
论文阅读笔记十:DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs (DeepLabv2)(CVPR2016)

论文链接:https://arxiv.org/pdf/1606.00915.pdf
摘要
该文主要对基于深度学习的分割任务做了三个贡献,(1)使用空洞卷积来进行上采样来进行密集的预测任务。空洞卷积可以在不增加参数量的基础上增大filter的感受野,从而可以得到更多的语义信息。(2)空洞空间金字塔池化结构(ASPP)从而以多尺寸来分割目标物体。通过不同sample rates的filters及不同大小的感受野,来获得多尺寸下的语义信息。(3)结合DCNN与概率模型提高物体的检测边界。DCNNs+CRF
介绍
DCNN应用于分割的三个挑战:(1)feature 分辨率的减少(2)不同尺寸的目标物(3)由于DCNN的不变性导致分割边界的不精确。
解决方案:(1)将DCNN最后几个maxpooling去掉,在后续的卷积层中添加更高sample rate的空洞卷积。结合空洞卷积与双线性插值将feature map 还原为原图大小。
(2)一个标准方式是将图片处理成相同的尺寸,然后融合特征与score maps,但会引入大量的计算。受到空间金字塔池化启发,对feature map以多rates 进行卷积,增强了感受野,该文对一张图片平行的使用不同sample rate 的空洞卷积层(ASPP)。
(3)一个对应物体中心的分类器,要求对空间的一些旋转等变换有类别不变性,一种方式是在进行最终的分割预测时通过跳跃连接不同层的 features 来获得潜在信息。本文,作者是用了一个全连接的CRF来改善模型对边界的分割。

本文对VGG16,ResNe-101进行改进,(1)将全连接层变为卷积层(2)通过增加空洞卷积增加特征图的分辨率,应用双线性插值将score map还原为原图大小。(3)后接CRF来增强分割结果。
DeepLab的优势:(1)空洞卷积提高了速度(2)准确率:在VOC的多个任务上实现state-of-art(3)简约性:DCNNs+CRFs
DeepLabv2相比DeepLabv1的改进:对多尺寸的图片分割效果更好,引入ASPP,用ResNet作为backbone,实现比VGG16更好的效果。
相关工作
先前主要靠将手工设计的特征与boosting,随机森林,SVM等分类器结合实现较好的分割效果,后来结合了上下文信息与结构预测技术,但他们特征表达能力仍有欠缺。近年来,Deep Learning 推动了分割的发展。大致分为如下三个部分:
(1)基于DCNN的分割:通常采用自底向上的feature map级联,然后送入DCNN进行区域分割。
(2)通过卷积得到的DCNN feature maps 来密集的图像标记,然后将每个feature map单独的与分割结合起来。
(3)通过DCNNs直接得到密集的图像标签,甚至可以丢弃传统的分割算法。
这里提一下,虽然CRF作为后处理的手段,但该文将CRF的 mean-filed 推理步骤进行转化,并添加到end-to-end可训练的前向网络中。
方法
在空洞卷积部分,作者提到使用反卷积的一个弊端是需要额外的内存和计算时间。

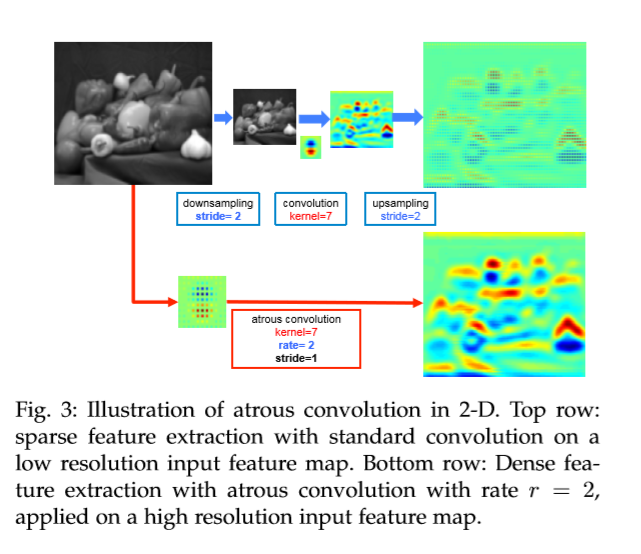
上图(上层为1D,下层为2D)很容易可以看出,将空洞卷积的rate 调大,会使得到的feature map更加密集。这里,由于网络最后的卷积池化层分辨率减少很多,因此,在随后的网络中增加rate 为2的空洞卷积,但这里会大大增加计算量,平衡效率与准确率,在对一个feature map放大四倍后,进行双线性插值来还原到原图分辨率大小。
空洞卷积的一个好处是可以控制感受野的大小。一个大小为kxk的卷积核引入rate为r的空洞卷积后大小变为Ke,计算如下
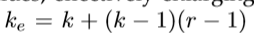
空洞卷积的应用表现在两个方面:(1)在卷积核中插入0值来进行上采样或稀疏采样输入的feature map。(2)根据空洞卷积中rate值的大小等倍数的对input feature map进行下采样。后通过标准的卷积使他们的像素恢复到原图大小。
ASPP
为了解决分割中的多尺寸问题,该文实验了两种方法:
(1)采用传统的方法,在训练和测试时,从DCNN中抽取多层(这里使三层)feature map,通过双线性插值恢复为原图尺寸,然后将其进行融合,这么做 确实有效果,但是增加了DCNN的计算量。
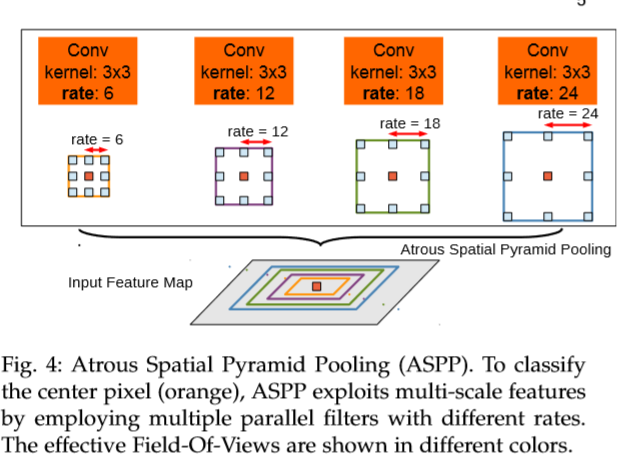
(2)对一张图片上通过平行的进行不同尺寸的空洞卷积操作,间接的得到多尺度特性,不同sample rate提取的特征经过单独的后处理和融合进而生成最终的结果。采用的即ASPP模型,如下图。
全连接CRF
DCNN中的一个固有弊端是位置的准确性与分类的效果之间的矛盾, 带有池化层越深的模型其分类效果越好,但 持续增加的不变性与较大的感受野只会使结果更加平滑,但无法使边界更加分明。
针对边界问题的方法,一是可以利用网络中多层feature map以便更好的进行边界分割。另一种方法是可以引入超像素表示,将边界任务交给较低级的分割方法处理。
该文结合DCNN的识别能力与全连接CRF较高的分界效果。
实验
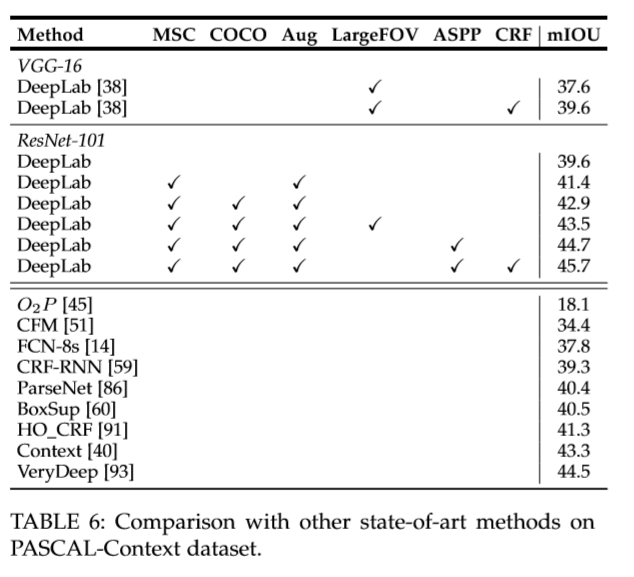
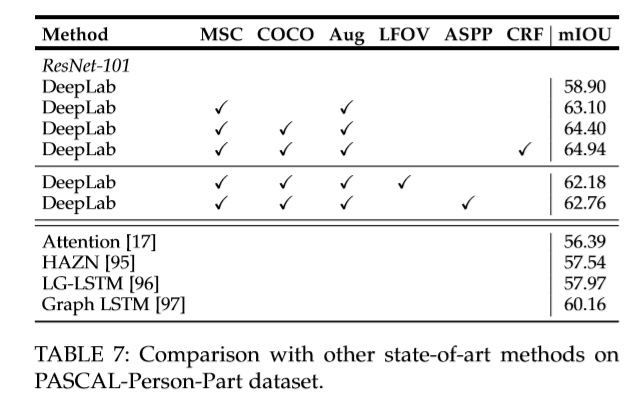
将VGG-16和ResNet-101处理成分割网络。损失函数是CNN输出feature map(缩小为8倍)后空间位置交叉熵的和,使用SGD优化算法,在PASCAL VOC 2012, PASCAL-Context, PASCALPerson-Part,和 Cityscapes上进行实验。
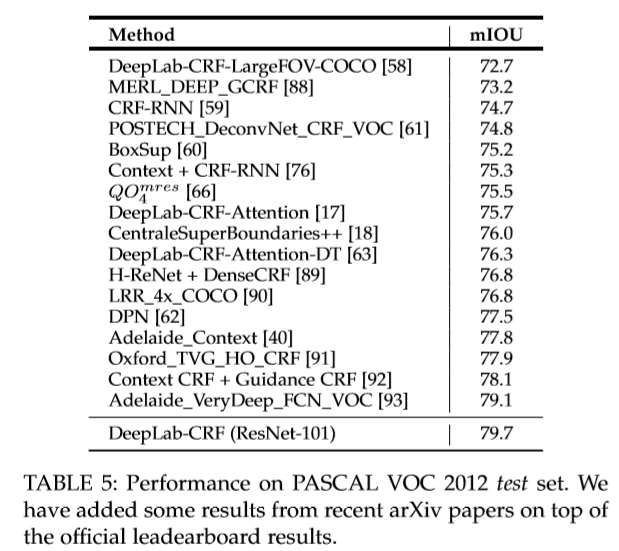
PASCAL VOC 2012:backbone:VGG-16 ,mini-batch:20 ,learning rate: 0.001,learning rate decay: 0.1 ,momentum: 0.9 ,weight decay: 0.0005

实验上的改进:(1)训练时不同的学习策略。(2)ASPP(3)加深网络和多尺度处理
(1)使用poly 学习速率,
(2)调整ASPP中的rate: r={2,4,8,12} r={6,12,18,24}
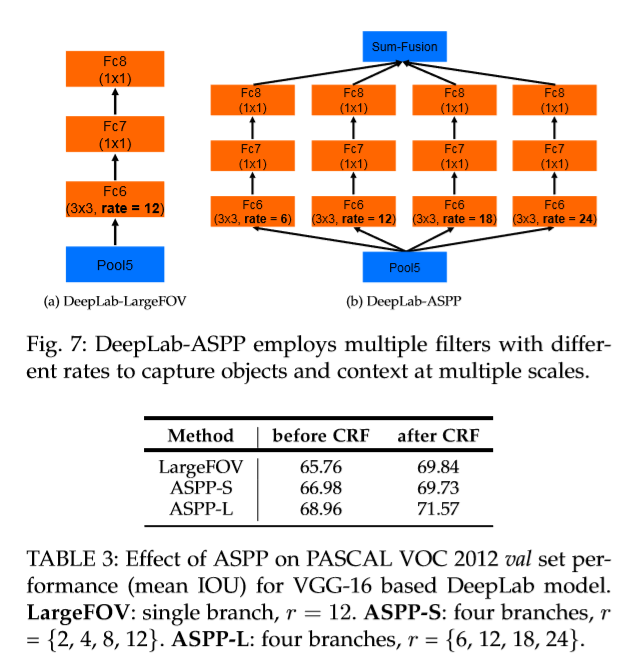
(3)将VGG-16换位ResNet-101使网络加深。



参考
[1] Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner, “Gradient-based learning applied to document recognition,” in Proc. IEEE, 1998.
[2] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” in NIPS, 2013.
[3] P. Sermanet, D. Eigen, X. Zhang, M. Mathieu, R. Fergus, and Y. LeCun, “Overfeat: Integrated recognition, localization and detection using convolutional networks,” arXiv:1312.6229, 2013.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号