相同的score map。
该网路的一个重要部分在于在ResNet block与RefineNet之间引入了长距离的残差连接。在前向过程中,残差连接可以将低层编码的可视化细节信息用于增强粗糙的高级别的feature map。训练时,这些连接可以将梯度直接传递到前端的卷积层中。
RefineNet
RefineNet block结构图如下图a所示,每个RefineNet单元可以被修改为不同数量的尺寸与通道数不限的输入。
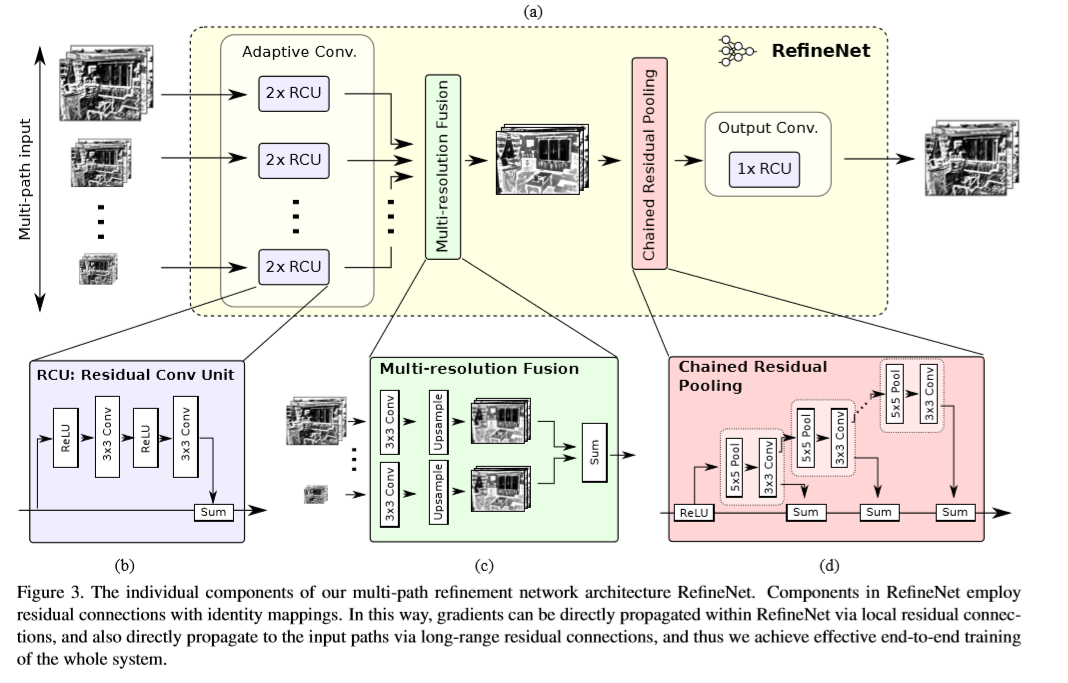
残差卷积单元(RCU):RefineNet的组成结构中的第一个,包含一系列的可调整的卷积集合,用于针对目标任务对与训练的ResNet权重进行微调。最终,每个输入通路经过两个RCU模块。RCU是原始ResNet中卷积单元的一个精简版本。移除了原始版本中的BN层。CMU中卷积核的数量在RefineNet4中设置为512,在其他的CMU中将为256。
多尺寸融合模块:所有通路的输入通过一个多尺寸融合模块得到一个高分辨率的feature map。该模块首先用卷积调整输入,生成相同特征维度,然后,童过上采样将所有尺寸调整为输入中最大的尺寸。最终,所有得到的feature map通过相加融合得到最终的feature map。对于输入特征通过卷积的调整可以将不同通路的特征值进行适当的调整,利于后面的特征融合。如果只有一个通路特征,则不会发生变化,直接穿过block。
链式残差池化:该模块的作用是从较大图片区域中捕捉背景上下文信息。利用可学习的权重,通过不同窗口大小的卷积池化操作并将其特征进行融合高效的实现特征池化操作。该组件由一系列不同的pooling block连接组成,每个pooling block由一层池化和卷积组成。每个block的输入是前一个block的输出,因此,当前的block可以再利用前一层block得到的结果,从而再不使用大尺寸窗口的条件下可以访问到更多区域的信息。本文使用了连个pooling block stride为1组成该链式残差池化模块。所有pooling blocks 输出的结果通过残差连接进行加和融合。该block中每一层池化后接一个卷积操作作为一个融合的权重层。从而在训练过程中,卷积层会调整池化vblock的重要性(通过卷积的权重参数调整)。
输出卷积:每个RefineNet的最后一块是另一种类型的RCU组件。因此,在每个RefineNet中存在三个RCU组块。为了反应RefineNet-1的block上的效果,在soft-max预测的前面添加了两个额外的RCU模块。这里对多通路的融合特征进行非线性操作生成后续用到或进行预测的特征。在经过此模块后,特征的维度并未发生变化。
RefineNet中的独立映射:
RefineNet中的所有卷积组件受ResNet启发,并一一对应进行映射。这种形式可以进行促进梯度的反向传播,同时可以对多通路的增强网络进行端到端的学习。应用残差连接,可以将梯度从一个block传到另一个block中,这种做法有利于保持一个干净的信息通道,而不会被其他非线性网络层或者组件干扰。而非线性操作主要应用在主信息通路中。在所有的卷积单元中都加了ReLU非线性操作,在链式残差池化中只含有一个ReLU非线性模块。实验发现,加入ReLU操作后,降低了模型对学习率的敏感度,而且对梯度的影响较小。
RefineNet中由长距离及短距离两种残差连接。短链接是指RCU或链式残差池化中的局部连接,长连接是指RefineNet模型与ResNet blocks之间的连接。经过长连接,梯度可以直接传递到ResNet前端的网络中,进而实现端到端的训练所有网络组件。
fusion block 将具有一定的维度或者尺寸的残差连接进行求和融合。这里多尺寸融合模块的作用类似于ResNet中传统残差卷积的融合作用。在RefineNet尤其是在fusion block中有特征的线性变换操作,像线性特征维度降低和双线性上采样。ResNet中的两个blocks的连接,用一个卷积层进行特征维度的适应。由于只有线性操作。因此,梯度可以在网络中进行高效的传播。
实验

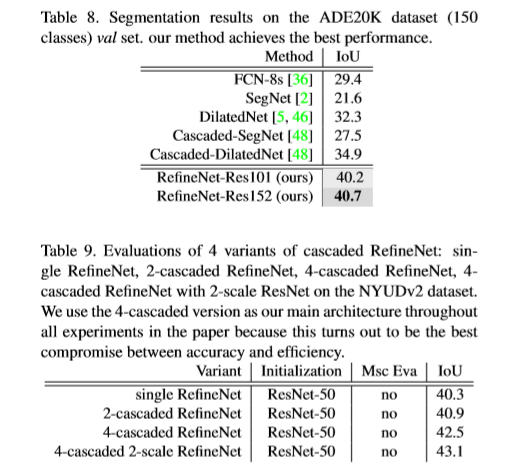

Reference
[1] A. Arnab, S. Jayasumana, S. Zheng, and P. H. Torr. Higher order conditional random fields in deep neural networks. In European Conference on Computer Vision. Springer, 2016.
[2] V. Badrinarayanan, A. Kendall, and R. Cipolla. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. CoRR, 2015.
[3] J. Carreira, R. Caseiro, J. Batista, and C. Sminchisescu. Semantic segmentation with second-order pooling. In ECCV, 2012.
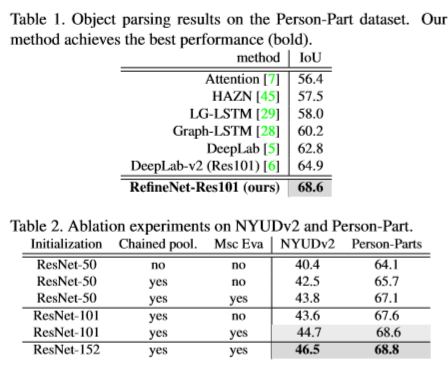
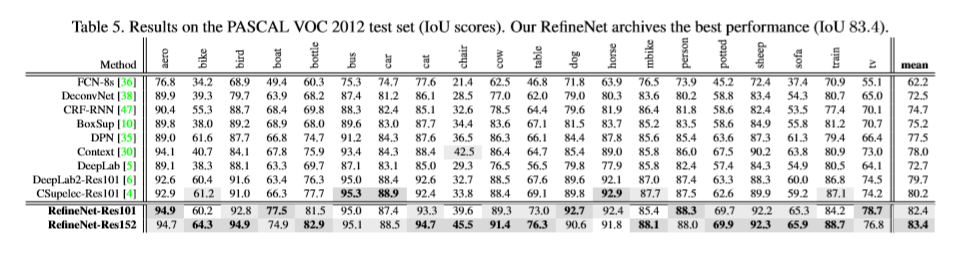
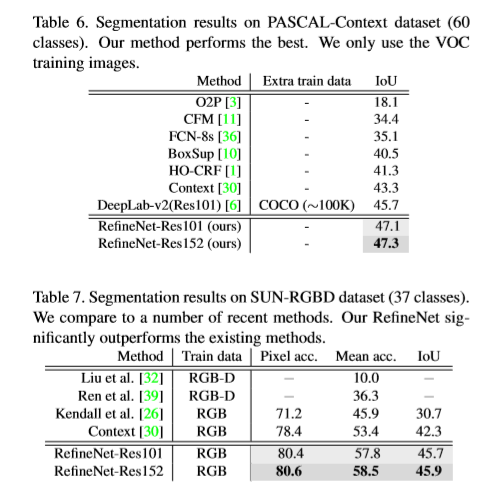
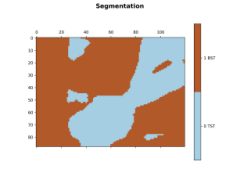
实验结果:目前分割效果不好,还在查找原因


 浙公网安备 33010602011771号
浙公网安备 33010602011771号